Python #14
웹크롤링
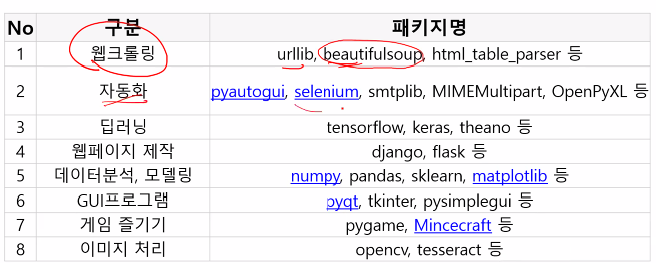
파이썬으로 할 수 있는 일들
- 과거에는 웹페이지 개발을 주로 하였다면, 최근에는 데이터 분석 분야에서 많이 활용
웹크롤링이란
- 웹페이지에 존재하는 정보를 수집하는 작업
- HTML 페이지를 가져와서 HTML/CSS 등을 파싱하고 필요한 데이터만 추출하는 기법
웹크롤링을 위한 라이브러리
- requests : 웹페이지에서 원하는 HTML 정보를 가져오는 모듈
- beautifulsoup4 : requests에서 가져온 HTML을 분석 및 가공하여 원하는 정보를 가져오는 모듈
라이브러리 설치
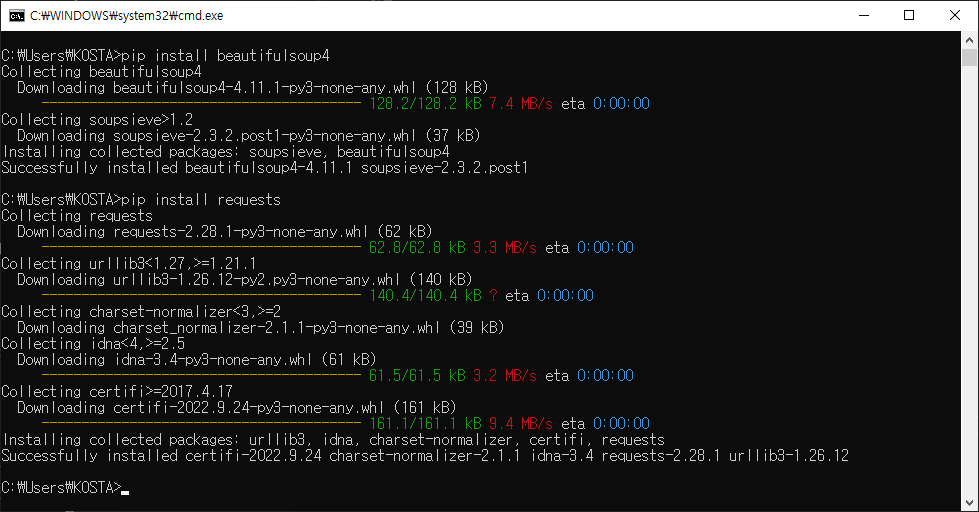
pip install beautifulsoup4
pip install requests
크롤링 예제
- ediya.html에서 메뉴이름 크롤링하기
ediya.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>이디야 메뉴판</title>
<link href="ediya.css" rel="stylesheet" type="text/css">
</head>
<body>
<div id="menu">
<hr>
<div id="coffee-menu">
<h1>COFFEE</h1>
<ul>
<li class="each">
<p class="each-menu">아메리카노</p>
<p class="each-price">3000원</p>
</li>
<li class="each">
<p class="each-menu">카페라떼</p>
<p class="each-price">3500원</p>
</li>
<li class="each">
<p class="each-menu">카푸치노</p>
<p class="each-price">4000원</p>
</li>
<li class="each">
<p class="each-menu">카페모카</p>
<p class="each-price">4000원</p>
</li>
</ul>
</div>
<hr>
<div id="ade-menu">
<h1>ADE</h1>
<ul>
<li class="each">
<p class="each-menu">자몽에이드</p>
<p class="each-price">3500원</p>
</li>
<li class="each">
<p class="each-menu">레몬에이드</p>
<p class="each-price">3500원</p>
</li>
<li class="each">
<p class="each-menu">유자에이드</p>
<p class="each-price">4000원</p>
</li>
<li class="each">
<p class="each-menu">청포도에이드</p>
<p class="each-price">4000원</p>
</li>
</ul>
</div>
</div>
</body>
</html>웹크롤링.py
from bs4 import BeautifulSoup
homepage = open ('ediya.html', 'r', encoding = 'utf-8')
html_doc = homepage.read() # 문자열로 리턴
homepage.close()
soup = BeautifulSoup(html_doc, 'html.parser') # BeautifulSoup이라는 라이브러리를 통해 파싱할 준비
result = soup.find_all('p', class_='each-menu') # 리스트로 받음
for data in result:
print(data.text)출력결과
아메리카노
카페라떼
카푸치노
카페모카
자몽에이드
레몬에이드
유자에이드
청포도에이드

알고 쓰자!