Aim of Scheduling
CPU는 1개, 실행하고 싶은 프로세스는 여러 개
- Response time
- 유저 입장에서는 내 프로그램이 빠르게 실행되어야 한다.
- 입력을 줬을 때 결과값을 나타내는 시간
- 시스템 입장에서는 중요하지 않다.
- Throughput
- 시스템 입장에서의 스케쥴링의 목표
- 단위 시간당 작업을 끝낸 프로세스의 개수
- Processor efficiency
- 프로세스의 efficiency = 필요한 작업이 얼만큼 사용됐는지
- 필요한 작업 = 사용자의 프로그램
- 중간중간 OS가 끼어들어서 작업한다 ⇒ 시스템의 목적이 아니다.
- Context Switching할 때마다 많은 시간이 소요 ⇒ efficiency가 떨어진다.
- 프로세스의 efficiency = 필요한 작업이 얼만큼 사용됐는지
- Fairness
- OS가 좋아하는 프로세스 = 스케쥴링에 도움이 되는 프로세스
- OS가 싫어하는 프로세스 = 스케쥴링에 도움이 안되는 프로세스
- Starvation 발생 가능 ⇒ Fairness가 중요
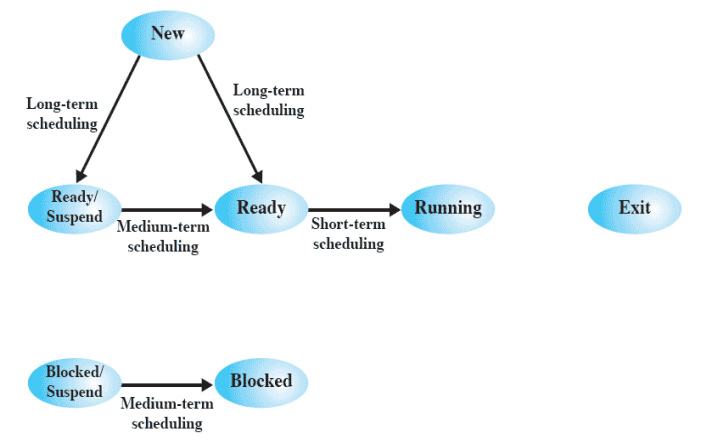
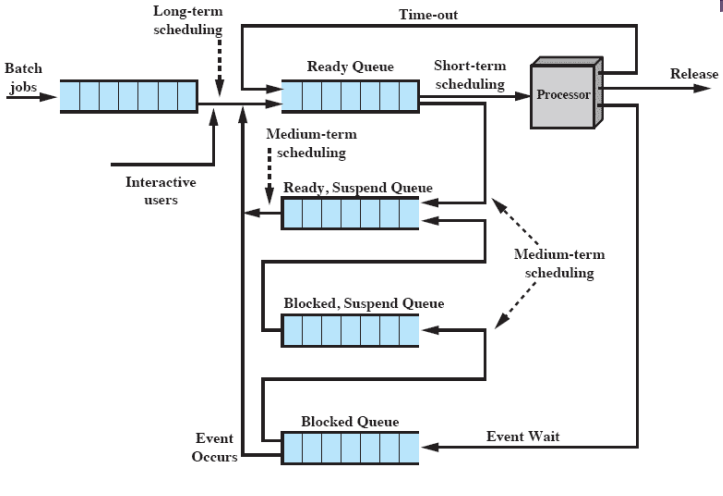
Types of Scheduling
- Long-term Scheduling
- 시스템 바깥쪽에서 안쪽으로 들어올 수 있는지 결정
- 프로세스가 만들어졌을 때 Ready Queue로 갈지, Ready/Suspend Queue 로 갈지를 결정한다.
- 새 프로세스가 생성됐을 때 실행된다.
- Batch job = 파일 입출력
- 시스템 상태에 따라 Ready/Suspend로 보내기도 한다.
- Medium-term Scheduling
- Swapping
- OS가 swapping 하는 과정에서 선택한다.
- Ready/Suspend or Block/Suspend → Ready or Block으로 갈지 OS가 선택한다.
