선형회귀(Linear Regression)
통계학에서, 선형회귀는 종속변수 y와 한 개 이상의 독립변수 x와의 선형 상관관계를 모델링하는 회귀분석 기법이다.
머신러닝에서 독립변수는 보통 feature(특성)이라고 하며 종속변수는 레이블(label) 또는 타겟(target)이라고 한다.
한 개의 설명 변수에 기반한 경우에는 단순 선형회귀, 둘 이상의 설명 변수에 기반한 경우에는 다중 선형 회귀라고 한다.
선형 회귀는 선형 예측 함수를 사용해 회귀식을 모델링하며, 알려지지 않은 파라미터는 데이터로부터 추정한다. 이렇게 만들어진 회귀식을 선형 모델이라고 한다.
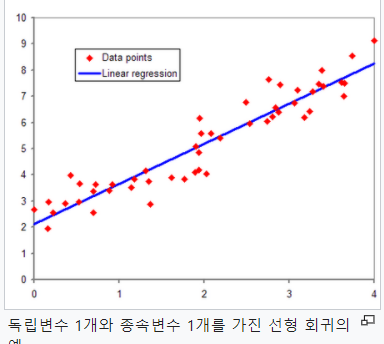
회귀식(회귀직선)을 어떻게 만들 수 있을까?
일반적으로 최소제곱법(least square method)을 사용해 선형 회귀 모델을 세운다. 최소제곱법 외에 다른 기법으로도 선형 회귀 모델을 세울 수 있다. 손실 함수(loss fuction)를 최소화 하는 방식으로 선형 회귀 모델을 세울 수도 있다. 최소제곱법은 선형 회귀 모델 뿐 아니라, 비선형 회귀 모델에도 적용할 수 있다.
회귀분석에서 중요한 개념은 예측값(모델이 추정하는 값)과 잔차(예측값과 관측값의 차이, residual)이다. 회귀선은 잔차 제곱들의 합인 RSS(residual sum of squares)를 최소화 하는 직선이다. 이는 SSE(sum of square error)라고도 한다. 이 RSS 값이 회귀모델의 비용함수(cost function)가 된다. 머신러닝에서는 이렇게 비용함수를 최소화하는 모델을 찾는 과정을 학습이라고 한다.
선형회귀는 주어져 있지 않는 점의 함수값을 보간(interpolate)하여 예측하는 데 도움을 준다. 위 그림에서 실제 존재하지 않는 2.4정도의 x값에 해당하는 y값을 예측할 수 있다.
train데이터와 test데이터로 나누기
우리가 목적은 모델 학습에 사용한 train데이터를 잘 맞추는 모델이 아니라, 학습에 사용하지 않는 데이터를 잘 맞추는 모델.
데이터를 train / test 데이터로 나눠야 모델의 성능을 제대로 평가할 수 있다.
X데이터를 각각 X_train, X_test로 나누고
y데이터를 각각 y_train, y_test로 나눈다.
다음 X_train과 y_train으로 ML 모델을 만들고
X_test를 모델에 넣으면 어떠한 y값이 나온다.
이제 궁금한 건 모델을 통해 나온 y값이 우리가 가지고 있는 y_test와 같은지.
같을수록 모델의 성능이 좋다고 할 수 있다.
그럼 데이터를 어떻게 나눠야 할까?
무작위로 나누는 것이 일반적이지만 시계열데이터를 가지고 과거에서 미래를 예측하려고 하는 경우 무작위로 하면 안 된다. train데이터보다 test데이터가 미래의 것이 되어야 한다.
scikit-learn 을 사용한 선형회귀모델 구현
scikit-learn을 활용해 모델을 만들고 데이터를 분석하기 위해서는 특성행렬 X는 보통 2차원 행렬로, 타겟배열 y는 보통 1차원 형태의 구조를 사용한다.
fit() 메서드를 사용하여 모델을 학습시킬 수 있고 predict() 메서드를 사용하여 새로운 데이터를 예측할 수 있다.
💻Simple linear regression
from sklearn.linear_model import LinearRegression
# 모델 인스턴스 생성
model = LinearRegression()
# X 특성들의 테이블과, y 타겟 백터
feature = ['내가 사용할 특성']
target = ['타겟']
X_train = df[feature]
y_train = df[target]
# 모델 학습
model.fit(X_train, y_train)
# 만들어진 model로 test데이터를 예측
X_test = [[1000]]
y_pred = model.predict(X_test)💻multiple linear regression
from sklearn.metrics import mean_absolute_error
features = ['특성1',
'특성2']
X_train = train[features]
X_test = test[features]
# 모델 학습
model.fit(X_train, y_train)
# 만들어진 모델로 train데이터 예측, 훈련에러
y_pred = model.predict(X_train)
mae = mean_absolute_error(y_train, y_pred)
'''
=> 만들어진 모델에 훈련데이터 X값을 넣어서 y를 예측
그 예측값과 실제 훈련데이터의 y값의 mae 계산(모델 성능)
'''
# test데이터에 적용, 테스트 에러
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
'''
=> 만들어진 모델에 테스트데이터 X값을 넣어서 y를 예측
그 예측값과 실제 테스트데이터의 y값의 mae계산(모델 성능)
'''
'''
모델에는 특성 X값을 넣어서 y를 예측할 수 있고
모델을 통해 나온 y값과 실제 y값(훈련이든 테스트이든)을 비교해 모델 성능 평가
'''Mean Absolute Error(MAE, 평균절대오차) 는 예측 error 의 절대값 평균을 나타냅니다.
모델의 예측값과 실제값의 차이를 모두 더한다는 개념
💻선형회귀모델의 계수
# 계수(coefficient): X가 한 단위 오를 때 y가 얼마나 오르는지
model.coef_
# 절편(intercept)
model.intercept_기준모델
예측 모델을 만들기 전에 간단하게 최소한의 성능을 나타내는 기준이 되는 모델을 말한다.
문제별로 기준모델은 보통 다음과 같이 설정한다
- 회귀문제: 타겟의 평균값
- 분류문제: 타겟의 최빈 클래스
회귀모델 평가지표
- MSE (Mean Squared Error) =
- MAE (Mean absolute error) =
- RMSE (Root Mean Squared Error) =
- R-squared (Coefficient of determination) =
- 참고
- SSE(Sum of Squares
Error, 관측치와 예측치 차이): - SSR(Sum of Squares due to
Regression, 예측치와 평균 차이): - SST(Sum of Squares
Total, 관측치와 평균 차이):, SSE + SSR
- SSE(Sum of Squares
💻평가지표
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# R^2 값이 1에 가까울 수록 데이터를 잘 설명하는 모델관련 https://partrita.github.io/posts/regression-error/
[출처] 위키백과

나도 선형회귀 배웠는데!