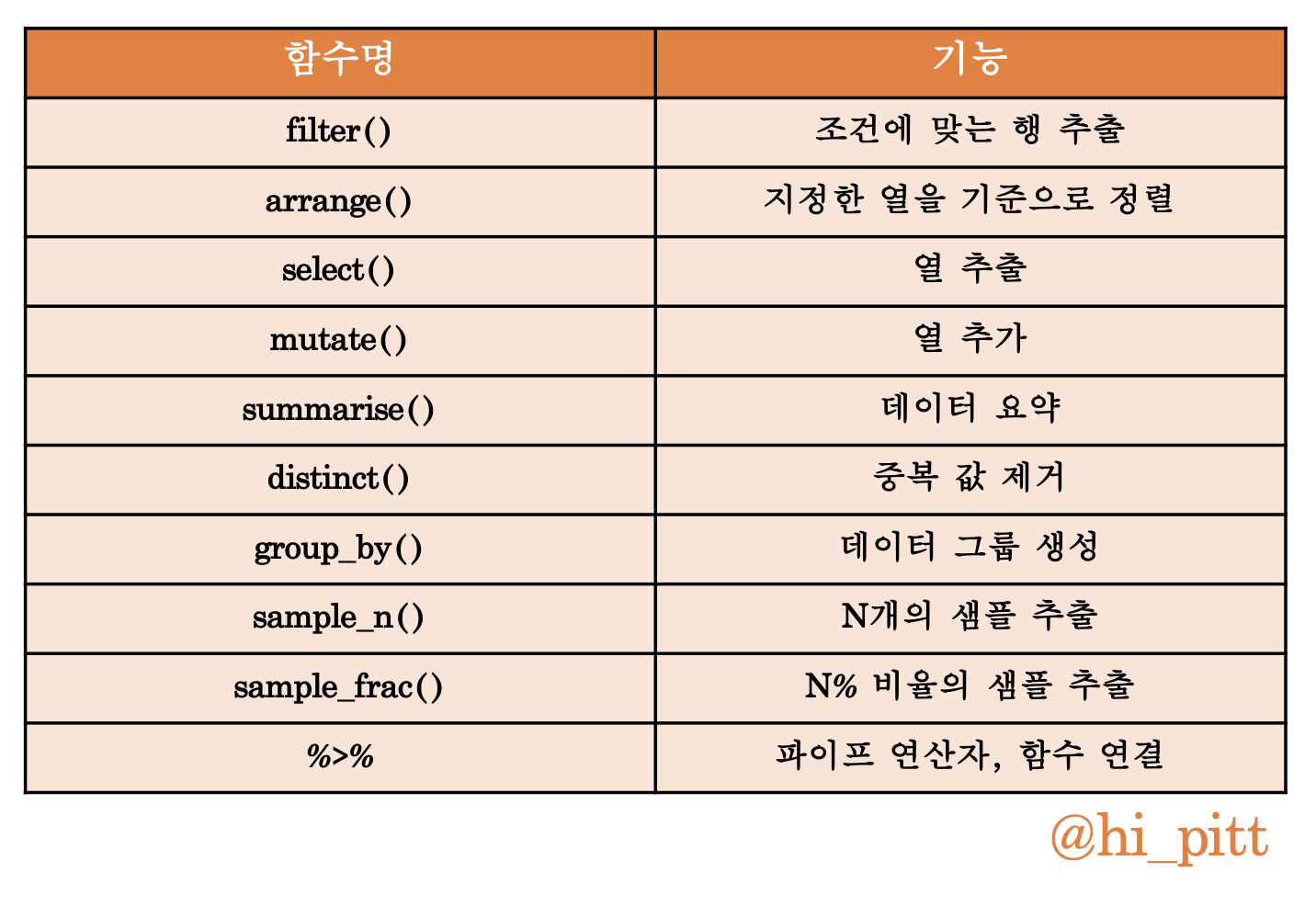
[스터디_R] dplyr 패키지
- dplyr 패키지 실습
- dplyr 주요 함수
- mtcars 데이터를 이용한다.
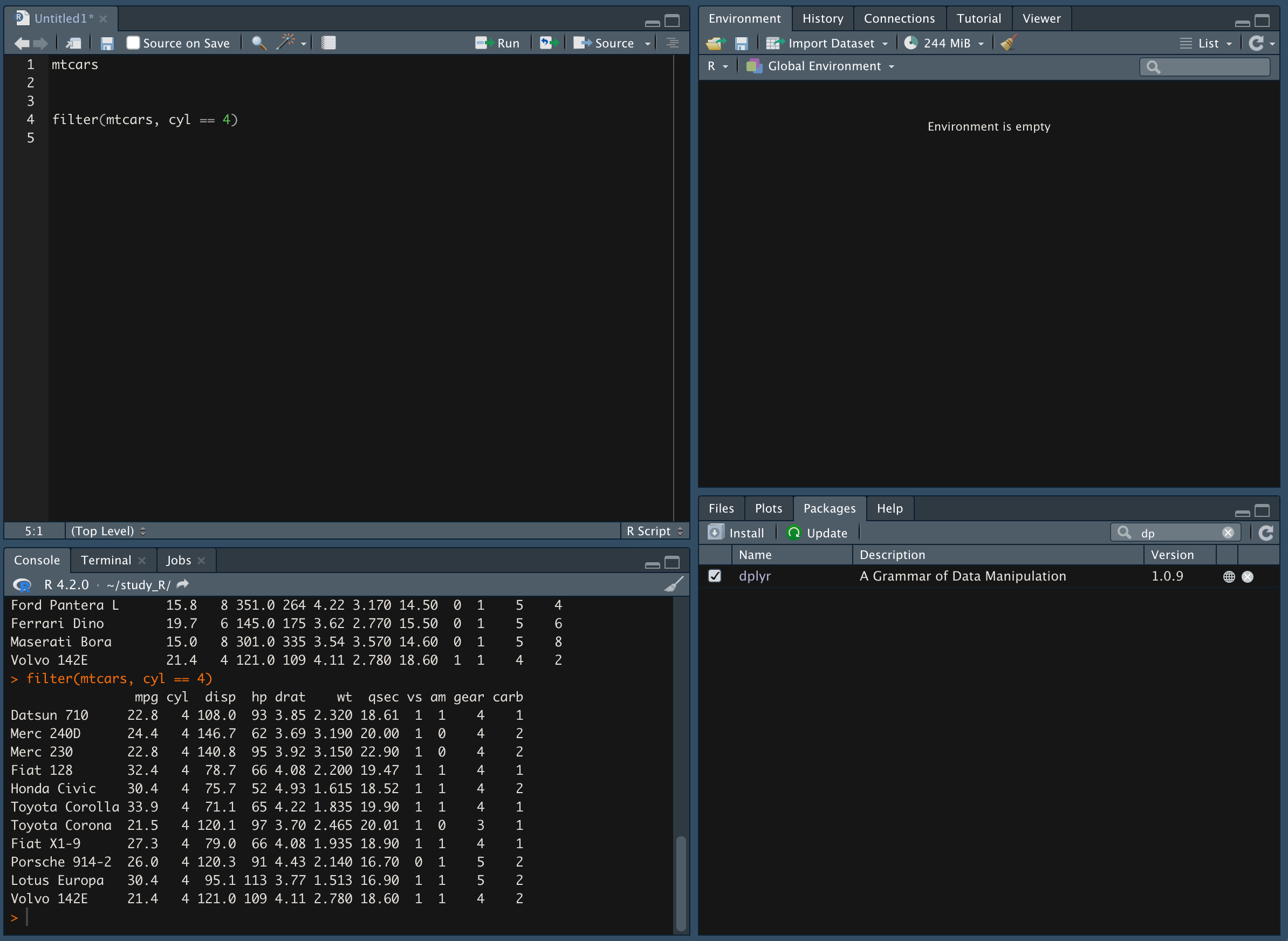
filter() 함수를 이용해 데이터를 추출한다.
