- 사전 설정 및 한글 처리 과정
- KoNLP 패키지에는 시스템사전, 세종사전, NIADic사전이 포함되어 있다.
- 시스템 사전은 28만 단어, 세종사전은 37만 단어, NIADic 사전은 98만 단어를 포함한다.
- 실습은 세종사전으로 진행한다.
(NIADic 사전을 이용해 불러오면 로드할 때 속도가 느려질 수 있음)
- 형태소를 분석하려면 텍스트 데이터를 불러오고, 형태소 분석에 알맞게 숫자나 특수문자 등을 제거하는 전처리 과정을 거친 후 한글 명사를 추출하는 과정을 거친다.
과정 요약 ) 텍스트 수집 > 분해 > 단어추출 > 정제 > 정형 데이터 추출 > 분석 > 시각화
- 형태소 분석하기
-
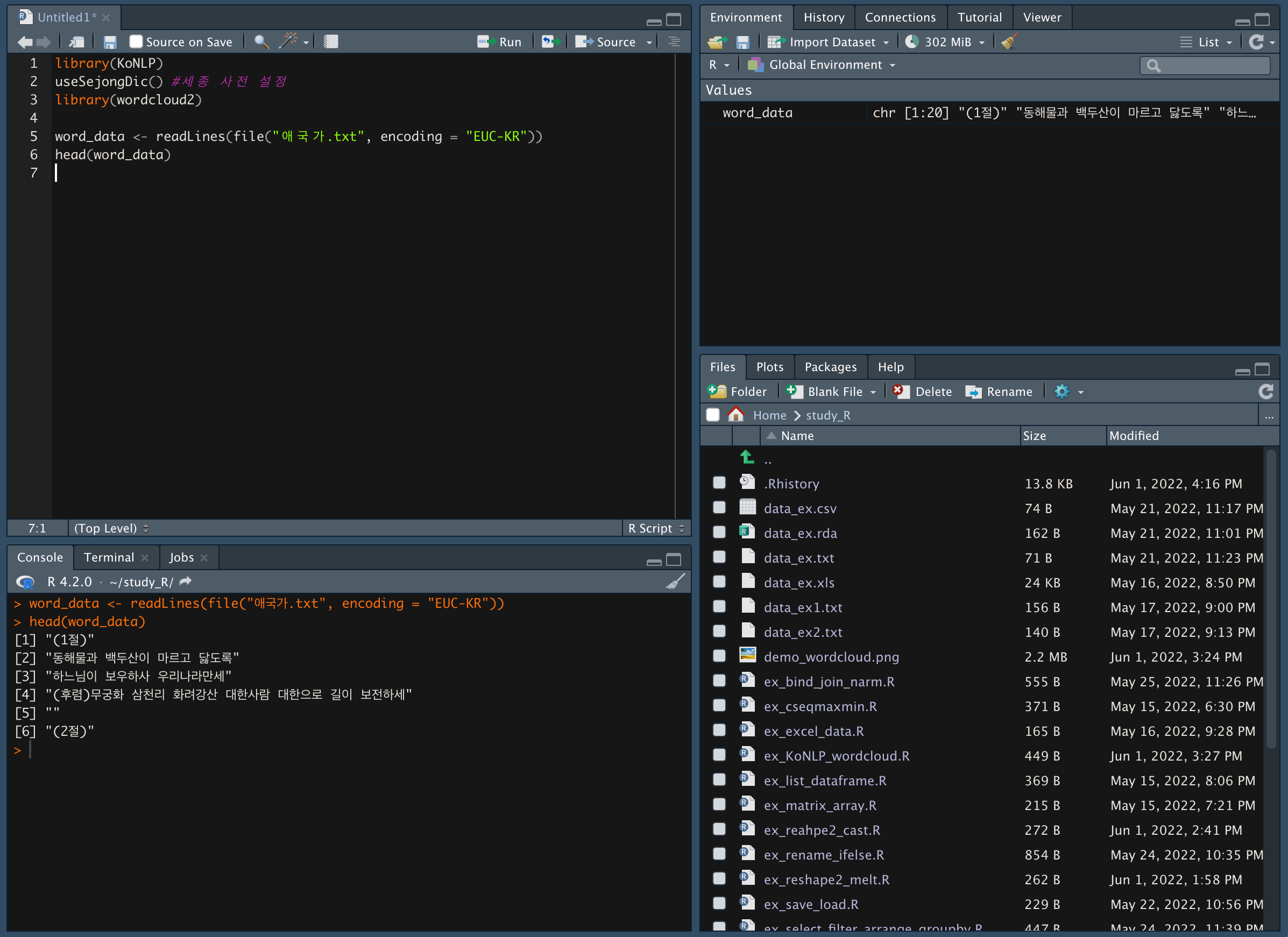
행전안전부 홈페이지에서 애국가 텍스트 파일을 다운받는다.
https://www.mois.go.kr/frt/sub/a06/b08/nationalIcon_3/screen.do -
중요 ) word_data <- readLines(file("애국가.txt", encoding = "EUC-KR"))로 텍스트 파일을 할당한다.
-
mac에서는 word_data <- readLines("애국가.txt") 코드를 입력해 크롤링하면 한글이 깨지는 현상이 나타났다 (이거 해결하려고 1시간 동안 찾아봤다.. 후)
-
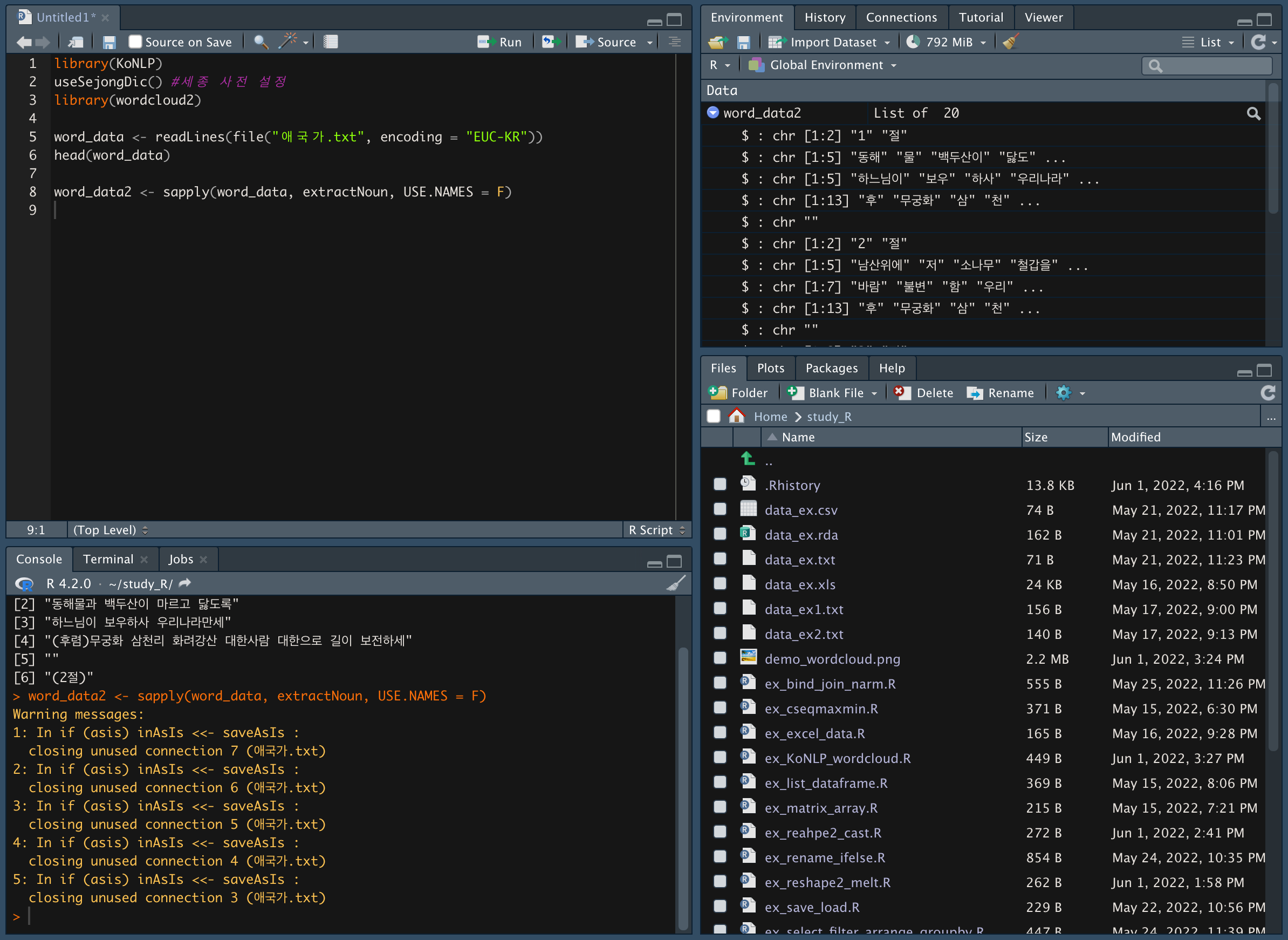
행별로 명사를 추출한다.