- Short-term Scheduling
- Ready Queue에 있으면 CPU를 할당할지 말지 결정해야 한다.
- 시스템 성능에 중요한 영향을 미친다.
Short-Term Scheduling Criteria
- User-oriented
- Response Time
- input → ouput 소요 시간
- Turnaround Time
- Batch job(file 입출력) = 실행을 시작시킨 다음 실행이 다 끝난 다음에 파일을 보고 확인한다. ⇒ 프로세스가 실행을 시작해서 끝날 때까지의 시간
- 즉, Batch job은 Turnaround Time이 중요하다.
- Response Time
- System-oriented
- 프로세서의 utilization
- CPU가 얼마나 유용한 작업을 하는지
- Throughput
- 얼마나 단위시간당 몇 개의 작업을 끝마쳤는지
- 프로세서의 utilization
위의 4가지는 모든 척도들이 수치로 표현할 수 있다.
- Performance-related
- Not performanced related
- Predictability and fairness
- 예측가능성 = 프로세스의 실행을 시작시켰을 때 output을 줄 때까지의 시간
- starvation과 관련있다.
- 공정성 = 모든 사람들한테 똑같은 기회를 준다.
- 예측가능성 = 프로세스의 실행을 시작시켰을 때 output을 줄 때까지의 시간
- Predictability and fairness
Priorities
선택을 받는 기준. 각각의 프로세스들은 우선순위를 가지고 있고 스케쥴러는 우선순위가 높은 프로세스부터 실행한다.
우선순위에 따라 Ready 큐가 여러 단계로 나누어져 있다. ⇒ multi-level ready queue
최악의 경우 Starvation이 발생한다.
우선순위가 낮은 프로세스가 시스템안에서 오랫동안 있게 되면 우선순위가 높아질 수 있는 방법이 필요하다 ⇒ 계속 우선순위가 변하도록 계산을 다시하는 시스템이 다수
이런 시스템들 중에서 성능만 생각해서 우선순위를 다시 계산하는 시스템이 있고, 공정성을 생각해서 우선순위를 다시 계산하는 시스템이 있다.
Scheduling Algorithms
5가지 방법 중 좋은 방법의 기준은 Response Time 이다.
- First-Come-First-Served
- Round-Robin
- Shotest Process Next
- Shortest Remaining Time
- Highest Response Ratio Next
예시
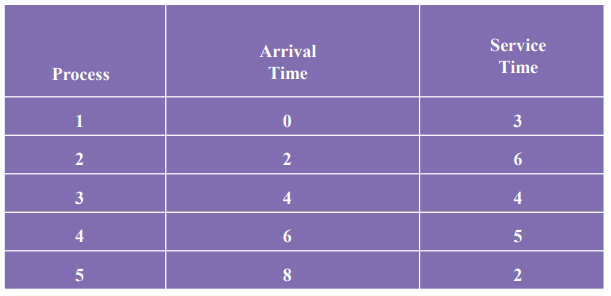
Arrival Time = 레디큐에 들어온 순서
Service Time = 다음번 I/O 작업까지 내가 얼만큼 CPU를 사용하려고 하는지
First-Come-First-Served(FCFS)
- 레디 큐에 프로세스들이 줄 서있으면 먼저 들어온 프로세스부터 실행한다.
- 중간에 끊지 않는다 = 타임아웃 X ⇒ Non-Preemption
- 우선순위 = Ready 큐에 도착한 시간
- Fair하다는 장점이 있다.
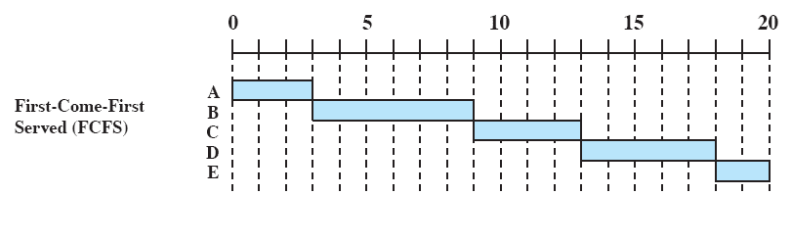
위의 상황을 보면 service time이 짧은 프로세스가 긴 시간동안 기다려야 한다.