-
cyl 값이 4인 자동차
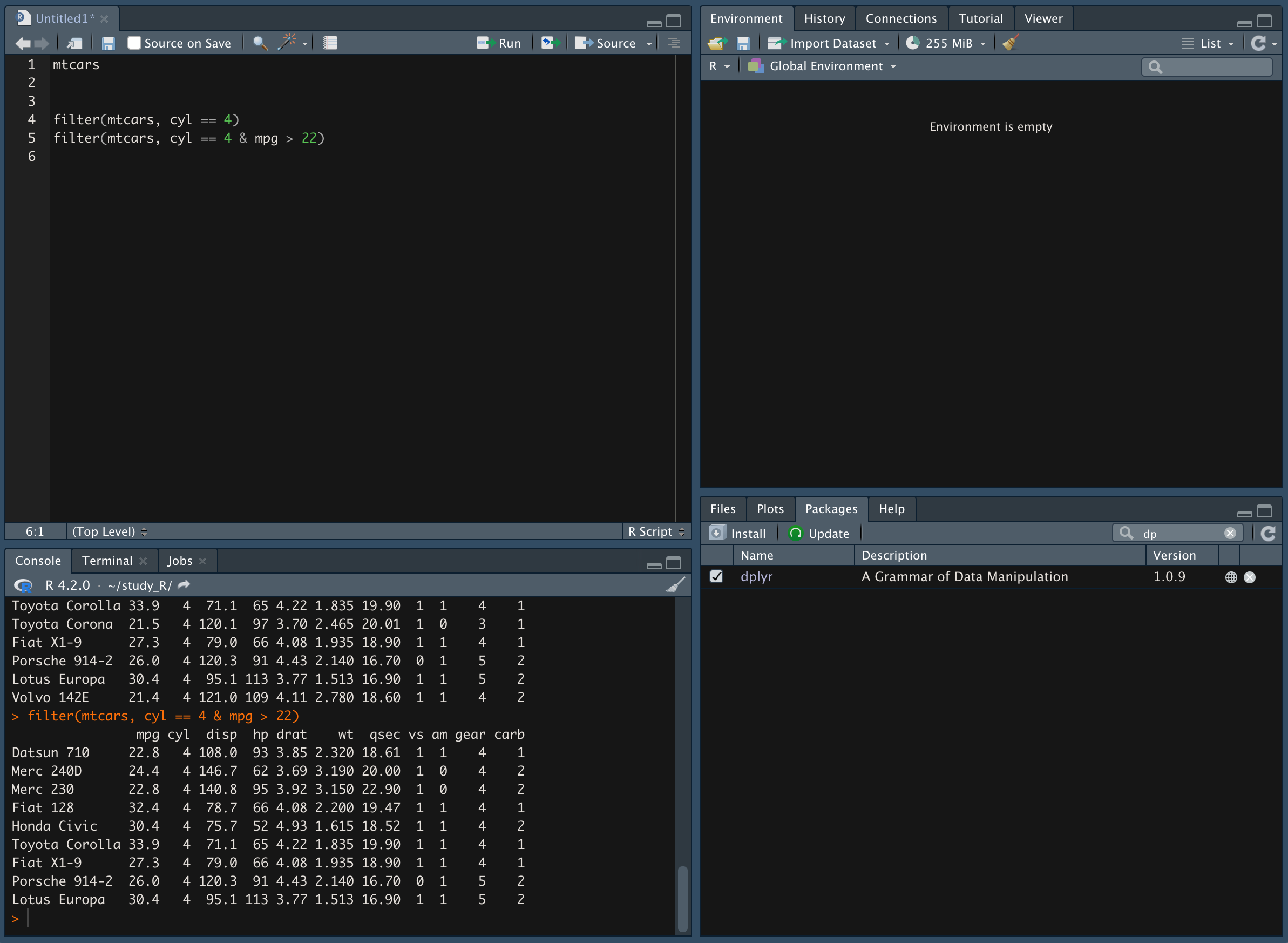
-
cyl 값이 4이고, mpg가 22 이상인 자동차
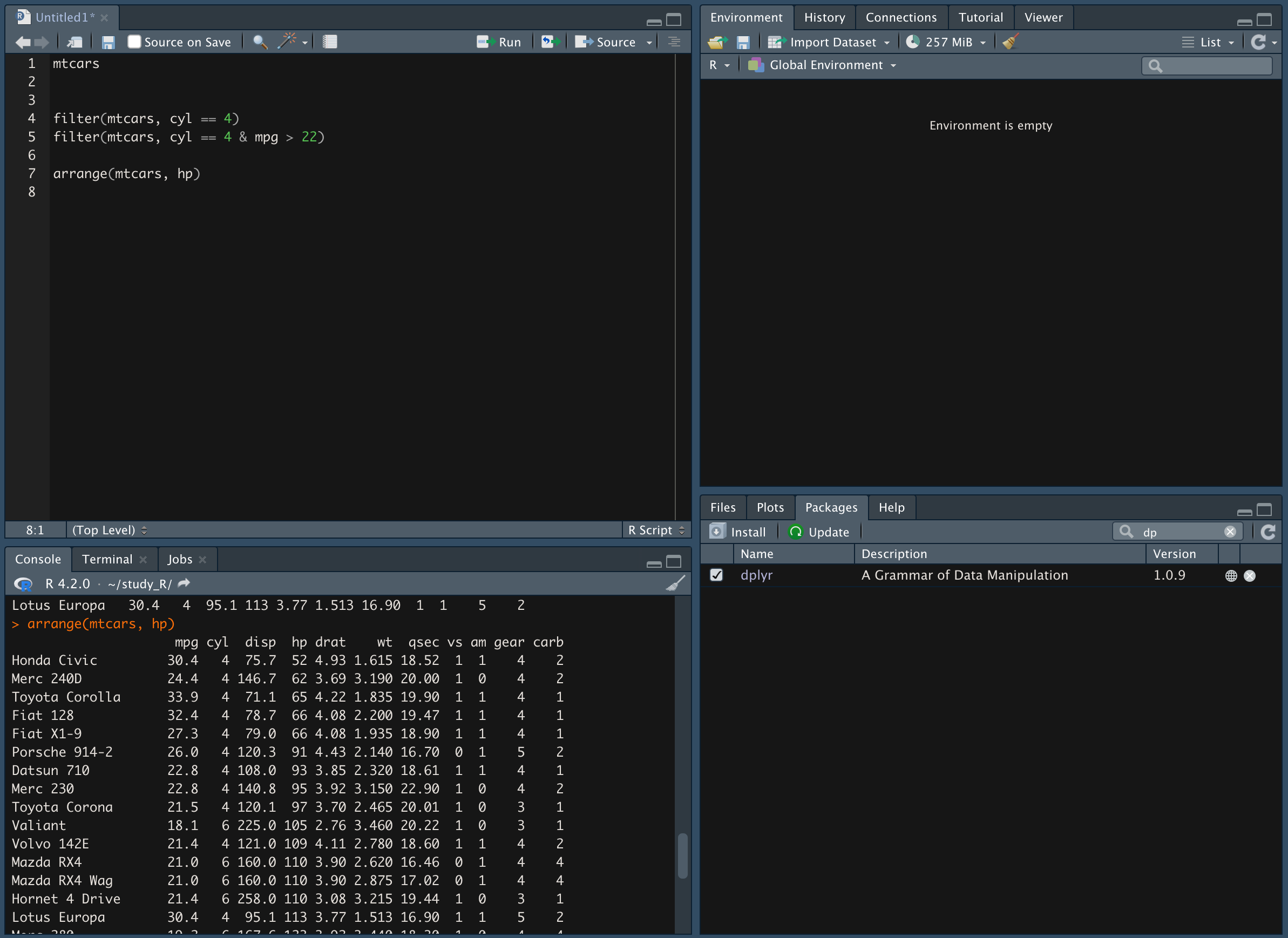
arrange() 함수를 이용해 데이터를 추출한다.