-
word_data2 <- sapply(word_data, extractNoun, USE.NAMES = F)
-
extractNoun 은 행별로 명사를 추출하는 함수다.
-
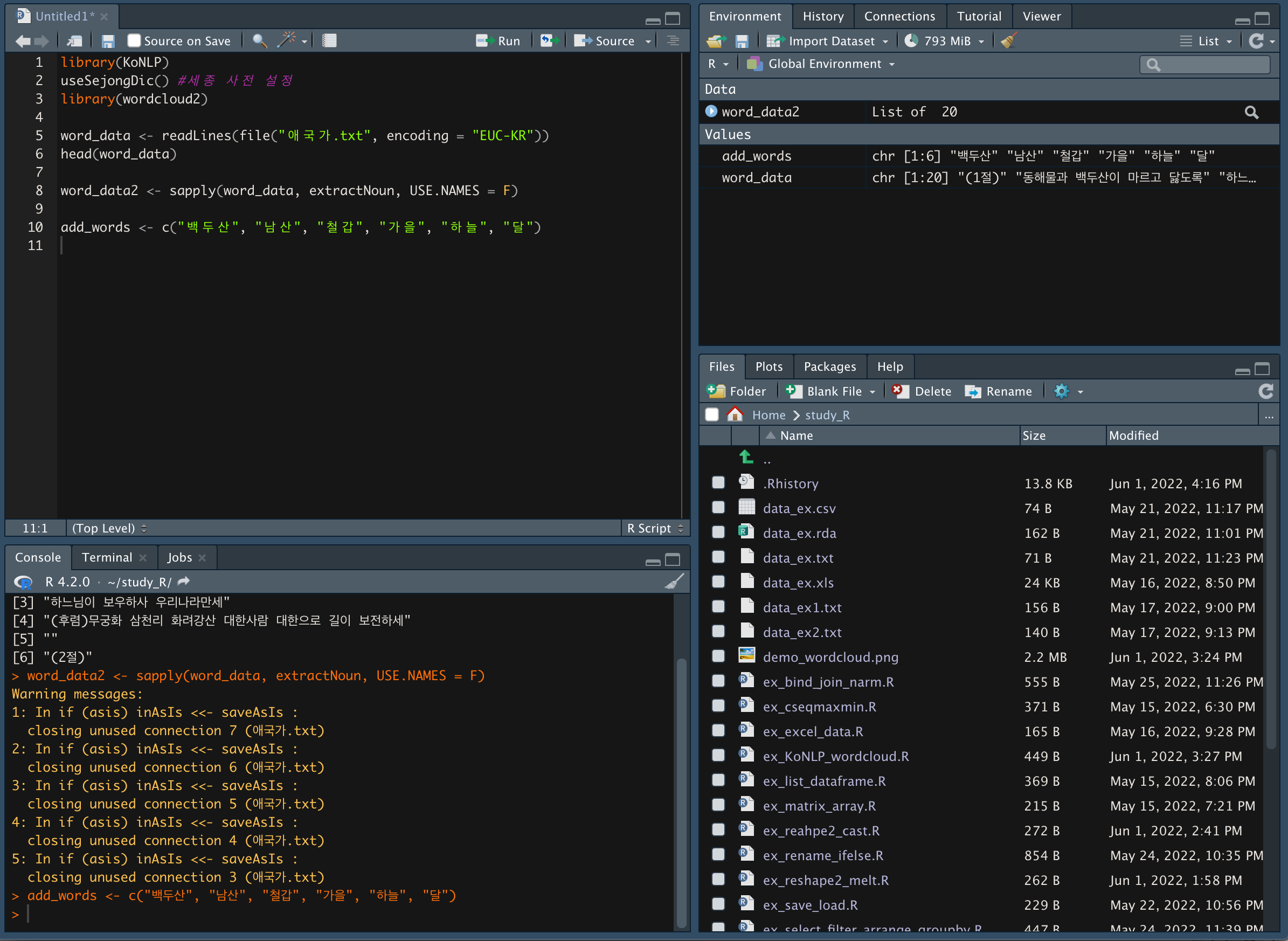
추가할 단어를 add_words에 할당한다.
-
buildDictionary() 함수를 이용해 add_words 단어를 user_dictionary에 명사로 추가해준다.
