웹크롤링
import requests
from bs4 import BeautifulSoup
webpage = requests.get("https://www.daangn.com/hot_articles")
soup = BeautifulSoup(webpage.content, 'html.parser')
print(soup.ul.children)
for child in soup.ul.children:
print(child.string)내가 가진 html이 아닌 일반 사이트에서 가져오고 싶을 때, requests를 import한다.
requests 라이브러리
특정 사이트의 html을 통째로 가져온다.
BeautifulSoup 라이브러리
내부로 객체화(데이터 구조화)
- 태그 기반 find_all
- CSS 기반 select
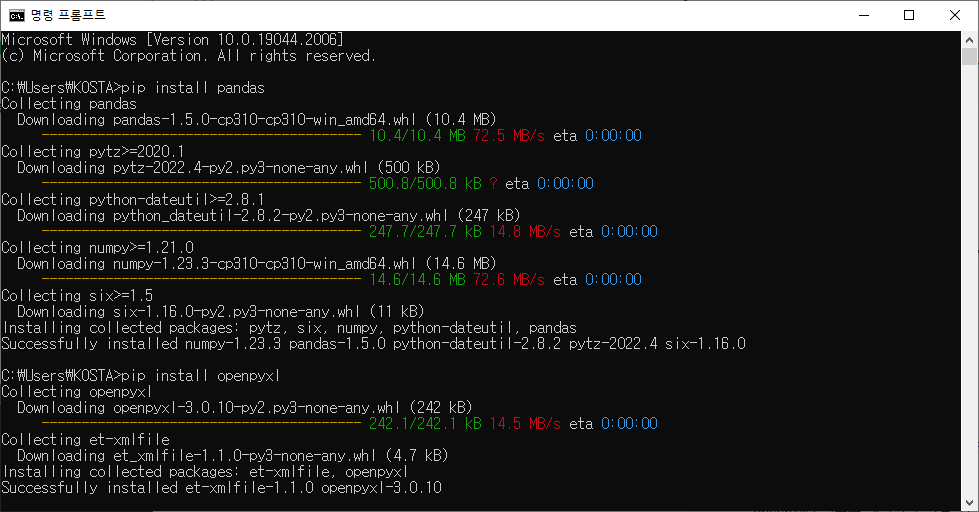
pandas, openpyxl 라이브러리
-
pandas : 데이터를 조작할 수 있도록 정형화시켜주는 역할
cmd에pip install pandas -
openpyxl : 텍스트 데이터를 엑셀파일 형태로 만들어줌
cmd에pip install openpyxl
import requests
from bs4 import BeautifulSoup as bs # BeautifulSoup 대신 bs라고 쓰겠다 선언
import pandas as pd
page = requests.get("https://library.gabia.com/") # 페이지 소스 가져오기
soup = bs(page.text, "html.parser") # soup = 구조화 된 데이터
elements = soup.select('div.esg-entry-content a.eg-grant-element-0')
titles = []
links = []
for index, element in enumerate(elements, 1): # enumerate : 순서를 나타내는 자료형
titles.append(element.text)
links.append(element.attrs['href'])
df = pd.DataFrame()
df['titles'] = titles # key, value 형태로 입력
df['links'] = links
df.to_excel('./data.xlsx', sheet_name='Sheet1')
requests는 한 페이지를 크롤링하지만, Selenium을 사용하면 여러페이지 크롤링도 가능하다.
빅데이터
정보란
-
의미없는 각각의 데이터들이 존재한다.
-
데이터를 필요에 맞게 가공을 해서 가치있는 결과를 만들어 낸 것을 정보라고 한다.
-
데이터가 정보의 원재료이지만 가공하지 않으면 의미가 없다.

-
금광을 데이터, 금을 정보라고 하자.
-
수많은 데이터 속에서 의미있는 정보를 찾아내는 것을 데이터마이닝이라고 한다.
-
데이터마이닝에 따라 적은 데이터로 정보를 많이 만들 수 있고, 많은 데이터로 정보를 못 만들 수도 있다.

데이터베이스란
- 의미있는 정보들을 체계적으로 관리하는 도구
- 데이터베이스는 어디에 쓰일지 정해져있는 데이터만 저장
- 데이터의 효율적인 저장, 관리, 해석
- 단점은 새로운 데이터의 저장, 관리, 해석이 필요할 때 유연성이 떨어짐
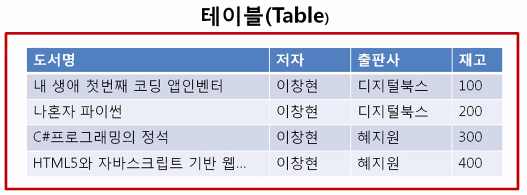
빅데이터의 등장
-
언제 어디에 쓸지도 모르는 데이터를 계속 모을 수 없다
⇒ 비용문제, 메모리 기술발전과 가격하락 -
데이터를 활용하는 모두가 아저씨처럼 창고를 잘 활용할 수 없다.
