지금 진행 중인 프로젝트에 이미지 캡셔닝을 하고 싶었고, 유튜브에서 이미지 캡셔닝 강의를 보려고 했다. 근데 일단은 앞서서 RNN 계열의 모델에 대한 개념이 필요했다. 그래서 이번 포스팅의 주제는 RNN 계열 모델!
그리고 RNN의 한계를 해결하기 위해 나온 LSTM 모델까지 함께 알아보려고 한다.
오늘은 Minsuk Heo 허민석 님의 유튜브에서 간단하게 이해할 수 있는 강의를 보고 공부한 내용을 베이스로 포스팅하려고 한다!
📌 RNN
먼저 예시 RNN 모델을 다이어그램으로 살펴보자.
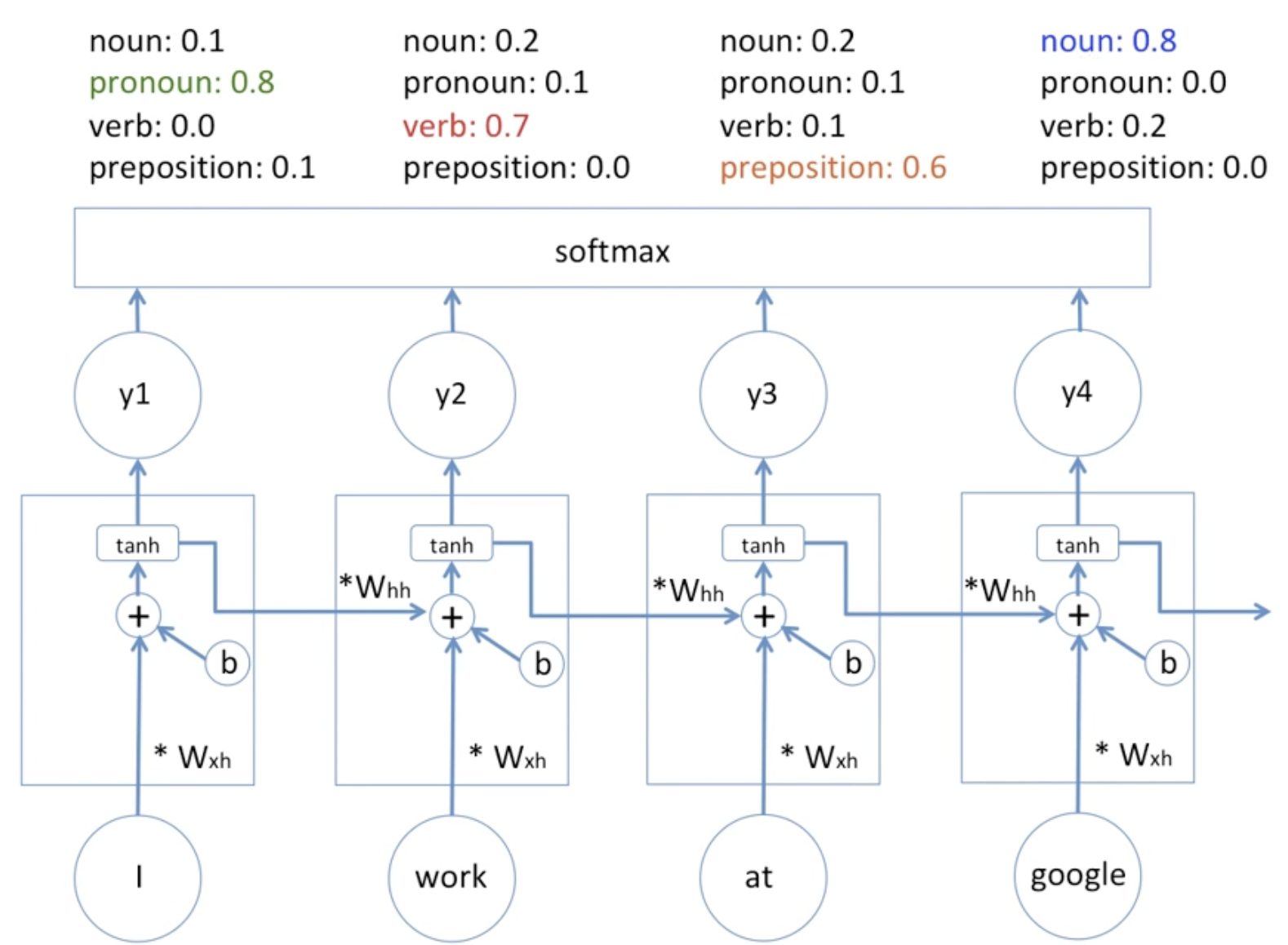
이것은 입력으로 들어온 문장을 끊어서 품사 구별을 하는 과정이다.
