Quantization 을 하기 위해서는 tensor의 min, max
target bitwidth 의 qmin, qmax 가 필요하다.
r : real value
q : quantized value
s : scale
z : zero-point offset (real value가 0
r = (q + z) * scale
q = r / scale - z
scale = (max - min) / (qmax - qmin)
z = -qmin + min / scale
위 공식으로 구할 수 있음.
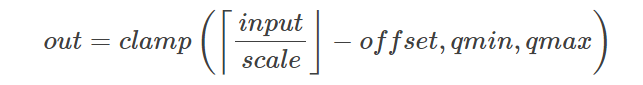
import aimet_torch.v2.quantization as Q
torch.manual_seed(0)
input = torch.randn(4, 4)
print(input)
"""
tensor([[-1.1258, -1.1524, -0.2506, -0.4339],
[ 0.8487, 0.6920, -0.3160, -2.1152],
[ 0.3223, -1.2633, 0.3500, 0.3081],
[ 0.1198, 1.2377, 1.1168, -0.2473]])
"""
i_min = input.min()
i_max = input.max()
q_min = 0
q_max = 255
r_scale = (input.max() - input.min()) / 255
r_offset = torch.round(input.min() / r_scale)
q = Q.affine.Quantize(shape=(1,), bitwidth=8, symmetric=False, block_size=None)
with q.compute_encodings():
_ = q(input)
print("min : ", input.min(), q.get_min())
print("max : ", input.max(), q.get_max())
print("scale : ", r_scale, q.get_scale())
print("offset : ", r_offset, q.get_offset())
"""
min : tensor(-2.1152) tensor([-2.1169], grad_fn=<MulBackward0>)
max : tensor(1.2377) tensor([1.2360], grad_fn=<MulBackward0>)
scale : tensor(0.0131) tensor([0.0131], grad_fn=<DivBackward0>)
offset : tensor(-161.) tensor([-161.], grad_fn=<_StraightThroughEstimatorBackward>)
"""
regacy_qx = input / r_scale - r_offset
regacy_qx = torch.round(regacy_qx)
regacy_qx = regacy_qx.clamp(q_min, q_max)
print(regacy_qx)
print(q(input))- min, max 값에 차이가 있는데, quantize-dequantize 했을때 발생하는 noise 를 보정한 값을 사용함.
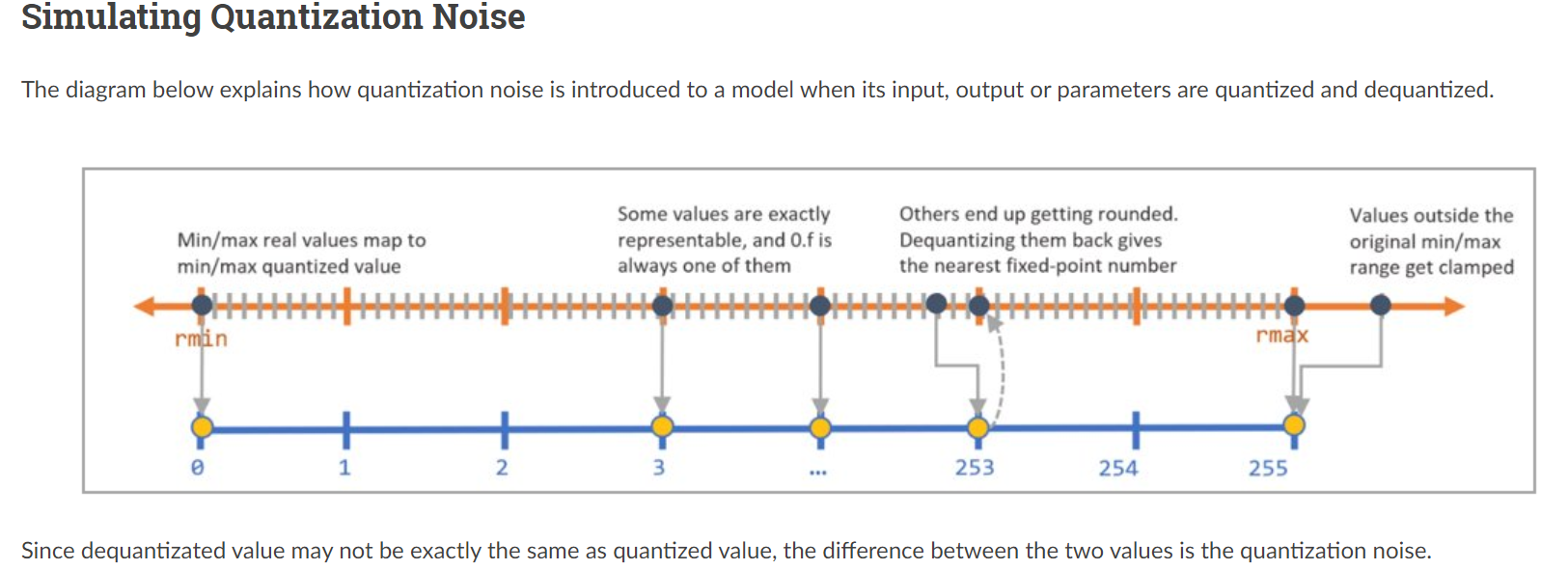
- 다시 dequantize 후 min, max값을 보면 aimet 결과와 같음을 알 수 있음.
