이번에 캐글 스터디 시작하면서 내가 시도한 방법이나 다른 노트북, 스터디에서 배운 방법들을 나중에 다시 보려고 정리하는 글.

Regression with a Tabular California Housing Dataset
|| Playground Series - Season 3, Episode 1
https://www.kaggle.com/competitions/playground-series-s3e1
California Housing Dataset에서 훈련된 딥 러닝 모델에서 생성된 데이터 세트.
MedHouseVal (한 블럭 내의 가계의 주택 중앙값) 을 예측.
👇 내가 시도한 파트
EDA
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 37137 entries, 0 to 37136
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 37137 non-null int64
1 MedInc 37137 non-null float64
2 HouseAge 37137 non-null float64
3 AveRooms 37137 non-null float64
4 AveBedrms 37137 non-null float64
5 Population 37137 non-null float64
6 AveOccup 37137 non-null float64
7 Latitude 37137 non-null float64
8 Longitude 37137 non-null float64
9 MedHouseVal 37137 non-null float64
dtypes: float64(9), int64(1)train data 37137개
모든 feature가 float 형태, null값은 존재하지 않는 것을 확인.
round(train_data.describe(), 3)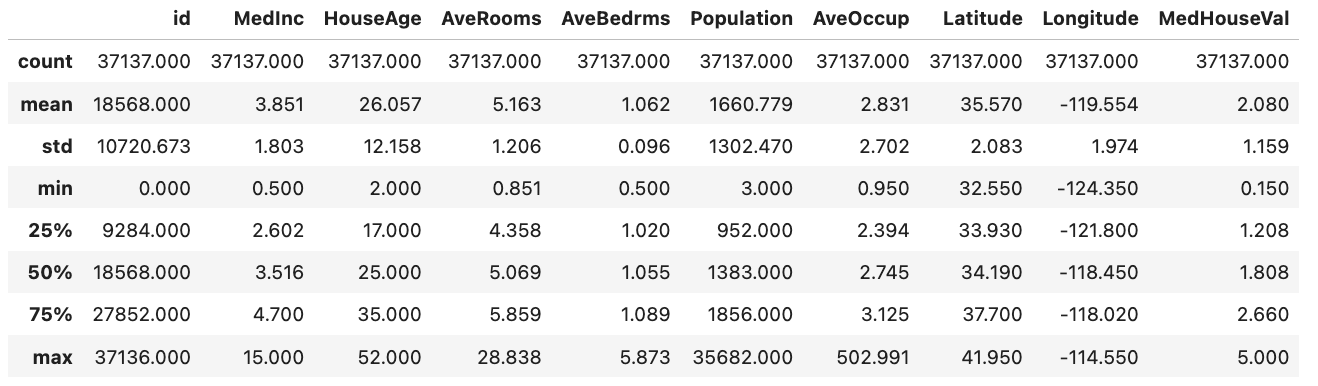
Target variable
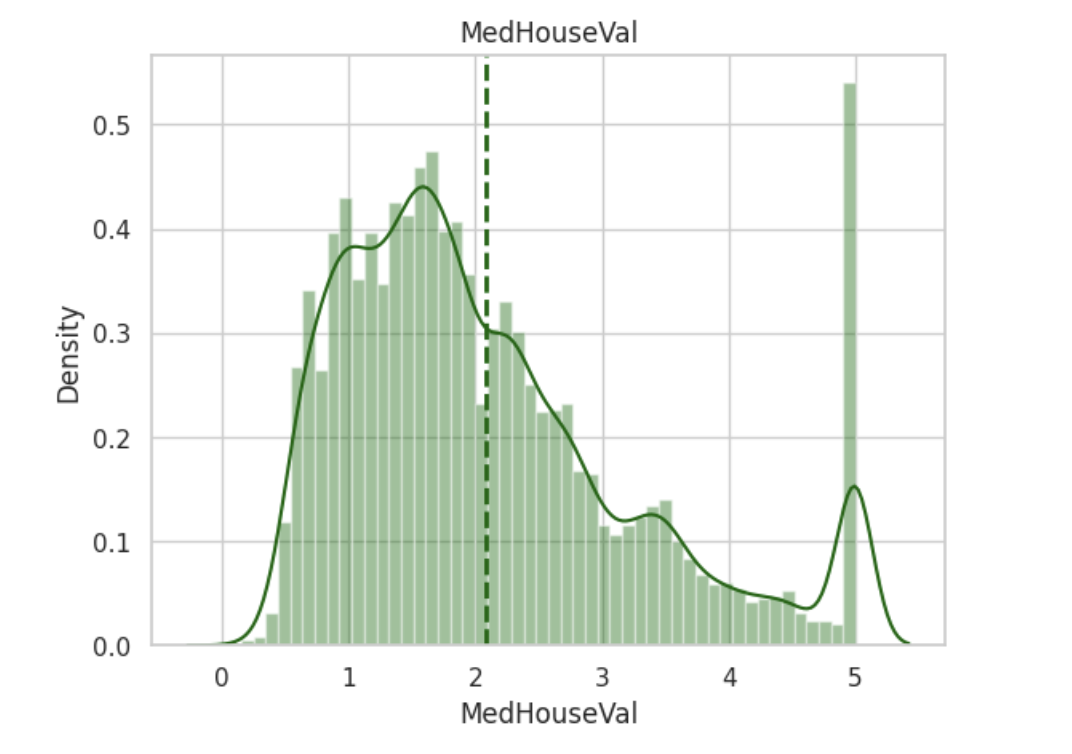
- Target 값은 1~5 사이에 분포하며 평균값은 2
- 대체적으로 1~2 사이에 가장 많이 분포
- 값이 5인 부분이 눈에 띄게 높음
→ 이상치일까? 사용할 수 있는 값일까? 어떤 특징이 있을지.
Correlation
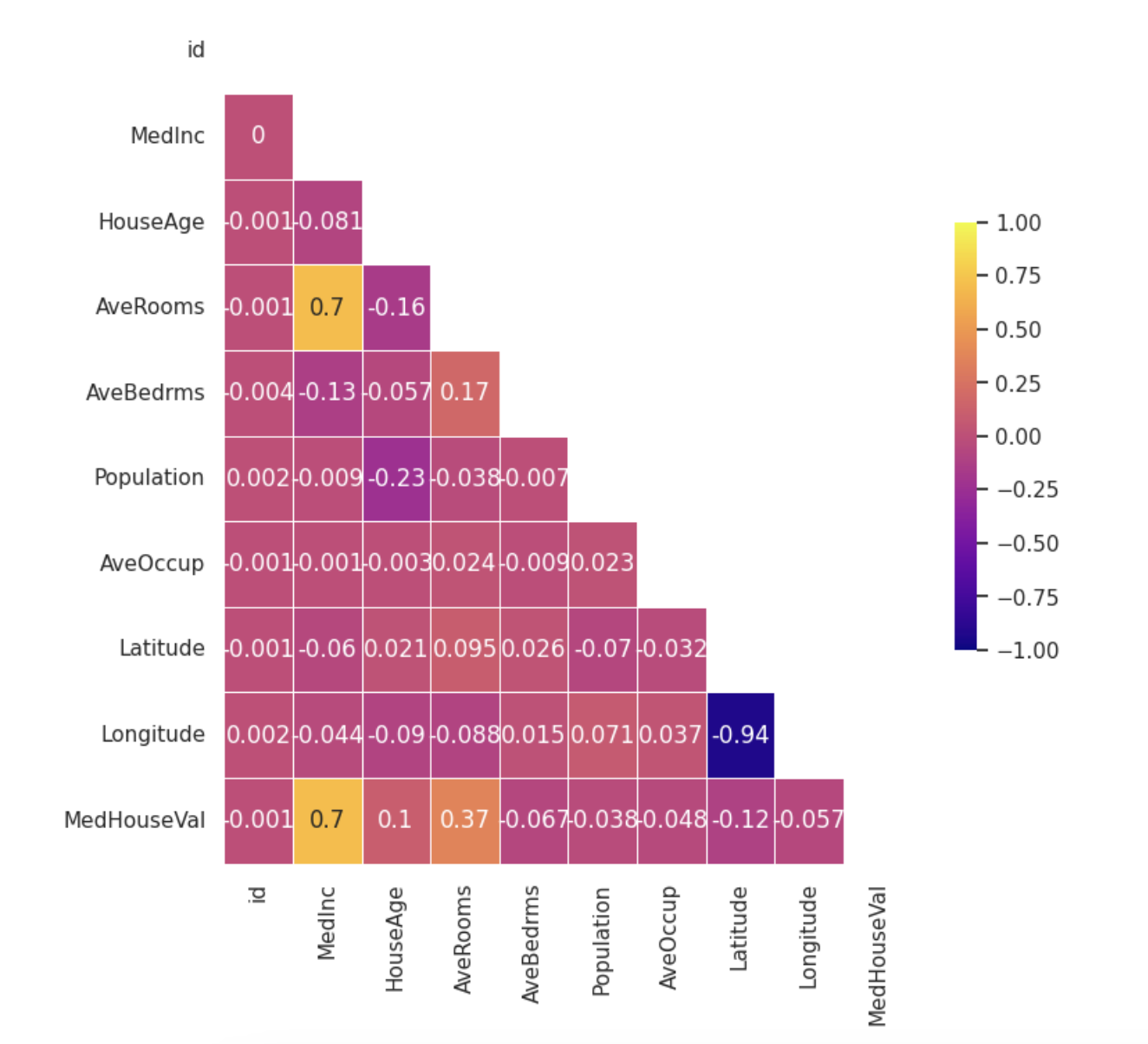
MedHouseVal 는 MedInc, AveRooms, HouseAge 와 상관관계가 있음을 확인
Pairplot / Scatter Matrices

-
MedHouseVal및MedInc관계는 선형적임을 확인할 수 있음. 약간의 편차는 있음. -
MedHouseValvsHouseAge관계에서는 데이터가 완전히 분산됨을 확인(비선형적) 거의 모든 부분에 데이터가 있음을 확인 가능.
→ KDE를 보았을 때, 왼쪽 아래쪽에 최고점이 있는것을 확인할 수 있다.
