강의 목표
-
컴퓨터 시스템에 존재하는 다양한 저장소들로 구성되는
메모리 계층 구조를 이해하고 필요성을 안다. -
메모리에 대한 물리 주소와 논리 주소를 이해하고
프로그램 실행 중에 논리 주소가 물리 주소로 변환됨을 안다. -
프로세스의 실행에 필요한 메모리 할당 정책에 대해 이해한다.
연속 메모리 할당
분할 메모리 할당 -
모든 메모리 할당에는 사용할 수 없는 조각 메모리(단편화)가 발생하는데, 단편화에 대해 이해한다.
-
홀 선택(동적 메모리 할당)알고리즘을 이해한다.
first-fit, best-fit, worst-fit -
메모리 관리 기법 중 세그멘테이션을 구체적으로 이해한다.
01. 메모리 계층 구조와 메모리 관리 핵심
1.1 메모리 계층 구조
메모리: CPU가 실행할 프로그램 코드와 데이터를 저장하는 물리 장치
메모리가 없는 컴퓨터는 존재할 수 없음
-
메모리는 컴퓨터 시스템 여러 곳에 계층적으로 존재
-
메모리 계층 구조의 중심은 메인 메모리(RAM)
전원이 끊어지면 저장된 정보가 사라짐
하드 디스크가 없는 컴퓨터는 존재할 수 있지만,
메인 메모리가 없는 컴퓨터는 존재할 수 없음 -
CPU로부터 멀어질수록 용량이 커지고, 속도가 느려지며, 가격이 비싸진다
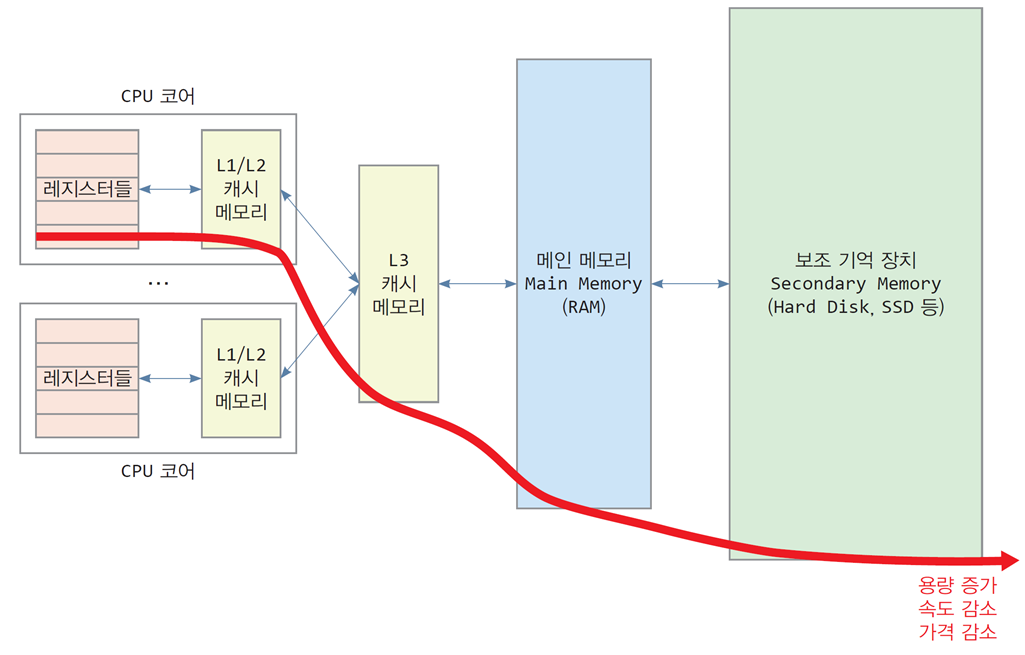
메모리 계층화, 성능과 비용의 절충
-
CPU 성능 향상 → 더 빠른 메모리 요구
→ 작지만 빠른 off-chip 캐시 등장
→ 더 빠른 액세스를 위해 on-chip 캐시
→ 멀티 코에어 적합한 L1/2/3 캐시
빠른 메모리일수록 고가이므로 작은 용량 사용 -
컴퓨터의 성능 향상 → 처리할 데이터 대형화
→ 저장 장치(하드디스크)의 대형화 → 빠른 저장 장치 요구
→ SSD 등장
메모리 계층 구조의 각 요소
CPU 레지스터(CPU registers, )
-
현재 실행할 코드와 데이터, 혹은 다음에 실행할 몇 개의 코드와 데이터 저장
-
레지스터의 크기와 개수는 CPU의 종류에 따라 다름
캐시메모리(cache memory, )
-
CPU의 빠른 처리 속도에 맞추기 위해 도입됨
-
캐시 메모리가 있는 컴퓨터에서는
CPU가 캐시 메모리에서 프로그램 코드와 데이터를 읽어 실행함
→ 코드와 데이터들은 메인 메모리로부터 캐시 메모리로 미리 복사되어야 함 -
캐시 메모리는 응답 속도와 위치에 따라 여러 레벨로 나누어 사용됨
멀티 코어 CPU의 경우, 코어 별로 L1/L2(KB 단위) 이름의 캐시를 두고,
모든 코어들이 공유하는 L3(MB 단위) 캐시를 둠(Core-i7의 경우 내부에 두기도 함) -
SRAM(Static RAM)
전원이 공급되는 한 정보가 안정적으로 유지됨
메인 메모리(main memory, RAM, )
-
현재 실행 중인 모든 프로세스의 코드와 데이터,
