My여행 쿼리 개선
쿼리를 신경쓰지 않고 "일단 완성시키자!"에만 집중한 행록팀!
서비스를 론칭한 뒤, 쿼리 개수를 확인해보고 충격을 받고 마는데...
-
My여행 생성시 쿼리 최대 110개...
-
My여행 단일 조회시 쿼리 최대 3800여개...?!
이게 무슨 일이고?
불쌍한 행록은 지금까지 모래 주머니를 차고 영차영차 일하고 있었다...
My여행 생성 쿼리 개선
개선전
My여행 생성시 최악의 경우 쿼리가 110개 나가는 상황이다.
1 :
RefreshTokenRepository에 접근해 접근한 사용자가 회원인지를 판별1 :
MemberRepository에서 멤버 정보 조회1 :
TripRepository에 여행 저장62 :
DayLogRepository에 데이로그 저장(여행당 최대 개수 62개)15 :
CityRepository에서 여행이 도시 조회(여행당 등록 시티 최대 15개)15 :
TripCity생성15 :
TripCity에 여행 정보 업데이트총 110개의 쿼리가 발생한다.
RefreshTokenRepository조회는@Auth가 붙은 인자가 있을 때 ArgumentResolver단에서 접속한 사용자가Anonymous(회원X)인지Member(호원O)인지를 검증하기 위해서 사용되고,MemberRepository조회는@Auth가 생성되기 전 회원인 지를 판별하는 레거시 코드이므로 이 부분은 건너뛰고 개선해보겠다.

개선 과정
DayLog 생성 & TripCity 생성 쿼리 개선
가장 먼저 개선해야할 것은 생성되는 DayLog개수만큼 쿼리가 추가되는 N+1문제였다.
JdbcTemplate의 batchUpdate를 사용해서 하나의 쿼리로 모든 DayLog들을 생성하게 변경했다. JdbcTemplate을 사용해서 DayLog객체들을 저장하는 CustomDayLogRepositoryImpl을 생성했다.
@RequiredArgsConstructor
@Repository
public class CustomDayLogRepositoryImpl implements CustomDayLogRepository {
private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
@Override
public void saveAll(final List<DayLog> dayLogs) {
final String sql = """
INSERT INTO day_log (created_at, modified_at, ordinal, status, title, trip_id)
VALUES (:createdAt, :modifiedAt, :ordinal, :status, :title, :tripId)
""";
namedParameterJdbcTemplate.batchUpdate(sql, getDayLogToSqlParameterSources(dayLogs));
}
private MapSqlParameterSource[] getDayLogToSqlParameterSources(final List<DayLog> dayLogs) {
return dayLogs.stream()
.map(this::getDayLogToSqlParameterSource)
.toArray(MapSqlParameterSource[]::new);
}
private MapSqlParameterSource getDayLogToSqlParameterSource(final DayLog dayLog) {
LocalDateTime now = LocalDateTime.now();
return new MapSqlParameterSource()
.addValue("createdAt", now)
.addValue("modifiedAt", now)
.addValue("ordinal", dayLog.getOrdinal())
.addValue("status", dayLog.getStatus().name())
.addValue("title", dayLog.getTitle())
.addValue("tripId", dayLog.getTrip().getId());
}
}TripCity 생성 쿼리도 같은 방식으로 해결했다.
그냥 spring.jpa.properties.hibernate.jdbc.batch_size=62 할 걸...
City 조회 쿼리 개선
@Query에 where in절을 사용해 여러 개의 City를 한 번에 조회해오게 변경했다.
public interface CityRepository extends JpaRepository<City, Long> {
@Query("""
SELECT c
FROM City c
WHERE c.id in :ids
""")
List<City> findCitiesByIds(@Param("ids") final List<Long> ids);
}TripCity 에 여행 정보 업데이트 쿼리 삭제
15 : TripCity 에 여행 정보 업데이트 문제는 코드상의 문제였다.
기존 여행 생성 코드의 일부이다.
public Long save(final Long memberId, final TripCreateRequest tripCreateRequest) {
...
final Trip newTrip = Trip.of(
member,
generateInitialTitle(cites),
tripCreateRequest.getStartDate(),
tripCreateRequest.getEndDate()
);
saveTripCities(cites, newTrip);
saveDayLogs(newTrip);
return tripRepository.save(newTrip).getId();
}TripCities를 먼저 생성한 뒤, Trip을 생성하는 것을 볼 수 있다.
Trip의 Id생성 전략은 IDENTITY이다. TripCities가 생성되는 시점에는 Trip의 Id가 아직 존재하지 않아 Trip의 Id가 Null로 할당되고, Trip이 저장될 때 TripCities에 Trip의 Id를 업데이트 하는 쿼리가 날아갔다. (아니 PERSIST 옵션도 안줬는데 이게 어떻게 됐지?;;; 연관객체에까지 변경감지가 되나? 진짜 알다가도 모르겠다)
Trip을 먼저 생성한 뒤, TripCities를 생성하는 방식으로 변경해 업데이트 쿼리를 없앴다.
public Long save(final Long memberId, final TripCreateRequest tripCreateRequest) {
...
final Trip newTrip = Trip.of(
member,
generateInitialTitle(cities),
tripCreateRequest.getStartDate(),
tripCreateRequest.getEndDate()
);
final Trip trip = tripRepository.save(newTrip);
saveTripCities(cites, trip);
saveDayLogs(trip);
return trip.getId();
}개선후
1 :
RefreshTokenRepository에 접근해 접근한 사용자가 회원인지를 판별1 :
MemberRepository에서 멤버 정보 조회1 :
TripRepository에 여행 저장62 -> 1 :
DayLogRepository에 데이로그 저장(여행당 최대 개수 62개)15 -> 1 :
CityRepository에서 여행이 도시 조회(여행당 등록 시티 최대 15개)15 -> 1 :
TripCity생성15 -> 0 :
TripCity에 여행 정보 업데이트총 110개의 쿼리 -> 6개의 쿼리