-
buildDictionary(user_dic = data.frame(add_words, rep("ncn", length(add_words))), replace_usr_dic = T)
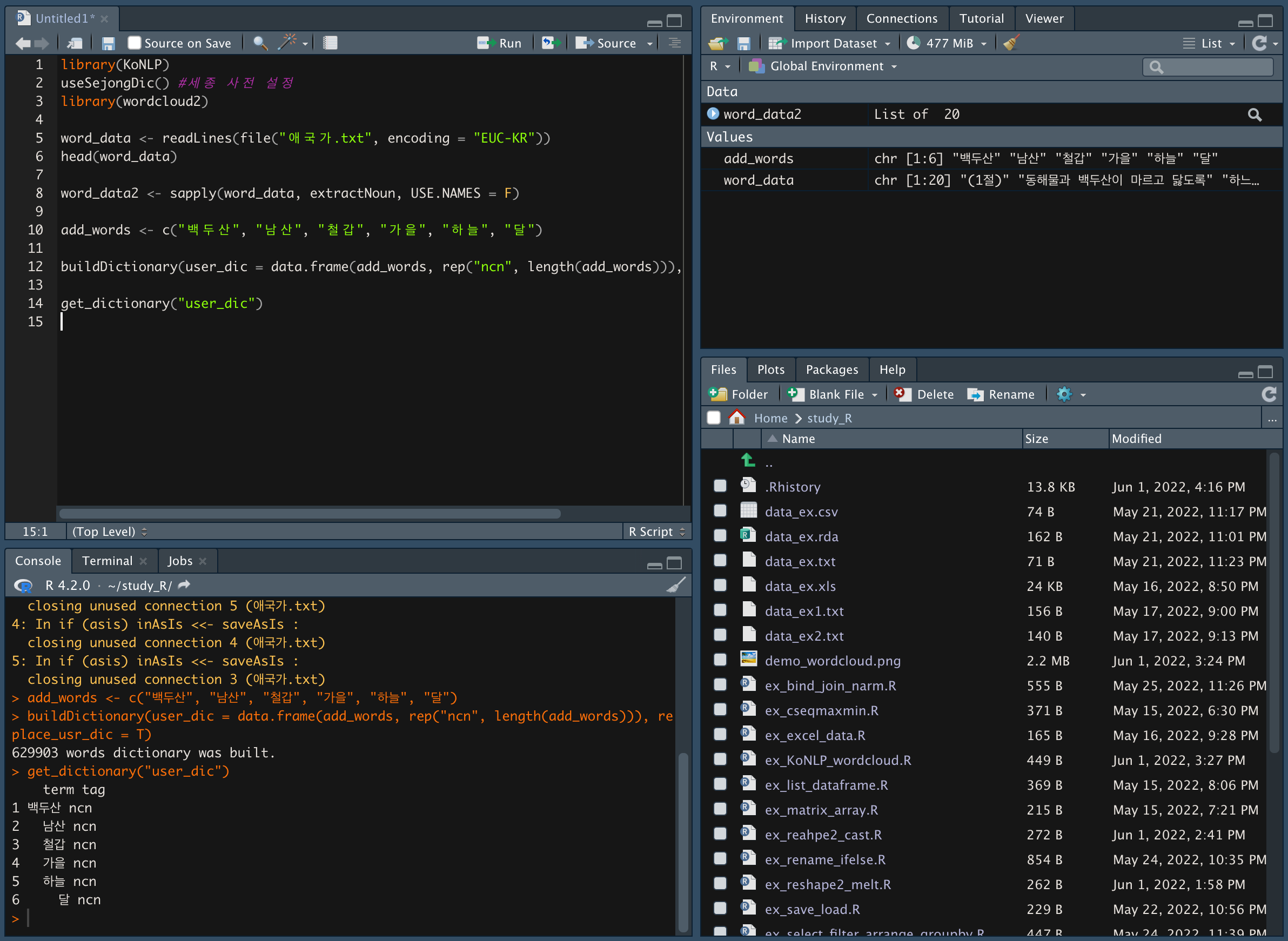
*replace_usr_dic = T은 유저가 설정한 단어를 우선시 한다는 의미 -
get_dictionary(user_dic) 함수를 이용해 추가된 단어를 확인한다.
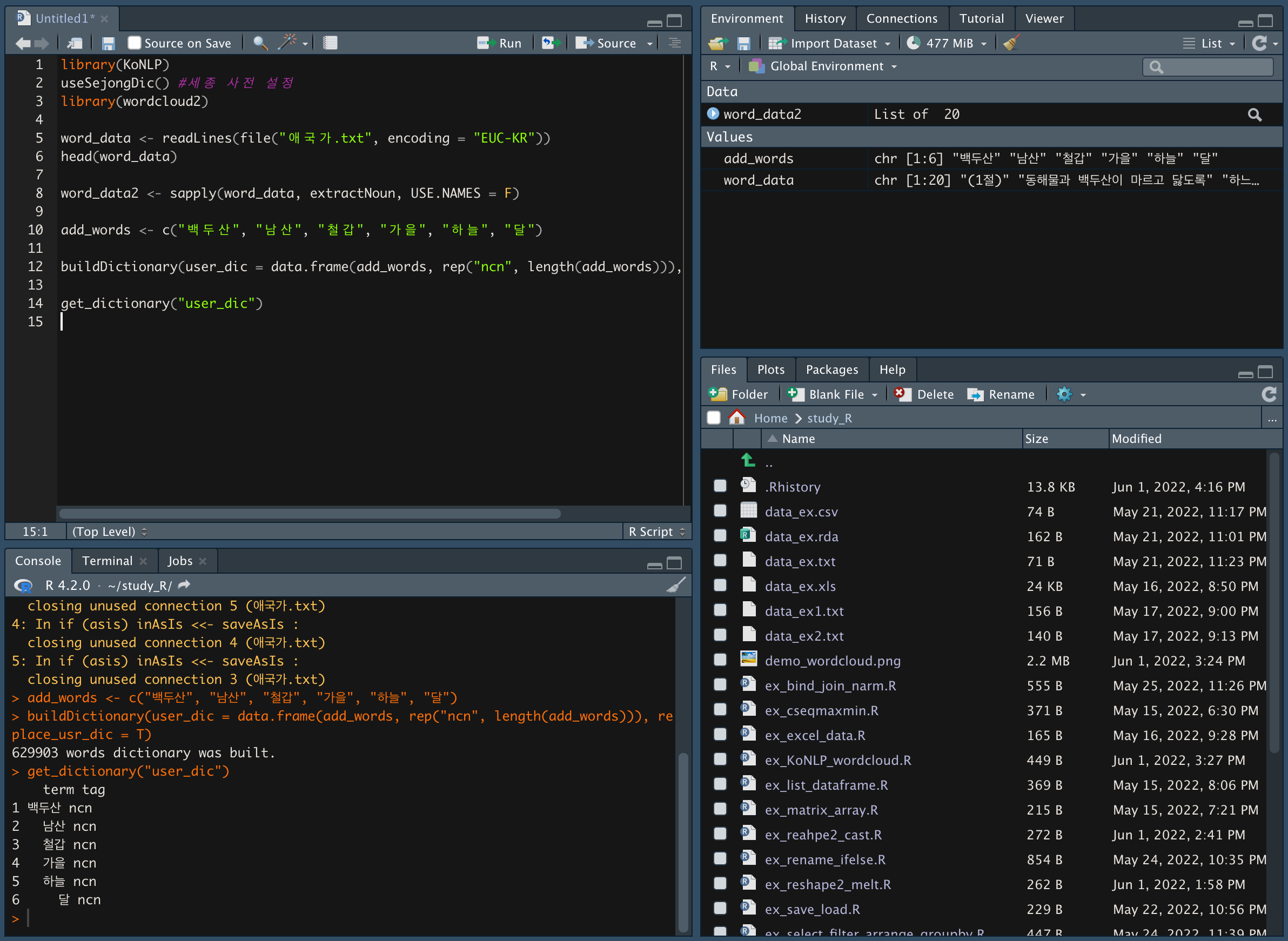
-
다시 word_data2 <- sapply(word_data, extractNoun, USE.NAMES = F)를 실행해보면 다른 결과 값을 확인할 수 있다.