읽거나 쓰고 있는 여러 파일들의 블록,
운영체제의 커널 코드와 커널 데이터들이 저장됨 -
메모리에 있는 사용자 프로그램과 운영체제 커널을 구분하지 않고
당장 실행을 위해 필요한 일부분의 코드와 데이터가 캐시 메모리로 복사된다 -
DRAM(Dynamic RAM)
시간이 지나면 저장된 정보가 사라지기 때문에,
사라지기 전에 동일한 정보를 다시 기록해주어야 함( refresh )
refresh를 지속적으로 수행해야 함
보조기억장치(secondary memory, )
-
전원을 꺼도 지워지지 않는 대용량 저장 장치
-
파일이나 데이터베이스 등을 저장
-
메인 메모리의 크기 한계로 인해
메모리에 적재된 프로그램 코드와 데이터의 일부를 일시 저장(스왑 영역 )
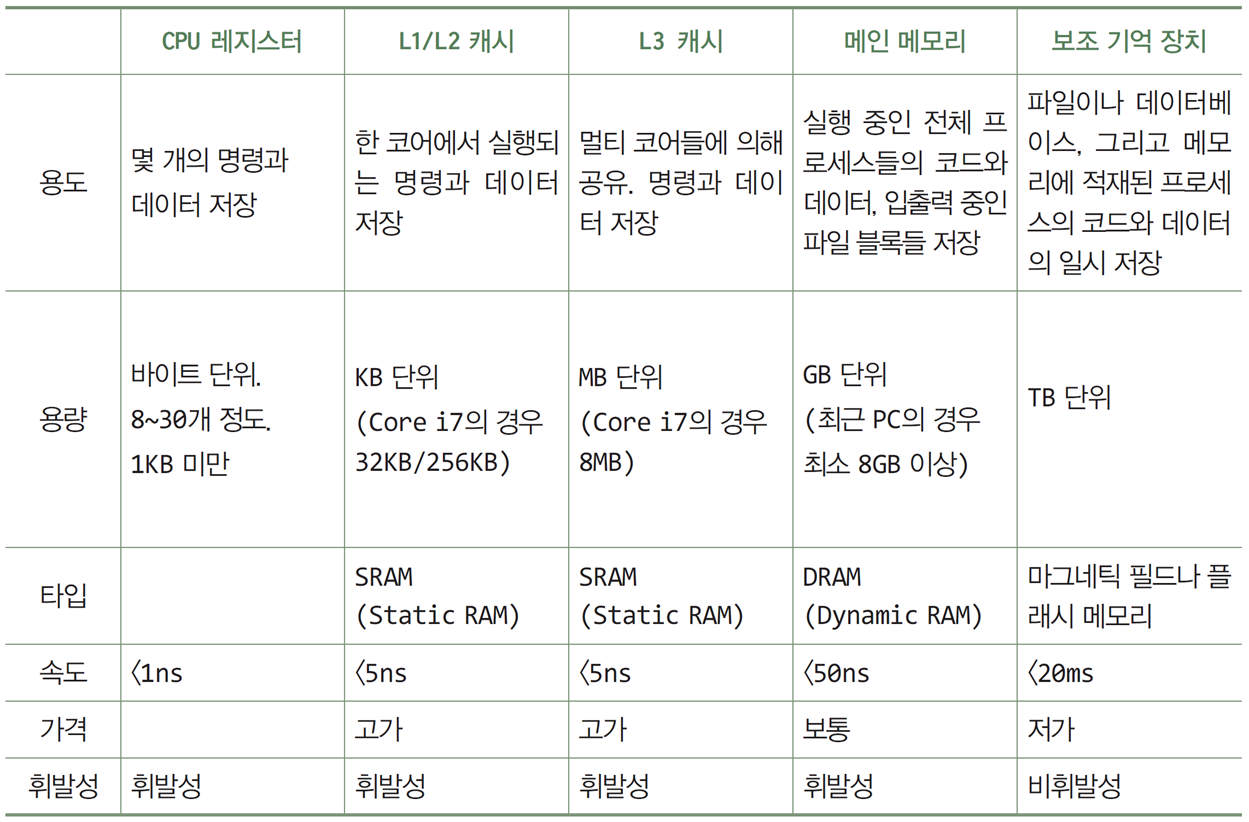
속도도 잘 봐둘 것
프로그램의 실행과 메모리 계층 구조
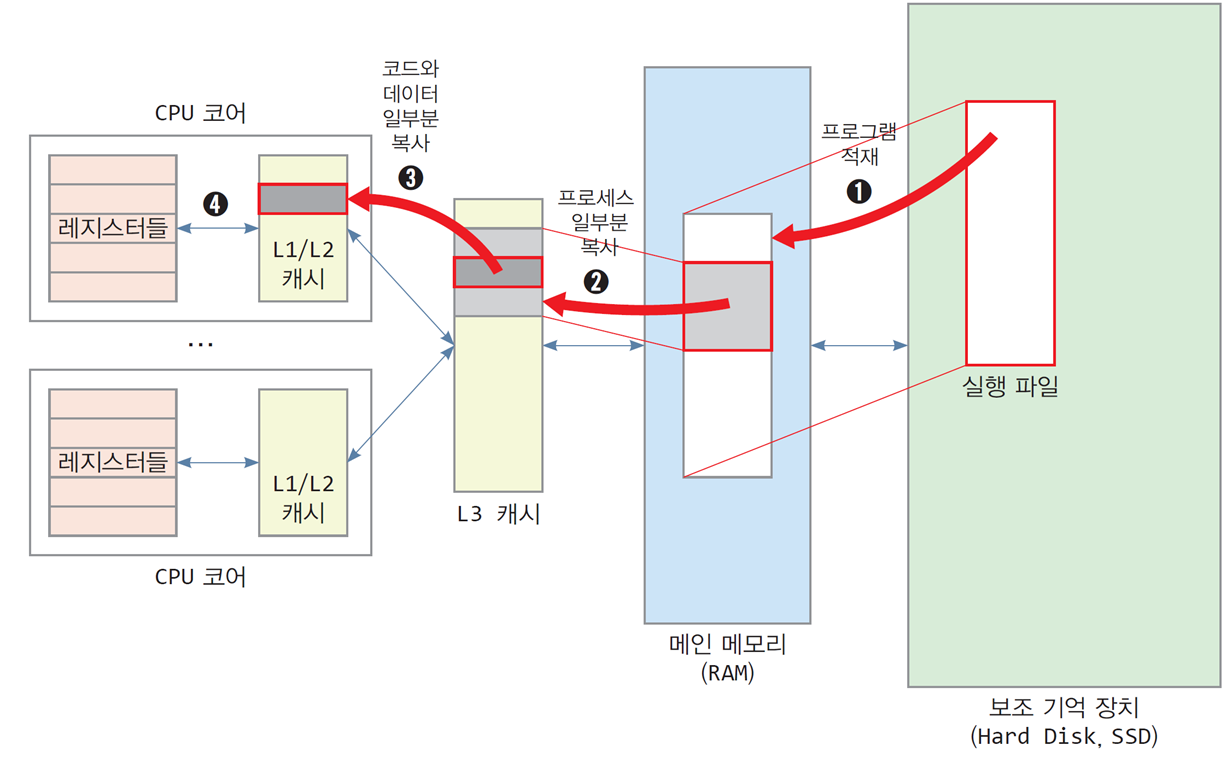
-
보조기억장치에 저장된 실행 파일을 메인 메모리에 적재
→ 메인 메모리의 일부 코드와 실행에 필요한 데이터가 L3 캐시로 복사
→ L3 캐시에서 당장 실행할 코드와 데이터의 일부분이 L1/2 캐시로 복사
→ CPU 코어는 L1/2 캐시에서 현재 실행할 명령과 데이터를
레지스터로 읽은 후 연산 실행 -
캐시가 없는 컴퓨터 → CPU가 메인 메모리로부터 데이터를 가져와 명령 실행
캐시를 가진 컴퓨터 → 캐시로부터만 프로그램 코드와 데이터를 읽고 실행
실행에 필요한 코드와 데이터는 반드시 캐시로 복사되어야 함
메인 메모리와 캐시
캐시 미스(cache miss)
-
CPU가 현재 프로세스나 스레드의 실행을 중단하고
다른 프로세스나 스레드를 실행할 때,
L1/2 캐시에서 새로 실행하고자 하는 프로세스/스레드의
명령과 데이터를 찾을 수 없는 현상 -
L1/2에 없다면 L3에서, L3에도 없다면 메인 메모리에서 데이터를 가져옴
캐시 미스는 연쇄적으로 발생함 -
새로운 프로세스나 스레드의 코드와 데이터가 캐시로 들어오기 전에,
현재 캐시의 수정된 데이터는 다시 L3 캐시나 메인 메모리에 기록되어야 함 -
캐시 미스는 프로그램의 실행 중에도 발생
메인 메모리와 보조기억장치
가상 메모리(virtual memory)
- 메인 메모리 전체가 사용 중 이거나 빈 영역이 일정 이하로 줄어들었을 때,
메인 메모리에 적재된 코드나 데이터의 일부분을
하드디스크나 SSD에 저장하고 메인 메모리에 빈 공간 확보
1.2 메모리 계층화의 성공 이유, 참조의 지역성
참조의 지역성(locality of reference)
- 코드나 데이터, 자원 등이 아주 짧은 시간 내에 다시 사용되는 프로그램 특성
1.4 메모리 관리
메모리에는 현재 실행 중인 모든 프로세스들의 코드와 데이터,
그리고 운영체제의 코드와 데이터가 적재되어 있다.
