목표
python, pandas
1. 서울시 구별 CCTV 현황 데이터 확보
2. 인구 현황 데이터 확보
3. CCTV 데이터와 인구 현황 데이터 합치기
4. 데이터를 정리하고 정렬
Matplotlib
5. 그래프 그리기
Regression using Numpy
6. 전체적인 경향 파악
Insight and Visualization
7. 경향에서 벗어난 데이터 강조
Pandas에서 엑셀 및 텍스트 파일 읽기
- python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가는 스테로이드를 맞은 엑셀로 표현함
모듈 Import
import pandas as pd
- import MODULE : MODULE을 사용하겠다.
- import MODULE as md : MODULE을 사용할건데, 앞으로는 md라는 이름으로 부르겠다
- from MODULE import function : MODULE에 포함된 function 이라는 함수만 사용하겠다.
DataFrame의 구조
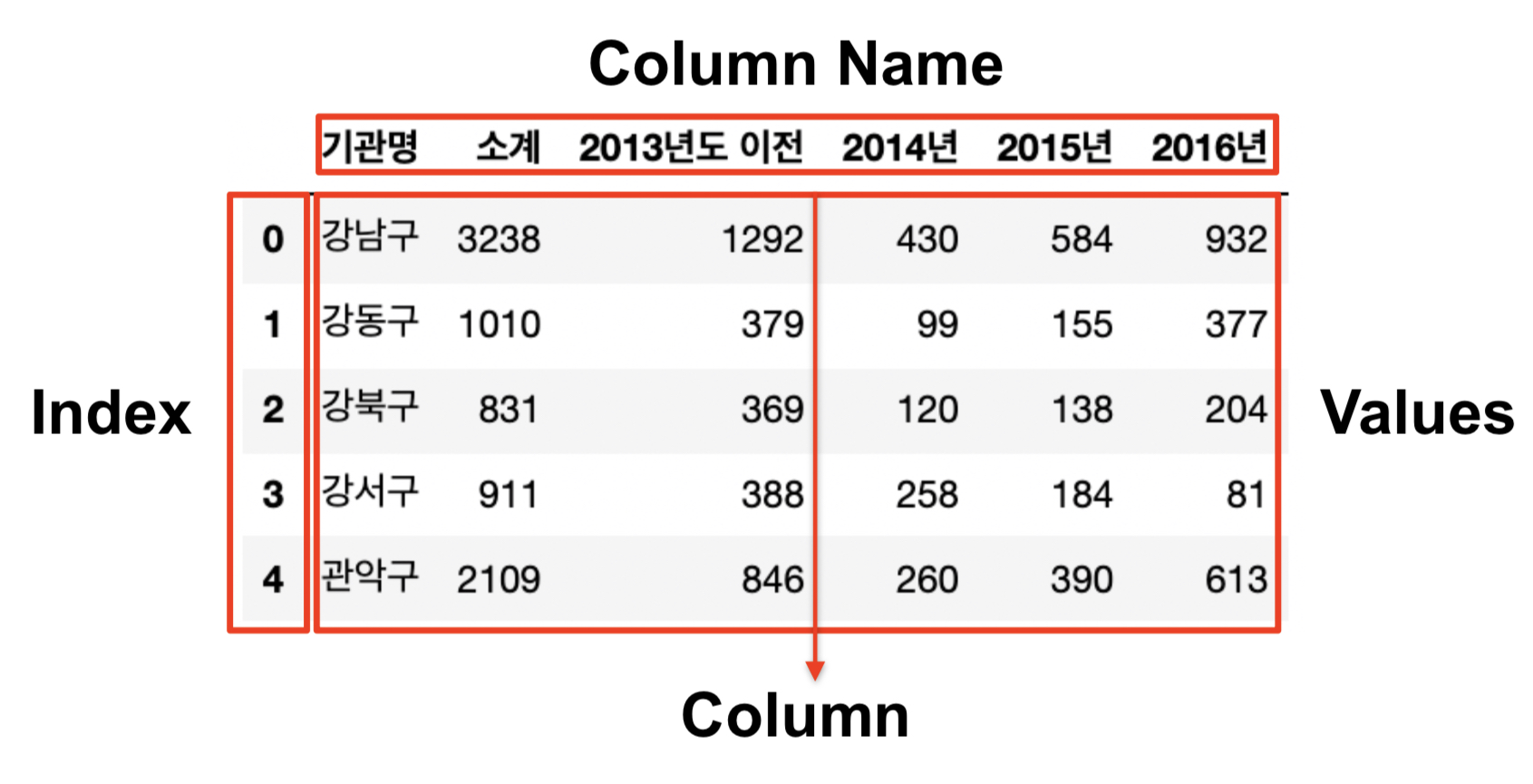
column의 이름 바꾸기
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace = True)
CCTV_Seoul.head()inplace=True를 해줘야지 다음번에 조회를 했을때에도 변경된 column이름으로 확인할 수 있다.
excel 파일 읽기
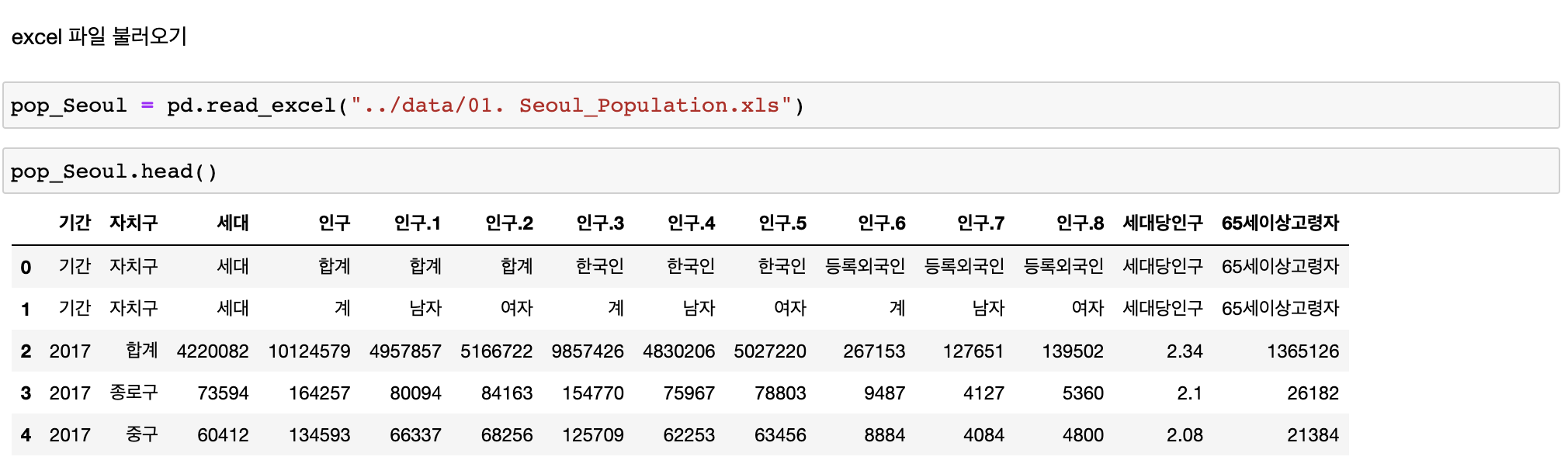
상단 두개의 데이터가 필요없어 보인다.
-> 일단 원본 excel 파일부터 확인

-> 원래 그렇게 만들어진 엑셀 파일이였다.
- 자료를 읽기 시작할 행(header)를 지정
- 읽어올 엑셀의 컬럼을 지정(usecols)
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols="B,D,G,J,N"
)pop_Seoul.rename(
columns={
pop_Seoul.columns[0]: "구별",
pop_Seoul.columns[1]: "인구수",
pop_Seoul.columns[2]: "한국인",
pop_Seoul.columns[3]: "외국인",
pop_Seoul.columns[4]: "고령자"
},
inplace=True
)
pop_Seoul.head()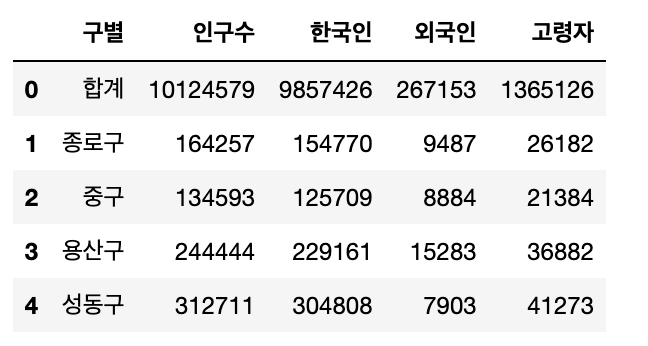
pandas 기초
- pandas는 통상 pd로 import 한다
- 수치해석적 함수가 많은 numpy는 통상 np로 import 한다
- pands의 데이터형을 구성하는 기본은 Series이다.