Q. 이는 집의 연식이과 상관이없다고 볼 수 있을까?
연식이 오래되면 집 값이 저렴해질거라고 생각했는데 오히려 연식이 뚜렷하게 오래된 집의 가격이 엄청 높게 분포된 것 또한 확인할 수 있음. (고풍스러운 고저택 느낌인가..?) 연식이 오래되지 않은 새집일수록 집 값은 비싸질거라고 생각했던 것도 완전히 그런 것은 아님을 확인할 수 있었고, 오히려 적당한 연식의 집이 저렴해 보임. -
MedHouseValvsLatitude관계에서는 두 가지로 나뉘어있음을 확인 가능.
→ 중요한 feature로 활용할 수 있을 것 같은데 어떻게 해석해야할지.. -
AveRooms은 특정 구간에 분포되어있는 것을 볼 수 있는데, 사실 방 개수의 평균이라 보통 1~2개일거라 크게 유의미해보이지 않음.
커널 밀도 추정(KDE: Kernel Density Estimator): 커널함수를 이용한 밀도 추정의 방법 중 하나
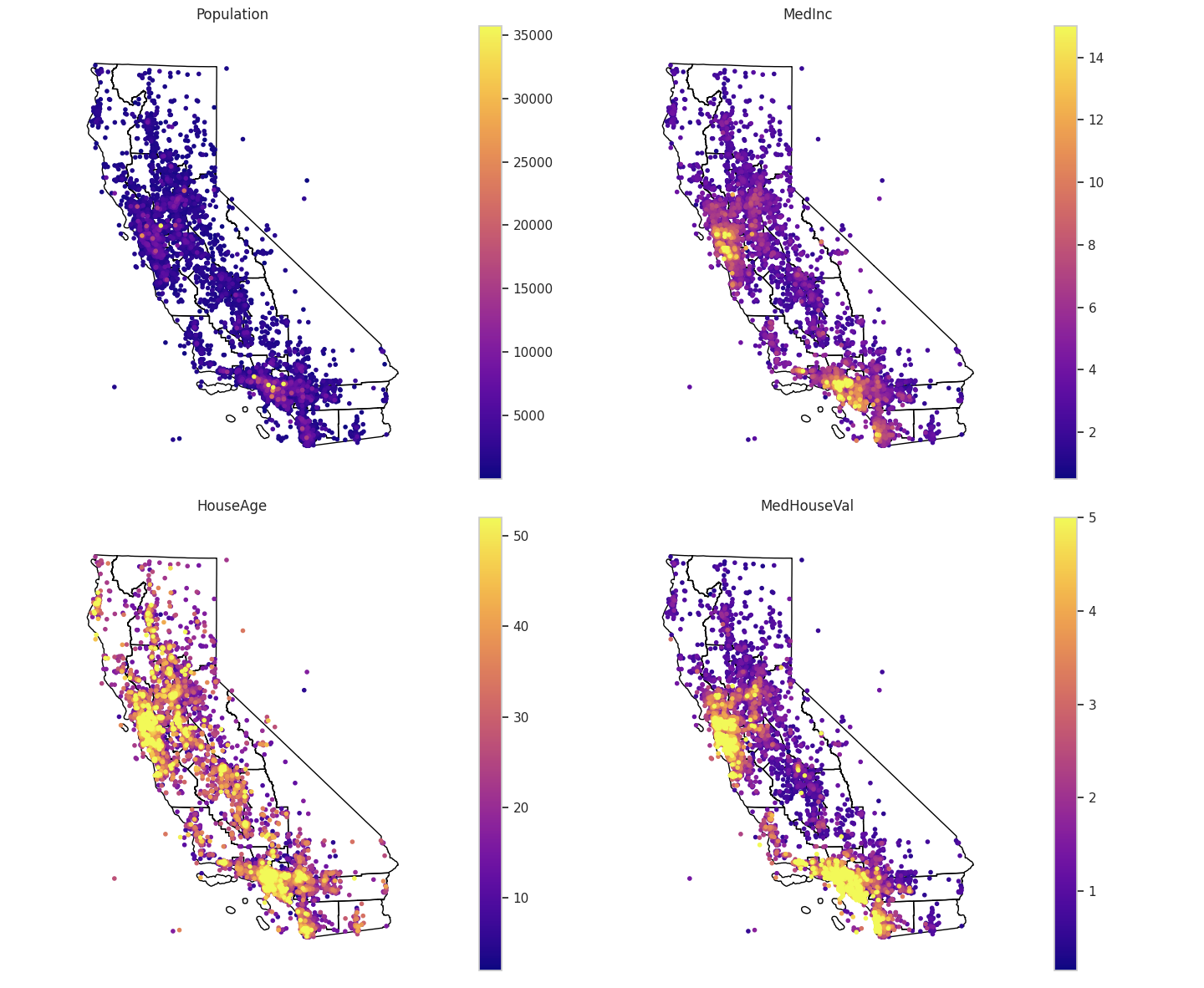
Geospatial multivariate data
Feature Engineering
...을 진행했어야했는데 모든 feature를 다 사용해서 우선 진행했다.
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
reg.score(X_train, y_train)
>> 0.6076397171443488
reg.score(X_test, y_test)
>> 0.5925494230112975
[score output]
R squared of linear regression : 0.5925494230112975
Adjacent R squared of linear regression : 0.5924323521275598
Mean absolute percentage error of linear regression : 30.818947088276737 %
RMSE : 0.7420941599757712우선 baseline 점수는 이렇게 시작한다고 보고..
features = ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population',
'AveOccup', 'Latitude', 'Longitude']outlier 처리와 features 중에서 유의미한 것들을 판단해보려고했는데..
스터디 진행하면서 스터디원분 중 한분이 Autogluon이라는 AutoML 도구..?를 소개해주셨다. (진짜 세상이 너무 빠르게 좋아져요..)
autogluon에서 지원하는 알고리즘들을 테스트해서 가장 좋은 성능의 알고리즘을 보여주고 중요한 feature가 무엇인지도 알려준다..ㄷㄷ
알고리즘별로 hyperparameter tuning도 할수있던걸로 기억하는데 자세한건 따로 찾아봐야할듯..
아무튼 사용법이 간단하고 직관적으로 보여줘서 엄청 편했다. (나의 할일이..)