Response time 계산
Response Time : 모든 프로세스의 Service time + Waiting time
FCFS : ((0+3)+(1+6)+(5+4)+(7+5)+(10+2))/5 = 43/5
모든 프로세스가 평균 43/5 = 8.6시간의 Response time을 가진다.
프로세스를 스위칭하는 시간이 불필요하게 발생하지 않는다.
CPU의 processor efficiency만 생각한다면 최적의 방식
Round-Robin
- Time-sharing( = time slicing) 방식 ⇒ 타임아웃이 존재
- preempted한 방식
- time quantum 마다 타임아웃 발생
- 최적의 타임퀀텀을 정하는 것이 중요
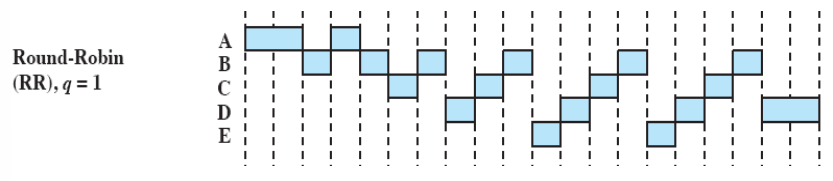
프로세스들은 동시에 도착하지 않는다. 작업하다가 타임아웃이 걸리면 큐의 제일 뒤로 간다.
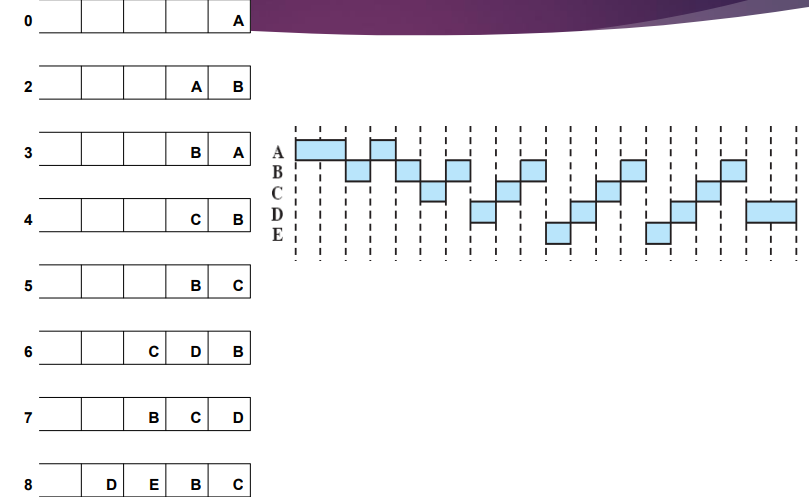
상황 이해하기
밖에서 들어온 프로세스 vs 타임아웃된 프로세스 ⇒ 밖에서 들어온 프로세스가 앞에선다고 가정
큐 그림을 그릴 수 있어야 한다.
Response Time 계산
- FCFS : ((0+3)+(1+6)+(5+4)+(7+5)+(10+2))/5 = 43/5
- RR : ((1+3)+(10+6)+(9+4)+(9+5)+(5+2))/5 = 54/5
FCFS와 RR을 사용했을 때 Response time을 계산하는데 있어서 차이점은 실행시간이 긴 프로세스의 WT는 늘어나고 짧은 프로세스의 WT은 줄어든다.
Batched multiprogramming system ⇒ FCFS
time sharing = Response time이 줄어든다. 하지만 time sharing 방식인 RR의 Response time이 더 길게 계산된다. 이유가 뭘까?
RR은 time quantum이 존재한다. time quantum을 바꾸면 Response time이 줄어든다. time quantum을 잘못사용하게 되면 Batched multiprogramming system보다 더 안좋은 Response time을 가지게 된다.