(MethodInterceptor에서 prepareStatement에서 메서드가 실행되는 것을 카운트한 결과이기에 batch insert 쿼리는 카운트되지 않았다. 사실상 6개)
6개의 쿼리... 로 일단 만족하기로 했다. 😂 RefreshToken과 Member 조회는 추후 개선할 예정이다.
Trip, DayLog, City, TripCity는 묶어서 저장할 방법을 모르겠어 그대로 두었다.
My 여행 단일 조회 쿼리 개선
1 :
RefreshTokenRepository에 접근해 접근한 사용자가 회원인지를 판별1 :
MemberRepository에서 멤버 정보 조회1 :
TripRepository에서 여행 조회1:
TripCityRepository에서 여행에 할당된 도시 조회15 :
CityRepository에서 도시 정보 조회 (최대 15개)1 :
DayLog들 조회62 : 해당
DayLog들의 아이템 목록 조회20 61 3 : 아이템 정보 조회 * (장소, 이미지, 경비)
20 1 2 : 기타 항목의 아이템 정보 조회 * (이미지, 경비)
C : 장소와 경비에 할당된 카테고리 개수만큼 조회
최대 3800여개
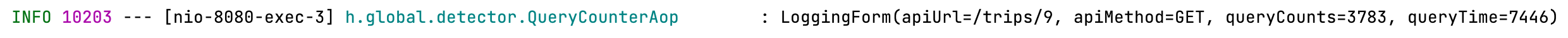
(위 예시는 경비와 장소의 카테고리를 하나로 통일했기에 최악의 쿼리는 아니다.)
fetch join을 통해 Trip + DayLog + Item을 한 번에 조회해오게 변경
@Query에서 fetch join을 사용해 Trip을 조회할 때, DayLog, Item, Image, Expense, Category를 한 번에 조회해오게 변경했다.
public interface TripRepository extends JpaRepository<Trip, Long> {
...
@Query("""
SELECT trip
FROM Trip trip
LEFT JOIN FETCH trip.sharedTrip sharedTrip
LEFT JOIN FETCH trip.dayLogs dayLogs
LEFT JOIN FETCH dayLogs.items items
LEFT JOIN FETCH items.images images
LEFT JOIN FETCH items.expense expense
LEFT JOIN FETCH items.place place
LEFT JOIN FETCH expense.category expense_category
LEFT JOIN FETCH place.category place_category
WHERE dayLogs.trip.id = :tripId
""")
Optional<Trip> findById(@Param("tripId") Long tripId);
}fetch join에는 where, on 절이 필요없다는 것을 이번에 알았다...
-
List<DayLog> dayLogs필드를 Set<DayLog> dayLogs로 변경- 1대다이면서 다 쪽의 객체 타입이 List일 경우 fetch join을 2번 이상하면 MultipleBagFetchException이 터진다. (참고블로그)
- 다 쪽의 객체 타입을 Set으로 변경한다면, MultipleBagFetchException이 발생하지 않는다. 행록의
DayLog와Item객체는 자신의 순서를 나타내는ordinal이라는 필드를 가지고 있기에Set객체로 관리가 되어도 괜찮다고 생각했다.
public class Trip extends BaseEntity { ... @OneToMany(mappedBy = "trip", cascade = {PERSIST, REMOVE, MERGE}, orphanRemoval = true) @OrderBy(value = "ordinal ASC") private Set<DayLog> dayLogs = new HashSet<>(); public Trip( ..., final List<DayLog> dayLogs) { ... this.dayLogs = new HashSet<>(dayLogs); } ... public List<DayLog> getDayLogs() { return new ArrayList<>(dayLogs); // 사이드이펙트를 막기 위해 getter에서 List로 반환 } }
spring.jpa.properties.hibernate.default_batch_fetch_size를 사용해 한 번에 조회를 할 수도 있겠지만 fetch join을 하는 게 쿼리가 더 깔끔해서 이렇게 했다. (
@Query가 길어지긴 하지만...)
개선후
1 :
RefreshTokenRepository에 접근해 접근한 사용자가 회원인지를 판별1 :
MemberRepository에서 멤버 정보 조회1 :
TripRepository에서 여행 조회1 -> 0:
TripCityRepository에서 여행에 할당된 도시 조회15 -> 1:
CityRepository에서 도시 정보 조회 (최대 15개)1 -> 0:
DayLog들 조회62 -> 0: 해당
DayLog들의 아이템 목록 조회20 61 3 -> 0: 아이템 정보 조회 * (장소, 이미지, 경비)
20 1 2 -> 0: 기타 항목의 아이템 정보 조회 * (이미지, 경비)
C -> 0: 장소와 경비에 할당된 카테고리 개수만큼 조회
최대 3800여개 -> 4개

참고