조금 더 자세히 확인하면 아래와 같은데,
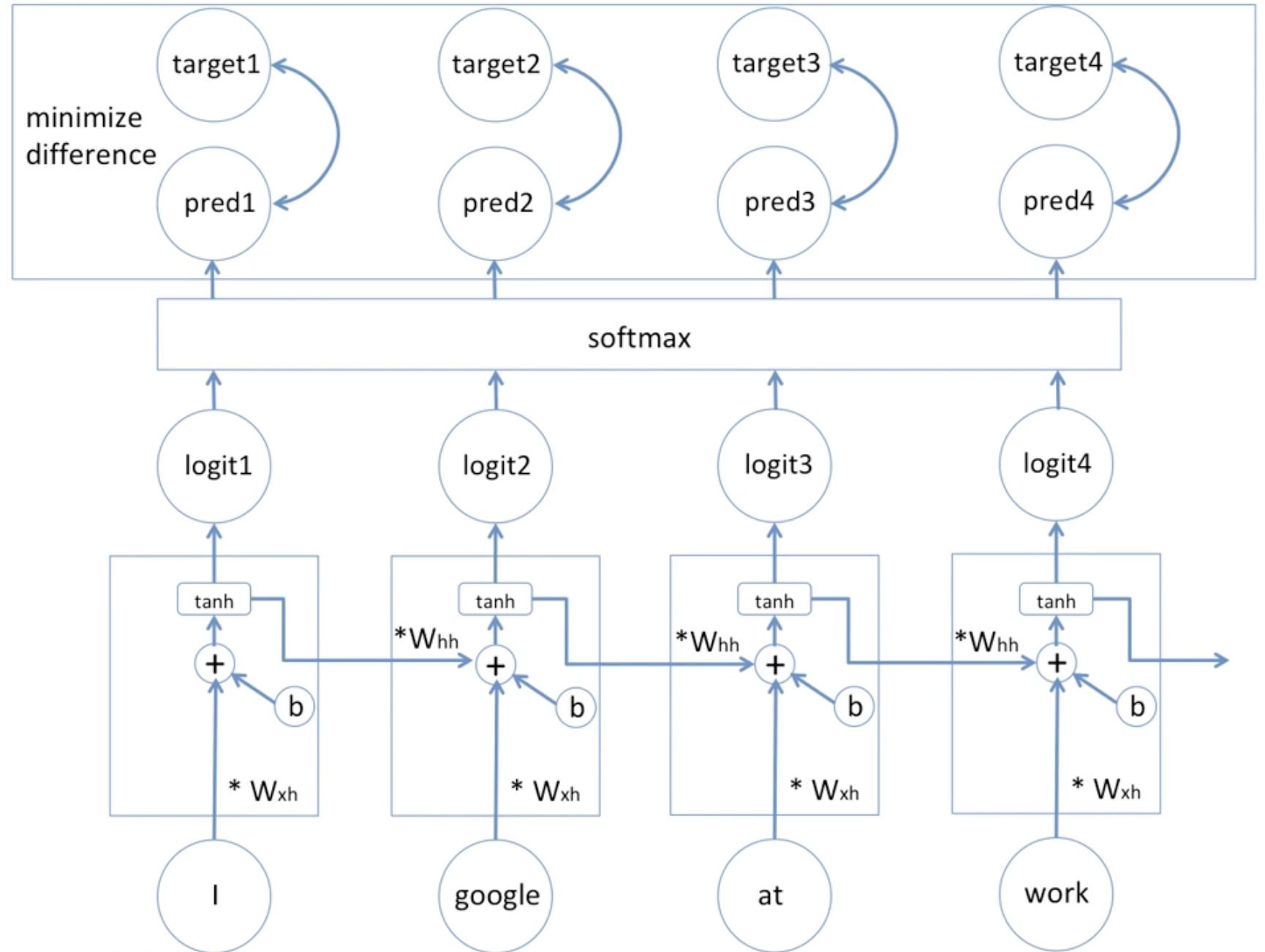
가장 위 박스 속 target이 예측 대상이고 pred가 예측 값이다.