-
hp 값을 기준으로 오름차순
-
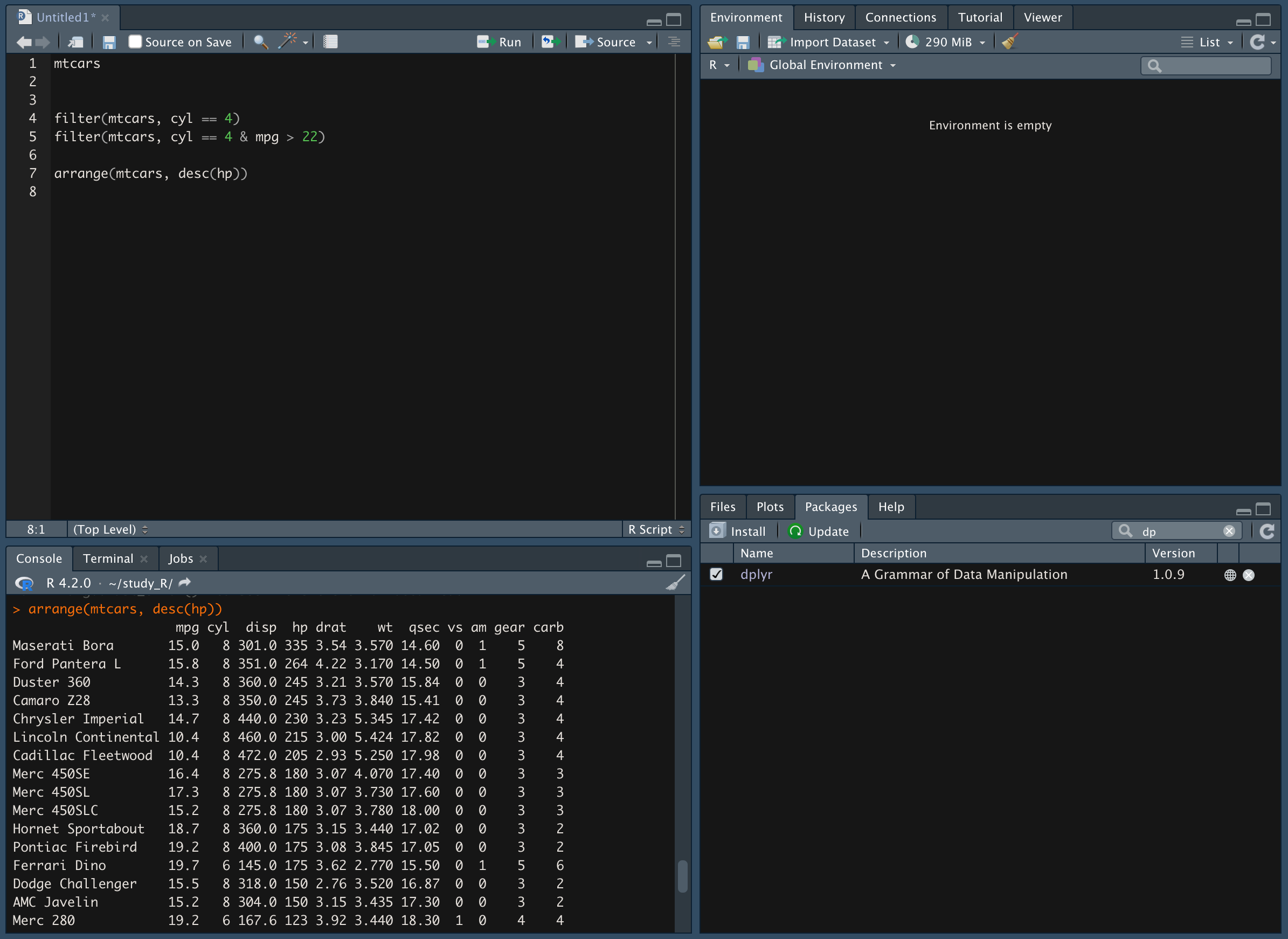
hp 값을 기준으로 내림차순
-
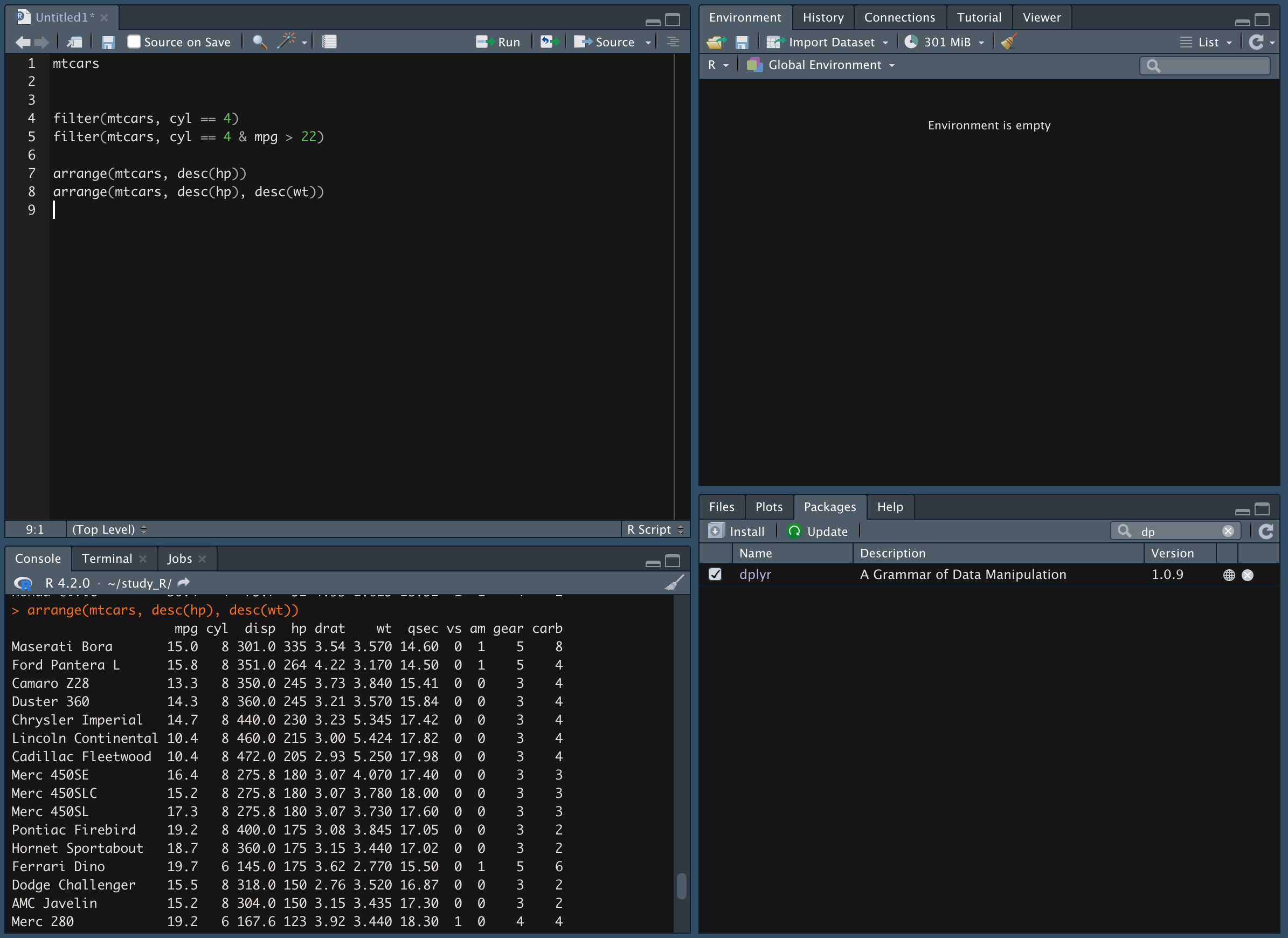
hp 값을 기준으로 내림차순하고, 동일 값 있을 경우 wt 값을 기준으로 내림차순
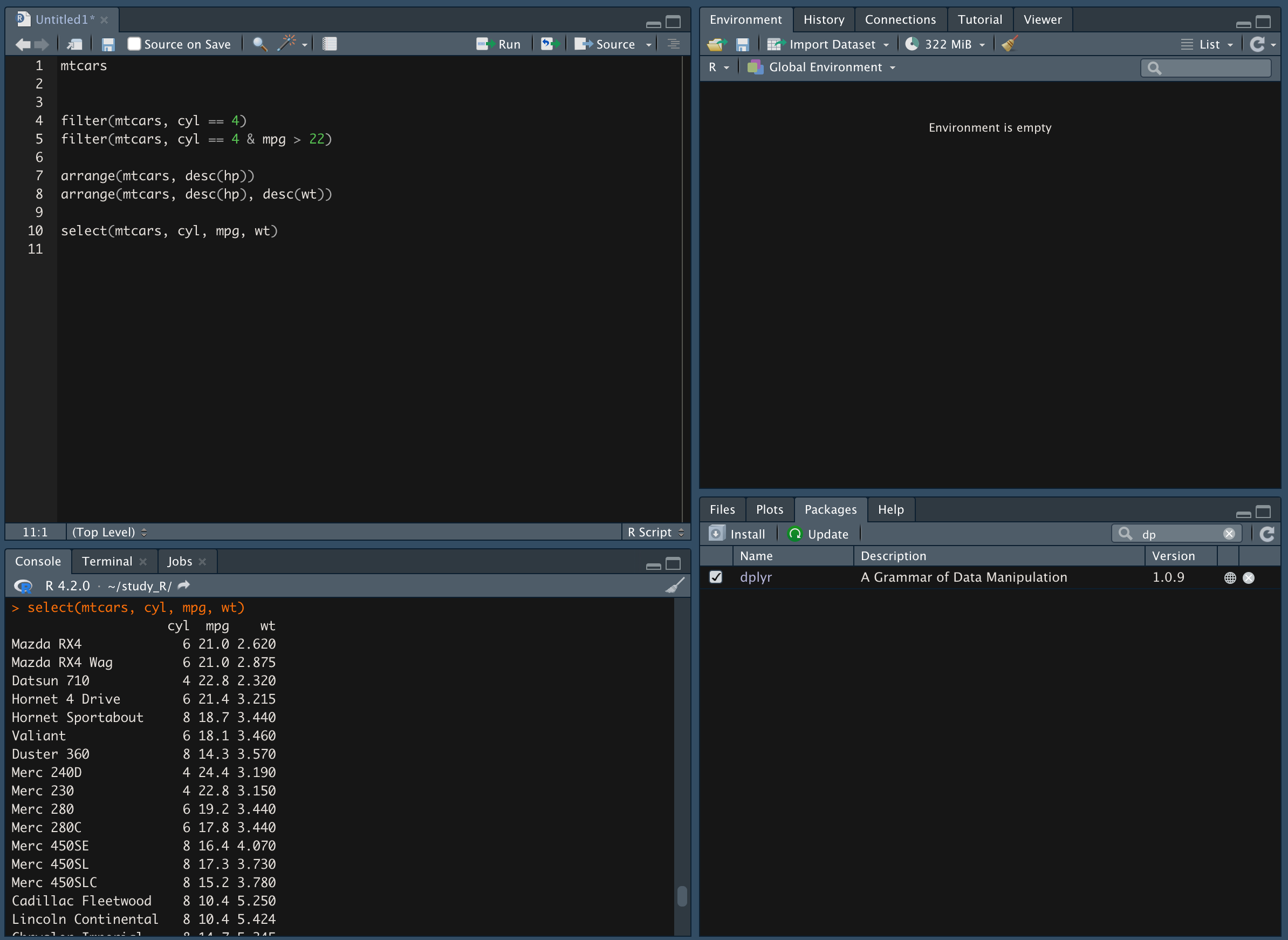
select() 함수를 이용해 데이터를 추출한다.
-
mtcars 데이터에서 cyl, mpg, wt 데이터만 추출
-