- 날짜(시간)를 이용할 수 있다.
- pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다.
- index와 columns를 지정하면 된다
-
DataFrame의 index 확인 - df.index
-
DataFrame의 columns 확인 - df.columns
-
DataFrame의 value 확인 - df.values
-
DataFrame의 기본 정보 확인 - df.info : 여기서는 각 column의 크기와 데이터형태를 확인하는 경우가 많다.
-
DataFrame의 통계적 기본 정보를 확인 - df.describe()
-
데이터 정렬
df.sort_values(by="B", ascending=False)- sort_values : 데이터를 정렬
-
특정 컬럼만 읽기 :
df["A"]
df[0:3]
df[n:m] : n부터 m-1까지 (그러나 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함함) -
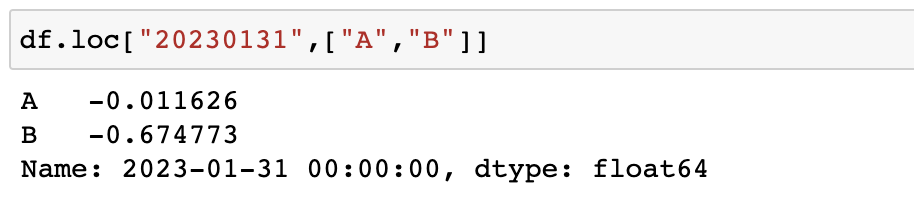
loc
loc : location
index의 이름으로 특정 행이나 열을 선택