FCFS와 RR의 차이점 ⇒ preemption
FCFS와 RR의 공통점 ⇒ 우선순위 = 큐에 도착하는 시간
큐에 도착하는 시간이 우선순위라는 것은 예측가능성, 공정성를 중요시한다고 할 수 있다. 큐에 도착하는 시간 순서대로 진행하면 큐에 도착했을 때, 앞에 몇 명이 있는지 알면 언제쯤 실행될지 예측할 수 있다. 또한 큐에 들어가있으면 분명히 실행된다. 따라서 starvation 이 존재하지 않는다.
하지만 성능이 상당히 좋지 않다.
스케쥴링에 있어서 중요한 것은 service time의 길이이다. 그래서 service time이 긴 프로세스 뒤에 service time이 짧은 프로세스가 줄을 서지 않게 해야한다. 프로세스를 다 처리하는 데 걸리는 시간은 결국 똑같다. 하지만 response time은 다르다. 작업을 처리하는 순서에 따라 response time의 차이가 발생한다.
💡service time이 짧은 프로세스를 먼저 실행하는 것이 좋은 이유는?
Service Time이 짧은 프로세스를 먼저 실행시키는 것이 Waiting Time의 총합이 줄기 때문이다.
Shortest Process Next
- Service Time이 긴 프로세스 뒤에 service time이 짧은 프로세스가 줄을 서지 않게한다.
- 실행시간이 짧은 프로세스를 먼저 실행 ⇒ response time이 짧아지는 방법
- non-preemptive 한 방식
- 이미 실행을 시작했으면 아무리 실행시간이 길어도 멈추지 않는다.
큐에 있는 프로세스들 중에서 실행시간이 제일 짧은 프로세스를 선택한다.
단점
- 실행시간이 길면 언제 실행이 될지 예측할 수 없다 ⇒ 예측가능성이 낮다.
- 최악의 경우 starvation 발생
- 실행시간 예측 방법
- 실행 시간을 예측해도 예측한 값이 실제 실행 시간과 맞지 않을 수 있다 ⇒ 시스템 성능이 떨어진다.
장점
성능은 FCFS나 RR과 비교했을 때 상당히 성능이 좋다.
Response Time 계산
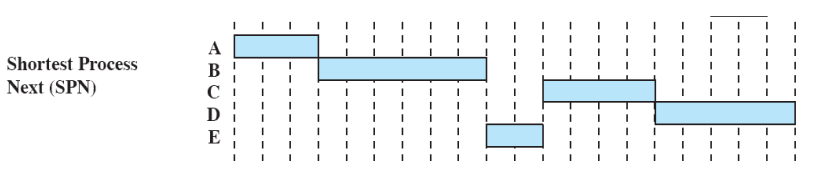
- FCFS : ((0+3)+(1+6)+(5+4)+(7+5)+(10+2))/5 = 43/5
- RR : ((1+3)+(10+6)+(9+4)+(9+5)+(5+2))/5 = 54/5
- SPN : ((0+3)+(1+6)+(7+4)+(9+5)+(1+2))/5 = 38/5
실행시간이 가장 짧다고 예상되는 프로세스를 실행한다. 실제로 실행하기 전까지 알 수 없다.
Calculating Program ‘BURST’
BURST time = CPU를 사용하는 시간
CPU를 사용하는 시간은 굉장히 짧고, I/O 작업을 하는 시간은 굉장히 길다. 그래서 BURST time을 예측해야 한다.
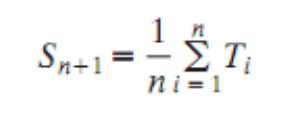
- S = 예측 시간
- T = CPU를 사용한 시간
N+1 번째 예측 시간 = 1 ~ N 까지의 실행시간의 평균 실행시간 ⇒ 산술평균
첫 번째 실행을 시작할 때는 예측할 수 없으므로 OS가 마음대로 예측한다. 대부분의 경우 프로세스의 타입에 따라서 예측한다.
