.jpg)
컴퓨터의 빠른 계산 능력을 이용하여 가능한 경우의 수를 일일이 나열하면서 답을 찾는 방법입니다.
무식하게 푼다 라는 의미인 Brute-Force라고도 부릅니다.
완전탐색 기법
완전 탐색 자체가 알고리즘은 아니기 때문에 완전 탐색 방법을 이용하기 위해서 여러 알고리즘 기법이 이용됩니다. 주로 이용되는 기법들은 다음과 같습니다.
1. 단순 Brute-Force
2. 비트 마스크(Bitmask)
3. 재귀 함수
4. 순열 (Permutation)
5. BFS/DFS
기본적으로 완전 탐색은 N의 크기가 작을 때 이용되기 때문에 보통 시간 복잡도가 지수승이나, 팩토리얼꼴로 나올 때 많이 이용됩니다.
1. 단순 Brute-Force
어느 기법을 사용하지 않고 단순히 for문과 if 문 등으로 모든 case들을 만들어 답을 구하는 방법이다. 이는 아주 기초적인 문제에서 주로 이용되거나, 전체 풀이의 일부분으로 이용하며, 따라서 당연히 대회나 코테에서 이 방법만을 이용한 문제는 거의 나오지 않는다.
2. 비트마스크(Bitmask)
2진수를 이용하는 컴퓨터의 연산을 이용하는 방식이다. 완전 탐색에서 비트마스크는 문제에서 나올 수 있는 모든 경우의 수가 각각의 원소가 포함되거나, 포함되지 않는 두 가지 선택으로 구성되는 경우에 유용하게 사용이 가능하다. 간단한 예시로 원소가 5개인 집합의 모든 부분집합을 구하는 경우를 생각해보자. 어떤 집합의 부분집합은 집합의 각 원소가 해당 부분집합에 포함되거나 포함되지 않는 두 가지 경우만 존재한다. 따라서 5자리 이진수 (0~31)을 이용하여 각 원소의 포함여부를 체크할 수 있다.
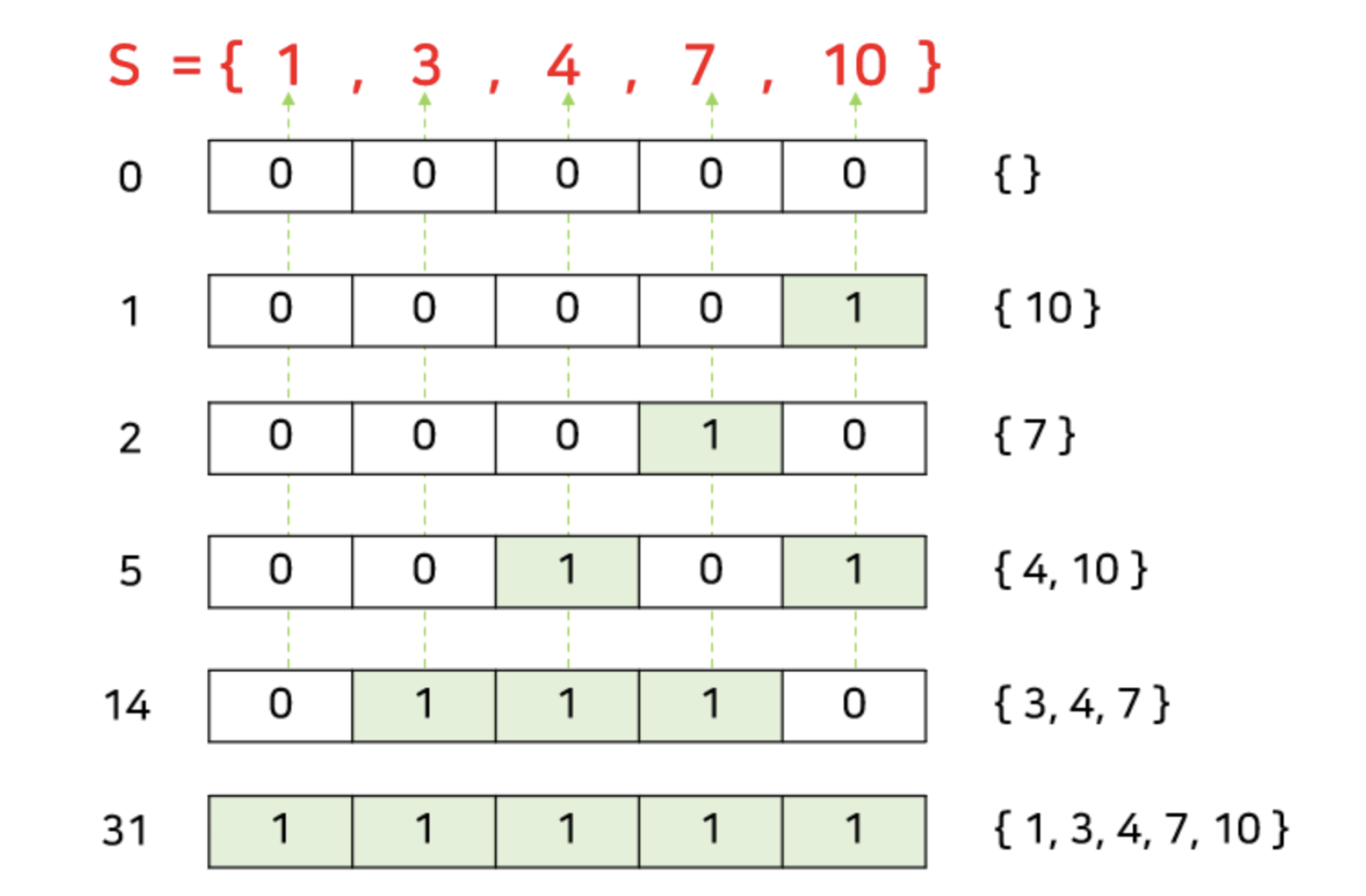
위 그림처럼 0부터 31까지의 각 숫자들이 하나의 부분집합에 일대일로 대응이 된다.
3. 재귀 함수
재귀 함수를 통해서 문제를 만족하는 경우들을 만들어가는 방식이다. 위에서 언급한 부분집합 문제를 예로 들면, 만들고자 하는 부분집합을 s라고 할때 s ={} 부터 시작해서 각 원소에 대해서 해당 원소가 포함이 되면 s에 넣고 재귀를 돌려주고 포함이 되지 않으면 s를 그대로 재귀 함수에 넣어주는 방식이다. 비트마스크와 마찬가지로 주로 각 원소가 포함되거나 포함되지 않는 두 가지 선택을 가질 때 이용된다.