결국에 이 둘 사이의 오차를 최소화하는 방향으로 학습하는 것이 RNN 모델이다.
연산되는 과정이 보이는 가운데의 박스는 hidden state이다. 이때 이전에서 넘어온 weight, input에서의 weight 두 가중치를 모두 고려해준다. 여기서 '고려한다'라는 말은 수식으로 + 를 사용해 표현한다.
그리고 딥러닝 모델의 학습을 더 수월하게 해주는 편향값을 b 로 표시하고 있다.
그 후, tanh 활성화 함수 적용을 해 비선형성을 주어 그 출력으로 output을 도출한다.
마지막으로 softmax 를 거쳐 품사의 확률값을 확인할 수 있게 된다.
RNN의 특징
RNN은 순환 경로를 갖기 때문에 이전 데이터를 기억하는 특징이 있다. 그리고 그 동시에 최신 데이터로 갱신을 할 수 있다.
위의 다이어그램은 RNN 순환 구조를 펼쳐 보기 쉽게 확인한 것이다. 이것을 단순화하여 나타내면 순환 구조라는게 조금 더 이해가 된다.

오른쪽이 위 다이어그램이고 왼쪽이 단순화한 구조이다. 화살표 방향으로 쉽게 이해할 수 있다.
그리고 최종 수식이 아래와 같이 정의된다.
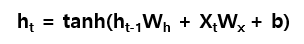
그리고 감정 분석 등을 할 때 오차 역전파를 통해 예측값과 실제값 사이의 오차를 줄여나가도록 한다.
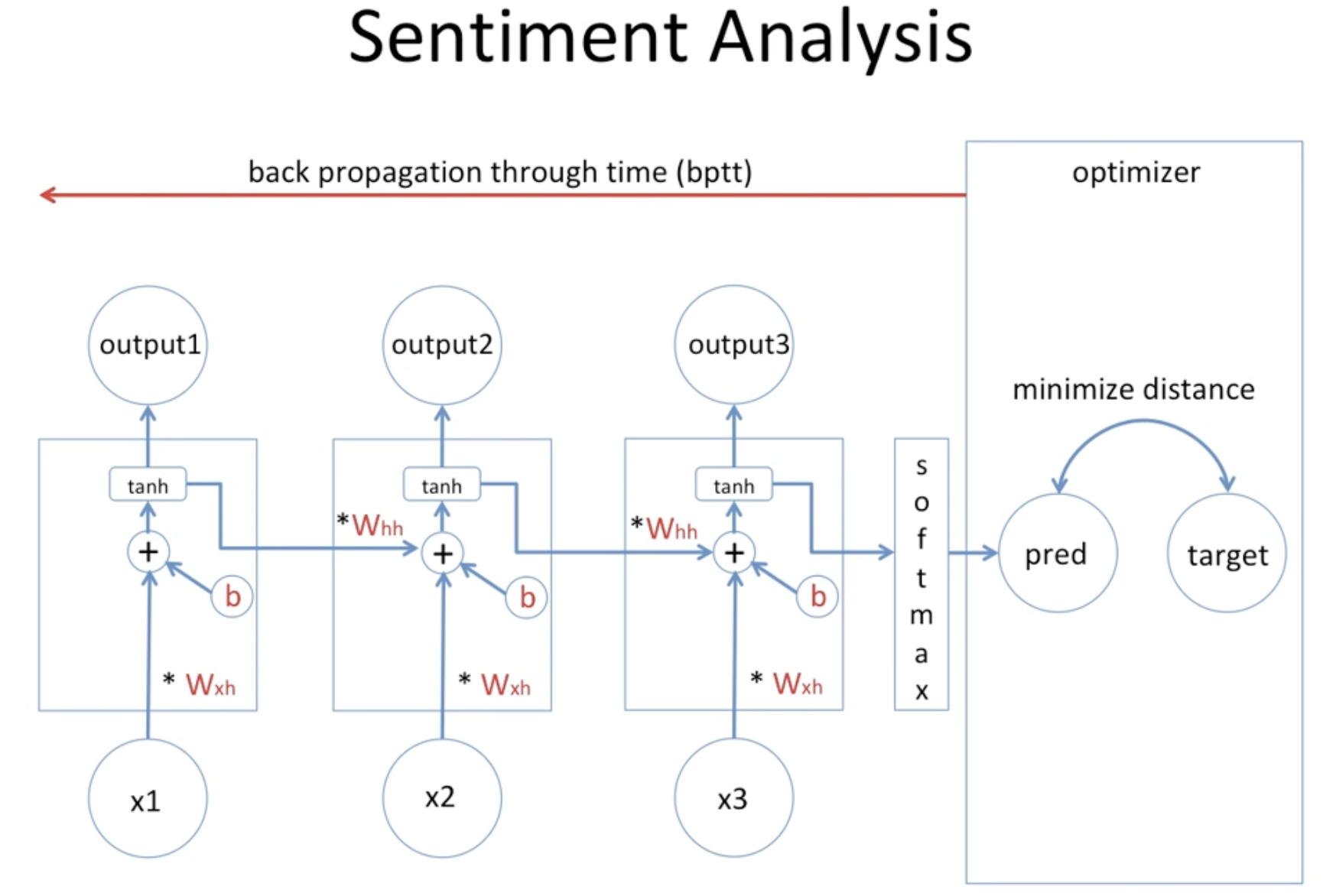
back propagation through time을 통해 빨간 글씨로 표시된 가중치 2개의 값과 편향값을 변경하면서 최소화해나가는 방식으로 학습이 진행된다.
그런데 이때 RNN에서 오차 역전파법을 적용하는데 그 깊이가 너무 깊어지다 보면, 계속해서 미분하기 때문에 기울기가 0에 가까워지는 Vanishing Gradient Problem 을 주의해야한다.
