
Chapter 02 변수(Varialbe)
4. 기본형(primitive type)
📍 인코딩과 디코딩(encoding & decoding)
문자를 숫자로 변환하는 기준은 '유니코드(unicode)'이다.
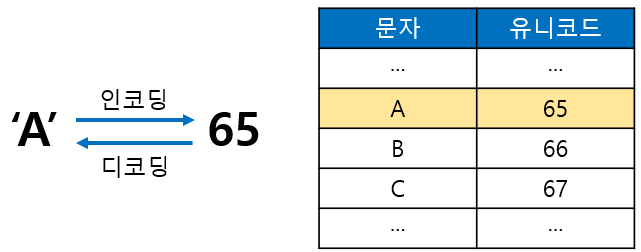
문자를 코드로 변환하는 것을 '문자 인코딩(encoding)', 그 반대로 코드를 분자로 변환하는 것을 '문자 디코딩(decoding)'이라고 하며, 문자를 저장할 때는 인코딩을 해서 숫자로 변환해서 저장하고, 저장된 문자를 읽어올 때는 디코딩을 해서 숫자를 원래의 문자로 되돌려야 한다.
📍 아스키(ASCII)
'ASCII'는 'American Standard Code for Information Interchange'의 약어로 정보교환을 위한 미국 표준 코드란 뜻이다.
아스키는 128(=2^7)의 문자 집합(character set)을 제공하는 7 bit부호로, 처음 32개의 문자는 인쇄와 전송 제어용으로 사용되는 '제어문자(control character)'로 출력할 수 없고 마지막 문자(DEL)를 제외한 33번째 이후의 무나들은 출력할 수 있는 문자들로, 기호와 숫자, 영대소문자로 이루어져 있다.
아스키는 숫자 '0~9', 영문자 'A~Z'와 'a~z'가 연속적으로 배치되어 있다는 특징이 있으며, 이러한 특징은 프로그래밍에서 유용하게 활용된다.
📍 유니코드(Unicode)
서로 다른 문자 인코딩을 사용하는 컴퓨터간의 문서교환에 어려움을 겪게 되자 이를 해소하고자 전 세계의 모든 문자를 하나의 통일된 문자집합으로 표현하고자 노력하였고 그 결과가 바로 '유니코드'이다.
유니코드는 먼저 유니코드에 포함시키고자 하는 문자들의 집합을 정의하였는데, 이것을 유니코드 문자 셋(또는 캐릭터 셋 character set)이라고 한다. 그리고 이 문자 셋에 번호를 붙인 것이 유니코드 인코딩이다.
유니코드 인코딩에는 UTF-8, UTF-16, UTF-32등 여러 가지 종류가 잇는데 자바에서는 UTF-16을 사용한다. UTF-16은 모든 문자를 2 byte의 고정크기로 표현하고 UTF-8은 하나의 문자를 1~4 byte의 가변크기로 표현한다.
그리고 두 인코딩 모두 처음 128문자가 아스키와 동일하다. 아스키를 그대로 포함하고 있는 것이다.
모든 문자의 크기가 동일한 UTF-16이 문자를 다루기는 편리하지만, 1 byte로 표현할 수 있는 영어와 숫자가 2 byte로 표현되므로 문서의 크기가 커진다는 단점이 있다. UTF-8에서 영문과 숫자는 1 byte 그리고 한글은 3 byte로 표현되기 때문에 문서의 크기가 작지만 문자의 크기가 가변적이므로 다루기 어렵다는 단점이 있다.
인터넷에서는 전송속도가 중요하므로, 문서의 크기가 작을수록 유리하다. 그래서 UTF-8인코딩으로 작성된 웹문서의 수가 빠르게 늘고 있다.
📑 원본 자료
- Java의 정석(3판) [남궁 성/도우출판/2016]