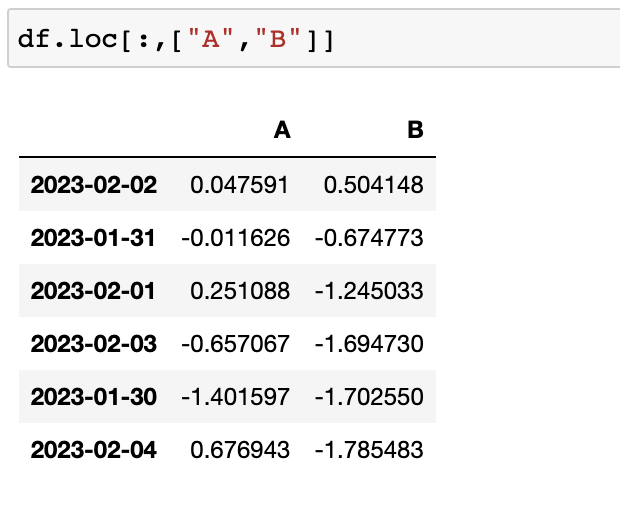
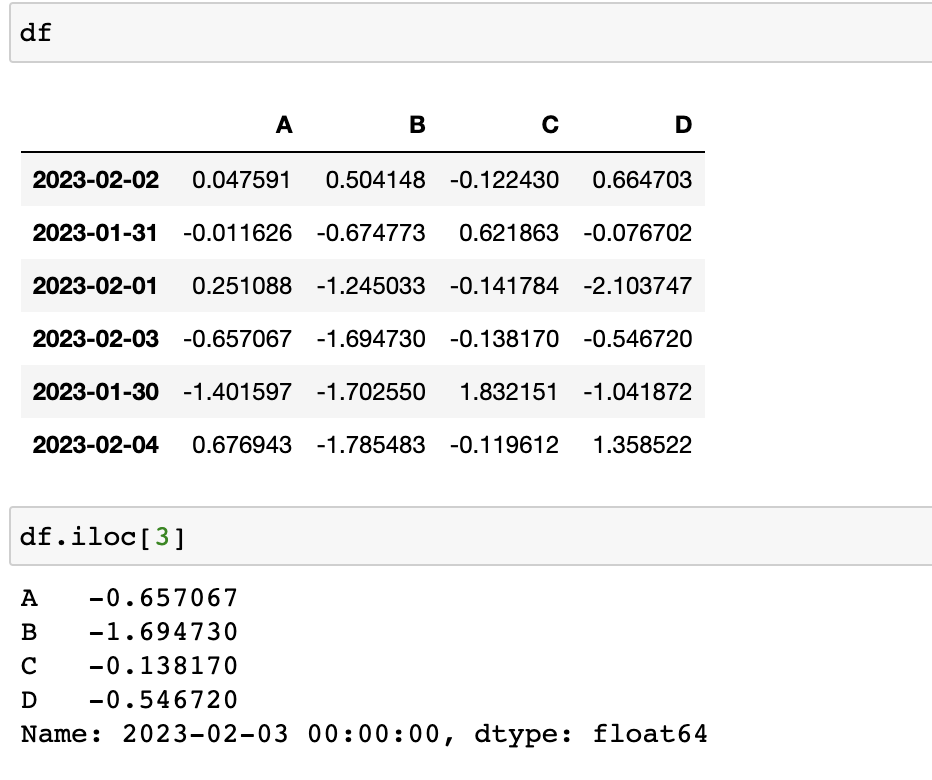
- iloc : inter location
컴퓨터가 인식하는 인덱스값으로 선택
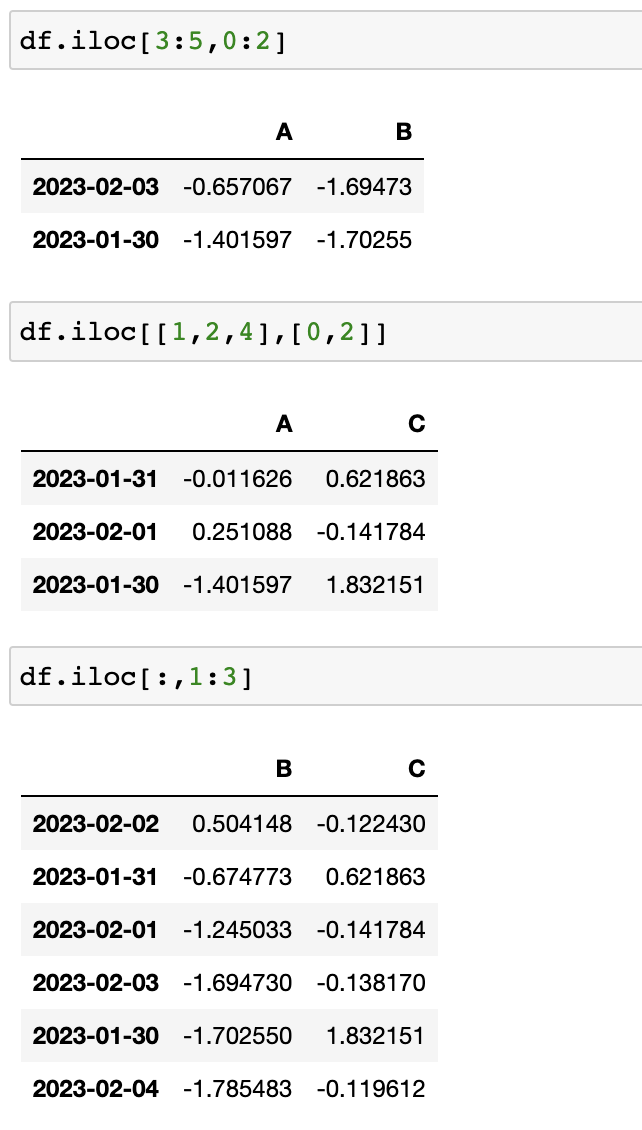
-
A 컬럼의 양수만 보고 싶을 때 :
df[df["A"] > 0] -
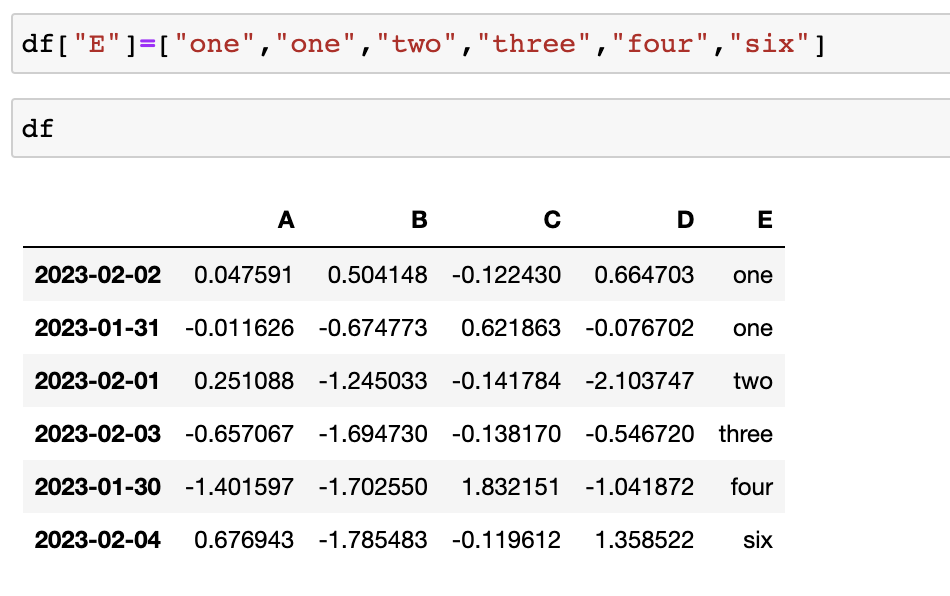
컬럼 추가
기존 컬럼이 없으면 추가
기존 컬럼이 있으면 수정
-
isin() : 특정 요소가 있는지 확인
df["E"].isin(["two","four"]) -
특정 요소가 있는 행만 선택
df[df["E"].isin(["two","four"])] -
특정 컬럼 제거
del df["E"]
- 각 컬럼 누적합
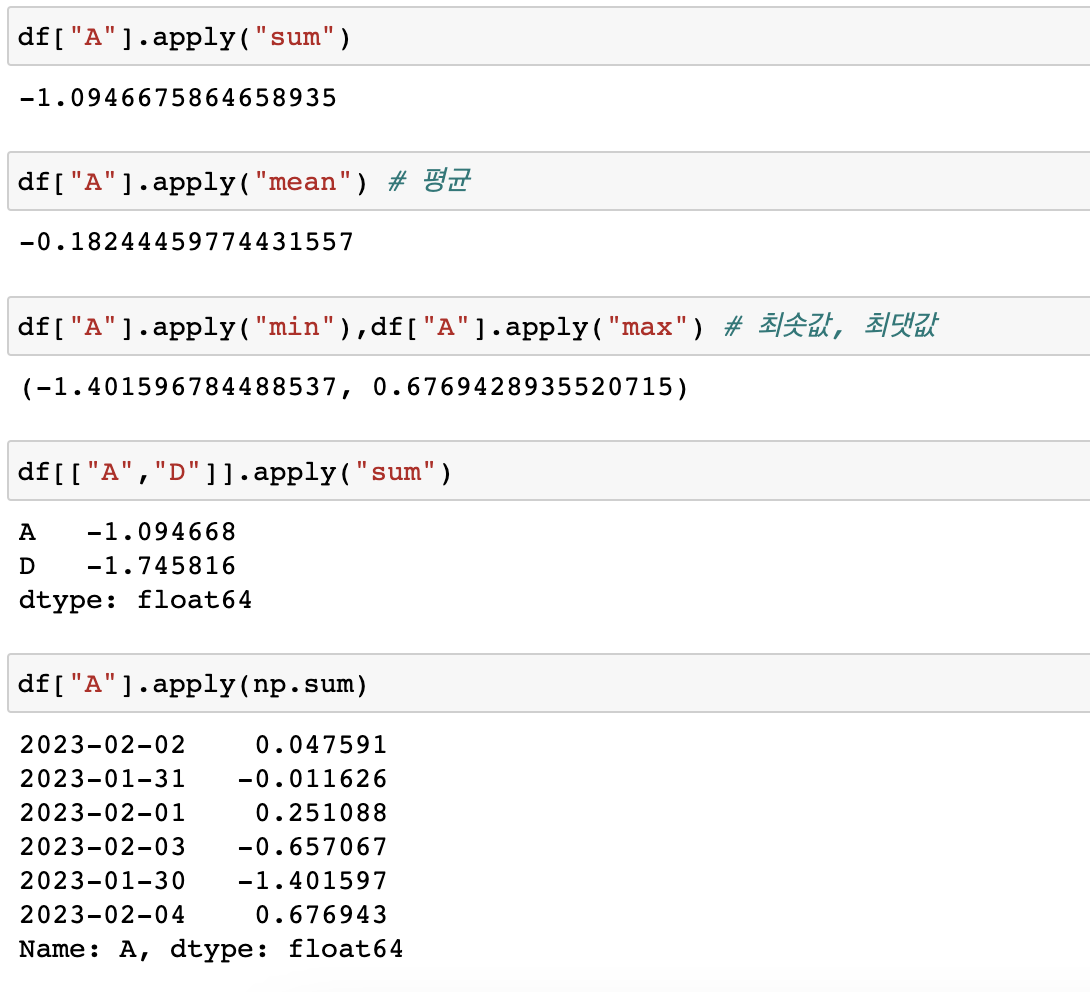
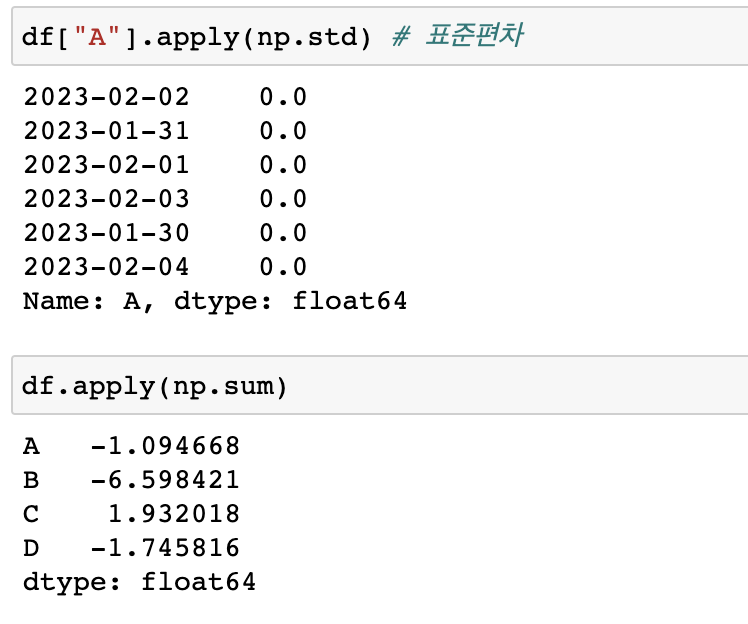
: numpy함수도 사용가능하다
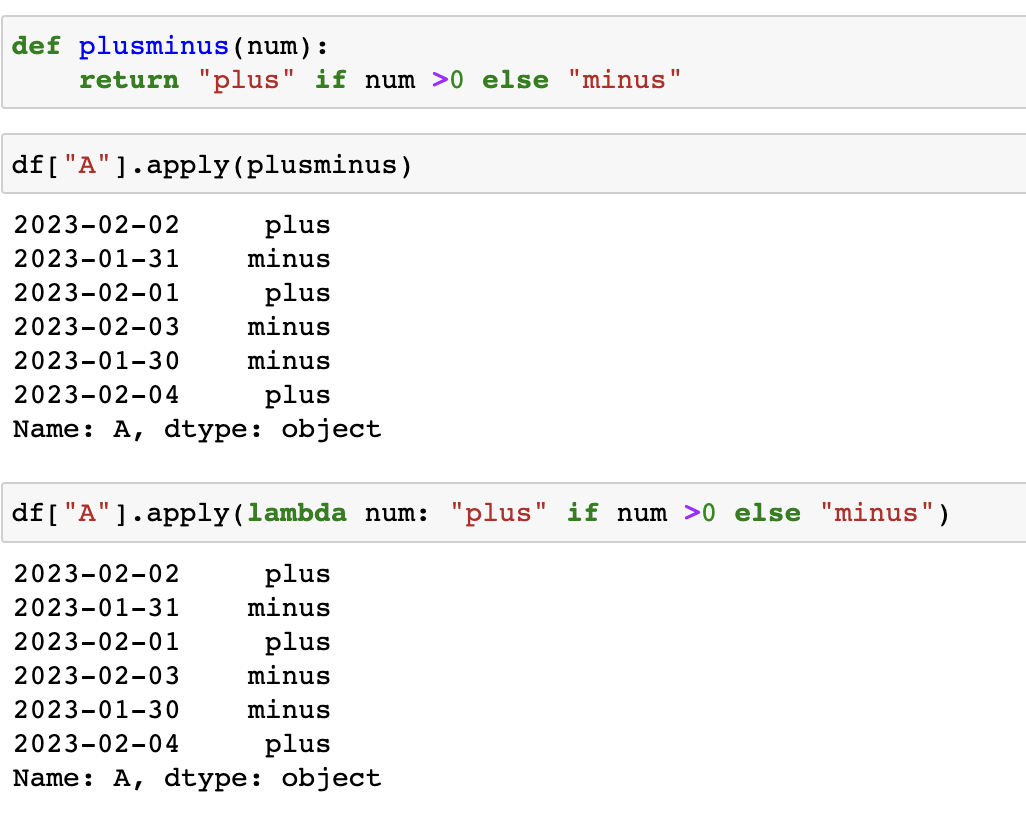
: 함수를 적용해서도 사용가능 하다.