Exponential Averaging
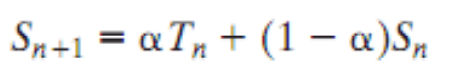
N+1 번째 예측 시간 = N 번째 실제 실행시간 가중치 + (1 - 가중치) N 번째 예측시
| T | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| S | 2 | ? | ? | ? |
위처럼 시간이 주어졌을 때 구할 수 있어야 한다.
Use Of Exponential Averaging
실행시간이 늘어나는 경우
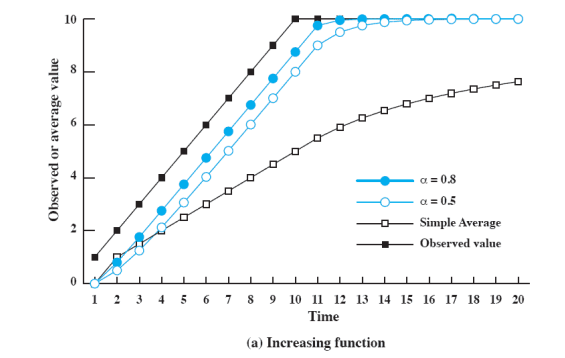
산술평균으로 예측한 경우 실제 상황과 많이 동떨어진다. 반면 Exponential Averaging을 사용하게 되면 실행시간 예측이 잘 들어맞는다.
실행시간이 줄어드는 경우
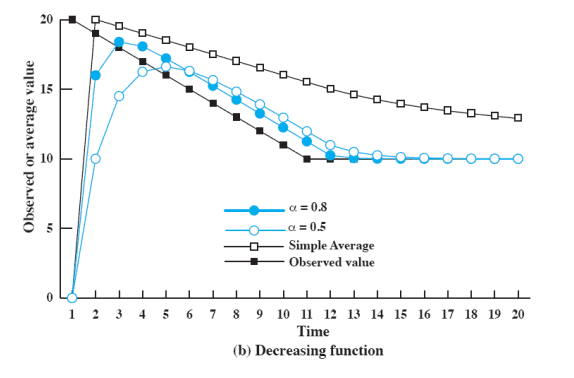
Exponential Averaging을 사용하면 실행시간 예측이 가능하다 ⇒ SPN 기법을 실제로 구현해서 사용 가능
Shortest Remaining Time
실행시간이 짧은 프로세스를 preemptive 하게 먼저 선택한다. ⇒ SPN의 preemptive version
전체 실행시간이 아닌 남아있는 시간을 비교한다.
| non-preemptive | preemptive | |
|---|---|---|
| 도착시간(예측가능성이 높고 starvation x, response time이 김) | FCFS | RR |
| 실행시간(starvation 가능) | SPN | SRT |
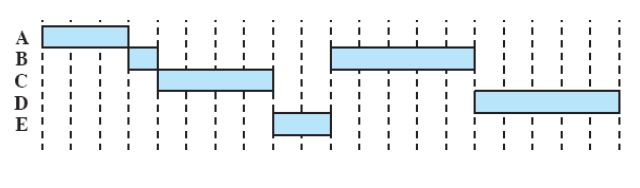
- FCFS : ((0+3)+(1+6)+(5+4)+(7+5)+(10+2))/5 = 43/5
- RR : ((1+3)+(10+6)+(9+4)+(9+5)+(5+2))/5 = 54/5
- SPN : ((0+3)+(1+6)+(7+4)+(9+5)+(1+2))/5 = 38/5
- SRT : ((0+3)+(7+6)+(0+4)+(9+5)+(0+2))/5 = 36/5
스케쥴링을 하는 데 있어서 SRT보다 더 성능이 좋은 기법은 존재하지 않는다. (구현할 수 없는 Optimal 제외)
그러나 단점이 존재한다.
- 실행시간 예측
- starvation
SPN은 운 좋게라도 실행을 시작하면 끝까지 실행하지만, SRT는 그렇지 않기 때문에 starvation 가능성은 SPN보다 더 크다.
starvation이 발생하는 대신 response time이 짧다. 그래서 중간을 선택하게 된다.
Highest Response Ratio Next (HRRN)
실행 시간도 고려하면서 오래 기다린 프로세스도 같이 고려한다. ⇒ 실행시간이 길다는 이유로 starvation이 발생하면 안되기 때문이다.