-
user_dic 전
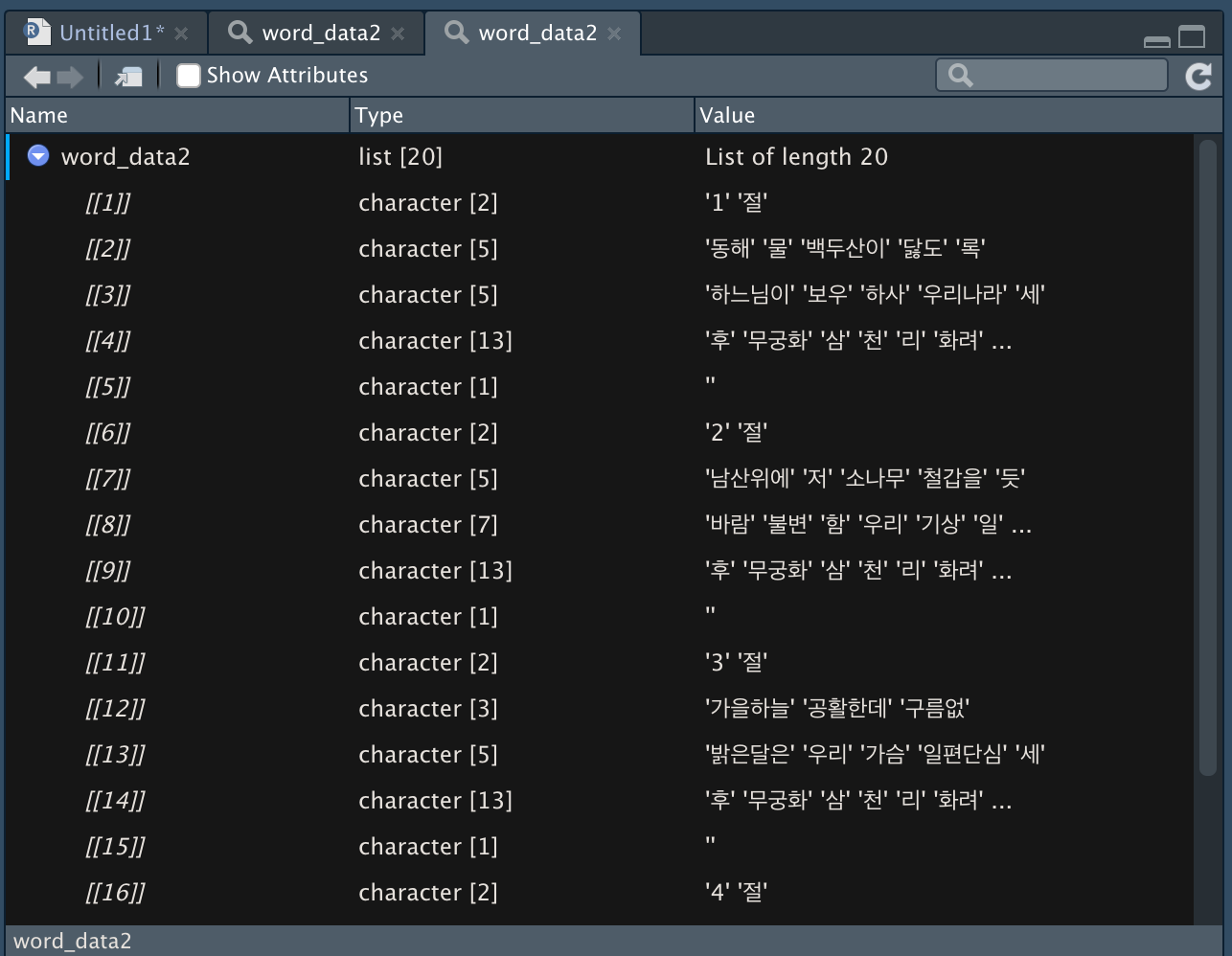
-
user_dic 후
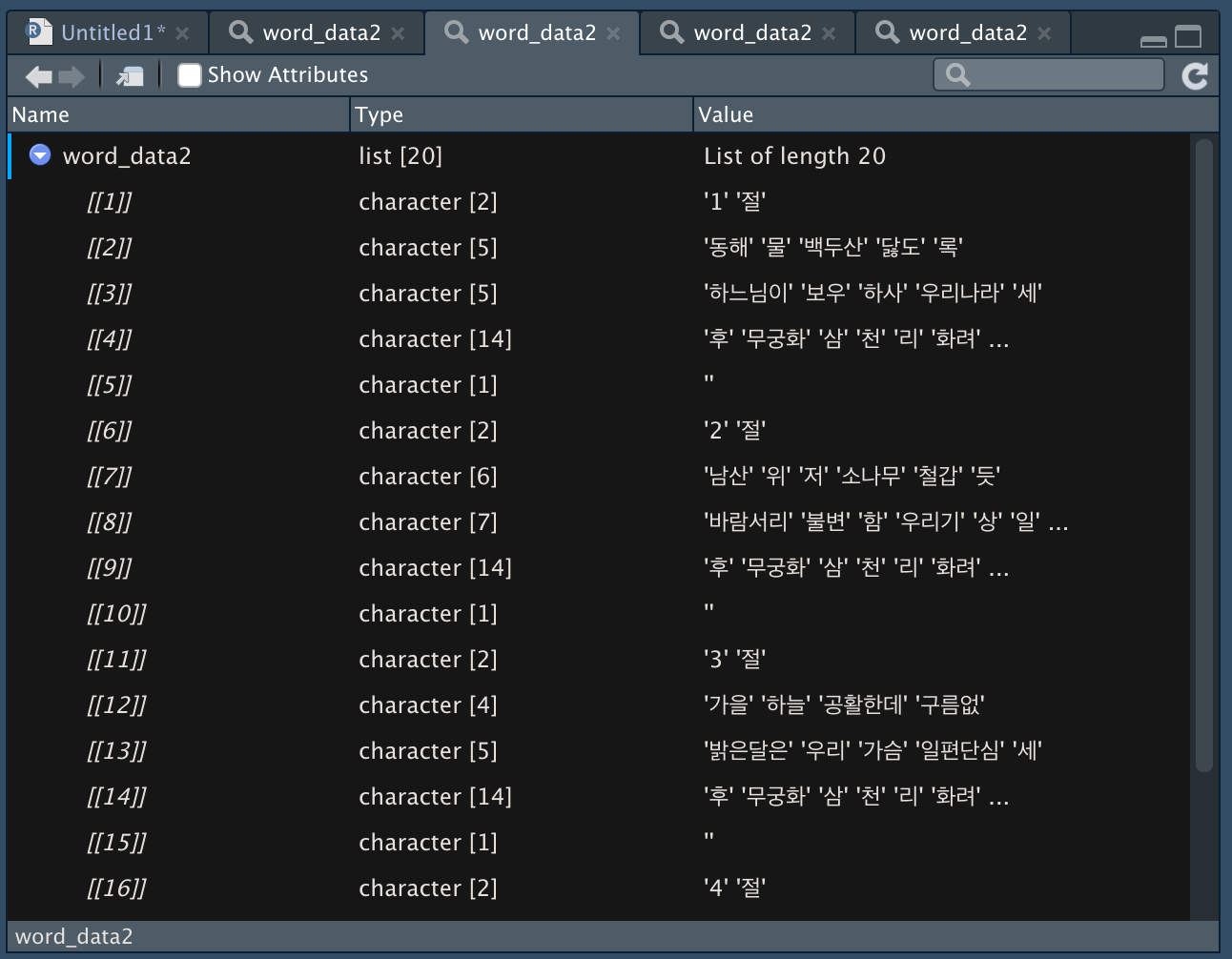
-
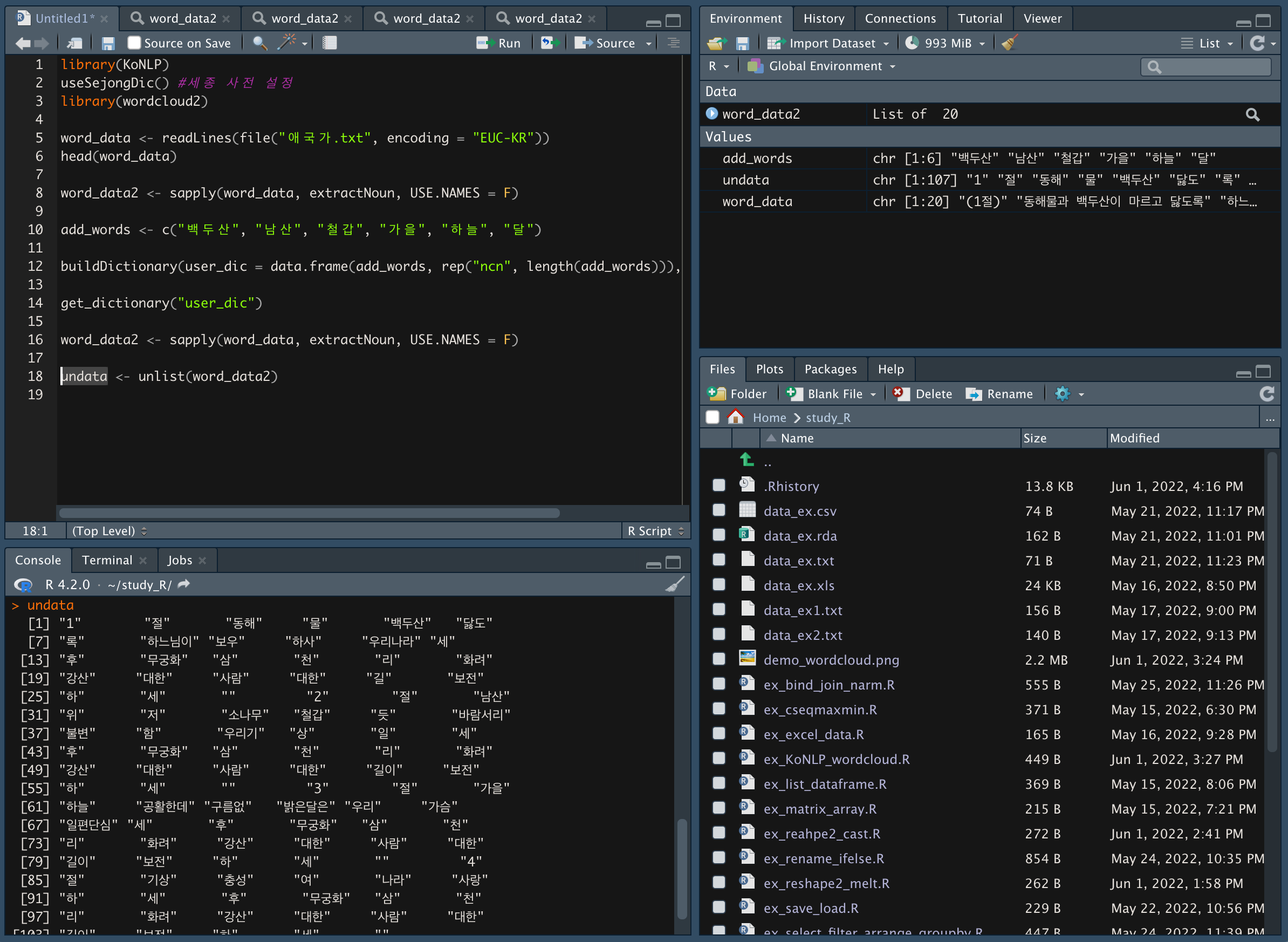