너무 신기해서 다들 이걸 사용해봄(ㅋㅋㅋ)
Autogluon
!pip install autogluonautogluon을 설치해주고 시작
from autogluon.tabular import TabularPredictor
from sklearn.model_selection import train_test_split
predictor = TabularPredictor(label='MedHouseVal').fit(train_data=train_data) #auto_stack = True
print(predictor.fit_summary())
print(predictor.get_model_best())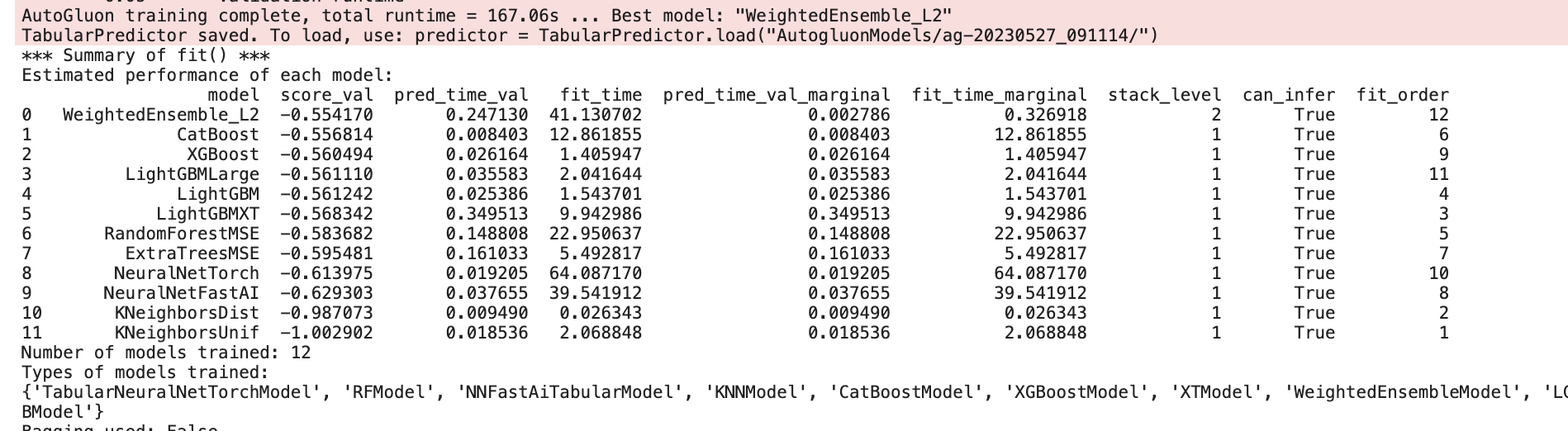
fit_summary()를 하면 이렇게 각 모델을 fitting한 후 결과 요약을 보여준다.
score_val는 당연하고 얼마나 걸렸는지 시간과 fitting한 모델의 타입이나 하이퍼파라미터..? 까지 보여주는것 같다.
get_model_best()하면 가장 성능이 좋은 모델을 보여준다.
여기서는 WeightedEnsemble_L2
# 각 feature 중요도 확인
featureimp_df = predictor.feature_importance(train_data)
print(featureimp_df)
# 각 모델 훈련 성능 평가
leaderboard_df = predictor.leaderboard(train_data, silent=True)
print(leaderboard_df)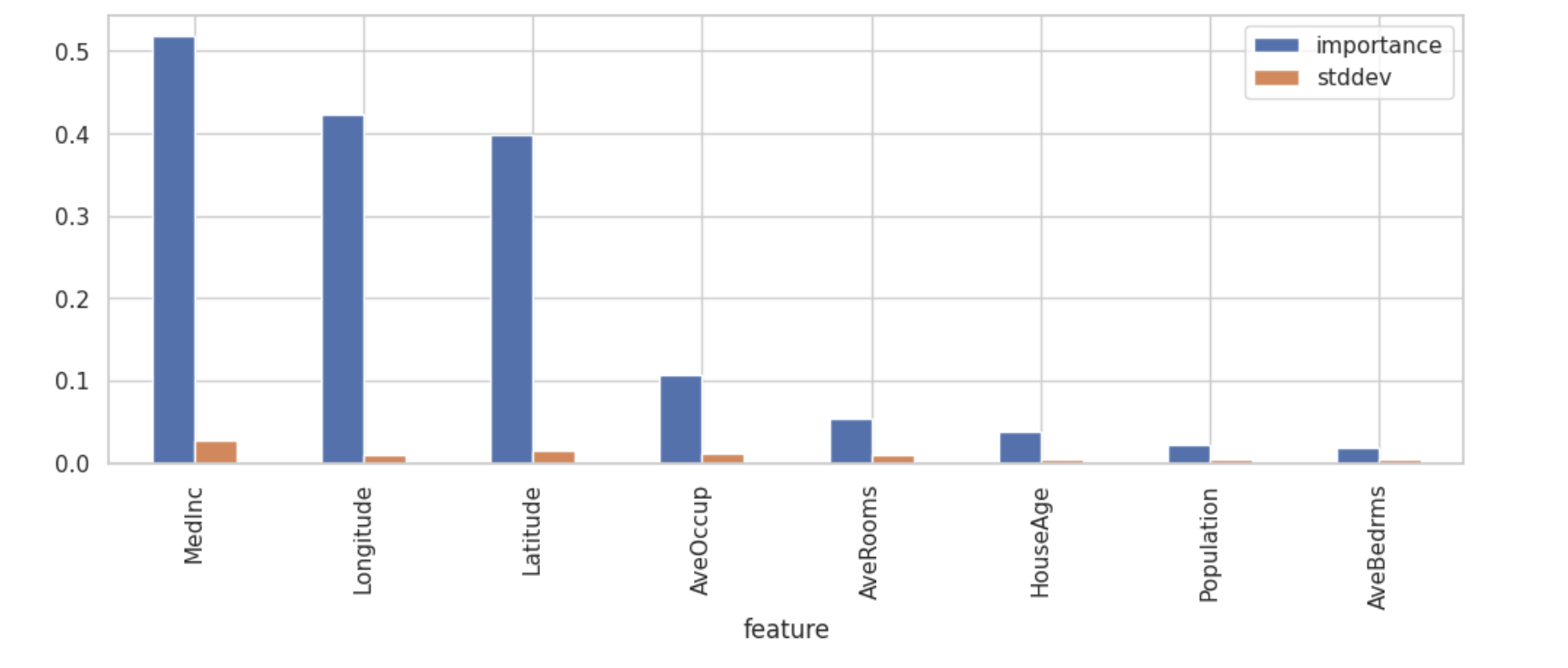
이렇게 feature들의 중요도를 확인할 수 있었고 그래프로 그려서 확인했을 때,