CCTV 데이터 훑어보기
- CCTV를 적게 보유한 구
CCTV_Seoul.sort_values(by="소계", ascending=True).head(5)
(소계를 기준으로 오름차순 다섯개. ascending=True는 디폴트값이라 안써도 된다)
- CCTV를 많이 보유한 구
CCTV_Seoul.sort_values(by="소계", ascending=False).head(5)
- 최근 3년간 그 전 보유한 갯수 대비 CCTV를 많이 설치한 구
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"]+ CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) /CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head(5)
인구현황 데이터 훑어보기
- unique 조사
pop_Seoul["구별"].unique()
len(pop_Seoul["구별"].unique()) : 데이터가 많아지면 unique조사를 통해 데이터를 초반 검증한다.
- 외국인과 고령자 비율 만들기
pop_Seoul["외국인 비율"] = pop_Seoul["외국인"] / pop_Seoul["인구수"] 100
pop_Seoul["고령자 비율"] = pop_Seoul["고령자"] / pop_Seoul["인구수"] 100
pop_Seoul.head()
(컬럼 연산이 편하다는 것이 python의 장점)
- 인구수가 많은 구
pop_Seoul.sort_values(["인구수"],ascending=False).head(5)
- 외국인이 많은 구
pop_Seoul.sort_values(["외국인"],ascending=False).head(5)
- 외국인 비율이 높은 구
pop_Seoul.sort_values(["외국인 비율"],ascending=False).head(5)
두 데이터 합치기
- merge를 이용한 데이터 병합
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 합니다
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 합니다
pd.merge(left,right, on="key")
key 컬럼을 기준으로 병합
how="inner"값이 디폴트값이다. 교집합이라는 뜻
pd.merge(left,right, how="left", on="key")
left에 key를 기준으로 right병합