메모리 관리 이유
메모리가 운영체제에 의해 관리되어야 하는 이유
-
1) 메모리는 공유 자원
여러 프로세스 사이에 메모리 공유
각 프로세스에게 물리 메모리 할당 -
2) 메모리 보호
프로세스의 독립된 메모리 공간 보장
다른 프로세스로부터 보호
사용자 코드로부터 커널 공간 보호 -
3) 메모리 용량 한계 극복
설치된 물리 메모리보다 큰 프로세스 지원 필요
여러 프로세스의 메모리 합이 설치된 물리 메모리보다 큰 경우 -
4) 메모리 효율성 증대
가능한 많은 개수의 프로세스를 실행시키기 위함
(DOM, Degree of Multiprogramming)
프로세스당 최소한의 메모리만 할당
메모리 관리 기능
기본적인 메모리 관리 기능은 할당과 보호의 2개로 요약할 수 있음
어떤 운영체제이든 이 2가지 기능은 반드시 지원되어야 함
-
메모리 할당
프로세스에게 메모리를 할당하는 기능 -
메모리 보호
프로세스가 다른 프로세스의 메모리 영역이나,
운영체제 영역을 침범·훼손하지 못하도록 보호하는 기능
메모리 주소
2.1 물리 주소와 논리 주소
메모리는 오직 주소를 이용해서만 접근됨
물리 주소(physical address): 실제 메모리 주소(하드웨어 주소)
-
물리 메모리(RAM)에 새겨진 주소
-
컴퓨터를 설계·제작하는 시점에 하드웨어에 의해 매겨지는 고정된 주소
-
0에서 시작하는 연속되는 주소 체계
-
메모리는 시스템 주소 버스를 통해 물리 주소(이진 신호)의 신호를 받음
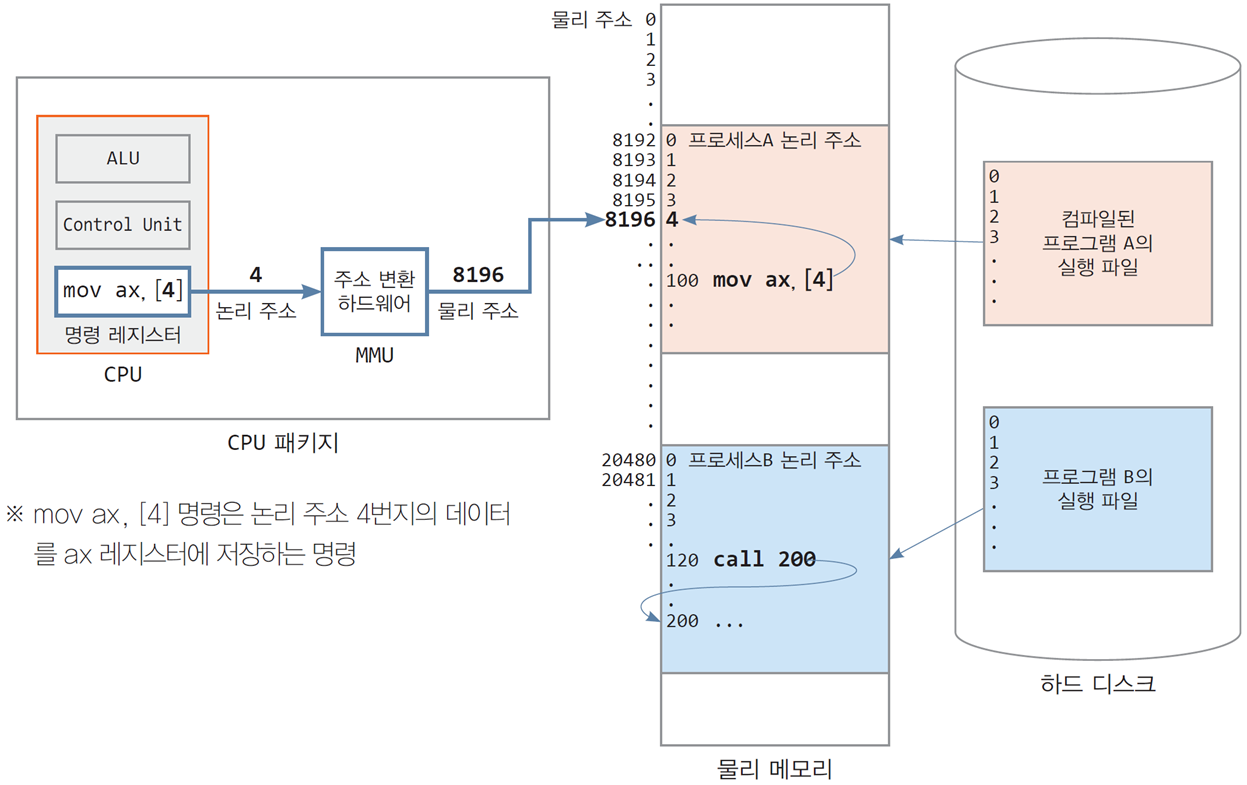
논리/가상 주소(logical/virtual address): 프로그램 내에서 사용되는 주소
-
개발자/프로세스가 프로세스 내에서 사용하는 주소로
코드나 변수 등에 대한 주소 -
0에서 시작하여 연속되는 주소 체계, 프로세스 내에서 매겨진 상대 주소
프로그램에서 변수 n의 주소가 100번지라면,
논리 주소를 의미. 물리 주소는 알 수 없음 -
컴파일러와 링커에 의해 매겨진 주소
실행 파일 내에 만들어진 목적 코드나 데이터의 주소들은 모두 논리 주소 -
CPU 내에서 프로세스를 실행하는 동안 다루는 주소는 모두 논리 주소