단어를 처리하기 위해서는 행렬 형태를 백터 형태로 변환해주어야하는데, 현재 리스트화 되어있는 것을 리스트를 푼다는 의미인 unlist()함수를 이용한다.
-
undata <- unlist(word_data2)
-
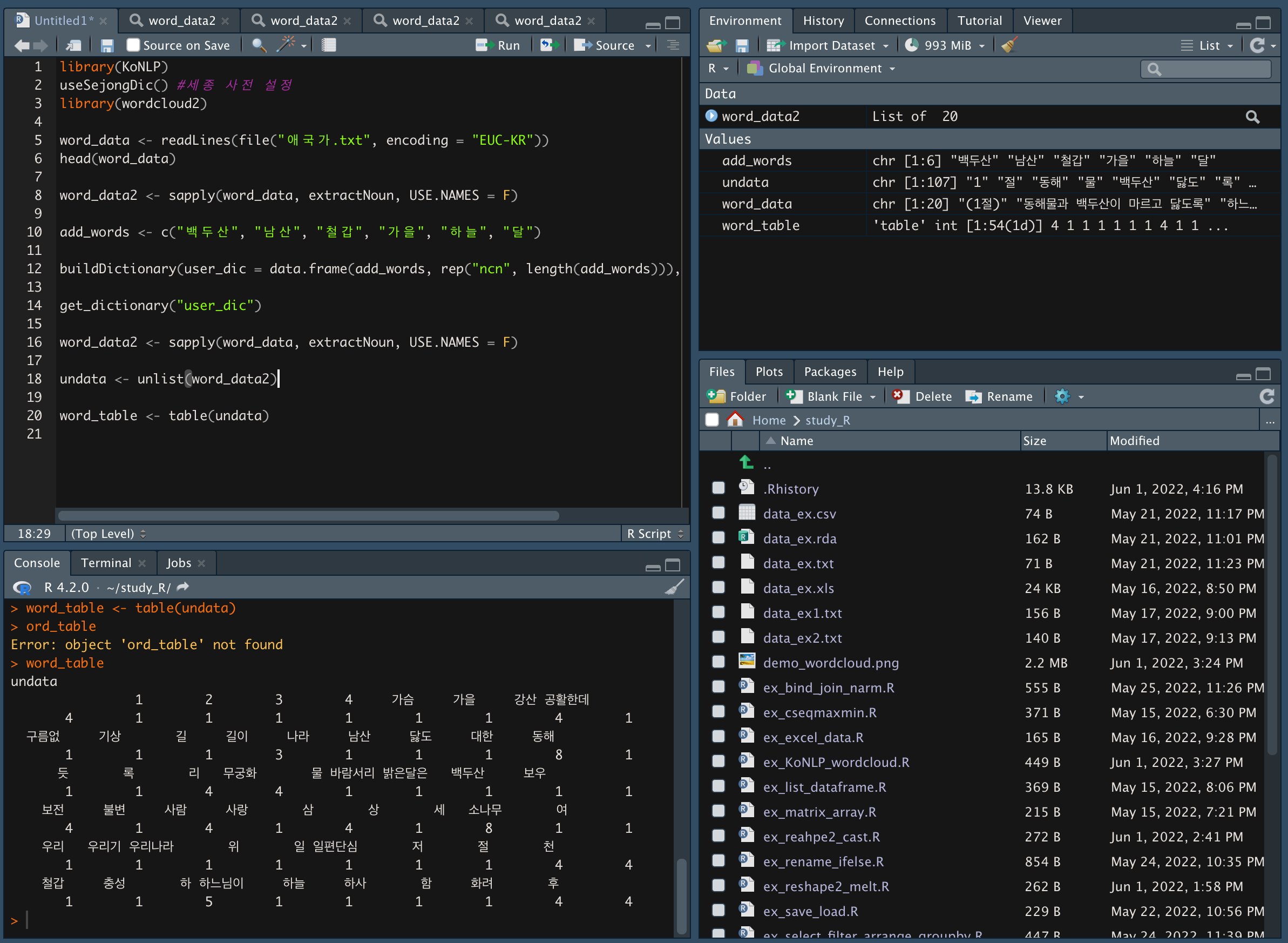
undata를 테이블로 만들어준다.
