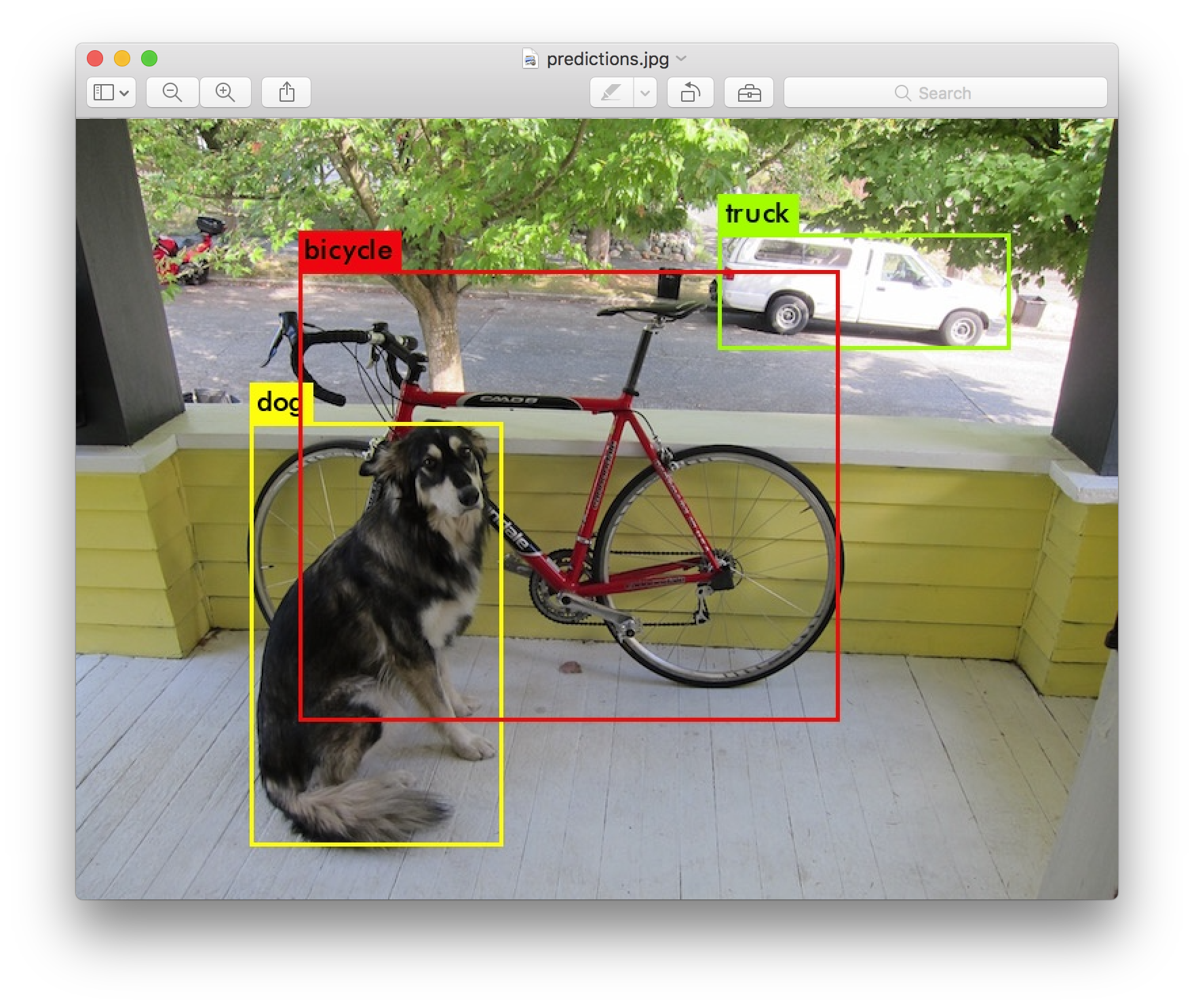
카메라에 비춰진 사물의 영역을 표시하고 뿐만 아니라 인식된 사물이 어떤것인지 까지 알려주는 모델이 있다. YOLO! 제 인생에 YOLO는 유온리리브원스 뿐이었는데 말이죠, 이 YOLO는 You Only Look Once 라고 한다. 자세한 설명은 본문에서 하도록 하자.