-
사용자나 프로세스는 결코 물리 주소를 알 수 없음
2.2 논리 주소의 물리 주소 변환
MMU(Memory Management Unit)
또는 주소 변환 하드웨어(Address Translation H/W)
-
논리 주소를 물리 주소로 바꾸는 하드웨어 장치
CPU가 발생시킨 논리 주소는 MMU에 의해 물리 주소로 바뀌어 메모리에 도달 -
오늘날 MMU는 CPU 패키지에 내장
MMU 덕분으로 여러 프로세스가 하나의 물리 메모리에서 실행되도록 됨 -
CPU가 발생시키는 주소
MMU가 CPU 칩(CPU 패키지) 외부에 위치 → 논리 주소
MMU가 CPU 칩 내부에 위치 → 물리 주소
CPU 패키지 = CPU + MMU 등
2.3 컴파일과 논리 주소, 논리 주소가 사용되는 이유
-
컴파일러는 프로그램을 논리 주소로 컴파일
컴파일 시점에 물리 메모리 몇 번지에 적재될지 알 수 없음
코드와 전역 변수들은 0번지에서부터 시작하는 논리 주소에 할당 -
프로그램 실행 시작 시, 운영체제에 의해
프로그램을 물리 메모리의 적절한 위치에 적재하고, 매핑 테이블이 생성됨 -
현재 실행하는 명령의 물리 주소를 아는 것은 오직 MMU 밖에 없음
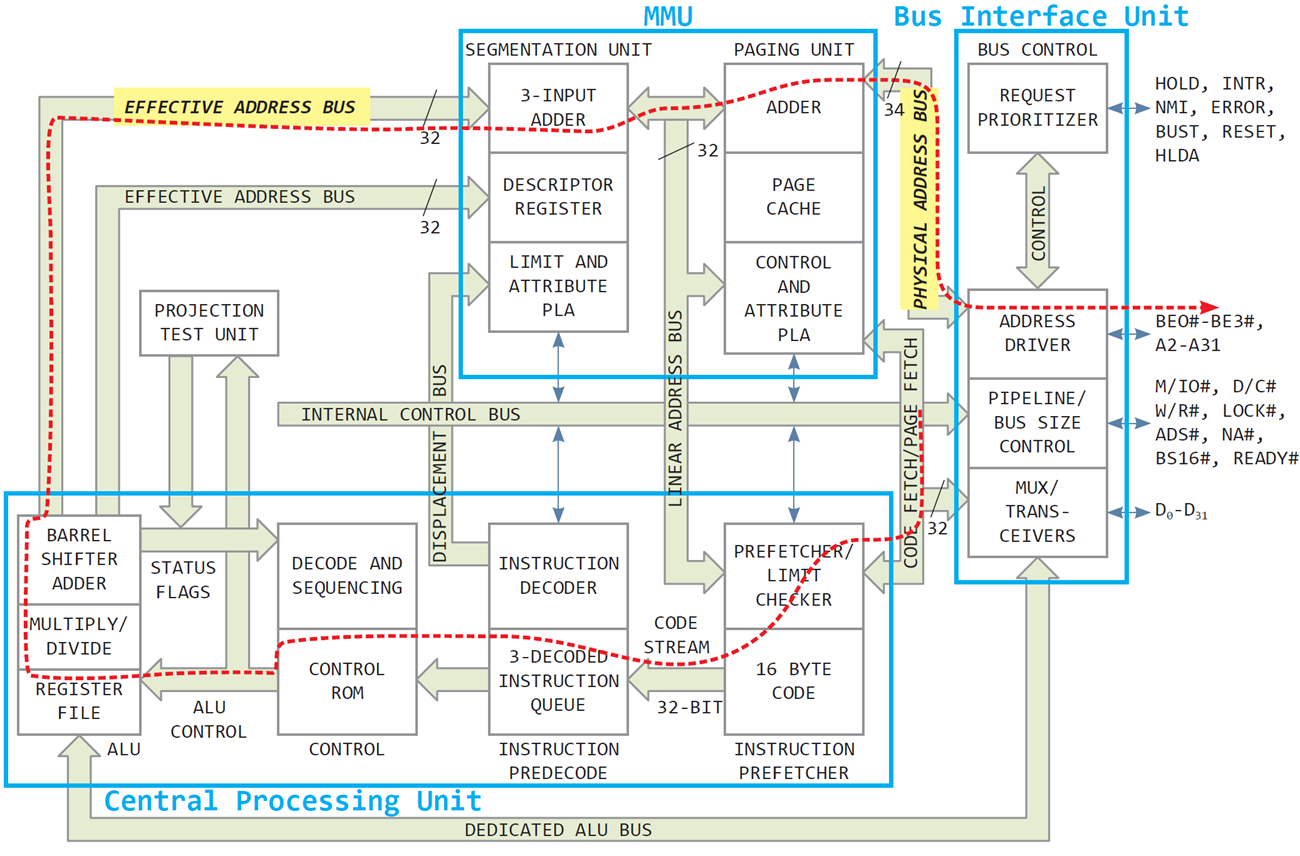
-
80386 칩은 CPU(Central Processing Unit),
BIU(Bus Interface Unit),MMU(Memory Management Unit)로 구성됨 -
MMU는 Segmentation Unit, Paging Unit으로 구성됨
-
PAGE CACHE
MMU 내부에 위치하며, 매핑 테이블의 일부를 저장해두는 캐시이다.
탐구 8-1
#include <stdio.h>
int n = 0;
int main() {
printf("변수 n의 주소는 %p\n", &n); // n의 주소 출력
}$ gcc -no-pie -o logical logicaladdress.c
$ ./logical
변수 n의 주소는 0x60103c
$ ./logical
변수 n의 주소는 0x60103c
$ ./logical
변수 n의 주소는 0x60103c