pd.merge(left,right, how="outer", on="key")
합집합으로 결합하겠다는 뜻
- set_index()
선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index("구별", inplace=True)
data_result.head()
- 우리의 주제는 인구대비 상대적으로 CCTV가 적은 구를 찾는 것
상관관계
두 변량 사이에 한쪽이 증가하면 다른 쪽도 증가(또는 감소)하는 경향이 있을 때,
이 두 변량 사이에는 상관관계가 있다고 함
단, 상관관계가 있다하여 두 변량이 인과관계인 것은 아님
-
0.2이하 : 상관관계가 없거나 무시해도 좋은 수준
-
0.4이하 : 약한 상관관계
-
0.6이상 : 강한 상관관계
-
corr() : 상관계수가 0.2이상인 데이터를 비교
(데이터의 관계를 찾을 때, 최소한의 근거가 있어야 해당 데이터를 비교하는 의미가 존재
상관계수를 조사해서 0.2 이상의 데이터를 비교하는 것은 의미가 있다.)
Matplotlib 기초
- 파이썬의 대표 시각화 도구
- plt로 naming하여 사용한다.
- %matplotlib inline 옵션을 사용한다.
import matplotlib.pyplot as plt
from matplotlib import rc
rc("font", family="Arial Unicode MS")
# %matplotlib inline
get_ipython().run_line_magic("matplotlib","inline")삼각함수 그리기
- np.arange(a,b,s) : a부터 b까지 s의 간격
- np.sin(value)
import numpy as np
t = np.arange(0,12,0.01)
y = np.sin(t)
plt.figure(figsize=(10,6))
plt.plot(t,np.sin(t))
plt.plot(t,np.cos(t))
plt.show()그래프를 예쁘게 그리려면
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(t,np.sin(t))
# plt.plot(t,np.sin(t), label="sin")
plt.plot(t,np.cos(t))
# plt.plot(t,np.sin(t), label="cos")
plt.grid(True)
plt.legend(labels=["sin","cos"]) # 범례
# plt.legend()
plt.title("Example of sinwave")
plt.xlabel("time")