처음에 간단하게 노트북 캠으로 영상 받아서 인식하는걸 해봤을 때 생각보다 더 신기하고 재밌어서 처음에 재미없다고 생각했던 OpenCV까지도 다시 보였다. 암 그렇고 말고 딥러닝은 비전이지.
왜 영상 속 사물 인식은 YOLO가 쓰이는지 궁금했기 때문에, 이번에 개념도 확인하고 장점을 알아보려고 한다.
그리고 공식적으로는 버전이 3까지 나와있고, 다른 개발자가 4, 5 그 이상 다른 버전도 만든걸로 알고 있는데 학술적으로는 4까지 인정된다고 한다. 그래서 만약에 차이점이 있다면 어떤 부분에서 차이가 있는지도 확인해보자!
📚 Object Detection
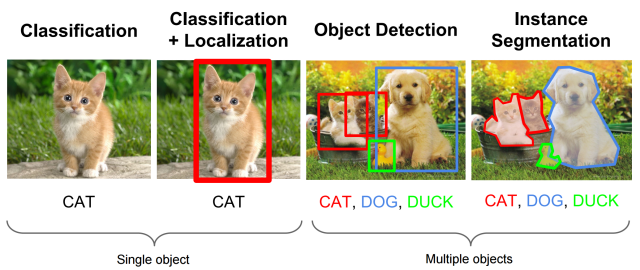
객체 검출(Object Detection)은 영상처리나 CV 분야에서 기본적이고 또 많이 쓰이는 기법이다. 최근에는 얼굴 인식, 음성 인식, 비디오 인식, 이미지 분류 등 다양한 분야에 활용된다.
여러 사물을 '어떤 것이다'하고 분류하는 (Multi-Labeled) Classification과 그 사물이 어디 있는지 박스(Bounding Box Regression)를 통해 위치 정보를 나타내는 Localization 문제를 해결하는 분야이다.
Object Detection = 여러가지 물체에 대한 Classification + 물체의 위치정보를 파악하는 Localization
원래는 이 문제를 CNN으로 주로 잘 해결할 수 있었다. 객체 탐지는 어쨌든 하나의 이미지에서 물체를 분류하고 위치를 추정하는 일을 한다. 그래서 CNN으로 하나의 물체를 분류하고, 위치를 찾은 후 이미지 모두를 훑는 방식으로 진행되었다. 그러니까, 이미지를 슬라이딩 하면서 모든 영역을 본다.
그런데, 위의 CNN 방식은 간단하고 쉬운 방법이지만, 여러번 실행해야하기 때문에 많이 느리다는 문제가 있었다. 그리고 제한된 수의 개체 탐지에는 괜찮지만, 많은 객체를 탐지하는 것에는 한계가 있었다.
이게 윈도우가 여러개고 계산상 비효율 때문에 문제가 되는 것인데,
그렇다면 윈도우의 일부만을 활용해 객체 탐지를 효율적으로 할 수 있는 방법은 무엇일까?