위 식을 간단하게 고치면 다음과 같다.
Ratio 가 높을수록 우선순위가 높아야 한다. service time이 작으면 Ratio 는 커진다. 따라서 Ratio 가 큰 프로세스가 우선순위가 높다.
또한 waiting time이 길어지게 될수록 Ratio 가 커진다.
즉, 실행 시간에 비해서 지나치게 오래 기다린 프로세스들 한테도 높은 우선순위가 주어진다.
그런데 HRRN은 Non-Preemptive 한 방식이다.
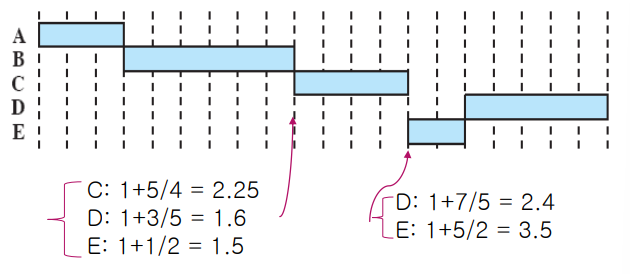
주의!
9시에
Ratio를 계산했을 때 D가 E 보다 0.1 더 높다. 그리고 이후에 12시에 고민 없이 D를 실행시키는 실수를 하지 말자. 같은 3시간이지만 각자의 실행시간에 따라 영향을 주는 정도가 다르다.
HRRN Response Time =
- FCFS : ((0+3)+(1+6)+(5+4)+(7+5)+(10+2))/5 = 43/5
- RR : ((1+3)+(10+6)+(9+4)+(9+5)+(5+2))/5 = 54/5
- SPN : ((0+3)+(1+6)+(7+4)+(9+5)+(1+2))/5 = 38/5
- SRT : ((0+3)+(7+6)+(0+4)+(9+5)+(0+2))/5 = 36/5
- HRRN : ((0+3)+(1+6)+(5+4)+(9+5)+(5+2))/5 = 40/5
Round-Robin 이나 FCFS 보다 response time이 작지만, SRT, SPN 보다는 response time이 크다.
결국 실행 시간만 따지는 기법들 보다는 response time이 떨어진다. 그러나 starvation 발생 가능성이 0이다. 실행시간이 아무리 길어도 실행시간보다 더 기다리다보면 결국 우선순위가 높아지기 때문이다.
지금까지 5가지 방법을 실제로 구현할 때의 문제점은 OS 이다. 시스템은 사용자의 프로세스를 실행시키는 것이 목적인데, 실행시간을 예측하거나 Ratio 값을 계산하려면은 OS가 실행되어야 한다.
이런 계산들은 시스템에 부담이 되기도 하고 계산이 틀릴 수도 있다. 실행 시간이 커졌다 작아졌다를 반복하게 되면 예측이 불가능하다.
Feedback
실행 시간을 예측하지 않고 실행 시간이 짧은 프로세스한테 우선순위를 준다.
실행 시간을 예측하는 것이 아니라, 실행 시간이 긴 프로세스한테 패널티를 준다. ⇒ 우선순위가 낮은 큐에서 나온 프로세스한테 타임 퀀텀을 길게 준다. ⇒ 우선순위가 낮다 = CPU를 오랜만에 잡음 ⇒ 잡았을 때 가능한 끝낼 수 있게
실행 시간이 길어지는 것을 파악하기 위해서 Multi-Level Feedback Queue 를 사용한다.