-
테이블로 나누는 이유는 빈도와 함께 표현되어 있는데, 빈도를 쪼개서 빈도 순으로 많이 나온 것을 확인하기 위해서다.
-
word_table <- table(undata)
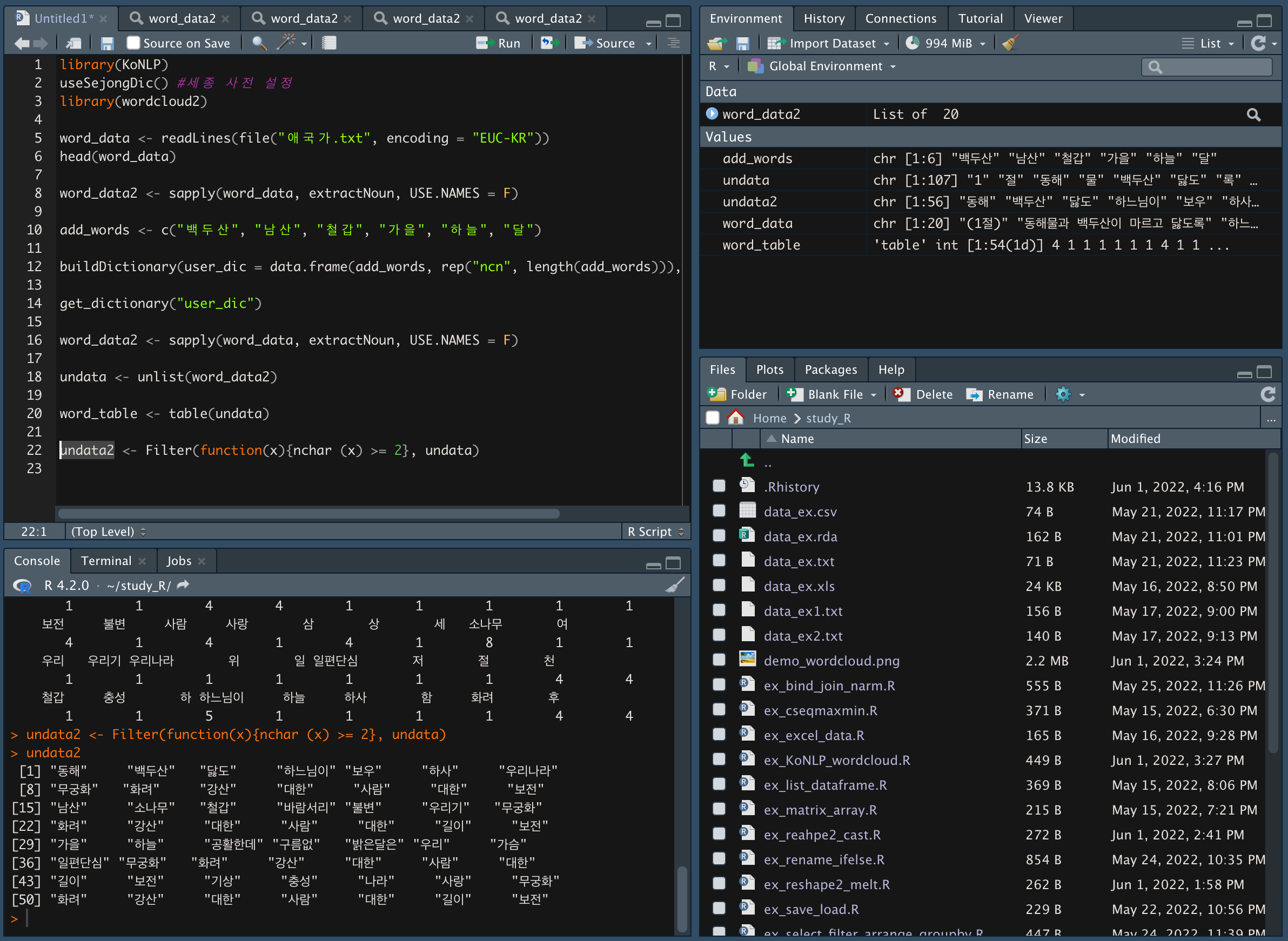
-Filter() 함수를 이용해 두 글자 이상인 단어만 추출한다.
-
table() 함수를 이용해 undata2 변수의 빈도를 확인한다.