4. 순열
완전 탐색의 대표적인 유형이다. 서로 다른 N개를 일렬로 나열하는 순열의 경우의 수는 N!이므로 완전 탐색을 이용하기 위해서는 N이 한자리 수 정도는 되어야한다.
5. BFS/DFS
약간의 난이도가 있는 문제로 완전 탐색 + BFS/DFS 문제가 많이 나온다. 대표적인 유형으로 길 찾기 문제가 있다. 단순히 길을 찾는 문제라면 BFS/DFS만 이용해도 충분하지만, 주어진 도로에 장애물을 설치하거나 목적지를 추가하는 등의 추가적인 작업이 필요한 경우에 이를 완전 탐색으로 해결하고 나서, BFS/DFS를 이용하는 방식이다.
실전 문제 풀이와 구현
단순 Brute-Force
(999. Available Captures for Rook)
https://leetcode.com/problems/available-captures-for-rook/
On an 8 x 8 chessboard, there is exactly one white rook 'R' and some number of white bishops 'B', black pawns 'p', and empty squares '.'.
When the rook moves, it chooses one of four cardinal directions (north, east, south, or west), then moves in that direction until it chooses to stop, reaches the edge of the board, captures a black pawn, or is blocked by a white bishop. A rook is considered attacking a pawn if the rook can capture the pawn on the rook's turn. The number of available captures for the white rook is the number of pawns that the rook is attacking.