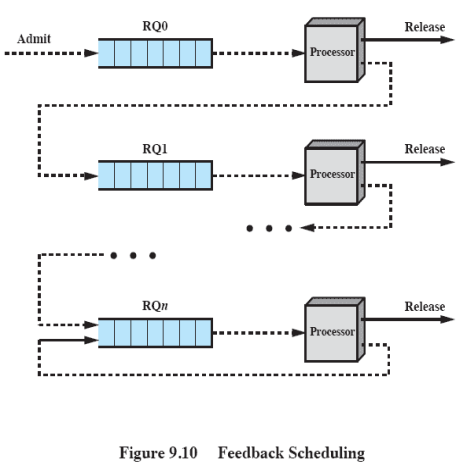
제일 처음에 도착한 프로세스는 0번 레디 큐로 들어간다. 그 후 스케쥴링되면 CPU를 차지한다. Block이나 Terminate 되면 그냥 나가면 되지만, 타임아웃이 되면 0번 큐로 들어가는 것이 아니라 1번 레디 큐로 들어간다.
위 작업을 반복하고 다시 타임아웃이 되면 2번 레디큐로 들어간다.
그러다 마지막 레디 큐에서 스케쥴링되고 다시 타임아웃이 발생할 때는 다시 마지막 레디 큐로 들어간다.
0번 큐에 있는 프로세스부터 Round-Robin 타임아웃을 써서 라운드 로빈 방식으로 스케쥴링 한다.
0번 큐가 다 빈 상황에서만 1번 큐의 프로세스를 스케쥴링한다. 즉, N번 큐에 있는 프로세스를 스케쥴링하려면 N-1번 큐 까지 다 비어있어야 한다.
Round-Robin 타임아웃을 사용하기 때문에 타임아웃 간격을 어떻게 하는지에 따라서 response time이 달라질 수 있다.
아애로 내려갈수록 스케쥴링 한 번 되기가 힘들기 때문에 타임 퀀텀을 로 주기도 한다.
타임아웃을 길게 주는 이유
- CPU를 차지하기 굉장히 힘들기 때문
- N-1 번 큐까지 아무도 없는 상태이기 때문에
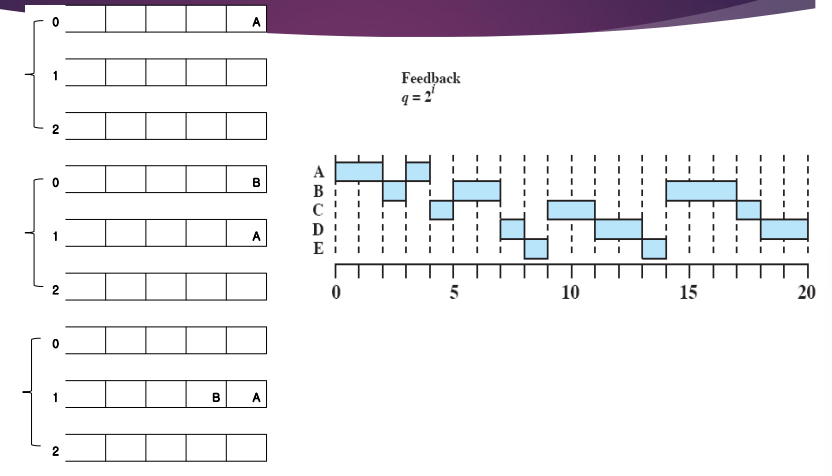
A는 혼자 먼저 도착하므로 실행을 시작하고 1시간이 지나도 A 밖에 없다. 그래서 A는 실행을 게속한다.
이 때 그림을 보면 A는 2시간동안 작업한다. 타임아웃이 2시간인 것이 아니라 1시간을 작업하고 아무도 없어서 작업을 그냥 계속 이어간 것이다. 큐로 들어가지 않는다. OS는 잠깐 끊고 다시 실행을 시킨 것이다.
2시가 됐을 때 타임아웃이 되고 A는 1번 큐로 들어가고 새로 도착한 B는 0번 큐에 있기 때문에 B를 꺼내서 작업한다.
위와 같은 방식으로 프로세스들이 스케쥴링된다.
이런식으로 멀티 레벨 피드백 큐를 사용하게 되면 결국 실행 시간이 긴 프로세스들은 큐 아래쪽으로 내려가게 되어서 CPU를 잡기 힘들어진다.
반면 실행 시간이 짧은 프로세스는 금방 작업하고 쉬었다가 작업하고 끝나게 된다.
