모델 성능 평가 방법
1. 홀드아웃 교차 검증
- 일반화 성능 추정 방법
- 초기 데이터셋을 별도의 훈련데이터셋과 테스트 데이터셋으로 분리하여 훈련 세트로 모델을 학습시키고 테스트 세트로 모델 성능을 평가하는데 사용하는 기법
- 가장 좋은 방법은 훈련/검증/테스트 데이터셋 3개로 나누는 것.
- 단점: 데이터 분할 방식에 민감 -> 성능 평가에 큰 영향을 줄 수도
2. k-겹 교차 검증
- 훈련 데이터셋을 k개의 폴드로 랜덤하게 나눔. k-1개의 폴드로 모델을 훈련하고 나머지 하나의 폴드로 성능 평가. 이 과정을 k번 반복하여 모델 성능 평가하는 기법
- 폴드는 중복 없이 독립적으로 구성. -> 중복을 허용하지 않는 리샘플링 기법. -> 테스트 폴드로써 검증에 딱 한 번 사용되는 장점 有
왜 검증에 1번 사용되는게 장점일까?
평가가 공정해진다! 특정 데이터 포인트가 검증 세트로 여러 번 사용되거나 아예 사용되지 않으면 평가 결과가 편향될 수 있음!
또한 모델이 다양한 샘플에 대해 얼마나 잘 일반화하는지 평가하는 것이 교차 검증의 목표! 여러 번 사용되면, 모델이 이미 익숙한 데이터를 검증할 가능성이 생겨 실제 성능을 과대평가할 위험이!
학습 곡선
-
훈련 데이터 크기에 따라 훈련 성능과 검증 성능을 보여주는 그래프 (즉 분석 대상: 데이터의 양)
-
목적: 모델이 과대적합인지 과소적합인지 확인
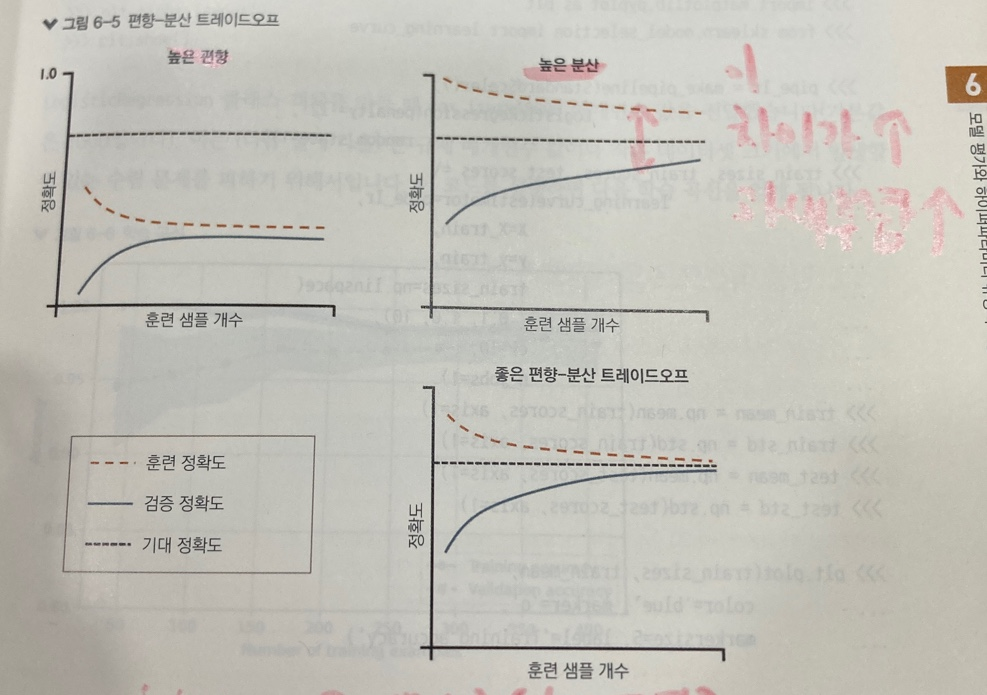
-
높은 편향은 훈련 정확도와 검증 정확도가 모두 낮은 상태 -> 해결방법: 일반적으로 모델의 파라미터 개수를 늘리는 것
-
높은 분산은 훈련정확도와 검증정확도 차이가 크다 = 과대적합 증가 -> 해결방법: 1. 더 많은 훈련 데이터를 모으거나 2. 모델 복잡도를 낮추거나 3. 규제 증가 *규제가 없는 모델은 특성 선택이나 특성 추출로 특성개수를 줄이기!