Return the number of available captures for the white rook.
무식하게 룩을 먼저 찾은 후 체스판에 있는 비숍과 폰의 위치를 찾아내면 된다.
//체스판 위의 룩의 위치를 찾는다.
function findRook(board) {
for (let i = 0; i < board.length; i++) {
for (let j = 0; j < board[i].length; j++) {
if (board[i][j] === 'R') {
return {i, j};
}
}
}
}
// 찾은 룩을 기준으로 상 하 좌 우로 찾는다. 이때 룩을 기준으로 비숍을 만나면 의미가 없으므로 비숍을 먼저 찾아준다.
// 그래서 언제나 시작은 룩을 기준으로 한다.
function checkRight(board, i, j) {
let counter = 0;
while (true) {
if (board[i][j] === 'B') {
break;
} else if (board[i][j] === 'p') {
counter++;
break;
} else if (j === board[i].length - 1) {
break;
}
j++;
}
return counter;
}
function checkLeft(board, i, j) {
let counter = 0;
while (true) {
if (board[i][j] === 'B') {
break;
} else if (board[i][j] === 'p') {
counter++;
break;
} else if (j === 0) {
break;
}
j--;
}
return counter;
}
function checkTop(board, i, j) {
let counter = 0;
while (true) {
if (board[i][j] === 'B') {
break;
} else if (board[i][j] === 'p') {
counter++;
break;
} else if (i === 0) {
break;
}
i--;
}
return counter;
}
function checkDown(board, i, j) {
let counter = 0;
while (true) {
if (board[i][j] === 'B') {
break;
} else if (board[i][j] === 'p') {
counter++;
break;
} else if (i === board.length - 1) {
break;
}
i++;
}
return counter;
}
let numRookCaptures = function(board) {
let rook = findRook(board);
let counter = 0;
counter += checkRight(board, rook.i, rook.j);
counter += checkLeft(board, rook.i, rook.j);
counter += checkTop(board, rook.i, rook.j);
counter += checkDown(board, rook.i, rook.j);
return counter;
};비트 마스크(Bitmask)
338. Counting Bits
Given an integer n, return an array ans of length n + 1 such that for each i (0 <= i <= n), ans[i] *is the number of 1's* in the binary representation of i.
Example 1:
Input: n = 2
Output: [0,1,1]
Explanation:
0 --> 0
1 --> 1
2 --> 10my code
/**
* @param {number} n
* @return {number[]}
*/
var countBits = function(n) {
//n을 2진수로 변환하고
//안에 1의 수를 배열에 넣는다.
let ans = [];
for(let i = 0; i <=n ; i++){
let count = 0;
let b =[...i.toString(2)];
console.log(b);
b.map((index) => {
if(index === "1"){count++;}
});
ans.push(count);
}
return ans;
};best code
const countBits = (num) =>
Array(num+1).fill().map( (c,i) =>
i.toString(2).replace(/0/g, '').length
)The regex matches the 0 character.
The g means Global, and causes the replace call to replace all matches, not just the first one.
재귀 함수 (recursion)
21. Merge Two Sorted Lists
You are given the heads of two sorted linked lists list1 and list2.
Merge the two lists in a one sorted list. The list should be made by splicing together the nodes of the first two lists.
Return the head of the merged linked list.
Example 1:

Input: list1 = [1,2,4], list2 = [1,3,4]
Output: [1,1,2,3,4,4]my code
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} list1
* @param {ListNode} list2
* @return {ListNode}
*/
var mergeTwoLists = function(l1, l2) {
//새로운 리스트 노드를 하나 만들고
//head가 merge를 바라보게 한다.
//l1 l2 모두 참일때
//l1 < l2 //merge에 l1을 붙인다. //l1전진
//else //merge에 l2f를 붙인다. //l2전진
//l1이 false라면 merge에 l2를 붙인다.