deq_x = (regacy_qx + r_offset) * r_scale print(deq_x) print(deq_x.min(), deq_x.max()) """ tensor([[-1.1308, -1.1571, -0.2498, -0.4339], [ 0.8547, 0.6969, -0.3156, -2.1169], [ 0.3287, -1.2623, 0.3550, 0.3024], [ 0.1183, 1.2360, 1.1176, -0.2498]]) tensor(-2.1169) tensor(1.2360) """
@@signed = True
signed = True로 encoding을 진행하면, [0, 255] 였던 q range가 [-128, 127]로 변함.
i_min = input.min()
i_max = input.max()
q_min = -128
q_max = 127
r_scale = (i_max - i_min) / 255
r_offset = torch.round(-q_min + i_min / r_scale)
q = Q.affine.Quantize(shape=(1,), bitwidth=8, symmetric=False, block_size=None)
q.signed=True
with q.compute_encodings():
print("min : ", input.min(), q.get_min())
print("max : ", input.max(), q.get_max())
print("scale : ", r_scale, q.get_scale())
print("offset : ", r_offset, q.get_offset())
"""
min : tensor(-2.1152) tensor([-2.1169], grad_fn=<MulBackward0>)
max : tensor(1.2377) tensor([1.2360], grad_fn=<MulBackward0>)
scale : tensor(0.0131) tensor([0.0131], grad_fn=<DivBackward0>)
offset : tensor(-33.) tensor([-33.], grad_fn=<AddBackward0>)
"""
_ = q(input) 마찬가지로, qmin, qmax 값만 바꿔서 직접 구할 수 있음.
offset 은 -qmin + min/scale 로 추측할 수 있다.
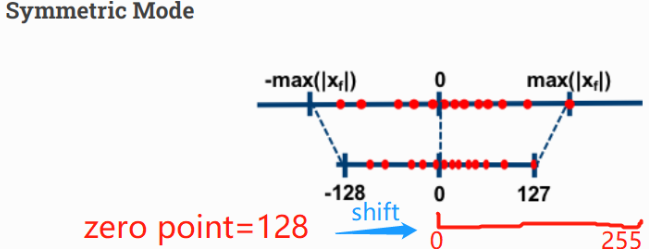
@@symmetric = True
Z 값이 0이 되도록 shift하는 옵션.
즉, real vlaue 의 0 인 지점 Z가, quantizaed value에서도 0을 나타냄.
-> 0을 기준으로 양옆의 range가 symmetric 하게 됨.
import aimet_torch.v2.quantization as Q
torch.manual_seed(0)
input = torch.randn(4, 4)
print("x")
print(input)
print("---------------------------------------------")
i_min = input.min()
i_max = input.max()
q_min = -128
q_max = 127
r_scale = input.abs().max() / 128
r_offset = torch.round(-q_min + i_min / r_scale)
q = Q.affine.Quantize(shape=(1,), bitwidth=8, symmetric=False, block_size=None)
q.symmetric=True
q.signed=True
with q.compute_encodings():
_ = q(input)
print("parameters")
print("min : ", input.min(), q.get_min())
print("max : ", input.max(), q.get_max())
print("scale : ", r_scale, q.get_scale())
print("offset : ", r_offset, q.get_offset())
print("---------------------------------------------")
regacy_qx = input / r_scale - r_offset
regacy_qx = torch.round(regacy_qx)
regacy_qx = regacy_qx.clamp(q_min, q_max)
print("outputs")
print(regacy_qx)
print("-----")
print(q(input))
print("---------------------------------------------")
print("dequantized")
deq_x = (regacy_qx + r_offset) * r_scale
print(deq_x)
print(deq_x.min(), deq_x.max())
print((q_min + r_offset) * r_scale, (q_max + r_offset) * r_scale)
print("---------------------------------------------")
"""
x
tensor([[-1.1258, -1.1524, -0.2506, -0.4339],
[ 0.8487, 0.6920, -0.3160, -2.1152],
[ 0.3223, -1.2633, 0.3500, 0.3081],
[ 0.1198, 1.2377, 1.1168, -0.2473]])
---------------------------------------------
parameters
min : tensor(-2.1152) tensor([-2.1152], grad_fn=<MulBackward0>)
max : tensor(1.2377) tensor([2.0987], grad_fn=<MulBackward0>)
scale : tensor(0.0165) tensor([0.0165], grad_fn=<DivBackward0>)
offset : tensor(0.) tensor([0.])