⇒ 데이터 분석/해석의 어려움, 인공지능의 발전 -
빅데이터
⇒ 누가 사용하냐에 따라 데이터로 만들어 낼 수 있는 정보는 무한대
⇒ 인공지능을 활용하여 다양한 분야에 활용
빅데이터의 개요
21세기의 석유라고 부르는 이유
- 석유를 정제하여 휘발유와 같은 연료를 얻는다.
- 그 과정에서 화학섬유, 플라스틱 제품, 의약품 원료 등을 얻을 수 있다.
- 데이터도 그 자체로 큰 의미를 가지지 않을 수 있다.
- 여러 과정을 통해 정제되고 분석되면서 예상치 못했던 것까지 발견할 수 있다는 점.
빅데이터란
- 기존 데이터베이스 관리 도구의 능력을 넘어서는 대량의 정형 또는 심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술이다.
빅데이터의 특징
- 데이터 저장 ⇒ 데이터 관리 ⇒ 데이터 추출 ⇒ 데이터 처리 ⇒ 데이터 시각화 ⇒ 데이터 분석
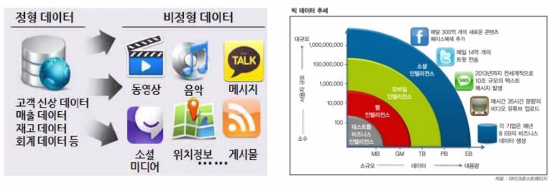
정형 데이터와 비정형 데이터
정형 데이터
- 엑셀과 같은 형태
- 관계형 데이터베이스의 형태
비정형 데이터
- 그림, 영상, 문서, 의료기록, 음성정보처럼 형태가 구조화되지 않은 데이터
- 이메일, 트위터, 블로그, SNS처럼 모바일 기기와 온라인에서 생성되는 데이터
- 일정한 규격이나 형태를 지닌 숫자 데이터가 아님.
- 수집된 전체 데이터의 80% 이상 비정형 데이터
빅데이터의 활용
첫 단계는 Raw Data를 수집하는 것
- 페이스북, 트위터 같은 SNS의 텍스트 데이터(가장 큰 빅데이터의 소스)
- 지하철, 버스 사용자의 실시간 사용 데이터를 수집하는 로그 데이터
- 영상을 분석하기 위한 시각 데이터
- 소리를 분석하는 음성 데이터
- IoT 센서를 통해 발생하는 데이터
두 번째는 데이터 전처리 단계(오류 줄이고, 정확도 높임, 소요시간 줄임)
⇒ 데이터 구조화
- 필요없는 데이터를 제외시키는 것
- 데이터를 컴퓨터가 이해할 수 있는 구조로 변환
- 수집된 데이터를 분석할 수 있도록 정리
빅데이터의 시각화
-
빅데이터가 우리 시대에 중요한 이유는 객관적 의사 결정을 도와준다는 점이다.
-
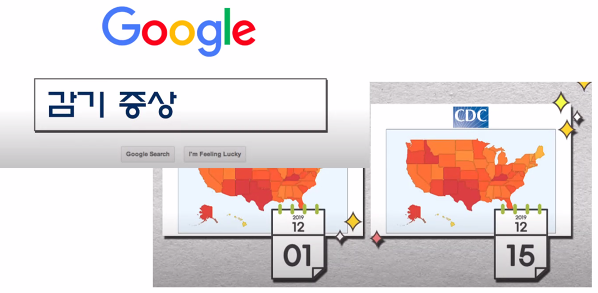
구글 - 빅데이터를 활용해 미국에 독감 유행 예측, 대선 선거 예측
질병통제예방센터보다 2주정도 더 빠르게 독감을 예측
-
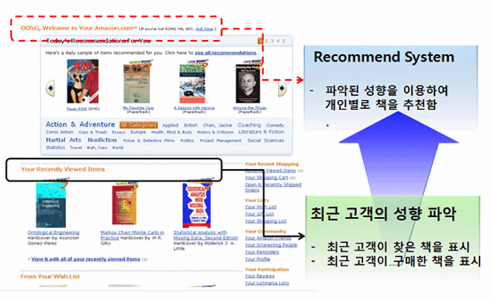
아마존 - 추천 상품 서비스 제공, 총 매출의 1/3 이상이 이 서비스에서 발생
-
넷플릭스 - 하우스 오브 카드 제작 시 시청자들의 성향 분석, 넷플릭스 이용자의 85%가 하우스 오브 카드를 시청함.