//l2가 false라면 merge에 l1을 붙인다.
let merge = new ListNode();
let head = merge;
while(l1&&l2){
if(l1.val < l2.val){
merge.next = l1;
l1 = l1.next;
}
else {
merge.next = l2;
l2 = l2.next;
}
merge = merge.next;
}
if(!l1){
merge.next = l2;
}
else if(!l2){
merge.next = l1;
}
return head.next;
};recursion code
let mergeTwoLists = function(l1, l2) {
if(!l1 || !l2) return (l1? l1:l2);
if(l1.val < l2.val) {
l1.next = mergeTwoLists(l1.next, l2);
return l1;
} else {
l2.next = mergeTwoLists(l1, l2.next);
return l2;
}
};순열 (Permutation)
https://velog.io/@devjade/JavaScript로-순열과-조합-알고리즘-구현하기
해당 블로그에서 순열 부분만 가져왔다.
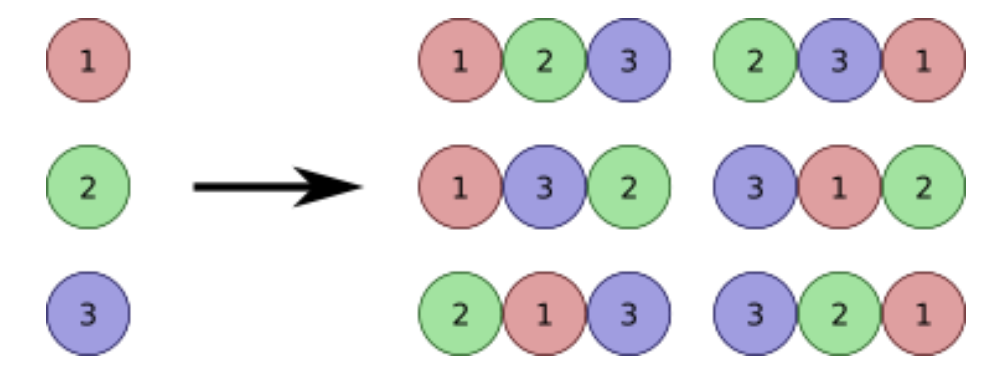
서로 다른 n개의 물건 중에서 r개를 택하여 한 줄로 배열하는 것을 n개의 물건에서 r개 택하는 순열이라 하고, 이 순열의 수를 기호로 nPr와 같이 나타낸다. 조합은 순서에 상관없이 선택한 것이라면, 순열은 순서가 중요하다. 실제로 순열을 구하는 공식도 조합으로부터 도출 가능하다.
Input: [1, 2, 3, 4]
Output: [
[ 1, 2, 3 ], [ 1, 2, 4 ],
[ 1, 3, 2 ], [ 1, 3, 4 ],
[ 1, 4, 2 ], [ 1, 4, 3 ],
[ 2, 1, 3 ], [ 2, 1, 4 ],
[ 2, 3, 1 ], [ 2, 3, 4 ],
[ 2, 4, 1 ], [ 2, 4, 3 ],
[ 3, 1, 2 ], [ 3, 1, 4 ],
[ 3, 2, 1 ], [ 3, 2, 4 ],
[ 3, 4, 1 ], [ 3, 4, 2 ],
[ 4, 1, 2 ], [ 4, 1, 3 ],
[ 4, 2, 1 ], [ 4, 2, 3 ],
[ 4, 3, 1 ], [ 4, 3, 2 ]
]수도코드
먼저, 재귀의 종료 조건은 조합을 구하는 함수와 동일하다. 왜냐하면, 한 개씩 선택한다고 하면 순서가 의미가 없어지기 때문이다.[1,2,3,4] 에서 3개를 선택해서 순열을 만드는 코드의 내부를 의사코드로 적어보면 다음과 같다.1, 2, 3, 4를 각각 순서대로 픽스하고 나머지 요소만으로 이루어진 배열에서 (seletNumber-1)만큼을 선택하여 또 순열을 구한다.(재귀)
1(fixed) => permutation([2, 3, 4]) => 2(fixed) => permutation([3, 4]) => ...
2(fixed) => permutation([1, 3, 4]) => 1(fixed) => permutation([3, 4]) => ...
3(fixed) => permutation([1, 2, 4]) ... 위와 동일...