📚 1 or 2 stage Detector
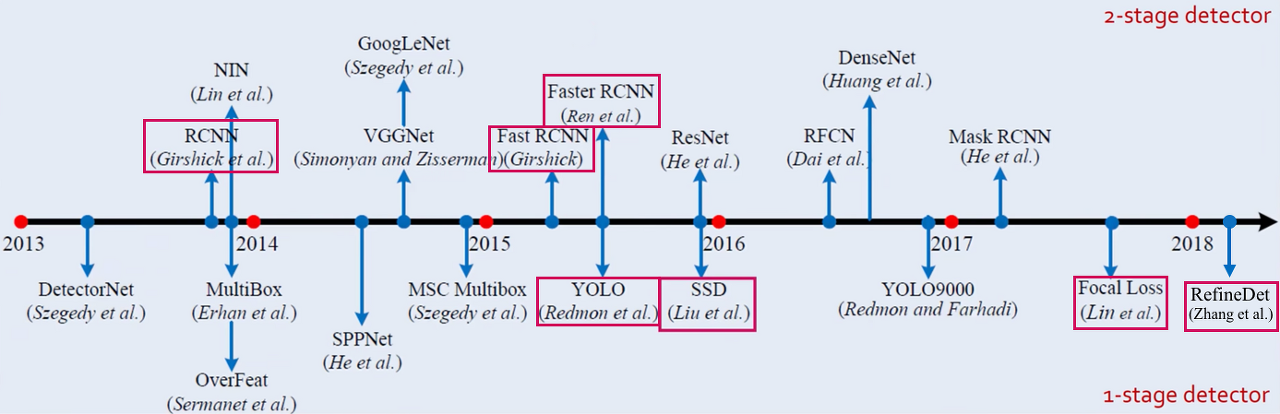
그 방법으로 크게 1-stage detector, 2-stage detector로 분류할 수 있다.
간단하게 차이점을 확인해보자.
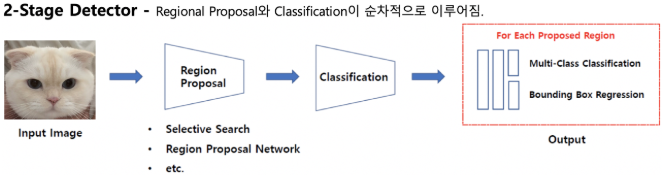
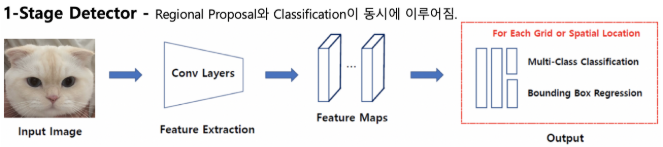
Object Detection은 위에서 소개한 것처럼 classification, localization 두 가지를 합한 문제이다.
2-stage는 이 두 문제를 순차적으로 해결하고, 1-stage는 동시에 해결한다. 2-stage에 비해 1-stage가 속도면에서 더 우수한 성능을 보이지만, 정확도는 2-stage가 더 높다.
우리의 YOLO는 1-stage에 해당된다!
📚 YOLO
YOLO는 Object Detection 분야에서 많이 알려져있다. 1-stage detector 방식을 처음으로 고안해서 실시간 객체 검출을 가능하게 한 모델이라고 한다.
YOLO의 특징은 총 3가지가 있다.
- 이미지 전체를 한 번만 본다.
CNN처럼 이미지를 여러장으로 분할해 해석하지 않는다. - 통합된 모델을 사용해 간단하다.
- 기존의 모델보다 빠른 성능으로 실시간 객체 검출이 가능하다.
빠르고 간단한 장점이 있지만, 작은 객체의 인식률이 떨어진다는 단점도 있다고 한다.