📌 LSTM
위와 같은 RNN의 한계점을 해결할 수 있는 모델이 등장한다. 그게 LSTM이다.
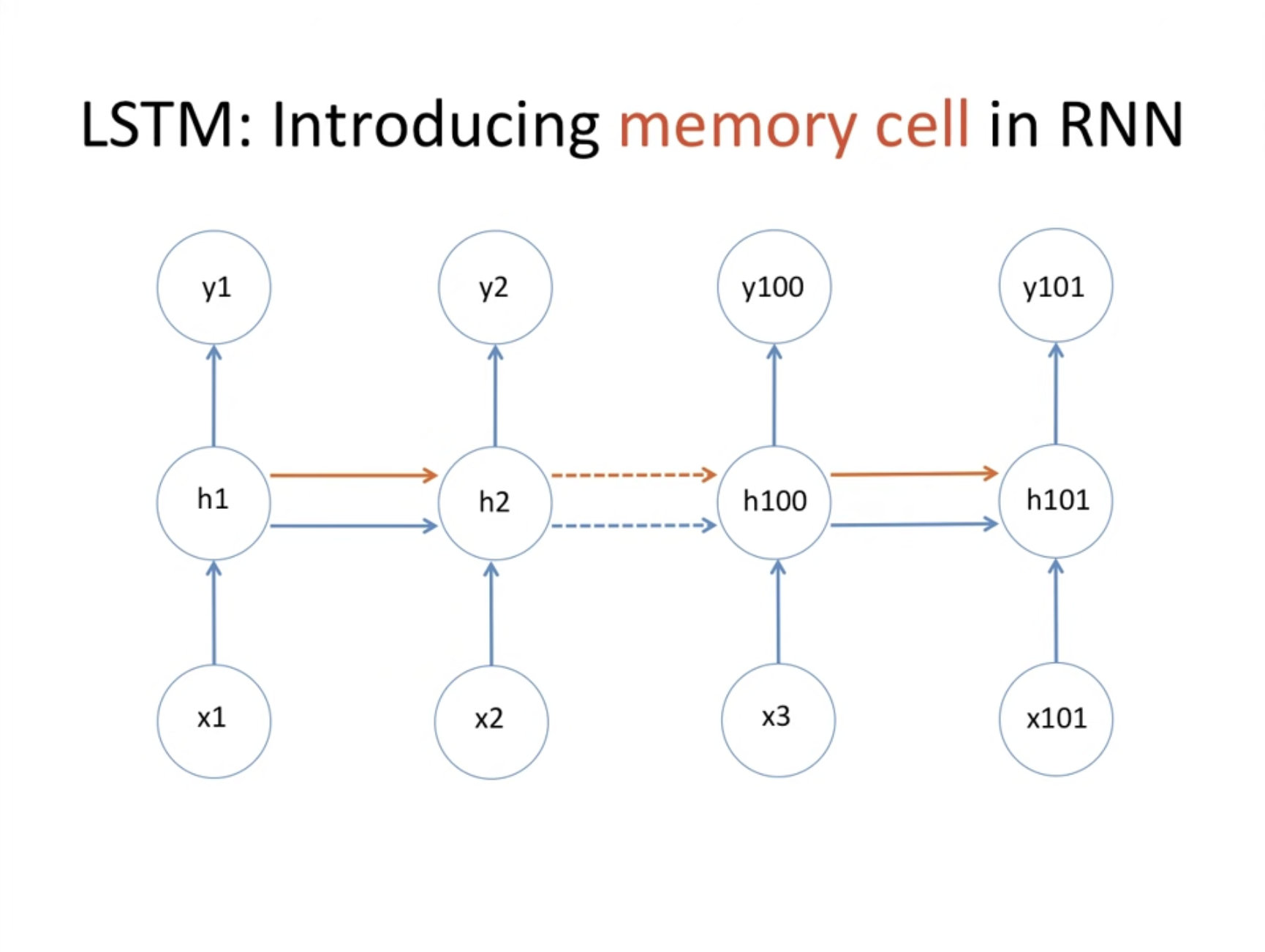
자세히 보면 RNN과 다르게 전파되는 화살표가 하나 더 늘어났다. 이전 정보를 기억해두고 계속 전달하는 역할을 한다고 생각할 수 있다.
LSTM은 이름에서도 알 수 있듯이 중요 정보를 계속 기억하는 memory cell 이 있다. 이 정보를 잊고 기억하는 매커니즘을 통해 개선할 수 있게 된 것이다.
예를 들어서 인물이 한 명 나왔을 때 그 다음 문장에서 he/she가 필요함을 쉽게 예측한다. 하지만 인물이 두 명이 등장했을 때는 앞선 내용을 기억해뒀다가 어느정도 잊고 새로운 정보로 갱신해 예측할 수 있어야하는데, 이는 LSTM에서 가능하다.