$전역 변수 n의 주소는 논리 주소이기 때문에
실행할 때 마다 주소가 같다.
단, 온라인 터미널 (Cocalc)등에서 실행 시,
메모리 보호 기능인 PIE에 의해 전역 변수와 코드의 논리 주소가 매번 변경된다.
PIE는 ASLR과 달리 코드 영역과 데이터 영역의 논리 주소까지 바꿈
$ gcc –no-pie –o logical logicaladdress.c: 보호 기능 제거 후 컴파일
TIP: ASLR
ASLR
-
해커들의 메모리 공격에 대한 대비책, 오늘날 대부분의 운영체제가 사용
-
주소 공간 랜덤 배치
프로세스의 주소 공간 내에서 스택이나 힙, 라이브러리 영역의 랜덤 배치
실행할 때 마다 논리 주소가 바뀌게 하는 기법
→ 실행 마다 함수의 지역 변수와 동적 할당 받는 메모리의 논리 주소가 바뀜 -
코드와 전역 변수가 적재되는 데이터 영역의 논리 주소는 바뀌지 않음
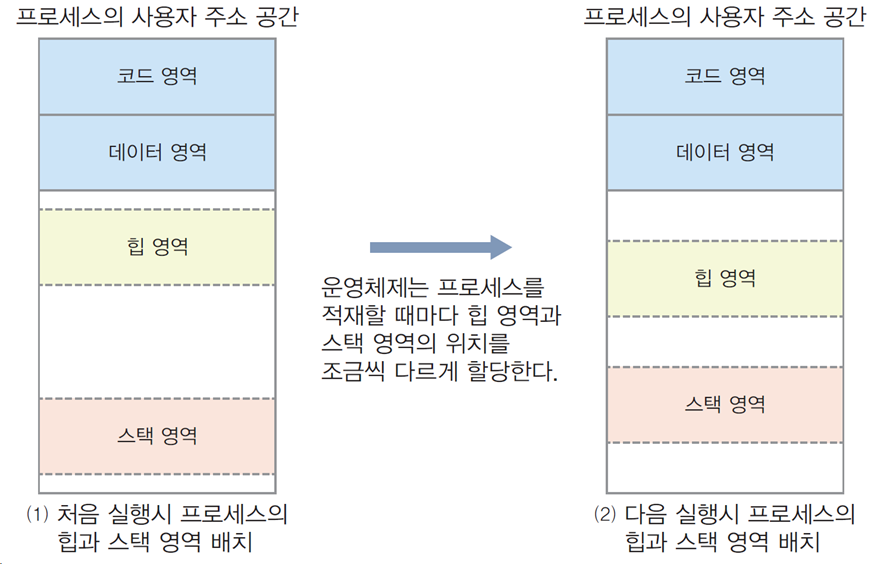
03. 물리 메모리 관리
3.1 메모리 할당(memory allocation)
메모리 할당
-
운영체제가 새 프로세스를 실행시키거나
실행 중인 프로세스가 메모리를 필요로 할 때
프로세스에게 물리 메모리를 할당하는 것 -
프로세스의 실행은 할당된 물리 메모리에서 이루어짐
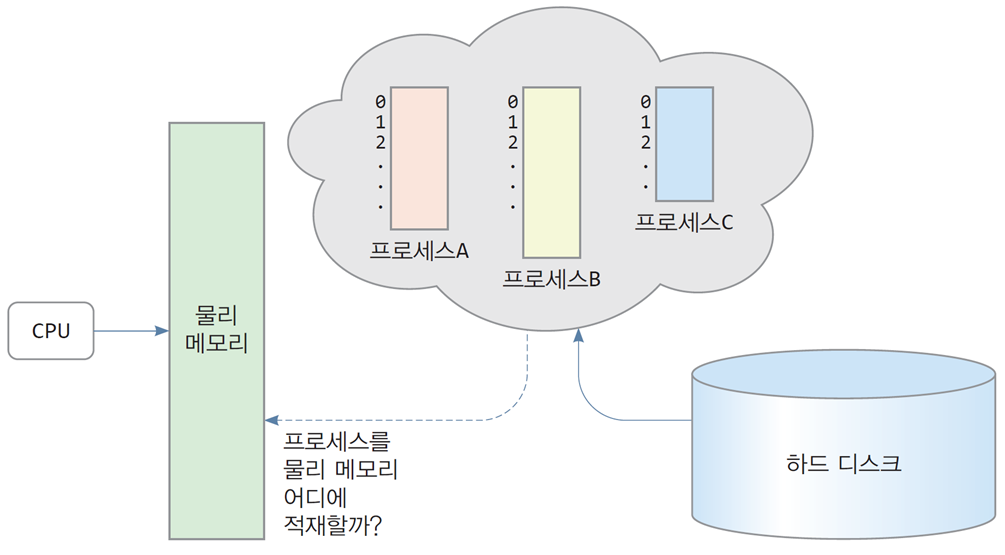
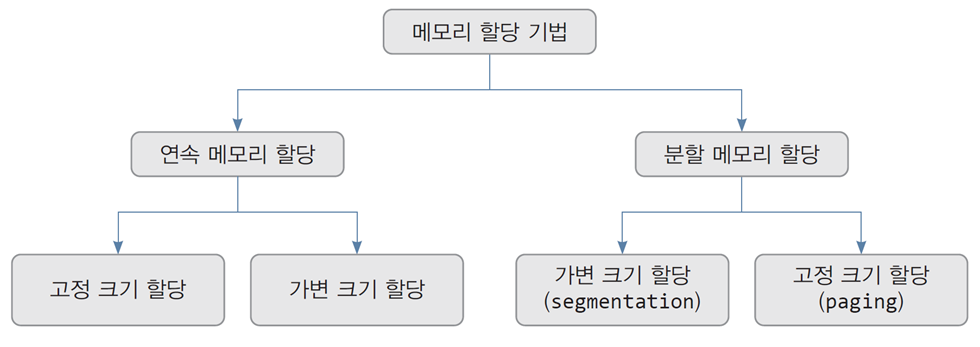
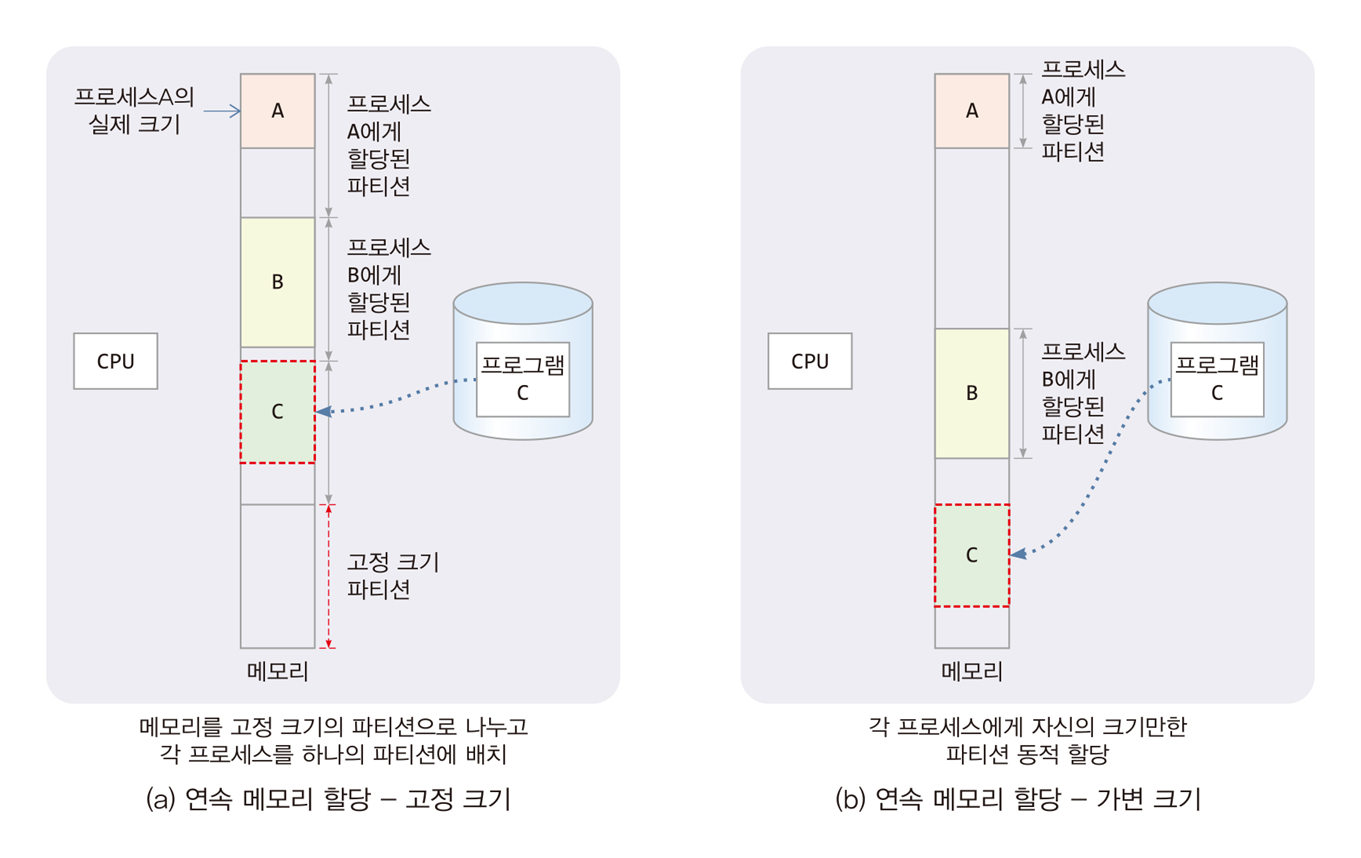
3.2 연속 메모리 할당(contiguous memory allocation)
- 프로세스별로 연속된 한 덩어리(single contiguous memory)의 메모리 할당
프로세스가 할당받은 메모리가 한 덩어리로 연속된 공간이라는 의미
고정 크기 할당(fixed size partition allocation)
-
메모리를 고정 크기의 파티션으로 나누고, 프로세스 당 하나의 파티션 할당
-
파티션이 미리 나누어져 있기 때문에
고정 할당(fixed partitioning)
또는 정적 할당(static partitioning)이라고도 한다.