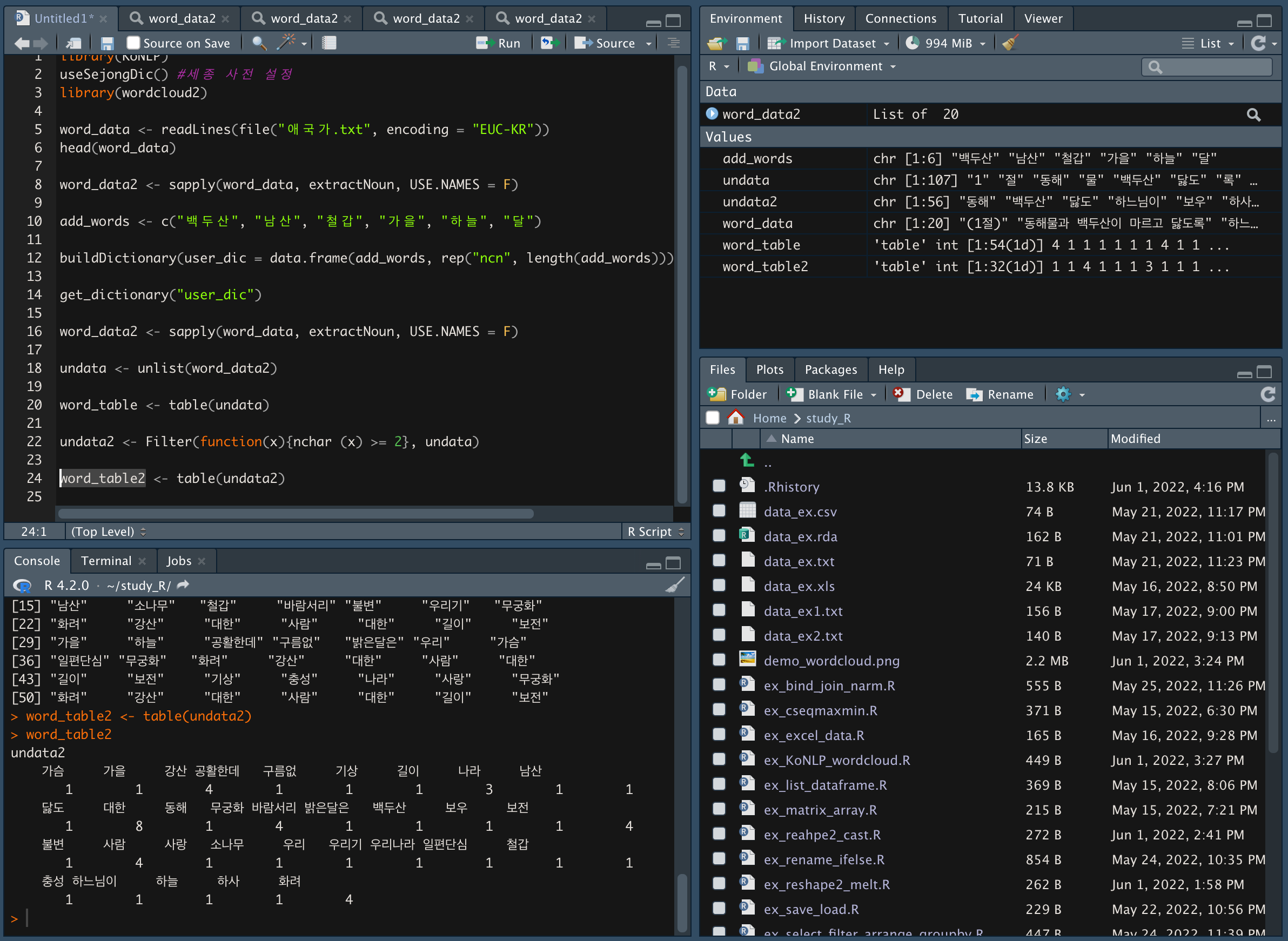
-
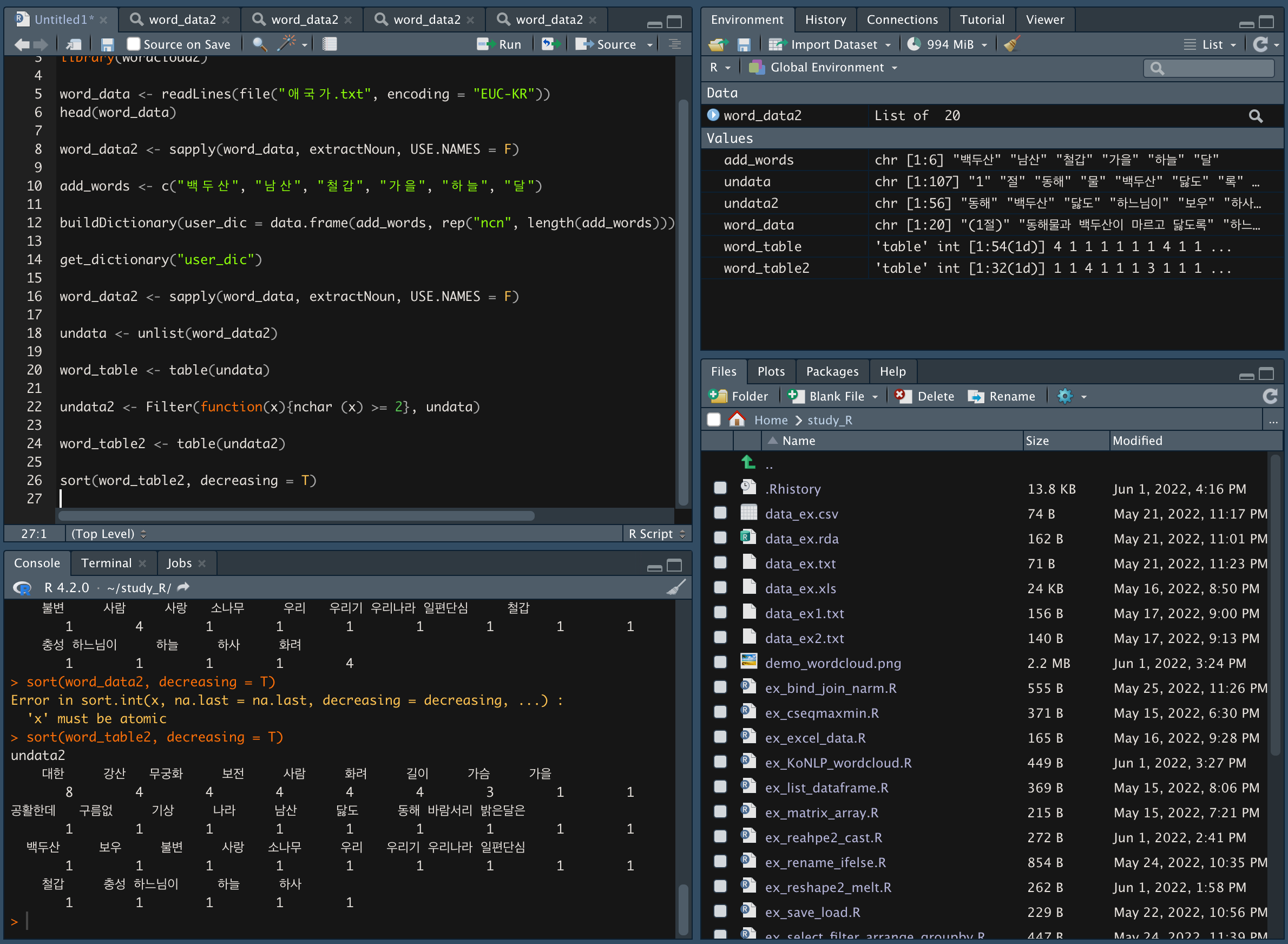
word_table2 를 내림차순으로 정렬해서 단어 빈도를 확인한다.
-
word_table의 워드클라우드를 생성한다.