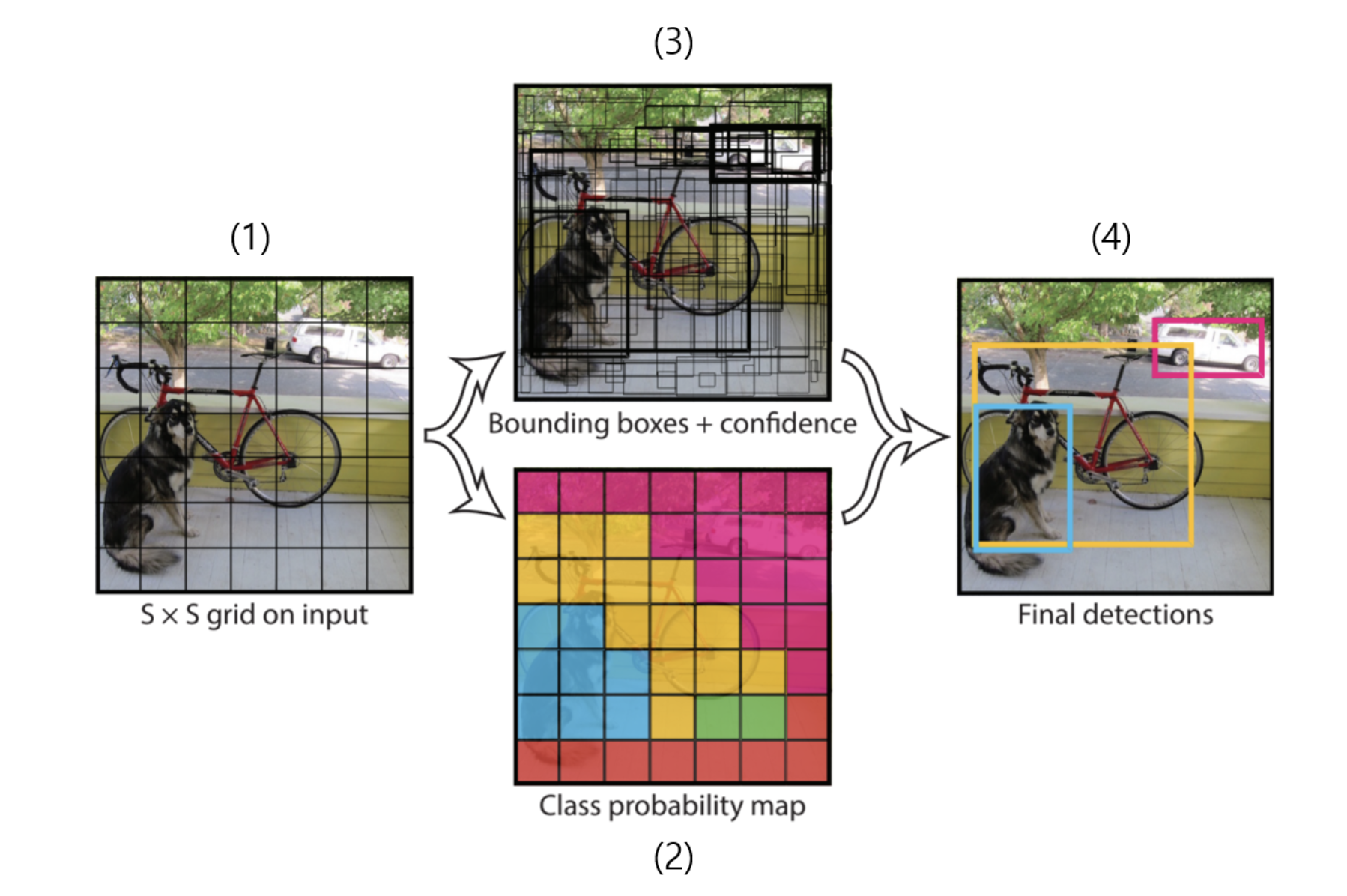
YOLO 모델에 새로운 사진이 입력되면, 위의 (1)처럼 그리드 영역으로 나눠준다. 그리고 네트워크를 통과하게 되면 (2),(3)의 결과를 얻을 수 있다.
각 그리드에 대해 그리드를 중심으로 미리 정의된 형태로 지정된 경계 박스의 개수(Anchor Boxes)를 예측하고 이를 기반으로 신뢰점수(confidence score)를 계산한다. 이때 높은 객체 신뢰도를 가진 위치를 선택해 객체 카테고리를 파악한다고 한다.
자세한 내용은 아래 글을 참고하면 좋을 것 같다.
https://ctkim.tistory.com/91
💡 그럼 버전별로 어떤 차이가 있는지 한 번 볼까?