4(fixed) => permutation([1, 2, 3])const getPermutations = function (arr, selectNumber) {
const results = [];
if (selectNumber === 1) return arr.map((el) => [el]);
// n개중에서 1개 선택할 때(nP1), 바로 모든 배열의 원소 return. 1개선택이므로 순서가 의미없음.
arr.forEach((fixed, index, origin) => {
const rest = [...origin.slice(0, index), ...origin.slice(index+1)]
// 해당하는 fixed를 제외한 나머지 배열
const permutations = getPermutations(rest, selectNumber - 1);
// 나머지에 대해서 순열을 구한다.
const attached = permutations.map((el) => [fixed, ...el]);
// 돌아온 순열에 떼 놓은(fixed) 값 붙이기
results.push(...attached);
// 배열 spread syntax 로 모두다 push
});
return results; // 결과 담긴 results return
}BFS/DFS
https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
https://velog.io/@sangbooom/JS-BFS-DFS
해당 블로그의 글을 가져왔다.
너비 우선 탐색(BFS, Breadth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다. 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우
깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다.
너비 우선 탐색의 경우 - Ash와 가까운 관계부터 탐색
너비 우선 탐색(BFS)이 깊이 우선 탐색(DFS)보다 좀 더 복잡하다.
너비 우선 탐색(BFS)의 특징
직관적이지 않은 면이 있다.
BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다.
BFS는 재귀적으로 동작하지 않는다.
이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
즉, 선입선출(FIFO) 원칙으로 탐색
일반적으로 큐를 이용해서 반복적 형태로 구현하는 것이 가장 잘 동작한다.
‘Prim’, ‘Dijkstra’ 알고리즘과 유사하다.
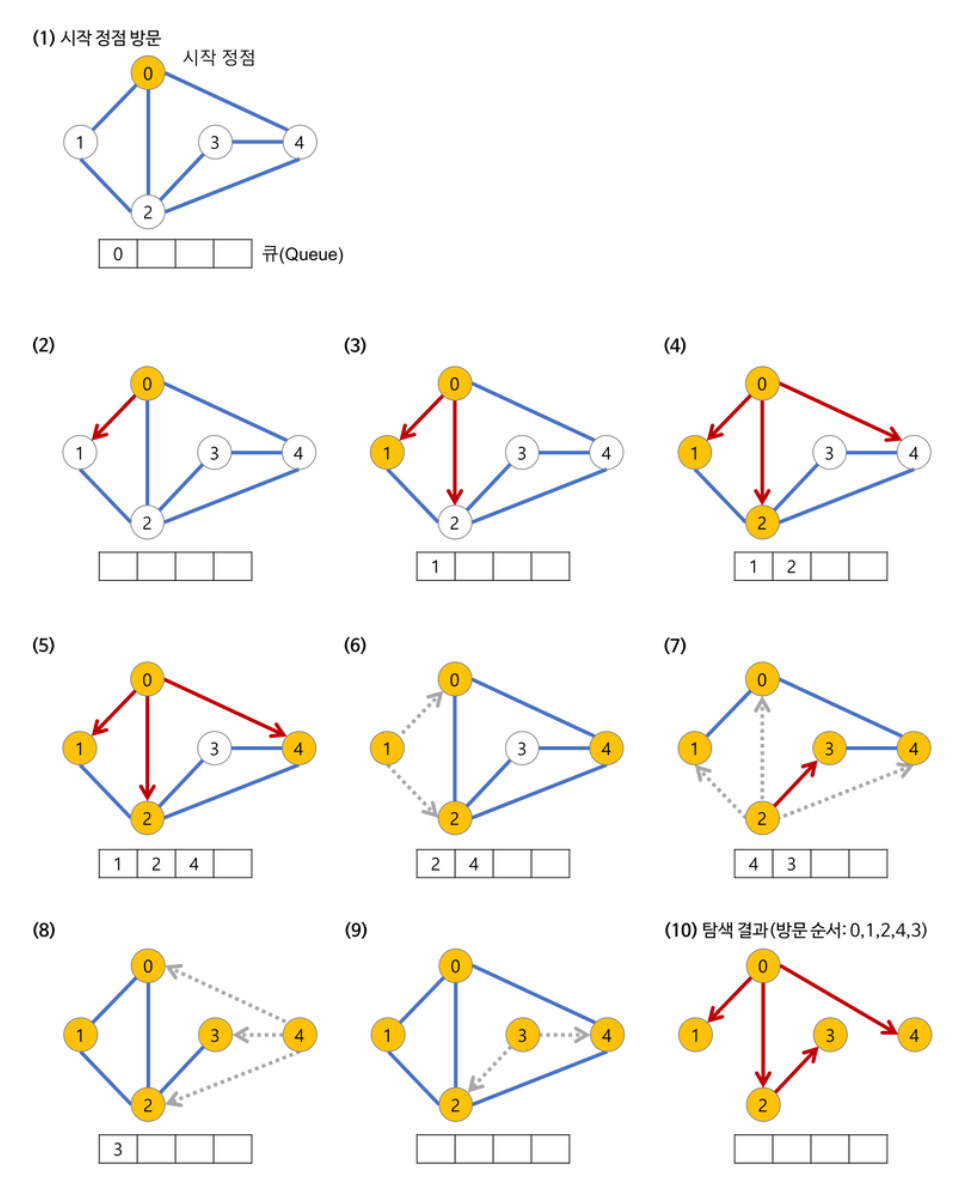
- a 노드(시작 노드)를 방문한다. (방문한 노드 체크)
큐에 방문된 노드를 삽입(enqueue)한다.
초기 상태의 큐에는 시작 노드만이 저장
즉, a 노드의 이웃 노드를 모두 방문한 다음에 이웃의 이웃들을 방문한다. - 큐에서 꺼낸 노드과 인접한 노드들을 모두 차례로 방문한다.
큐에서 꺼낸 노드를 방문한다.
큐에서 커낸 노드과 인접한 노드들을 모두 방문한다.
인접한 노드가 없다면 큐의 앞에서 노드를 꺼낸다(dequeue).
큐에 방문된 노드를 삽입(enqueue)한다. - 큐가 소진될 때까지 계속한다.