검증 곡선
- 모델의 훈련 성능과 검증 성능이 모델 하이퍼파라미터 값에 따라 어떻게 변하는지 시각적으로 보여주는 그래프 (즉 분석 대상 하이퍼파라미터 값)
- ex) 로지스틱 회귀에 있는 규제 매개변수 c
- 목적: 최적의 하이퍼파라미터 값을 찾기 위해 사용
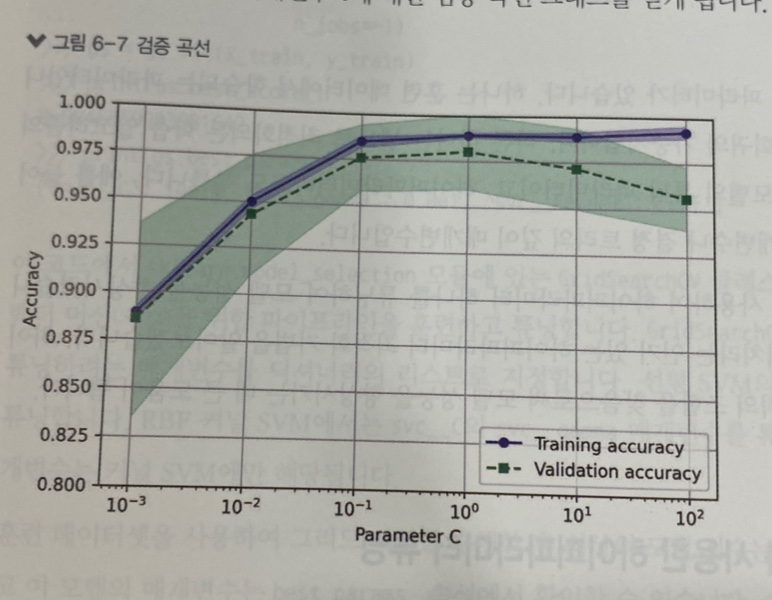
- 규제 강도를 높이면(c값을 줄이면) 모델이 과소적합 방향으로
- 규제 강도를 낮추면(c값을 높이면) 모델이 과대적합 방향으로
그리드 서치(모델 세부 튜닝 방법)
-
머신러닝에는 두 종류의 파라미터 존재
1) 훈련 데이터에서 학습되는 파라미터 ex) 로지스틱 회귀에서 가중치
2) 모델의 구조나 학습 과정을 제어하기 위해 사용자가 직접 설정하는 값. 별도(실험과 튜닝을 통해)로 최적화되는 학습 알고리즘의 파라미터 = 모델의 튜닝 파라미터 = 하이퍼파라미터 ex) 로지스틱 회귀의 규제 매개변수나 결정트리의 깊이 매개변수 -
그리드 서치는 하이퍼파라미터 값에 대한 최적의 조합을 찾는 기법.
여러가지 성능 평가 지표
- 정밀도: 모델이 전체 데이터 중에서 얼마나 정답을 맞췄는지의 비율.
- 정밀도를 최적화하면 환자가 악성 종양을 가졌는지 정확히 예측. but, 악성 종양 환자를 자주 놓치는 결과 초래.
- 재현율: 모델이 찾아야 할 대상(실제 정답) 중에서 얼마나 잘 찾아냈는지, 포착했는지
- 재현율을 최적화하면 악성 종양을 감지하지 못할 확률을 최소화. but, 건강한 환자임에도 악성 종양으로 예측하는 비용 발생
- F-1 점수
등 등..
오차행렬 : 진짜음성, 거짓음성, 진짜양성, 거짓양성
- 학습 알고리즘의 성능을 행렬로 펼쳐 놓은 것.
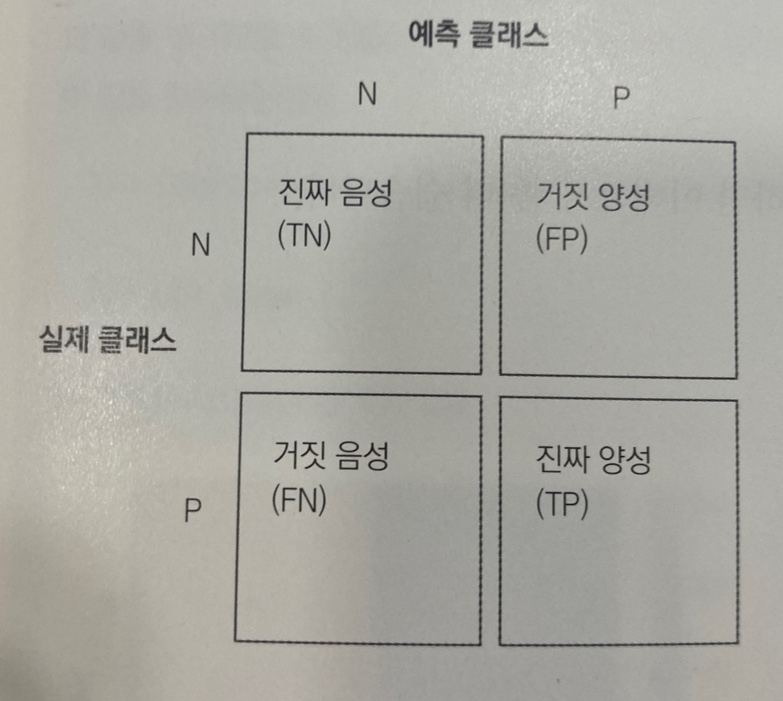
기타 개념 정리
- 파이프라인이란?
데이터 전처리부터 모델 학습까지의 과정을 순서대로 자동화하는 도구
이전 내용 관련하여 궁금한 것
Q. 데이터 전처리를 위해 특성의 스케일을 왜 조정해야되는 것일까?
- 먼저, 특성의 스케일이란? 각 데이터 특성 값의 범위나 단위.
- 예) 키: 150cm ~ 180cm / 연봉: 2천만원 ~ 1억
-> 머신러닝 모델은 값이 큰 특성에 더 큰 영향. 즉 큰 값에 치우치는 결과가 도출될 가능성이 有/ - 조정 방법으로 표준화와 정규화