대부분의 시스템에서는 멀티 레벨 피드백 큐를 사용한다. 사실상 멀티 레벨 피드백 큐에서 starvation 발생 가능성은 존재한다. 계속 밀려서 제일 아래쪽으로 내려가고, 새로운 프로세스가 계속 들어오면 실행하지 못한다. 그럼에도 사용하는 이유가 뭘까?
사실 BURST time은 굉장히 짧고, I/O 시간은 굉장히 길다. I/O 작업은 몇 초씩 걸리지만 CPU는 나노 세컨드 단위로 작업한다. 그래서 실제로는 대부분의 큐가 비어있다.
대부분의 큐가 비어있고 프로세스들이 갑자기 툭툭 들어오기 때문에 밑으로 내려가더라도 큐가 다 비어서 CPU를 차지할 기회가 온다.
단 최악의 경우 밀리고 밀려서 아래끝까지 내려갔다고 하면 starvation 발생 가능성은 여전히 있다.
그래서 멀티 레벨 피드백 큐를 사용하는 프로세스는 같은 타임 퀀텀을 사용하지 않는다. 왜냐하면 아래 내려가있는 프로세스는 starvation 발생 가능성이 있으므로 한번 CPU를 잡았을 때 최대한 오래 실행을 시켜주려고 한다.
Fair-Share Scheduling
하나의 어플리케이션은 여러 개의 프로세스/쓰레드를 통해 실행된다.
이럴 때 프로세스 단위로 스케쥴링을 하게되면 Fair하지 않다.
따라서 프로세스와 쓰레드의 집합을 스케쥴링 단위로 본다.

Round-Robin 방식으로 스케쥴링한다.
Traditional UNIX Scheduling
- 조금 다른 방식의 Multi Level Feedback Queue 사용
- 같은 우선순위의 큐에서는 Round-Robin 사용
- 1초에 한 번씩 프로세스들의 우선순위를 다시 계산한 후 우선순위에 따라 큐에 삽입
- 그 후 0번 큐에 있는 프로세스부터 Block될 때 까지 처리
- 큐에 한 프로세스만 있으면 FCFS
- 큐에 여러 프로세스가 있으면 RR
- 그 후 0번 큐에 있는 프로세스부터 Block될 때 까지 처리
- 큐의 프로세스가 다 Block
- 다음 큐로 내려가서 작업
우선순위의 기준은 두 가지가 있다.
- 프로세스의 타입
- exceution history
Scheduling Formula

- = 프로세스 j의 i 번째 타임의 우선순위 값
- = 프로세스 j의 타입에 따른 우선순위.
- OS 입장에서는 유저 프로세스들보다 시스템 작업을 하는 프로세스한테 우선순위를 더 크게 준다. 시스템 작업을 하는 프로세스는 아무리 execution history가 나빠도 유저 프로세스보다 더 우선순위가 높게 계산되도록 한다.
- Swapper
- Block I/O device control
- File manipulation
- Character I/O device control
- User Process
- = 유저가 줄 수 있는 값.
- 프로그램 내에서 빨리 실행되어야 하는 프로세스가 존재한다. 이 때 유저가 프로세스의 nice 값을 조정한다. 유저는 우선순위를 낮추는 것만 가능하고, 시스템 관리자는 프로세스들의 우선순위를 낮추고 올릴 수 있다.
위 내용은 프로세스의 기본 우선순위이다. 시간이 지나도 변하지 않는 우선순위 값이다. 반면 CPU 값은 실행을 하면서 계속 변하는 우선순위이다.
- = 프로세스 j의 i 번째 시간의 CPU 값
- = / 2 + / 4 + + / 16 + …
- = 1초 동안 CPU가 스케쥴링하는데, CPU를 사용한 시간
- CPU 값이 크면 P 값이 커진다 ⇒ 우선순위가 낮아진다
- = / 2 + / 4 + + / 16 + …
Traditional UNIX 시스템에서 스케쥴링은
Fairness를 가장 중요하게 생각한다.따라서 starvation 발생 가능성은 없고, 예측 가능성이 상당히 높다.