plt.ylabel("Amplitude") # 진폭
plt.show()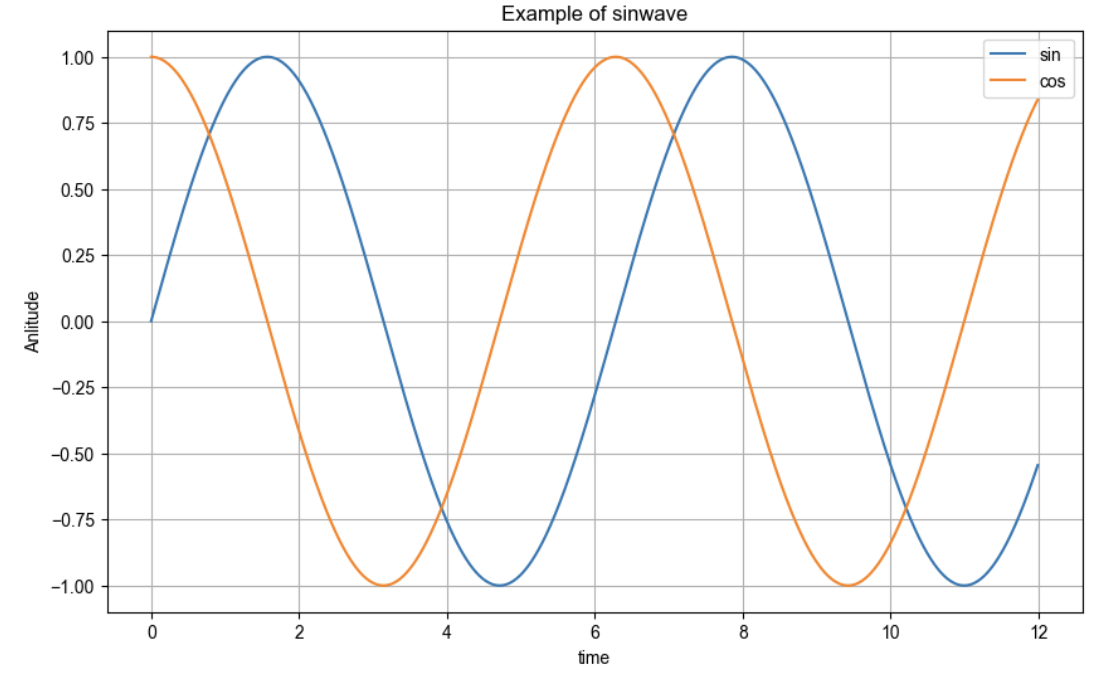
그래프 커스텀
t = np.arange(0, 5, 0.5)
t
plt.figure(figsize=(10,6))
plt.plot(t, t, "r--") # red ---
plt.plot(t, t ** 2, "bs") # blue square
plt.plot(t, t ** 3, "g^") # green triangle
plt.show()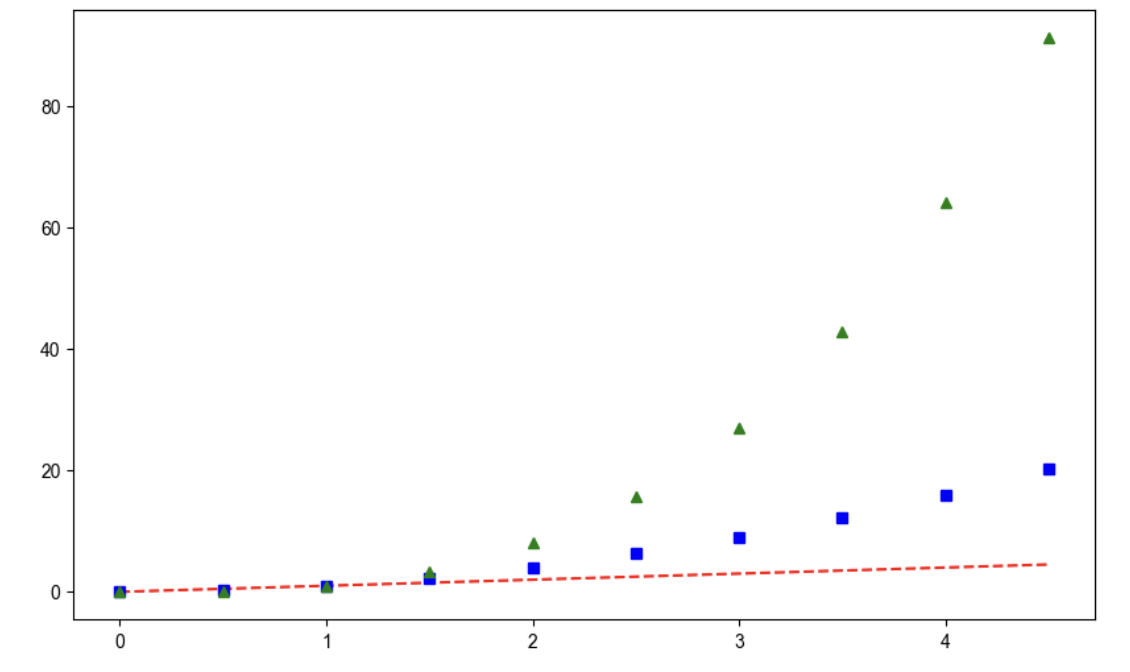
# t = [0, 1, 2, 3, 4, 5, 6]
t = list(range(0,7))
y = [1, 4, 5, 8 ,9, 5, 3]
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(
t,
y,
color = "green",
linestyle = "dashed", # 점선
marker="o", # 포인트마다 동그라미
markerfacecolor="blue",
markersize=15,
)
plt.xlim([-0.5,6.5])
plt.ylim([0.5,9.5])
plt.show()
drawGraph()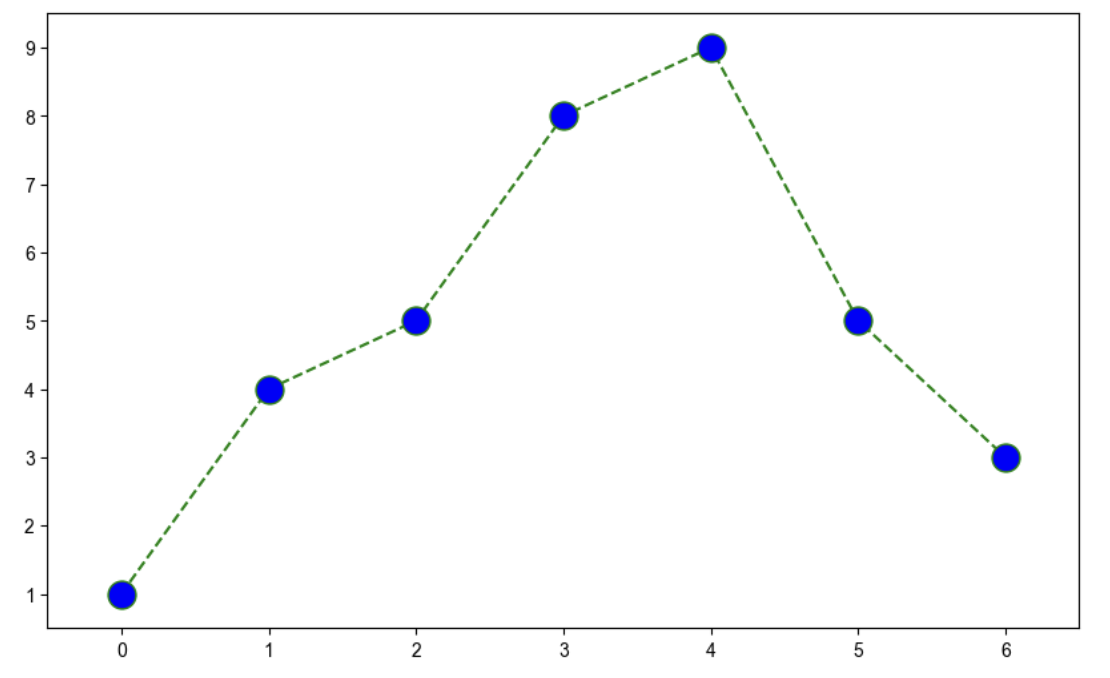
scatter plot
t = np.array(range(0,10))
y = np.array([9,8,7,9,8,3,2,4,3,4])
def drawGraph():
plt.figure(figsize=(10,6))
plt.scatter(t,y)
plt.show()
drawGraph()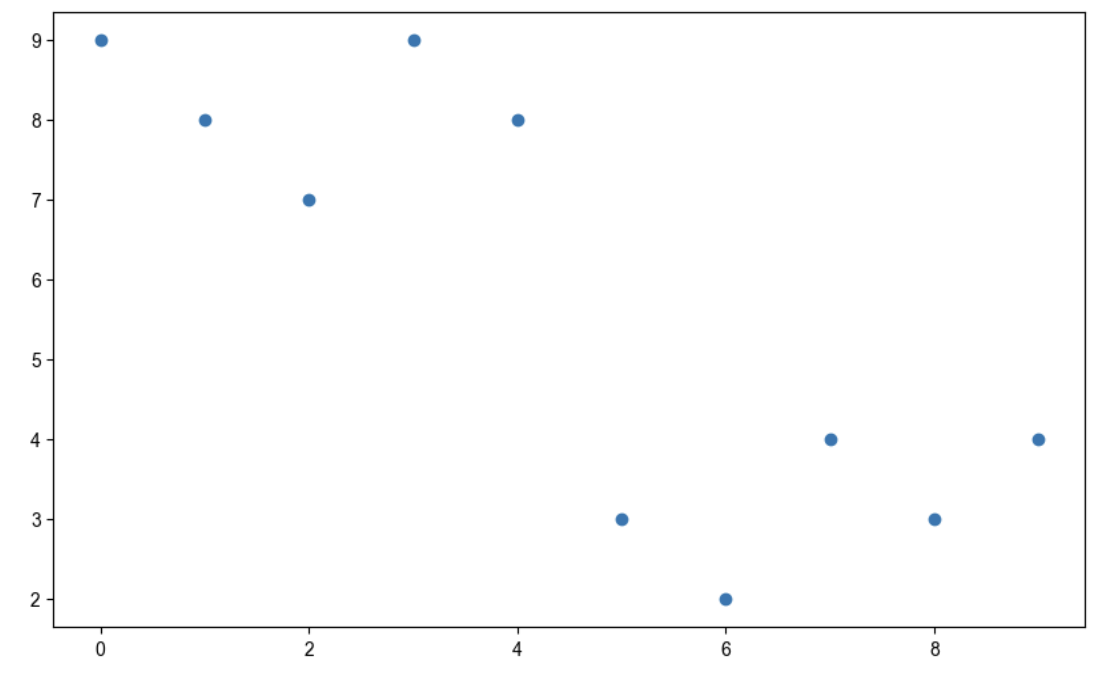
colormap = t
def drawGraph():
plt.figure(figsize=(20,6))
# s : 포인터 사이즈
plt.scatter(t,y, s=100, c=colormap, marker=">")
plt.colorbar()
plt.show()
drawGraph()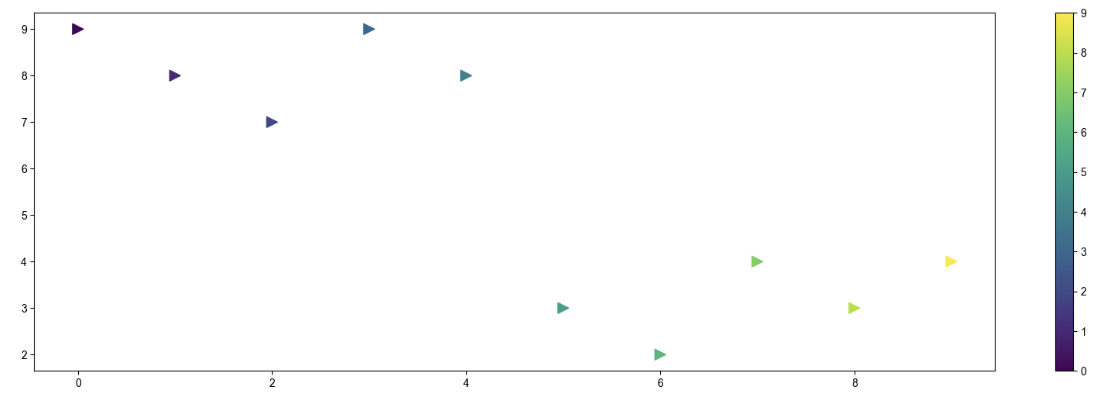
데이터 시각화
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh", grid=True, title="가장 CCTV가 많은 구",figsize=(10,10));
drawGraph()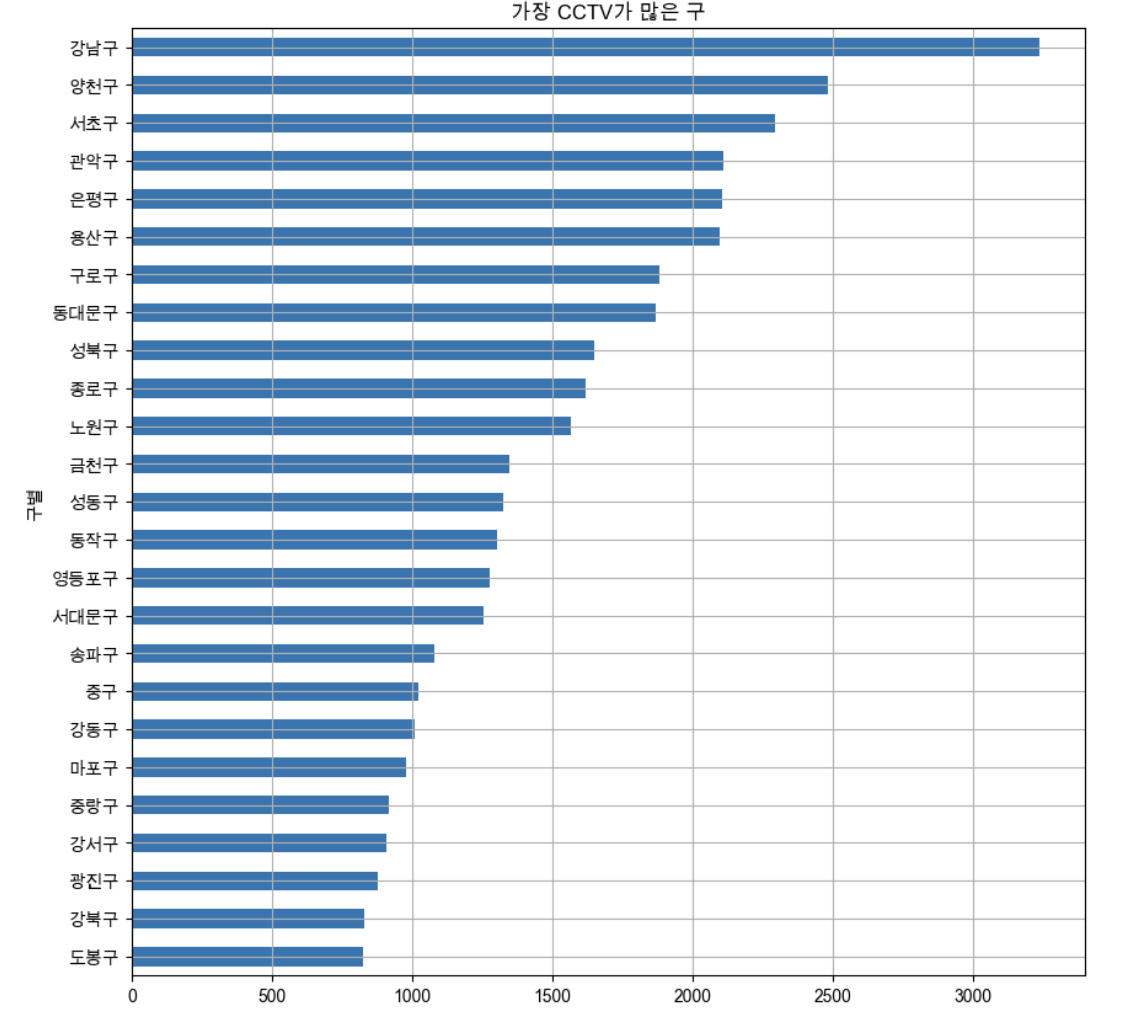
- 데이터(컬럼)가 많은 경우 정렬한 후 그리는 것이 효과적이다.