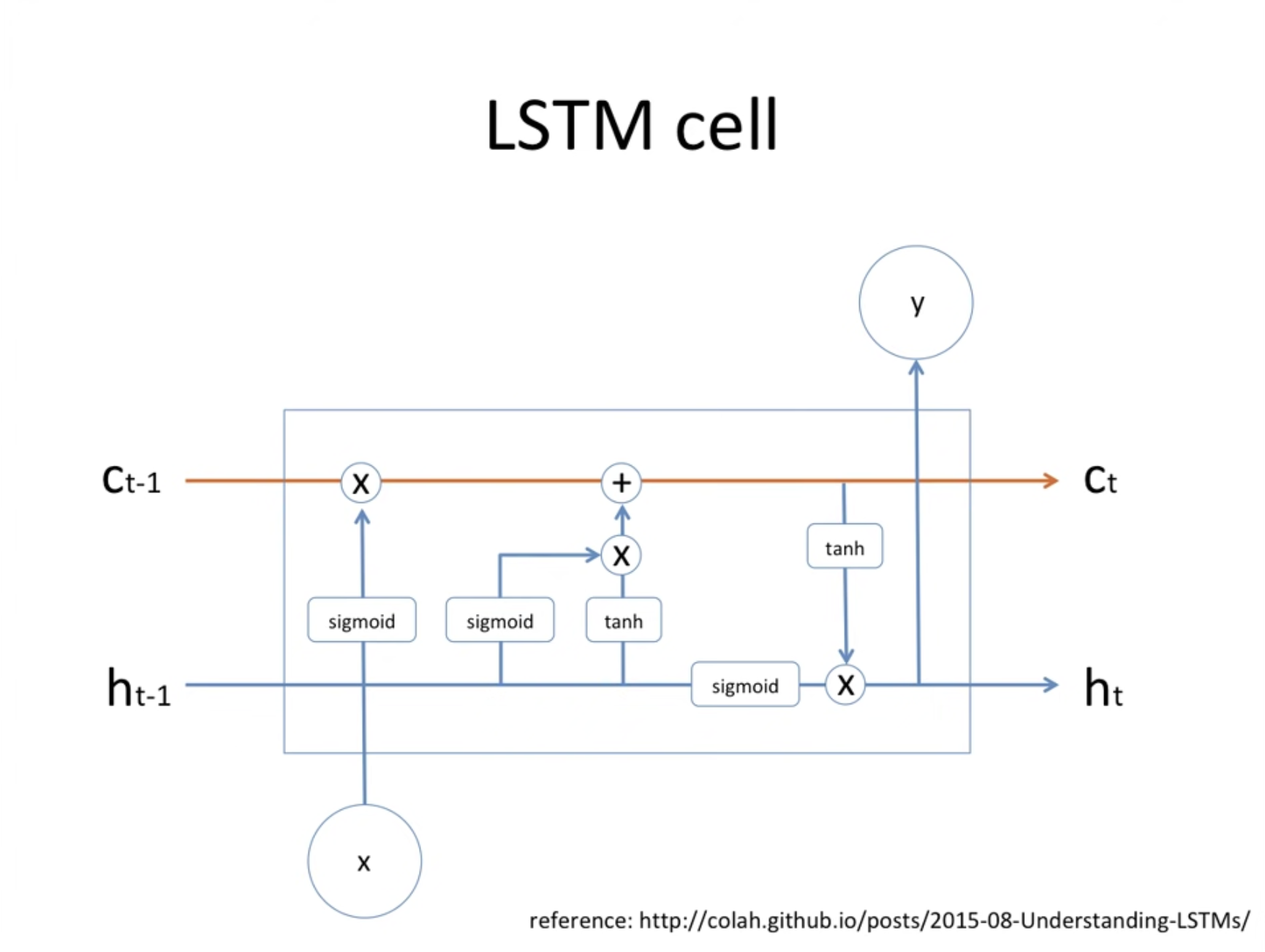
위 그림에서 볼 수 있는 주황색 선은 memory cell 이고, 파란색 선은 hidden state 이다. 이 둘은 계속해서 옆으로 전파가 되고 있는 상태이다.
잊는 매커니즘에 대해서 이해해보자.