**깊이 우선 탐색(DFS, Depth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 이곳으로부터 다른 방향으로 다시 탐색을 진행하는 방법과 유사하다. 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다. 사용하는 경우: 모든 노드를 방문 하고자 하는 경우에 이 방법을 선택한다. 깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단하다. 단순 검색 속도 자체는 너비 우선 탐색(BFS)에 비해서 느리다.
깊이 우선 탐색(DFS)의 특징
자기 자신을 호출하는 순환 알고리즘의 형태 를 가지고 있다.
전위 순회(Pre-Order Traversals)를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다.
이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다. 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
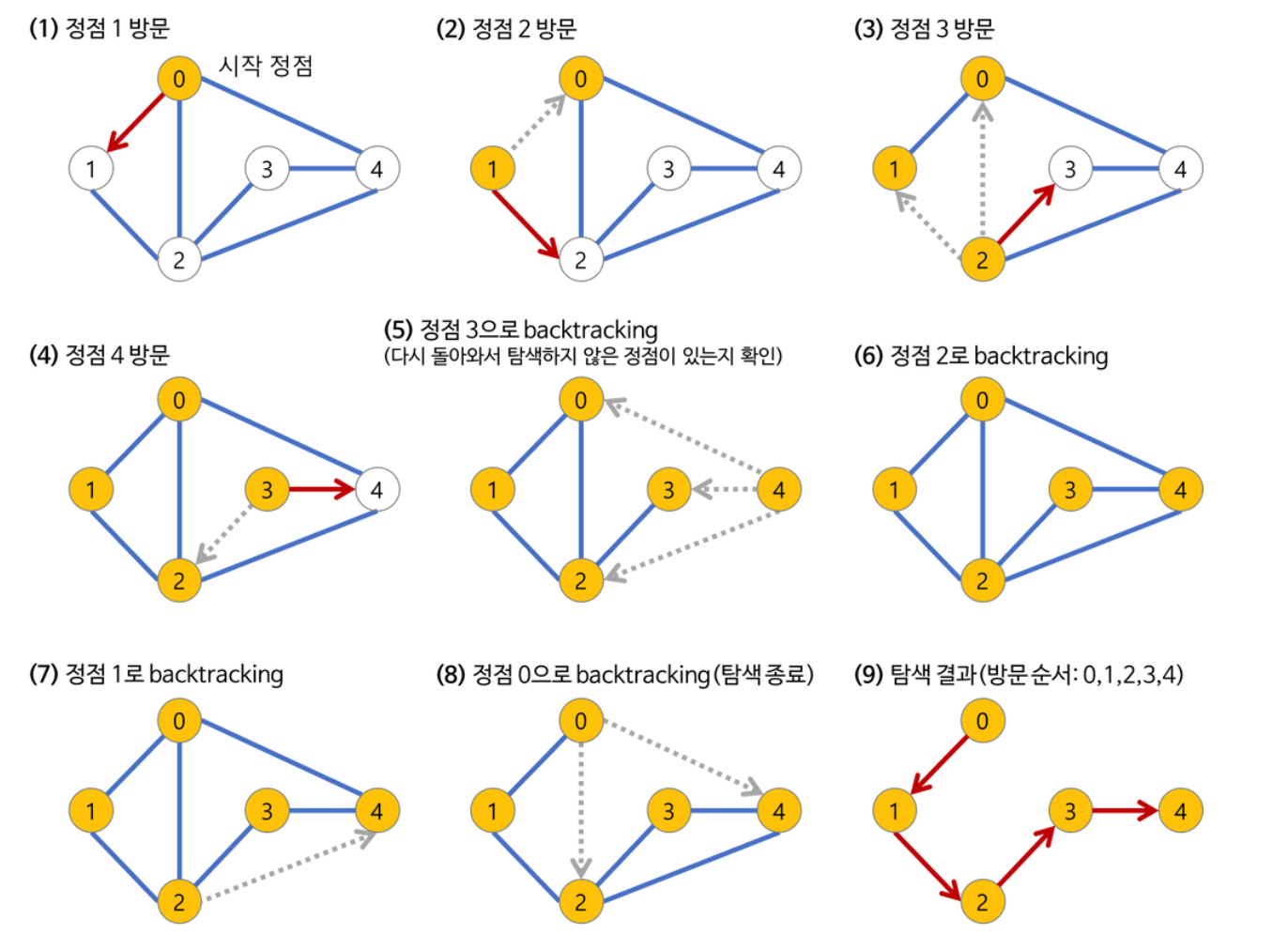
-
a 노드(시작 노드)를 방문한다.
방문한 노드는 방문했다고 표시한다. -
a와 인접한 노드들을 차례로 순회한다.
a와 인접한 노드가 없다면 종료한다. -
a와 이웃한 노드 b를 방문했다면, a와 인접한 또 다른 노드를 방문하기 전에 b의 이웃 노드들을 전부 방문해야 한다.
b를 시작 정점으로 DFS를 다시 시작하여 b의 이웃 노드들을 방문한다. -
b의 분기를 전부 완벽하게 탐색했다면 다시 a에 인접한 정점들 중에서 아직 방문이 안 된 정점을 찾는다.
즉, b의 분기를 전부 완벽하게 탐색한 뒤에야 a의 다른 이웃 노드를 방문할 수 있다는 뜻이다.
아직 방문이 안 된 정점이 없으면 종료한다.
있으면 다시 그 정점을 시작 정점으로 DFS를 시작한다.