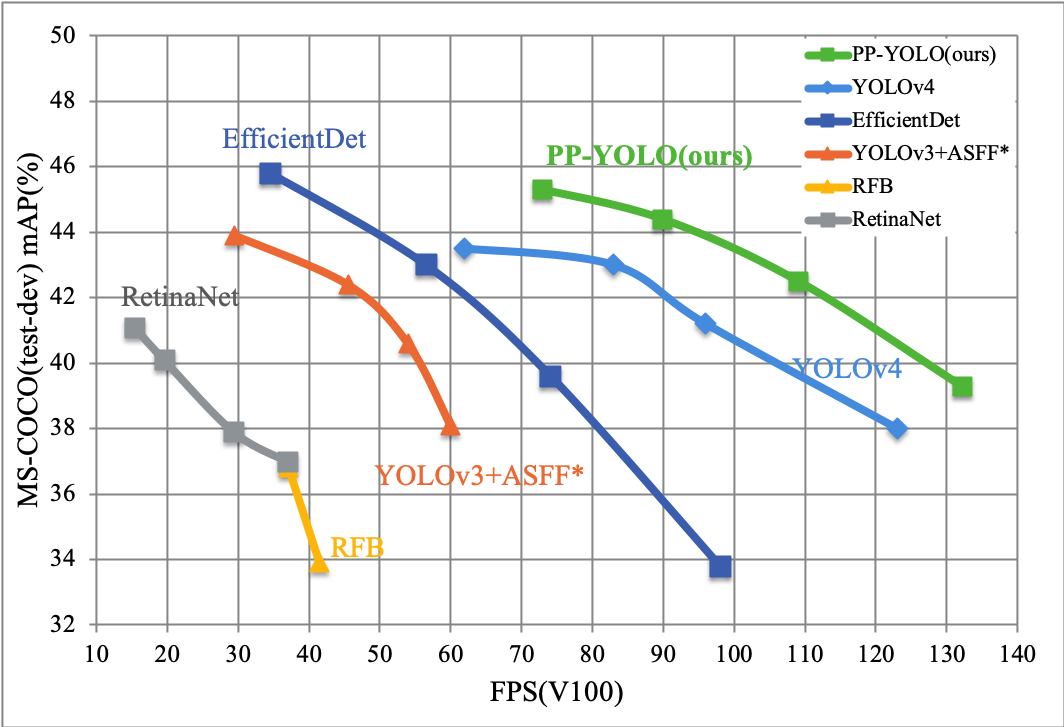
위 사진이 버전별 비교 그래프이다.
일단 원래 YOLO를 만든 사람은 YOLOv3까지 만들고 그 이후로 다른 버전은 더 이상 만들지 않겠다고 했다고 한다. 왜?
☝🏻 YOLOv3
백본 아키텍쳐 Darknet 53 기반
✌🏻 YOLOv4
v3에 비해 AP, FPS가 각각 10%, 12% 증가
v3에서 다양한 딥러닝 기법(WRC, CSP ...) 등을 사용해 성능을 향상
CSPNet 기반의 backbone(CSPDarkNet53)을 설계하여 사용
🤟🏻 YOLOv5
v4에 비해 낮은 용량과 빠른 속도, 성능은 비슷
YOLOv4와 같은 CSPNet 기반의 backbone을 설계
PyTorch 구현이기 때문에, 이전 버전들과 다름
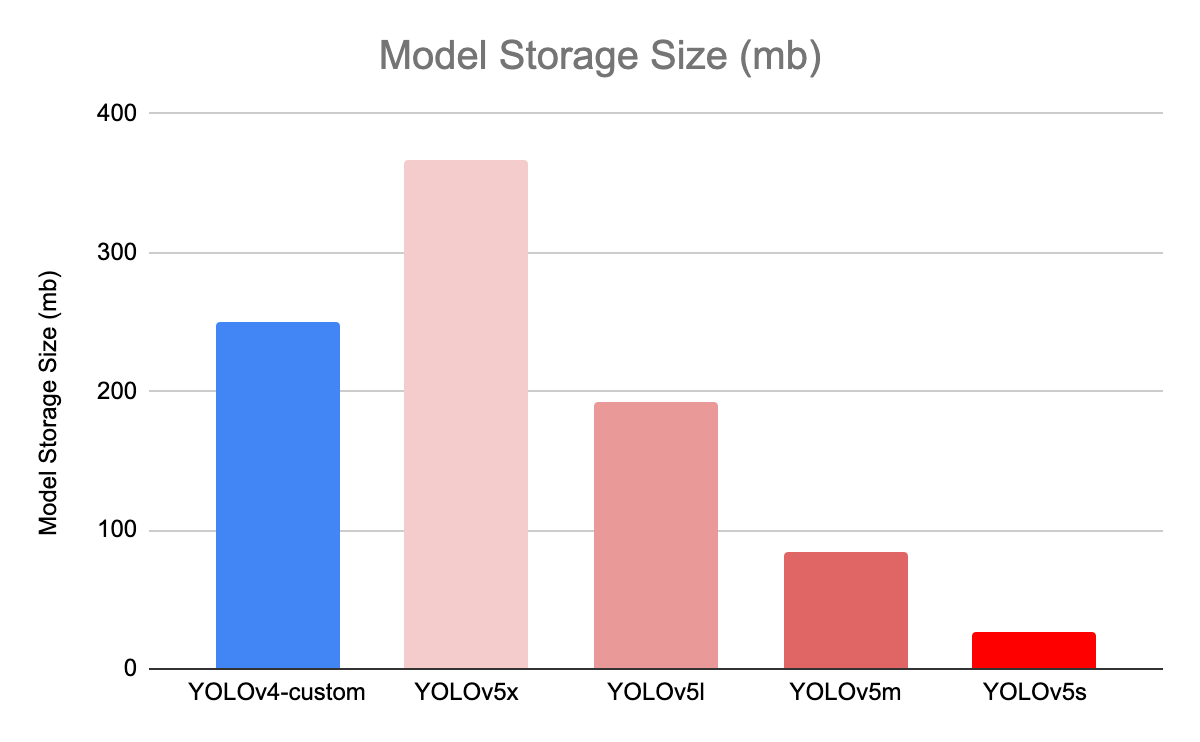
위에 사진을 보면 v5에서도 세분화된다. 정확도와 시간 성능에 따라 반비례하면서 달라지는데, 원하는 모델 결과가 정확도가 중요한지, 실시간으로 반영한다면 detection 시간이 짧은지를 비교해 고르면 될 것 같다.
아무래도 YOLOv5가 구현이 쉽고 속도도 빠르기 때문에 많이 사용되는 것 같다. 논문이 나오기만을 기다리는 사람들이 많은 것을 보니...
그리고 20년에 PP-YOLO 라는 모델도 나온 것 같은데, v3을 기반으로 한다고 한다. 하지만 아직 많이 쓰이고 있지는 않는 것으로 보인다.