select 함수 사용 시 오류가 발생하면 dplyr::select()로 함수를 사용한다.
- 데이터 추가 및 중복 데이터 제거하기
mutate() 함수를 이용해 데이터를 추가한다.
- years="1974" 열을 추가
- rank로 순위를 측정한 열을 추가
distinct() 함수를 이용해 중복값을 제거한다.
-
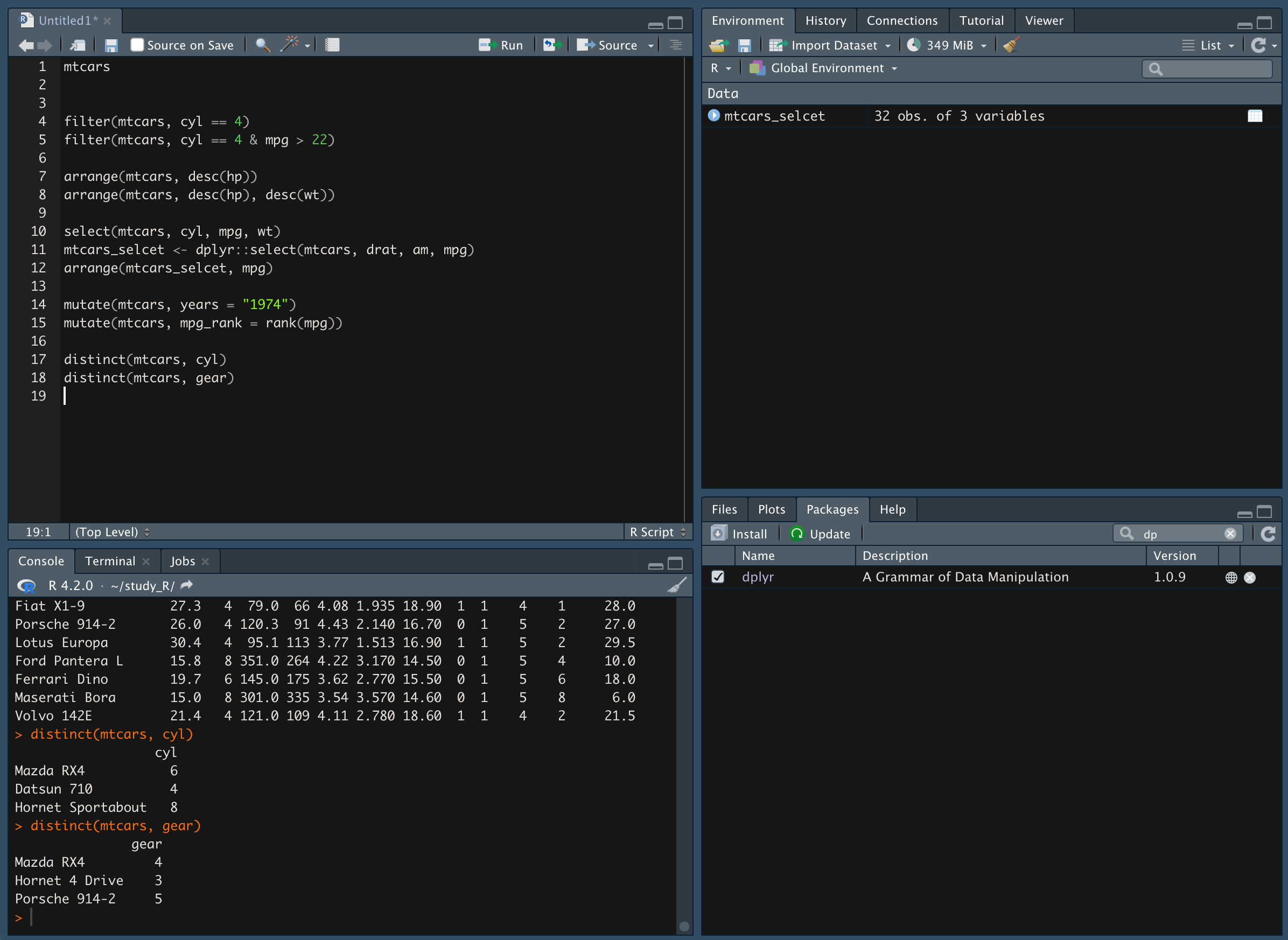
cyl 중복 값 제거
-
gear 중복 값 제거
-
cyl와 gear 중복 값 제거
-
and 조건이기 때문에 두 값이 모두 중복 될 때만 제거 된다.
