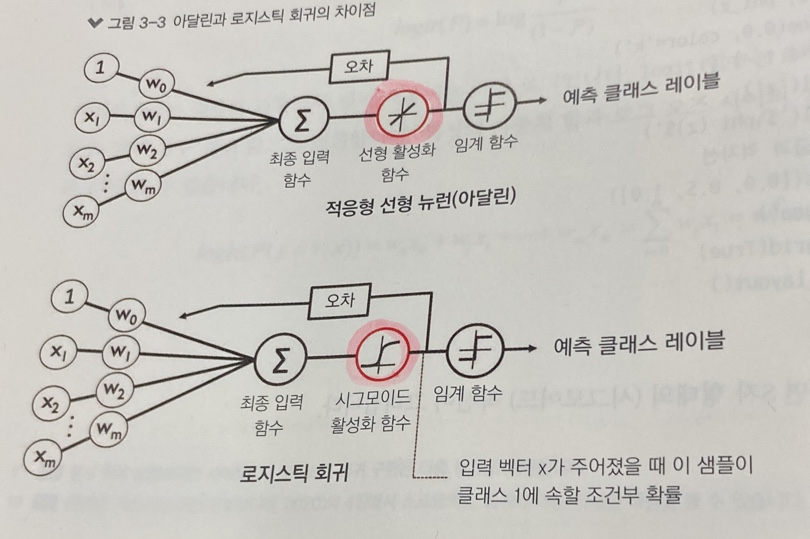
- 입력 변수에 대한 가중합을 시그모이드 함수에 통과시켜 확률값을 예측하고, 이를 기반으로 이진 분류 문제를 해결하는 통계적 모델
- 이진 분류를 위한 선형모델이기도 함.
시그모이드 함수
[정의]
- 이진 분류에서 입력값을 0과 1 사이의 확률 값으로 변환하는 S자 형태의 비선형 함수
[특징]
- 지수 함수: 시그모이드 함수는 지수 함수의 형태를 기반으로 하기 때문에, 출력값이 느리게 변화하다가 일정 시점(함수의 출력값이 중간값인 0.5를 중심으로 급격하게 변화)에서 급격히 변화하는 특징을 가짐. 이로 인해 그래프가 S자 형태! 참고로 지수함수는 로그함수의 역!! 로그 함수는 작은 값에서는 느리게 증가하고, 큰 값에서는 급격하게 증가하는 성질을 가지고 있음. 시그모이드 함수도 입력값이 작을 때는 출력이 0에 가까워지고, 큰 값에서는 출력이 1에 가까워짐
- 비선형성: 이 특성은 분류 문제에서 이진 분류를 할 때 매우 유용. 중간 값에서 출력이 빠르게 변하면서, 예측을 확률적으로 해석할 수 있음.
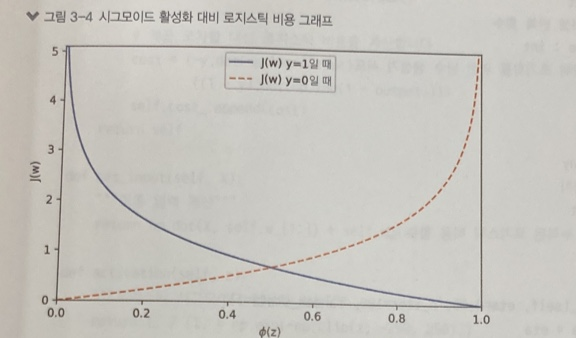
[시그모이드 활성화 대비 로지스틱 비용 그래프]
- 클래스 1에 속한 샘플을 정확히 예측하면 비용이 0에 수렴(실선)
- 클래스 0에 속한 샘플을 정확히 예측하면 비용이 0에 수렴(점선)
->> 예측이 잘못되면 비용은 무한대~ 잘못된 예측은 점점 더 큰 비용 발생!
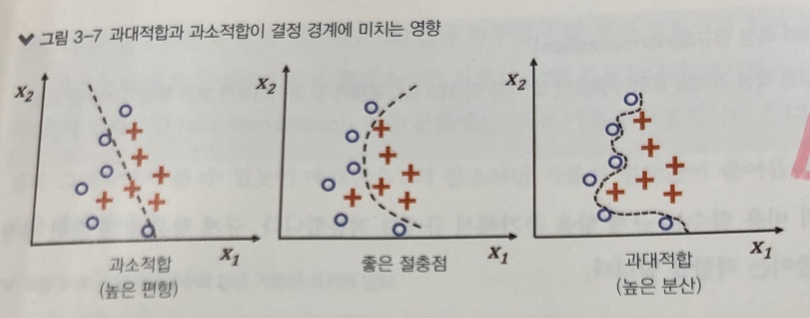
과대 적합(높은 분산)과 과소 적합(높은 편향)
-
과대적합은 모델이 훈련 데이터에 너무 잘 맞춰져서 높은 분산을 가지며, 새로운 데이터에 대한 일반화 능력 떨어지는 현상. 즉, 모델이 훈련 데이터에 지나치게 적합하여 예측력 ↓
- 분산: 모델이 훈련 데이터가 조금만 달라져도 예측이 크게 변하는 정도. 여러 번 훈련했을 때, 특정 샘플에 대한 예측의 일관성(변동성)
-
과소적합은 모델이 훈련 데이터를 충분히 학습하지 못해 높은 편향을 가지며, 데이터의 패턴을 잘 포착하지 못하는 현상입니다. 즉, 모델이 너무 간단하여 훈련 데이터에 잘 맞지 않고 예측력 ↓
- 편향: 모델이 훈련 데이터의 패턴을 제대로 학습하지 못하는 정도를 의미. 예측값이 얼마나 정확한 값에서 벗어났는지의 정도.

정리하는게 공부가 될 지 모르겠지만, 정리를 하면 마음만큼은 편해