간단하게 만약 모델의 성능 등을 검증할 필요가 있는 경우라면 v3를 사용하면 된다. 그리고 c++ 기반이기 때문에 만약에 임베디드화 할 예정이 있다 같은 경우, v3를 사용한다.
그리고 어플리케이션에 집중한다면 v5가 적합하다고 한다. 어쨌든 파이썬으로 구현할 수 있어 쉽고 빠르고 간단한 장점이 있어서 그런 것 같다.
아직 작동원리에 대해서는 조금 더 공부를 해봐야할 것 같다.🧐
이제 막 시작한 프로젝트가 CV 프로젝트이고 YOLO를 사용해 사물 인식을 해야한다. 그래서 아마 다음주에는 v5 사용법에 대해서 업로드를 하지 않을까 생각한다. 파이토치 구현이라 다루기 쉽다고 했으니까 날 실망시키지 않길 바래..
참고
https://nuggy875.tistory.com/20
https://ganghee-lee.tistory.com/34
https://rubber-tree.tistory.com/119
https://yong0810.tistory.com/30

안녕하세요. 현재 자율주행 로봇의 SLAM 알고리즘을 개발하는 업무를 하고 있는 개발자입니다.
YOLO에 관련된 내용을 공유해주셔서 감사합니다~!
블로그의 다른 글들을 살펴보니 머신러닝 개발에 관심이 많으신 것 같아 머신러닝을 공부하신 경험에 대한 간단한 대화(30~40분)를 나누고 싶어 이메일을 남깁니다.
irobou0915@gmail.com
오늘도 좋은 하루 보내세요!