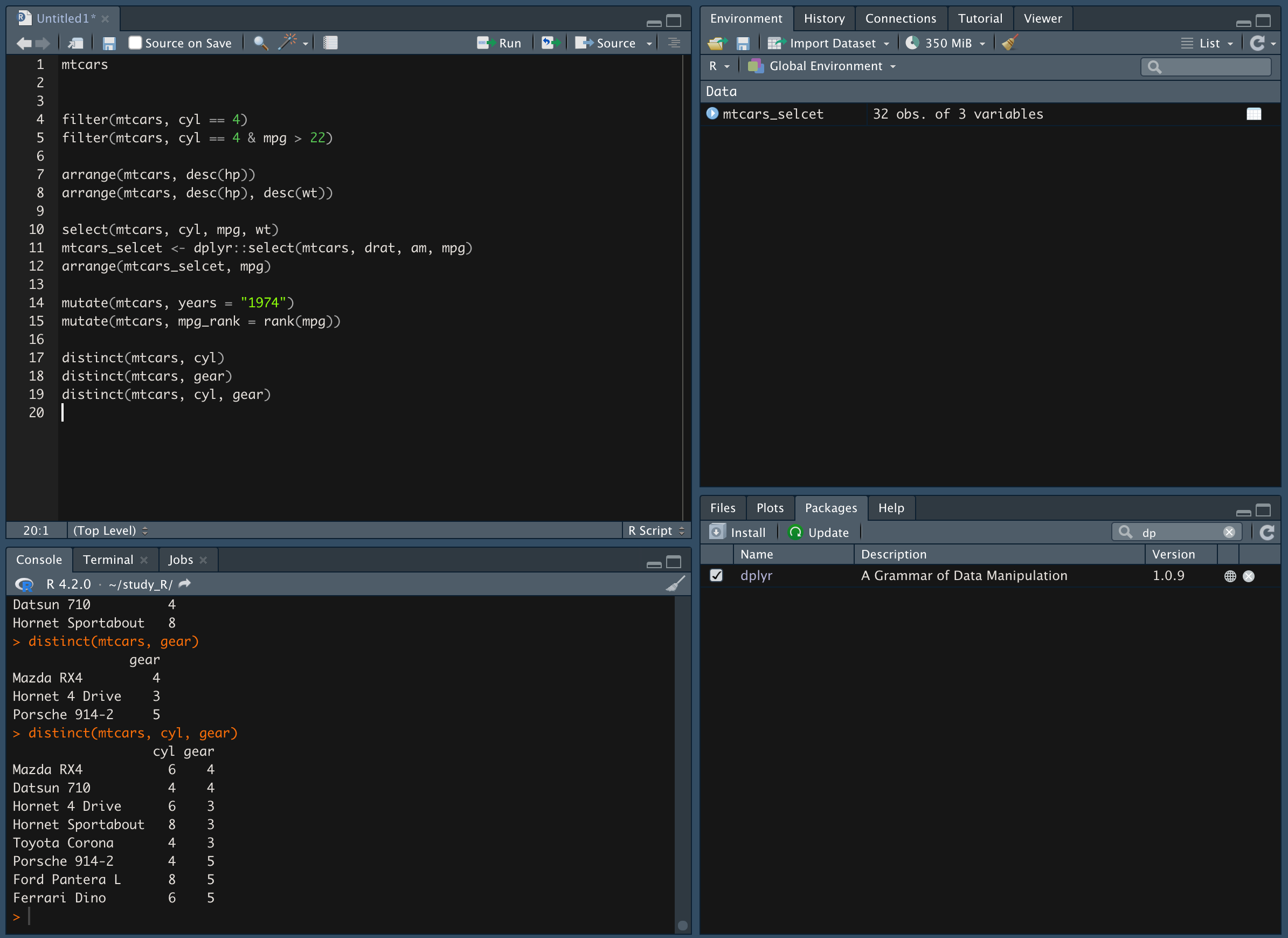
*mazda RX4 와 Hornet 4 Drive, Ferrari Dino 는 동일한 cyl 이지만 gear 값이 다르다.