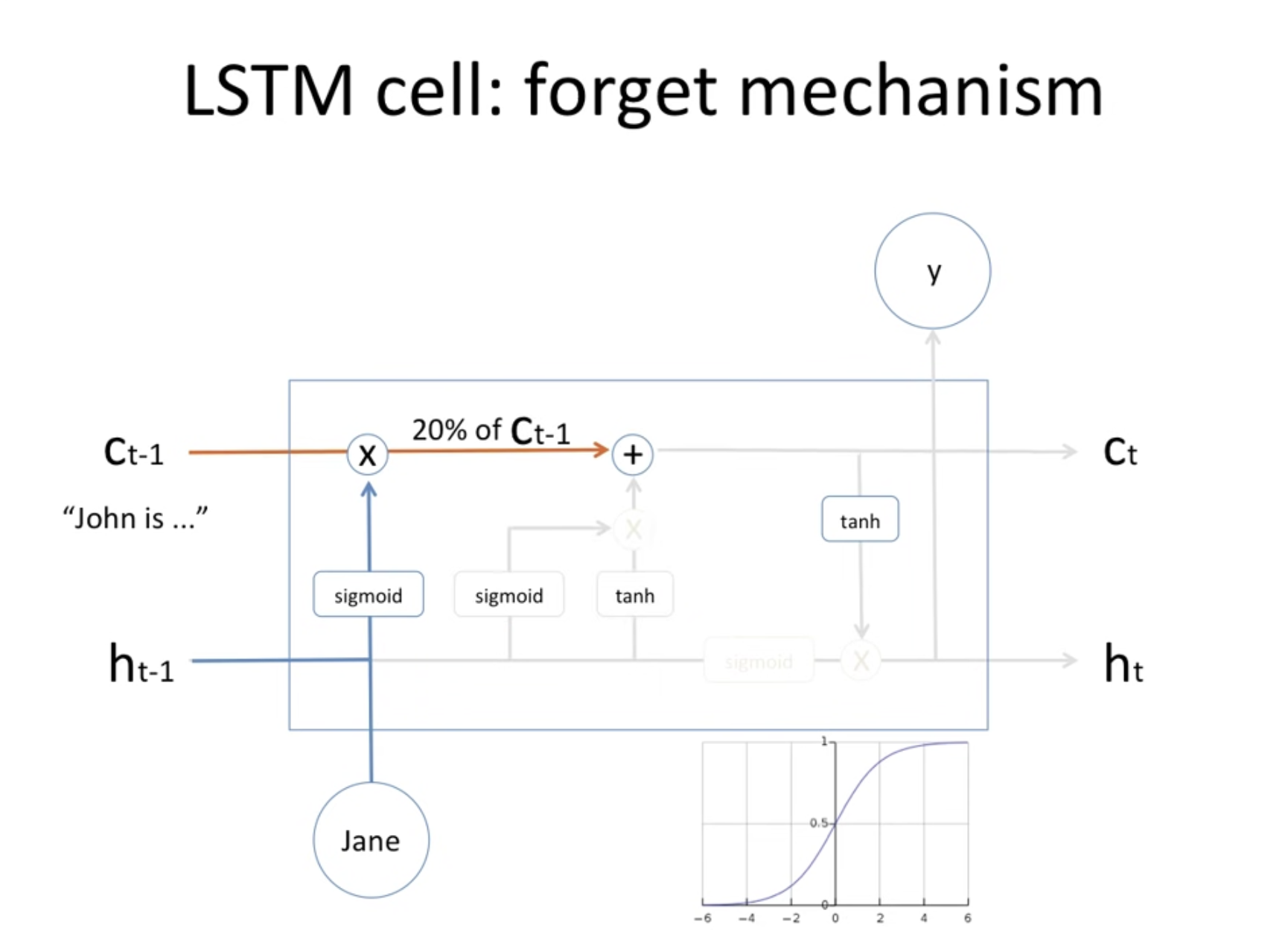
왼쪽의 C에 보면 John이라는 정보가 저장된 상태이다. 이때 새로운 input은 Jane으로 기존 기억하던 내용과 다르다. 이럴때 sigmoid 함수를 통하는데 이 값은 확률값으로 계산되고 앞선 memory cell의 내용을 그 확률만큼만 기억해라, 즉 잊으라는 의미가 된다.
그 다음에 새로운 input 정보가 memory cell에 저장되기 위해서 sigmoid, tanh 계산을 거친 것을 고려해주면 새로운 정보를 적용해 저장하게 된다.
그리고 수정된 현재 memory cell과 hidden state 값이 각각 tanh, sigmoid를 통해서 들어오고, 두 값을 곱해 output이 되고 다음 hidden state 값으로 전파가 되며 과정이 진행된다.
LSTM은 성능이 좋지만 매개변수도 많고 연산량이 많다는 단점이 있다고 한다. 그래서 최근 GRU라는 모델이 많이 쓰이고 있는데, 이는 비슷한 개념을 갖고 있는데 매개변수가 줄고 연산량이 적다는 장점이 있다. 그리고 한국인 박사님이 제안한 개념이라고 해서 더 인기를 끌고 있다고 한다 :)
참고