MedInc, Longitude, Latitude의 중요도가 높은 것을 확인할 수 있었다.
위도 경도의 중요도가 상당히 높은 것이 의외였었는데,
위의 지리데이터 시각화한것을 참고해보면 위치에 따라 가격이 분포도 달라졌던것을 확인할 수 있었다.
일단 해당 에피소드는 여기까지 진행되었었는데,
스터디원의 진행상황을 참고했을때 위도/경도를 참고해서 feature engineering을 진행했다.
- 원본 위도 및 경도 값에서 지역적인 패턴을 추출
- 위도와 경도를 클러스터로 그룹화한 후, 결과를 새로운 범주형 변수로 사용
- 지역 특성을 나타내는 추가적인 변수를 생성
같은 과정을 통해서 새로운 feature를 생성했다. 해당 노트북 참고하셨다고 한다.
( 어렵다.. )
느낀점
- 데이터 타입에 따른 시각화 방식 고민하기
무조건 막대그래프부터 그리는게 아니라 데이터 형태에 따라 어떤 방식으로 시각화를해야 데이터를 해석하기 좋은지 생각해가면서 그려보기 - 시각화한 자료를 보고 해석하는 연습 필요
데이터 시각화를 해도 해석을 잘 못하니 인사이트 뽑아내는 부분에서 많이 헤메는것 같다.. 다른 노트북도 많이 참고해가면서 감을 익혀보자 - feature가 어떤걸 의미하는지 제대로 파악하고 시작하기
- 내 생각, 왜 그렇게 생각하는지 잘 정리하고 적어놓기
EDA, 피처엔지니어링 진행하면서 왜 그렇게 생각했는지 제대로 적어놓지 않으니 나중에 다시 보거나 다르게 시도할때 근거가 빈약해지고 참고하기 어려운것 같다. 제대로 메모해놓기.
처음에 뭐부터해야할지 조금 어리버리했던것같은데,,
그래서그런지 다른사람 노트북 참고하느라 진행이 많이 느렸던것같다🥲
feature 뽑는 아이디어는 어떻게 생각하는걸까 노트북 참고할때마다 놀라기도하고..😲