데이터의 경향 표시
경향을 파악할 필요
- 단순 CCTV수와 인구대비 CCTV 비율을 볼 때
- CCTV 많은 구는 강남, 양천, 서초, 관악, 은평, 용산
- CCTV 비율이 높은 구는 종로, 용산, 중구가 1위 그룹
- 비율로 데이터를 보아도 전체 경향과 함께 보지 않으면 데이터를 제대로 이해시키기 어려울 것 같다
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"],s=50)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()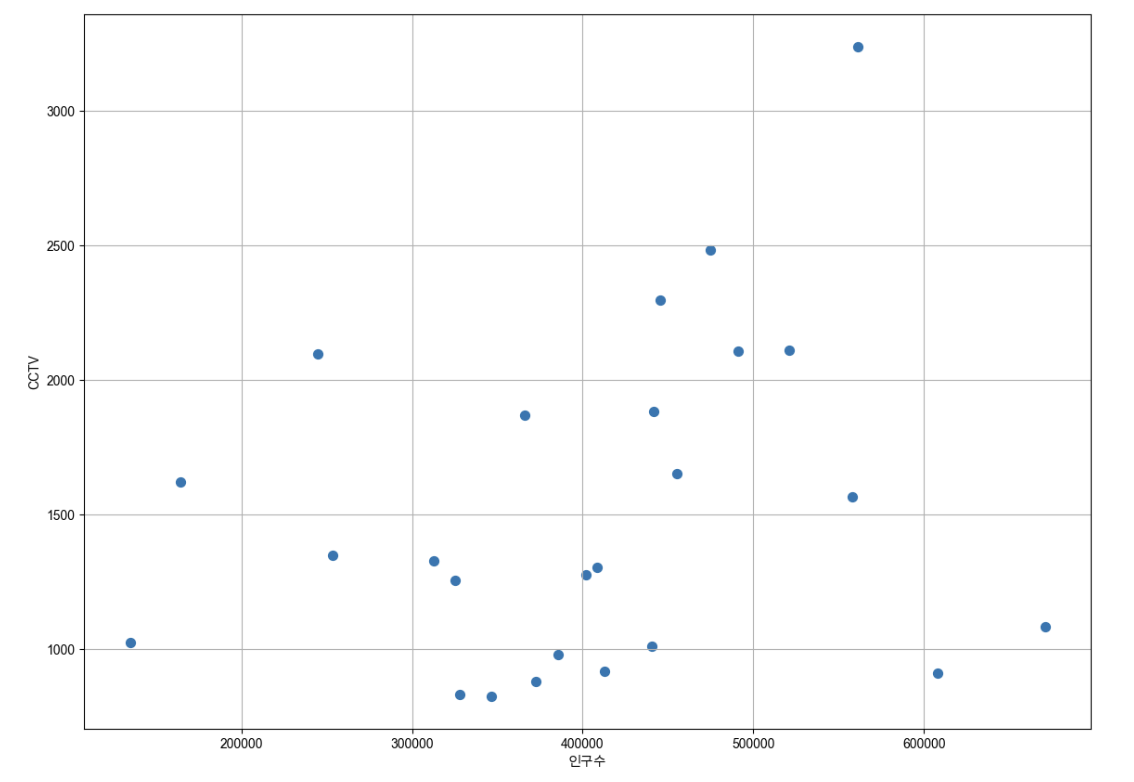
Linear Regression 선형 회귀 (feat.Numpy)
numpy를 이용한 1차 직선 만들기
- np.polyfit() : 직선을 구성하기 위한 계수를 계산
- nplpoly1d() : polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능


- polyfit에서 찾은 계수를 넣어서 함수 완성


- 경향선을 그리기 위해 x 데이터 생성
- np.linspace(a,b,n) : a부터 b까지 n개의 등간격 데이터 생성
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"],s=50)
plt.plot(fx,f1(fx), ls="dashed",lw=3, color="green")
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.grid(True)
plt.show()
drawGraph()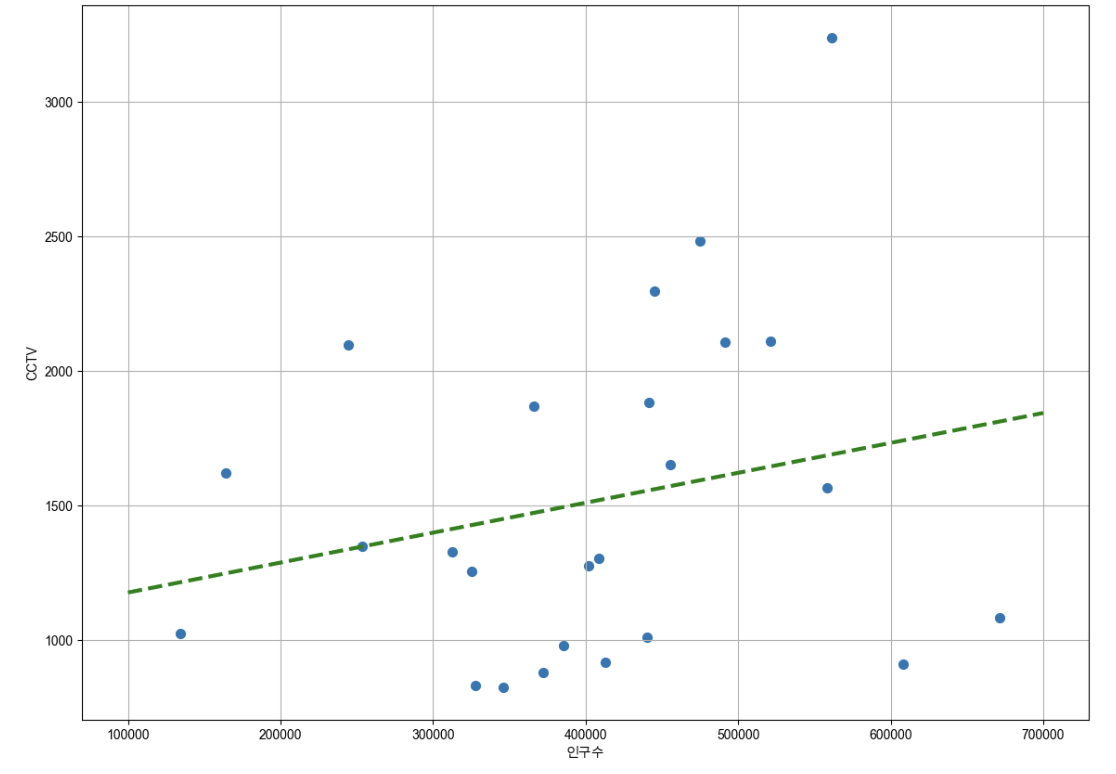
강조하고 싶은 데이터를 시각화
그래프 다듬기
- 경향과의 오차를 만들자
- 경향은 f1 함수에 해당 인구를 입력
- f1(data_result["인구수"])
fp1 = np.polyfit(data_result["인구수"], data_result["소계"],1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
# 경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(by="오차",ascending=False) # 내림차순
df_sort_t = data_result.sort_values(by="오차",ascending=True) # 오름차순