BFS/DFS 예제
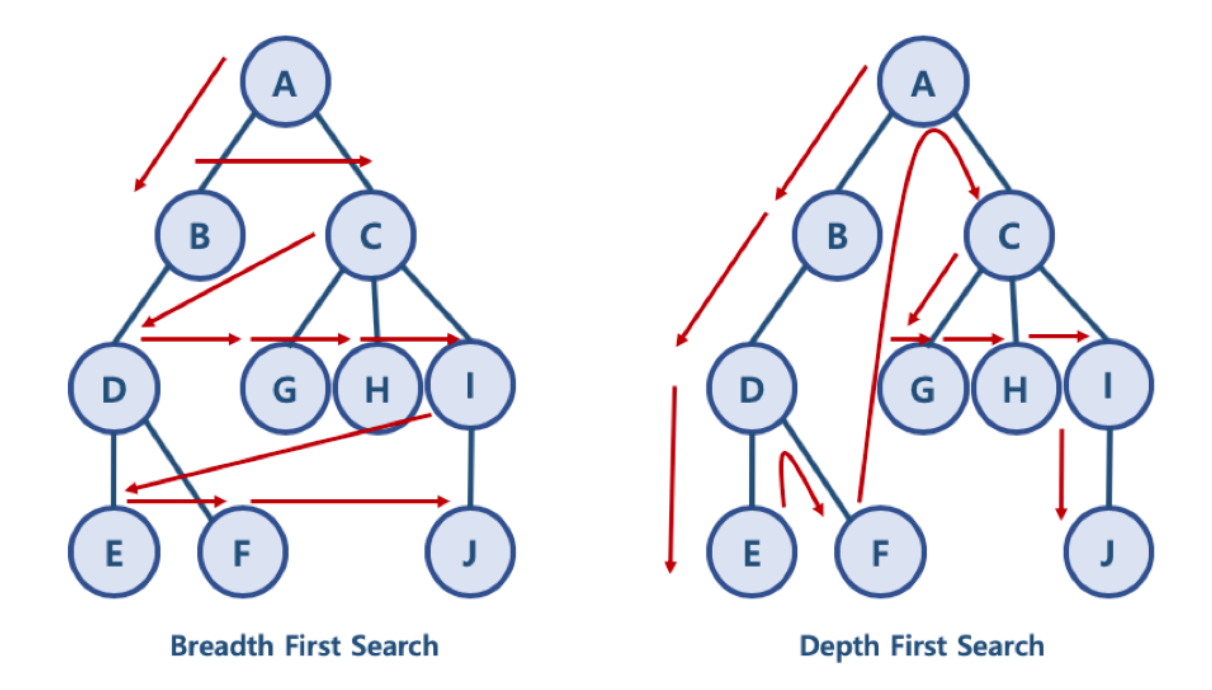
자바스크립트로 그래프 표현하기
const graph = {
A: ['B', 'C'],
B: ['A', 'D'],
C: ['A', 'G', 'H', 'I'],
D: ['B', 'E', 'F'],
E: ['D'],
F: ['D'],
G: ['C'],
H: ['C'],
I: ['C', 'J'],
J: ['I']
};BFS 구현
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"]
};
const BFS = (graph, startNode) => {
const visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) { // 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // queue이기 때문에 선입선출, shift()를 사용한다.
if (!visited.includes(node)) { // 해당 노드가 탐색된 적 없다면
visited.push(node);
needVisit = [...needVisit, ...graph[node]];
}
}
return visited;
};
console.log(BFS(graph, "A"));
// ["A", "B", "C", "D", "G", "H", "I", "E", "F", "J"]DFS 구현
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"],
};
const DFS = (graph, startNode) => {
const visited = []; // 탐색을 마친 노드들
let needVisit = []; // 탐색해야할 노드들
needVisit.push(startNode); // 노드 탐색 시작
while (needVisit.length !== 0) {
// 탐색해야할 노드가 남아있다면
const node = needVisit.shift(); // queue이기 때문에 선입선출, shift()를 사용한다.
if (!visited.includes(node)) {
// 해당 노드가 탐색된 적 없다면
visited.push(node);
needVisit = [...graph[node], ...needVisit];
//DFS는 이전 노드가 아니라 자기 자신과 연결되었던 노드를 먼저 탐색한다.
}
}
return visited;
};
console.log(DFS(graph, "A"));
// ["A", "B", "D", "E", "F", "C", "G", "H", "I", "J"]