가변 크기 할당(variable size partition allocation)
-
메모리를 가변 크기의 파티션으로 나누고, 프로세스 당 하나의 파티션 할당
-
파티션이 미리 나누어져 있지 않고, 프로세스의 크기나 요청에 따라 바뀌므로
동적 할당(dynamic partiitioning)이라고도 한다.
단점
-
연속된 메모리를 할당하기 때문에 메모리 할당의 유연성이 부족
-
메모리 전체에 비어 있는 작은 공간(홀)들을 합하면 충분한 공간이 있음에도,
프로세스를 할당할만큼 연속된 메모리가 없어 적재할 수 없음
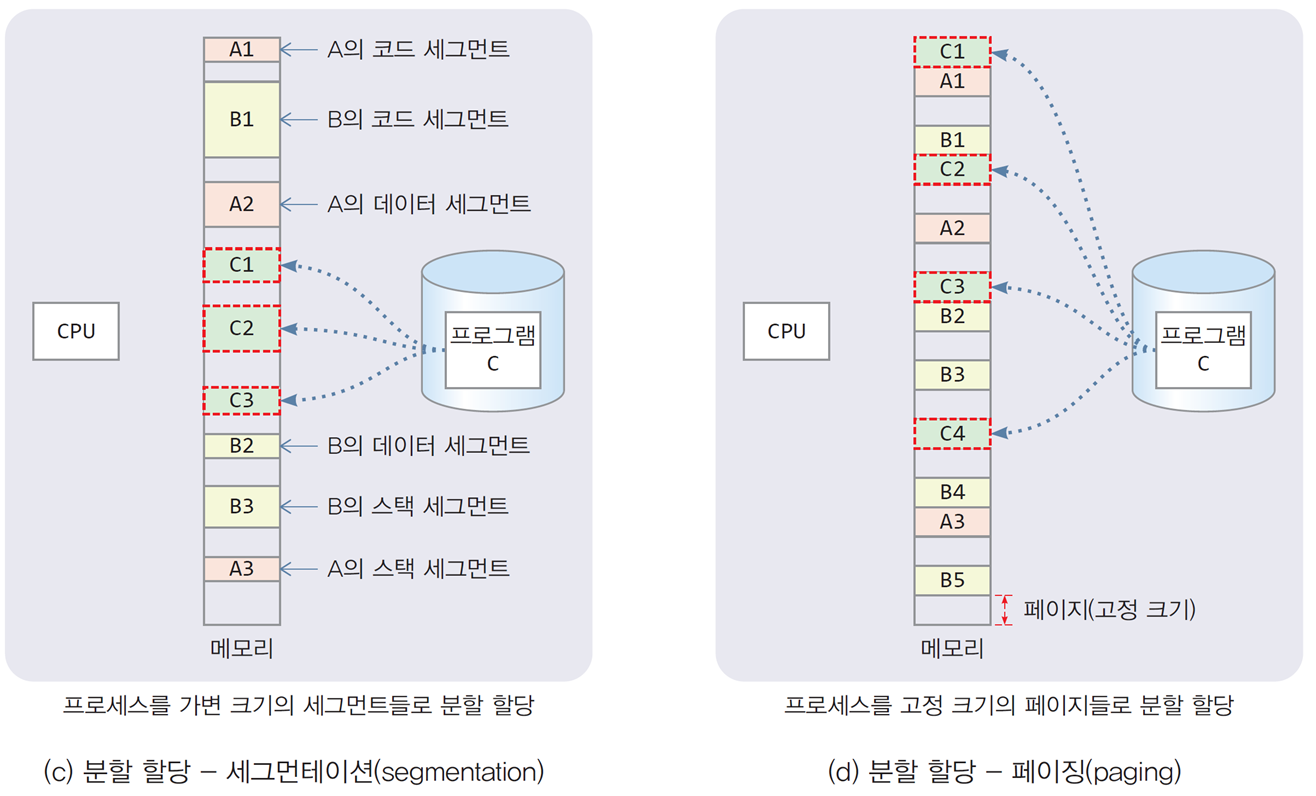
3.3 분할 메모리 할당(non-contiguous memory allocation)
- 프로세스에게 여러 덩어리의 메모리 할당
가변 크기 할당: 세그먼테이션(segmentation)
-
가변 크기의 덩어리 메모리를 여러 개 분산 할당
-
세그먼트(segment)
프로세스 내에서 하나의 단위로 다룰 수 있는 의미 있는 블록
하나의 함수, 객체가 될 수 있음
프로세스에 존재하는 각 세그먼트의 크기가 다름 -
대부분의 시스템에서는 프로세스를
코드, 데이터, 스택, 힙의 4개 세그먼트로 분할·할당한다.
단점
- 프로세스들이 실해되고 종료되기를 반복하고 나면, 메모리에 적재된 세그먼트들 사이에 빈 공간이 생기게 되며, 일부는 크기가 작아
새 프로세스에게 할당하지 못하는 메모리 낭비(외부 단편화)가 초래됨
고정 크기 할당: 페이징(paging)
-
고정 크기의 덩어리 메모리를 여러 개 분산 할당
-
세그먼테이션의 메모리 낭비를 해결하기 위해 도입됨
-
프로세스를 논리적인 단위로 분할하지 않고, 논리주소 0번지부터
페이지(page)라고 부르는 고정 크기(동일한 크기)로 분할 -
물리 메모리 또한 페이지와 동일한 크기로 분할하여 프레임(frame)이라고 함
현대 컴퓨터 시스템은 페이징 기법을 기반으로 세그먼테이션을 혼합 사용함
04. 연속 메모리 할당
-
프로세스를 1개의 연속된 메모리 공간에 배치
메모리 전체를 여러 개의 파티션으로 분할
각 프로세스에게 한 파티션 할당 -
연속 메모리 할당은 초기 운영체제에서 사용
MS-DOS: 한 프로세스가 전체 메모리 독점
초기의 다중프로그래밍 운영체제
4.1 고정 크기 할당
- 메모리를 처음부터 파티션(partition)이라고 부르는 고정 크기로 나누고,
프로세스에게 1개의 파티션을 할당
4/8/16KB 등 몇가지 파티션들을 만들어두고 적합한 파티션을 할당
IBM OS/360 MFT(Multiple Programming with a Fixed Number of Tasks)
-
메모리 전체를 n개의 동일한 파티션으로 분할하여 프로세스마다 하나씩 할당
-
동시에 실행시킬 수 있는 프로세스 또한 n개
-
메모리가 부족할 때, 프로세스는 큐에서 대기
단점
-
프로세스가 파티션의 크기보다 작은 경우 메모리의 일부가 낭비됨
-
파티션보다 큰 크기의 프로세스는 처음부터 실행될 수 없음
→ 시스템 운영자에 의해
실행시킬 전체 응용프로그램들의 크기가 사전에 계산됨

4.2 가변 크기 할당
-
고정 크기 할당의 메모리 낭비(내부 단편화)를 해결하기 위해 제시됨
-
처음부터 파티션을 나누어 놓지 않고, 프로세스와 동일한 크기의 메모리 할당