# 경향 대비 CCTV를 많이 가진 구
df_sort_f.head()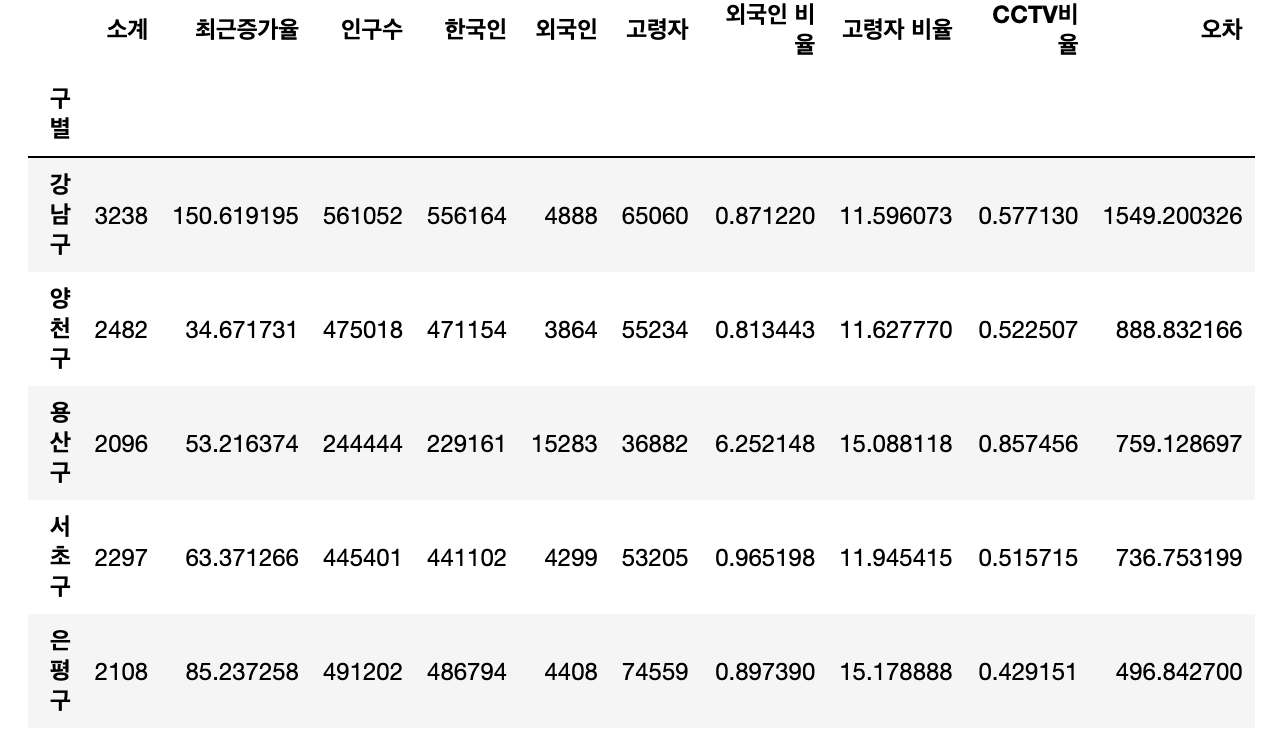
# 경향 대비 CCTV를 적게 가진 구
df_sort_t.head()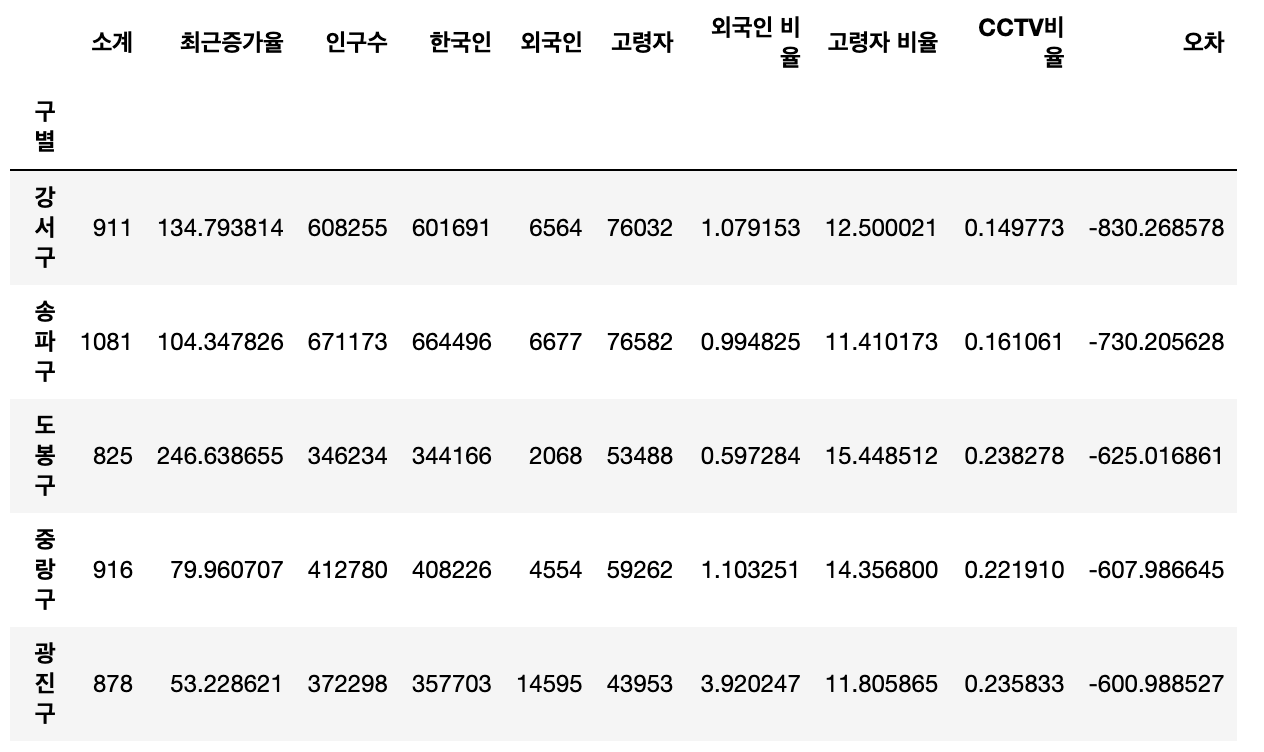
from matplotlib.colors import ListedColormap
# colormap 을 사용자 정의(user define)로 세팅
color_step = ["#e74c3c","#2ecc71","#95a9a6","#2ecc71","#3498db","#3498db"]
my_cmap = ListedColormap(color_step)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"],s=50,c=data_result["오차"],cmap=my_cmap)
plt.plot(fx,f1(fx), ls="dashed",lw=3, color="g")
for n in range(5):
# 상위 5개
plt.text(
df_sort_f["인구수"][n] * 1.02, # x 좌표
df_sort_f["소계"][n] * 0.98, # y 좌표
df_sort_f.index[n], # title
fontsize=15,
)
# 하위 5개
plt.text(
df_sort_t["인구수"][n] * 1.02, # x 좌표
df_sort_t["소계"][n] * 0.98, # y 좌표
df_sort_t.index[n], # title
fontsize=15,
)
plt.text(df_sort_f["인구수"][0] * 1.02, df_sort_f["소계"][0]*0.98,df_sort_f.index[0], fontsize=15)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()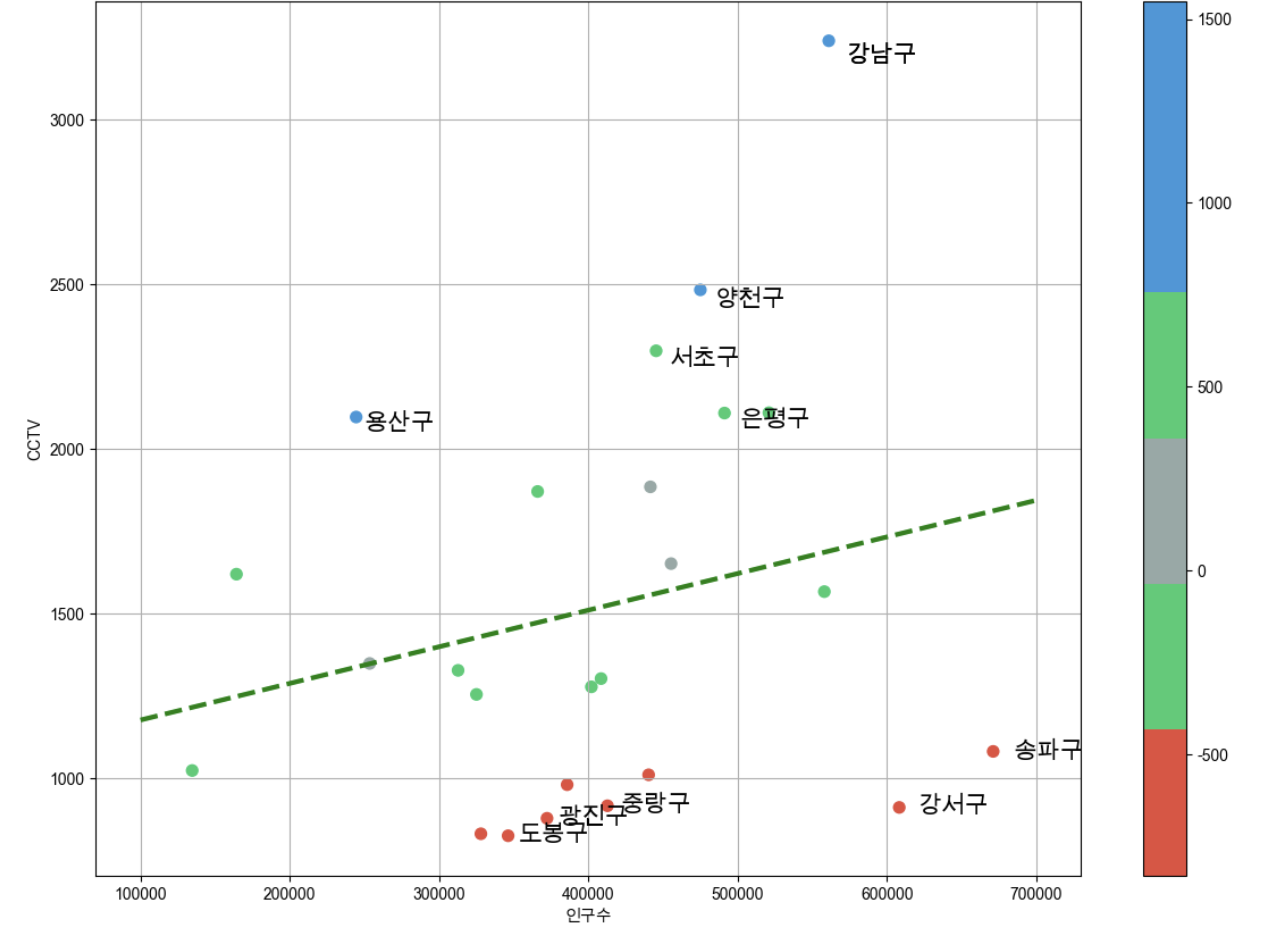
- s : 마커의 크기
- c : color 세팅에 방금 계산한 경향과의 오차를 적용
- cmap : 사용자 정의한 맵을 적용
- 오차가 큰 데이터 아래 위로 5개씩만 특별히 마커 옆에 구 이름을 명시
- text : 그래프에 글자를 그리는 명령
- plt.text(X,Y,Text,설정)
- x,y 데이터에 1.02, 0.98을 곱한 이유?
- 구 이름이 마커에 겹치지 않도록 살짝 거리를 두게 하는 의도
데이터 저장
data_result.to_csv("../data/01. CCTV_result.csv", sep=",", encoding="utf-8")