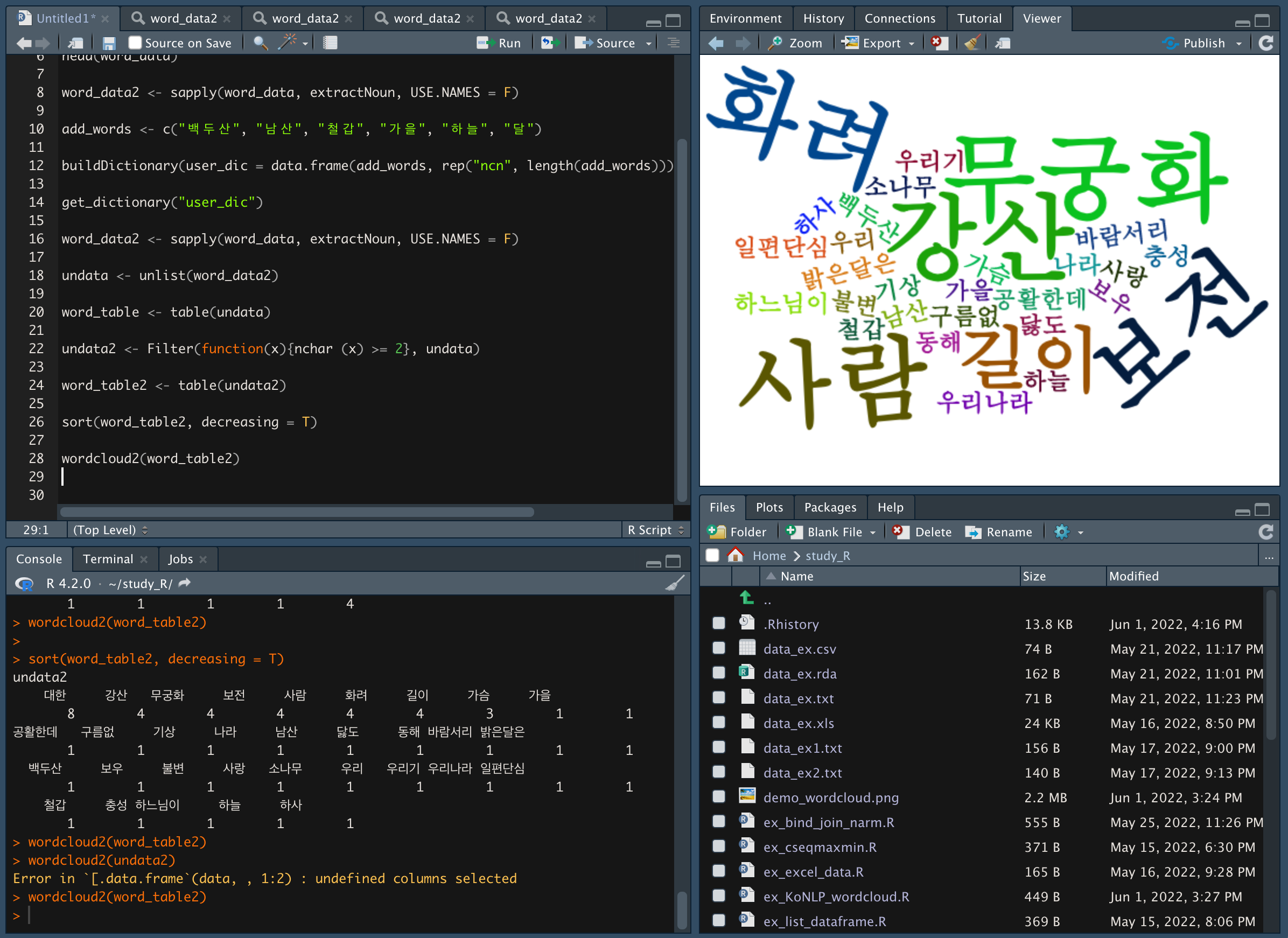
- 데이터에는 "대한"이 있는데 내 워드클라우드엔 왜 "대한"이 안보일까....?
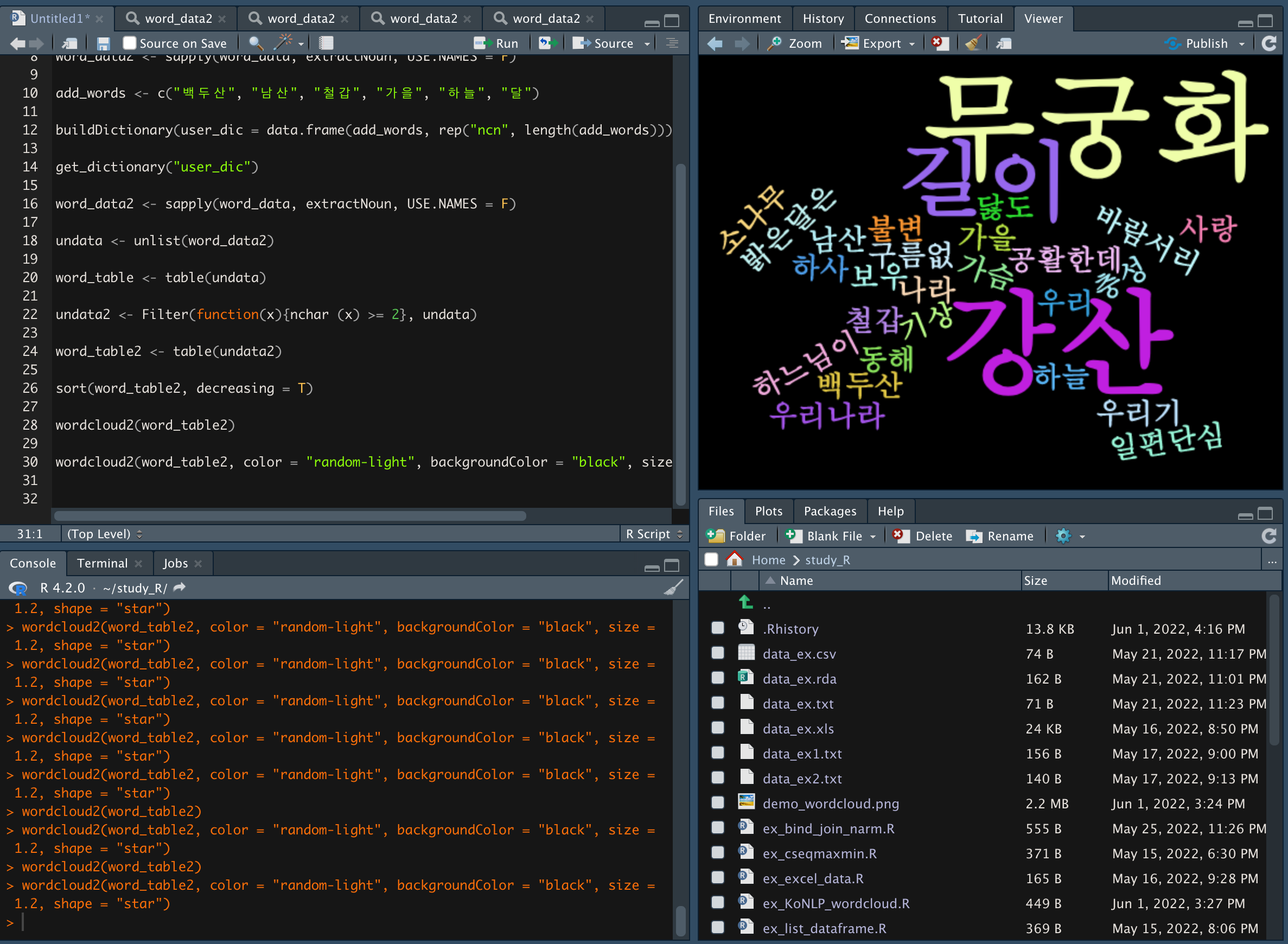
- 옵션을 활용해 워드클라우드를 설정할 수 있다.
- color : 색상
- backgroudColor : 배경색
- fontFamily : 글꼴
- size : 크기
- shape : 모양
[출처] 처음 시작하는 R데이터 분석, 강전희