IBM OS/360 MVT(Multiple Programming with a Variable Number of Tasks)
-
할당되는 메모리 공간을 리전(region)이라고 부름
-
수용 가능한 프로세스의 개수는 가변적
고정 크기 할당과 가변 크기 할당 모두 가상 메모리 기법을 지원하지 않음

4.3 단편화(fragmentation)
- 프로세스에게 할당할 수 없는 조각 메모리들이 생기는 현상
- 조각 메모리를 홀(hole)이라고 부름
내부 단편화(internal fragmentation)
- 할당된 메모리 내부에 사용할 수 없는 홀이 생기는 현상
파티션보다 작은 프로세스를 할당하는 경우, 파티션 내에 홀 발생
IBM OS/360 MFT

외부 단편화(external fragmentation)
-
할당된 메모리들 사이에 사용할 수 없는 홀이 생기는 현상
가변 크기의 파티션이 생기고 반환되는 과정에서 작은 홀 생성
홀이 프로세스의 크기보다 작으면 할당할 수 없음
IBM OS/360 MVT
→ MFT의 내부 단편화 문제를 해결하기 위해 만들어진 개선된 운영체제 -
메모리 압축(memory compaction)
외부 단편화로 인해 할당할 메모리가 부족해지면
파티션을 이동시켜 홀을 없애는 방법
4.4 연속 메모리 할당 구현
- 연속 메모리 할당 구현을 위해서는 고정/가변 관계 없이 모두
하드웨어와 운영체제의 지원이 필요함
하드웨어 지원
- 논리 주소를 물리 주소로 변환하는 기능
- 프로세스가 다른 프로세스의 메모리 액세스를 금지하는 기능
base 레지스터: 현재 실행 중인 프로세스에게 할당된 물리 메모리 시작 주소
limit 레지스터: 현재 실행 중인 프로세스에게 할당된 메모리 크기
주소 레지스터: 현재 액세스하는 메모리의 논리 주소
주소 변환 하드웨어(MMU): 논리 주소를 물리 주소로 변환하는 장치
- MMU는 논리 주소를 물리 주소로 바꾸기 전,
다른 프로세스의 메모리 보호를 위해 논리 주소를 limit 레지스터의 값과 비교
할당된 메모리 주소 범위를 넘어섰다면 (논리주소 ≥ limit)
→ 오류 처리 커널 코드를 실행하고, 현재 프로세스를 강제 중단
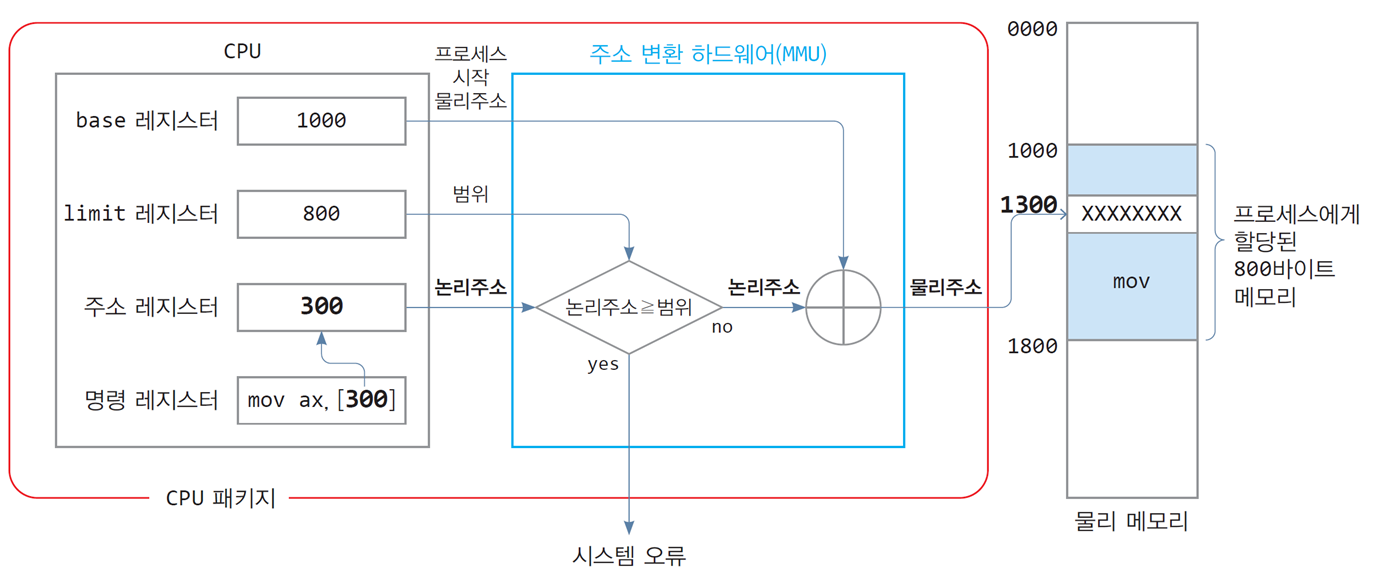
현재 1000~1799번지에 적재된 상황
운영체제의 지원
-
운영체제는 모든 프로세스에 대해
할당된 물리 메모리의 시작 주소와
크기 정보를 저장·관리 및 비어 있는 메모리 영역 관리 -
새 프로세스 스케줄링 시,
프로세스의 물리 메모리 시작 주소와
크기 정보를 CPU 내부의 base/limit 레지스터에 적재
4.5 홀 선택 알고리즘(hole selection algorithm)
-
또는 동적 메모리 할당(dynamic memory allocation)
-
프로세스를 처음 실행시키거나 실행 도중 메모리가 요구될 때,
적당한 홀을 선택해서 할당하는 기법
고정 크기
- 운영체제는 홀(파티션)들을 가용 메모리 리스트로 만들어 관리·선택함
가변 크기
-
홀마다 시작 주소와 크기 정보에 대한 홀 리스트 생성 및 관리
-
first-fit
홀 리스트에서 처음 만나는 요청 크기보다 큰 홀 선택
할당 속도가 빠르지만, 외부 단편화로 인한 메모리 낭비가 큼 -
best-fit
홀 리스트에서 요청 크기를 수용하는 것 중 가장 작은 홀 선택
리스트가 정렬되지 않았을 때, 탐색 부담
할당 후 가장 작은 홀이 생성됨 -
worst-fit