---------------------------------------------
outputs
tensor([[ -68., -70., -15., -26.],
[ 51., 42., -19., -128.],
[ 20., -76., 21., 19.],
[ 7., 75., 68., -15.]])
-----
QuantizedTensor([[ -68., -70., -15., -26.],
[ 51., 42., -19., -128.],
[ 20., -76., 21., 19.],
[ 7., 75., 68., -15.]], grad_fn=<AliasBackward0>)
---------------------------------------------
dequantized
tensor([[-1.1237, -1.1568, -0.2479, -0.4297],
[ 0.8428, 0.6941, -0.3140, -2.1152],
[ 0.3305, -1.2559, 0.3470, 0.3140],
[ 0.1157, 1.2394, 1.1237, -0.2479]])
tensor(-2.1152) tensor(1.2394)
tensor(-2.1152) tensor(2.0987)
---------------------------------------------
"""
- q.get_min(), q.get_max() 는 quantized range의 min,max값을 dequantize 한 값과 같음을 알 수 있음.
@@ symmetric = True, Signed = False
real value = 0 을 기준으로 양 옆을 같은 range로 quantize 함.
하지만 quantized Zero point = 0.
따라서 real value 의 음수 부분은 모두 0으로 quantize 된다.
import aimet_torch.v2.quantization as Q
torch.manual_seed(0)
input = torch.randn(4, 4)
print("x")
print(input)
print("---------------------------------------------")
i_min = input.min()
i_max = input.max()
q_min = 0
q_max = 255
r_scale = input.abs().max() / 128
r_offset = 0 # torch.round(-q_min + i_min / r_scale)
q = Q.affine.Quantize(shape=(1,), bitwidth=8, symmetric=False, block_size=None)
q.symmetric=True
q.signed=False
with q.compute_encodings():
_ = q(input)
print("parameters")
print("min : ", input.min(), q.get_min())
print("max : ", input.max(), q.get_max())
print("scale : ", r_scale, q.get_scale())
print("offset : ", r_offset, q.get_offset())
print("q_offset: " , q_offset)
print("---------------------------------------------")
regacy_qx = input / r_scale - r_offset
regacy_qx = torch.round(regacy_qx)
regacy_qx = regacy_qx.clamp(q_min, q_max)
print("outputs")
print(regacy_qx)
print("-----")
print(q(input))
print("---------------------------------------------")
print("dequantized")
deq_x = (regacy_qx + r_offset) * r_scale
print(deq_x)
print(deq_x.min(), deq_x.max())
print((q_min + r_offset) * r_scale, (q_max + r_offset) * r_scale)
print("---------------------------------------------")
"""output
x
tensor([[-1.1258, -1.1524, -0.2506, -0.4339],
[ 0.8487, 0.6920, -0.3160, -2.1152],
[ 0.3223, -1.2633, 0.3500, 0.3081],
[ 0.1198, 1.2377, 1.1168, -0.2473]])
---------------------------------------------
parameters
min : tensor(-2.1152) tensor([0.], grad_fn=<MulBackward0>)
max : tensor(1.2377) tensor([4.2139], grad_fn=<MulBackward0>)
scale : tensor(0.0165) tensor([0.0165], grad_fn=<DivBackward0>)
offset : 0 tensor([0.])
q_offset: tensor(-128.)
---------------------------------------------
outputs
tensor([[ 0., 0., 0., 0.],
[51., 42., 0., 0.],
[20., 0., 21., 19.],
[ 7., 75., 68., 0.]])
-----
QuantizedTensor([[ 0., 0., 0., 0.],
[51., 42., 0., 0.],
[20., 0., 21., 19.],
[ 7., 75., 68., 0.]], grad_fn=<AliasBackward0>)
---------------------------------------------
dequantized
tensor([[0.0000, 0.0000, 0.0000, 0.0000],
[0.8428, 0.6941, 0.0000, 0.0000],
[0.3305, 0.0000, 0.3470, 0.3140],
[0.1157, 1.2394, 1.1237, 0.0000]])
tensor(0.) tensor(1.2394)
tensor(0.) tensor(4.2139)
---------------------------------------------
"""- Relu 가 적용되는 효과로 사용할 수 있나?

개발 0부