- 데이터 요약 및 추출
-
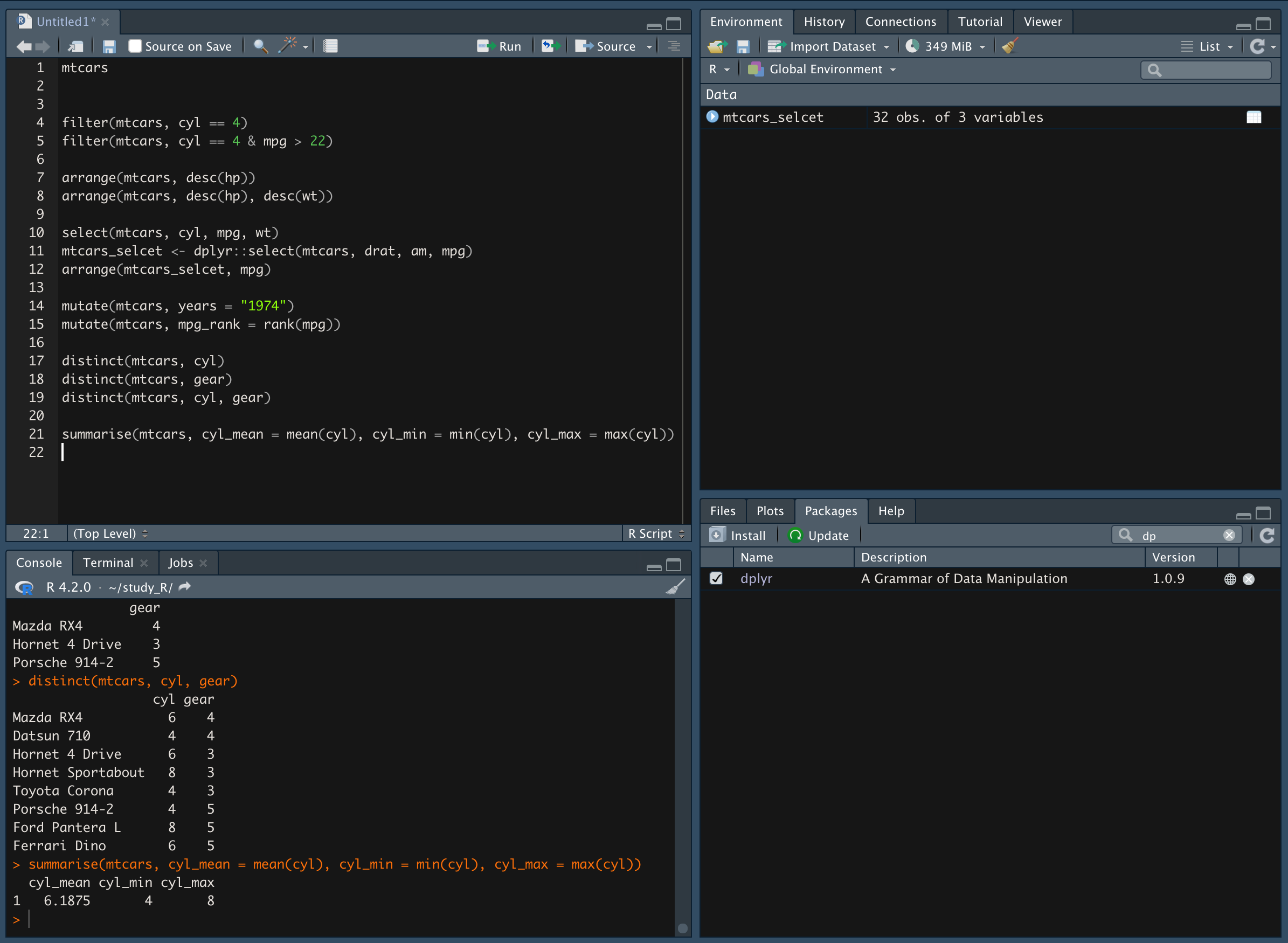
summarise() 함수를 이용해 요약값 추출
-
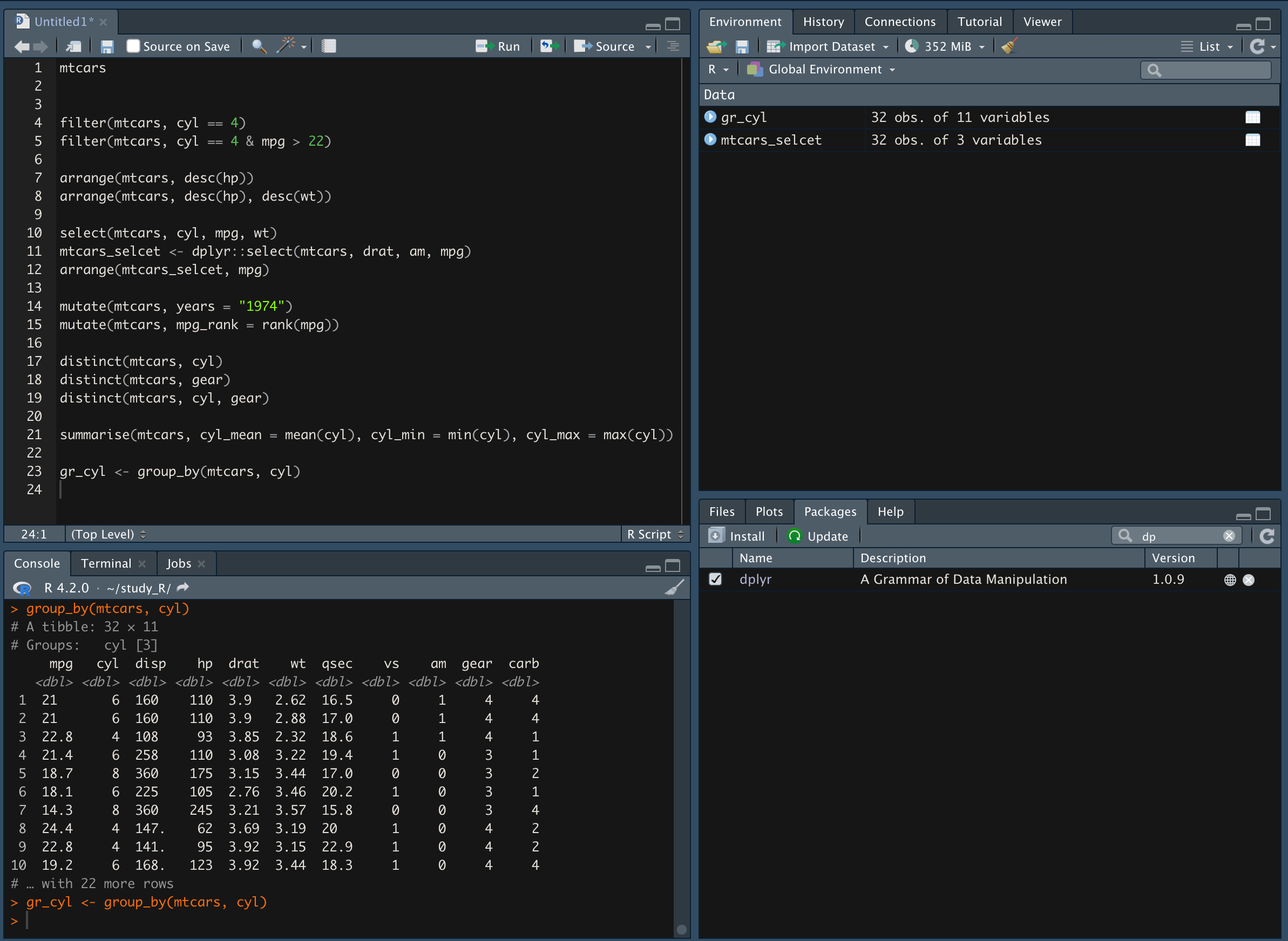
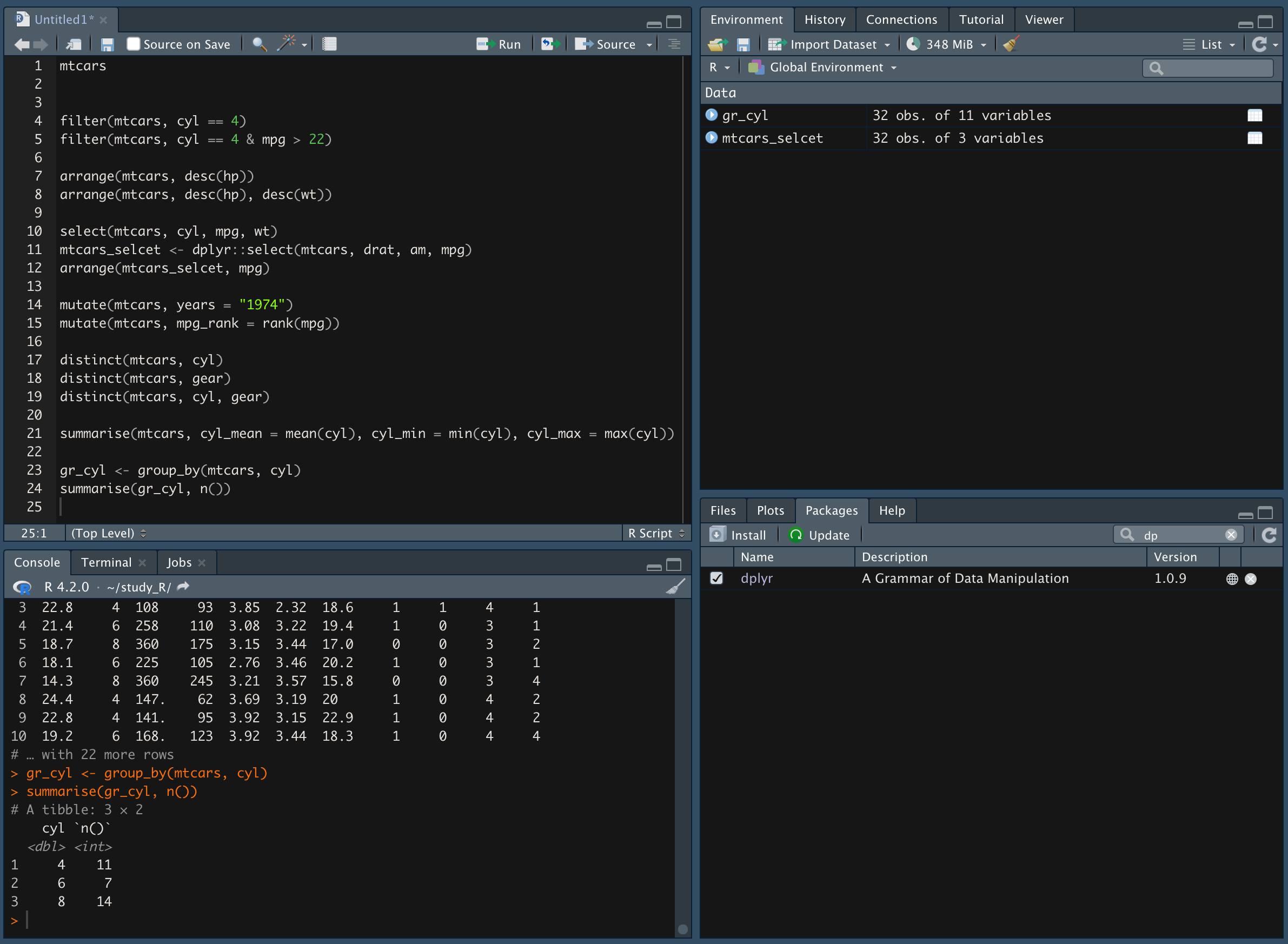
group_by() 함수를 이용해 같은 값(=cyl)끼리 요약
-
summarise(변수명, n())을 활용해 그룹별 개수 요약
-
n_distinct()를 추가해 특정 열의 중복값을 제외하고 개수를 파악
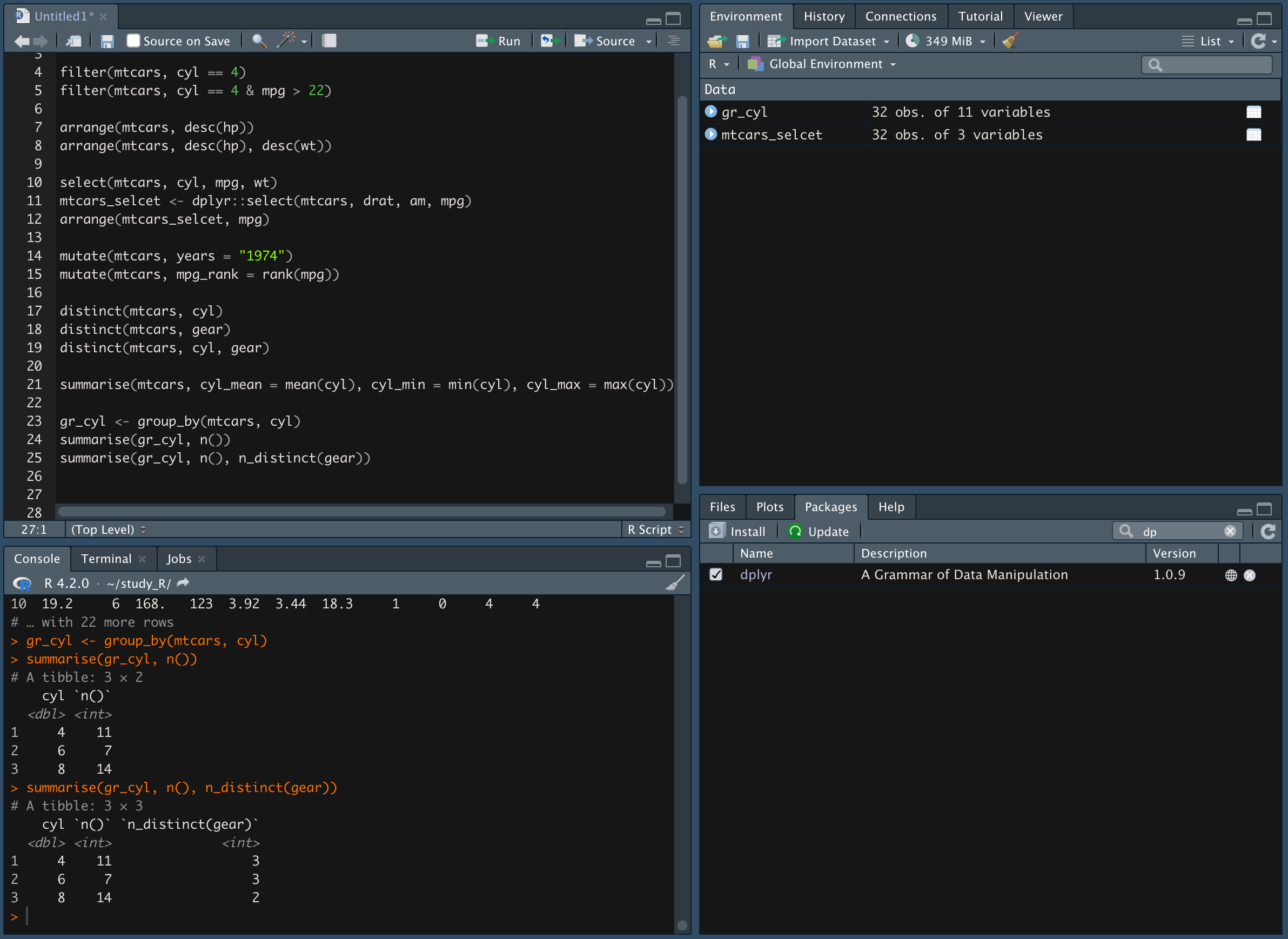
*n()과n_distinct()함수는 단독으로 사용할 수 없고 통계함수를 쓸 때 사용가능 -
sample_n(변수명, 추출할 샘플 개수) 함수는 관측치에서 랜덤한 개수로 데이터를 추출
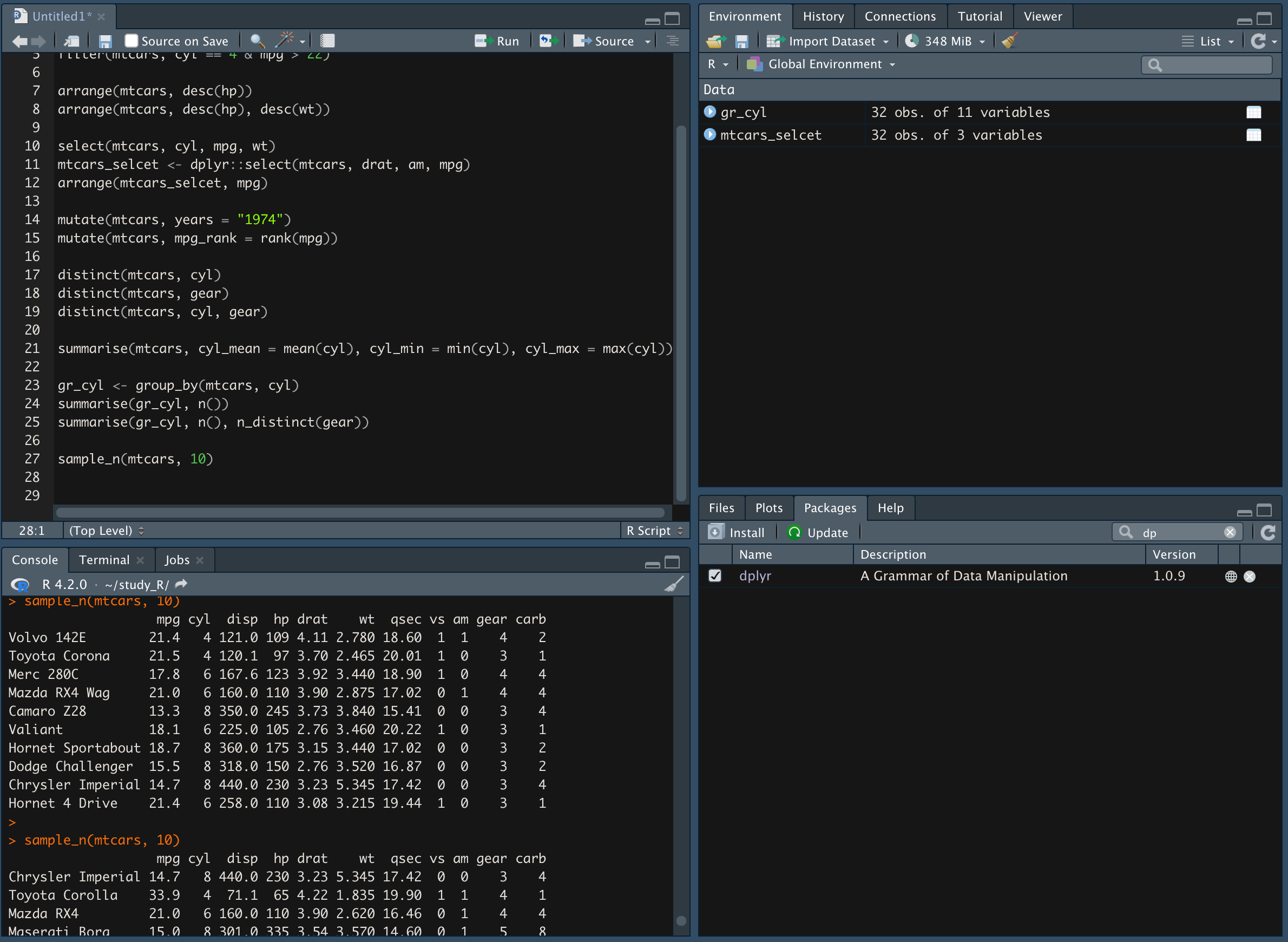
-
sample_frac(변수명, 추출할 샘플 퍼센트) 함수는 관측치에서 랜덤한 퍼센트로 데이터를 추출
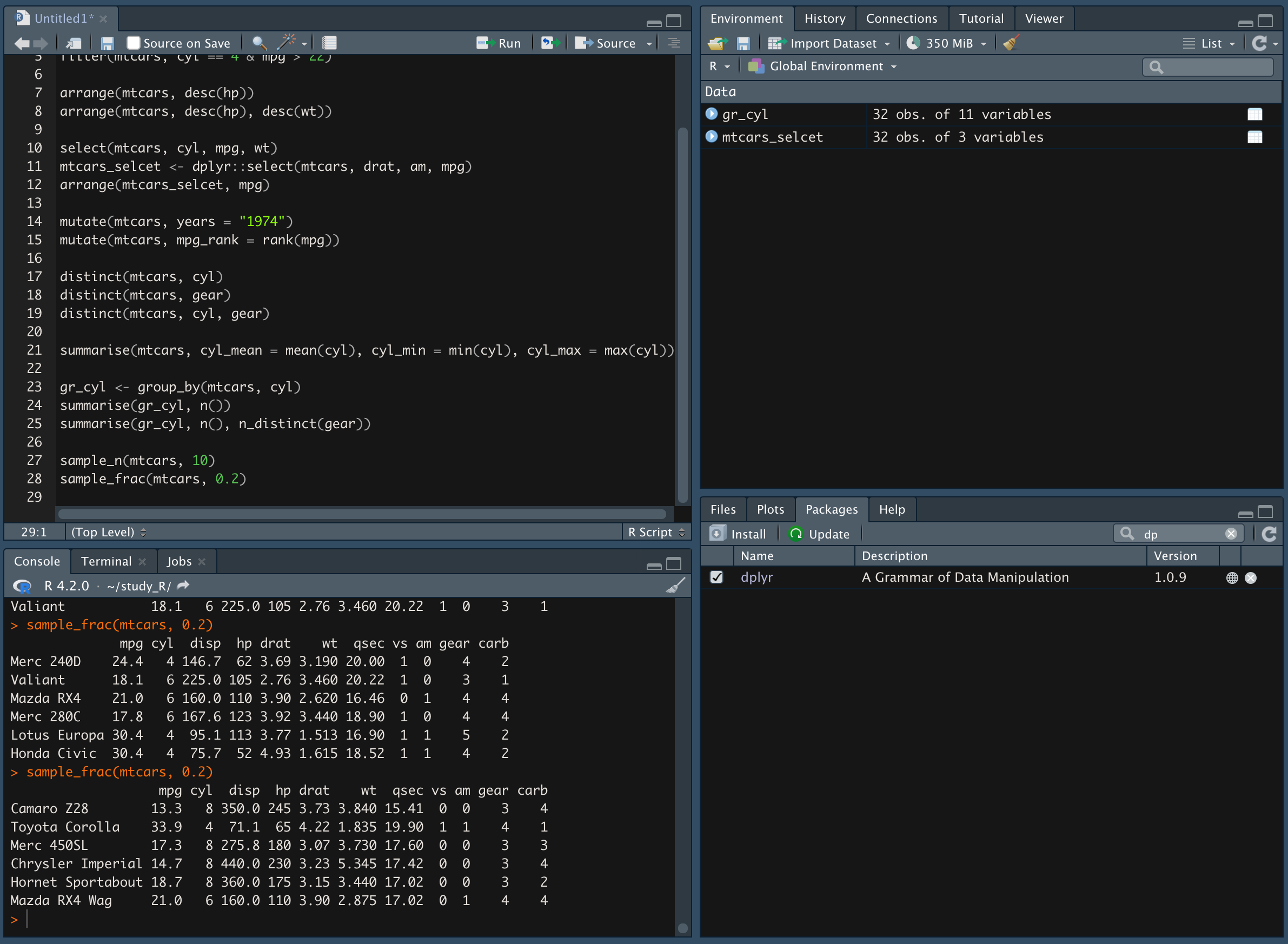
함수와 함수를 연결하는 %>% 연산자
-
dplyr 패키지에서 가장 많이 사용하는 함수
-
파이프 연산자를 사용하면 변수명을 따로 입력할 필요가 없다.
-
예시 ) group_by를 사용한 값을 따로 변수 지정없이 summarise 함수를 통해 값을 추출
-
data set에 직접 사용 가능
[출처] 처음 시작하는 R데이터 분석, 강전희