홀 리스트에서 요청 크기를 수용하는 것 중 가장 큰 홀 선택
리스트가 정렬되지 않았을 때, 탐색 부담
할당 후 가장 큰 홀이 생성됨
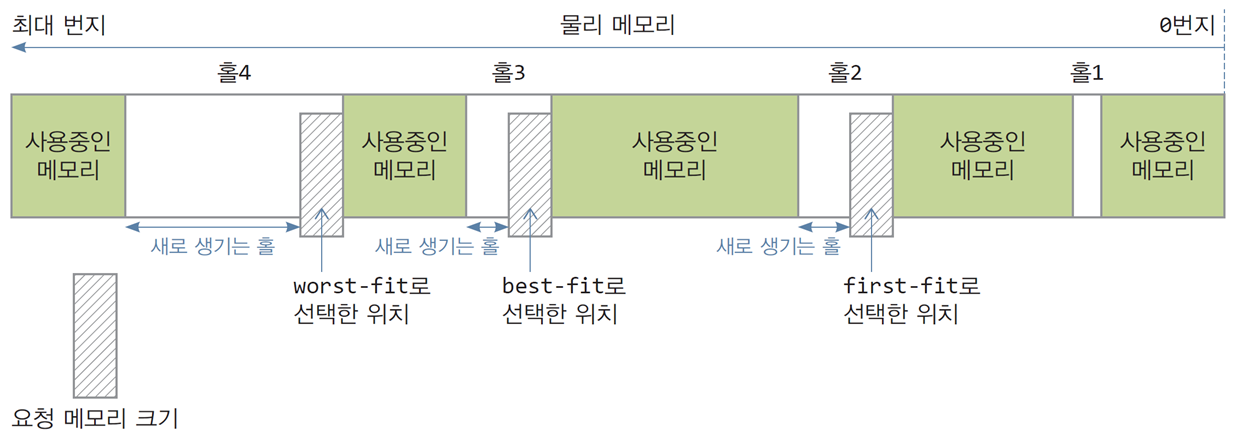
worst-fit 기법은 잘 사용하지 않음
단편화: 홀이 생기는 현상이 아닌,
메모리 할당 요청에 사용할 수 없게 된 작은 홀이 생기는 현상
4.6 연속 메모리 할당의 장단점
장점
- 논리 주소 → 물리 주소의 과정이 단순
- CPU의 메모리 액세스 속도 빠름
- 운영체제가 관리할 정보량이 적어서 부담이 덜함
단점
- 메모리 할당의 유연성이 떨어짐
- 작은 홀들을 합쳐 충분한 크기의 메모리가 있음에도,
연속된 메모리를 할당할 수 없는 문제가 발생
4.7 버디 시스템
-
오늘날 리눅스의 커널 메모리 관리에 사용되는 메모리 할당 알고리즘
-
고정 크기 할당과 가변 크기 할당의 장점을 결합하여 사용
05. 세그먼테이션 메모리 관리
5.1 세그먼테이션의 개요
세그먼트(segment)
- 프로그램을 구성하는 논리적 단위
- 각 세그먼트는 서로 크기가 다르다
- 세그먼트는 코드/데이터/스택/힙 세그먼트로 나뉨
세그먼테이션 기법
- 프로세스를 논리 세그먼트들로 나누고,
각 논리 세그먼트를 물리 메모리에 할당하는 메모리 관리 기법
프로세스의 주소 공간
- 프로세스의 주소 공간은 여러 개의 논리 세그먼트들로 구성
- 각 논리 세그먼트는 물리 세그먼트에 매핑
- 프로세스를 논리 세그먼트로 나누는 과정은 컴파일러와 링커에 의해 이루어짐
- 컴파일러와 링커는 응용프로그램과 라이브러리의 코드를 모아
코드 세그먼트를 구성하고, 전역변수들을 모아 데이터 세그먼트 구성
- 컴파일러와 링커는 응용프로그램과 라이브러리의 코드를 모아
- 운영체제와 로더는 실행 파일에 구성된 각 논리 세그먼트를
물리 세그먼트에 할당, 논리 세그먼트 적재
- 운영체제와 로더는 실행 파일에 구성된 각 논리 세그먼트를
5.2 논리 세그먼트와 물리 세그먼트의 매핑
-
운영체제는 프로세스의 각 논리 세그먼트가 할당된
물리 메모리 위치를 관리하기 위해 세그먼트 테이블을 구성함
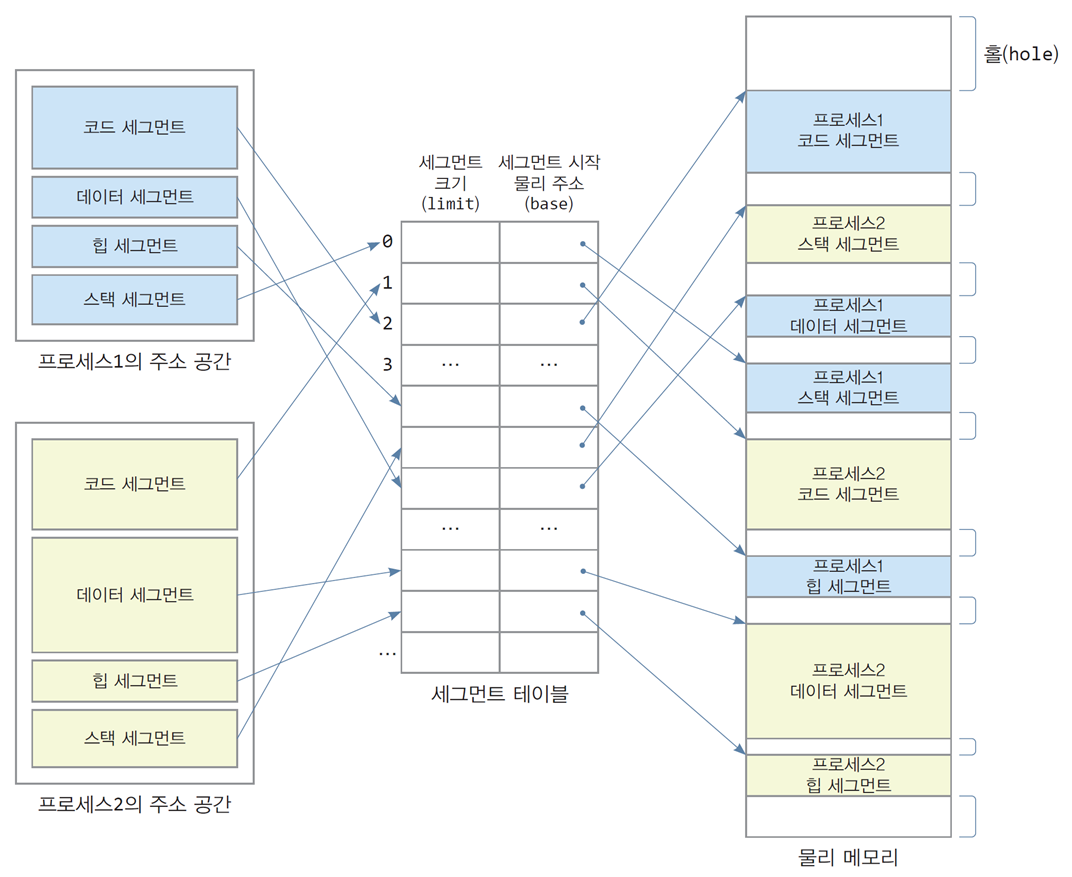
-
세그먼트 테이블에는 세그먼트 크기를 담은 limit와
세그먼트 시작 물리 주소를 담은 base 정보가 저장된다. -
세그먼트 테이블은 시스템에 1개만 존재함
-
프로세스의 실행과 종료에 따라 물리 메모리에는 홀이 생기며,
이로 인해 외부 단편화가 초래됨 -
새로운 프로세스가 실행되면 적절한 홀을 찾기 위한 홀 선택 알고리즘이나 동적 메모리 할당 알고리즘을 사용함
5.3 세그먼테이션의 구현
- CPU, 컴파일러와 링커, 운영체제, 로더 등이 모두 세그먼테이션을 지원
- 세그먼테이션의 구현은 CPU에 매우 의존적
하드웨어 지원
논리주소 구성
세그먼테이션의 논리주소 = [세그먼트 번호(s), 옵셋(offset)]
세그먼트 번호: 세그먼트 테이블에서 몇 번째 항목인지 나타내는 index정보
세그먼트 테이블
index(세그먼트 번호) | base | limit
0번 | 1000 | 500
1번 | 2000 | 300
2번 | 3000 | 200옵셋: 세그먼트 내 상대 주소
물리 메모리
1000번지 ← 코드 세그먼트 시작 (base)
1001번지
1002번지
1003번지
...
물리 주소 1002번지는 세그먼트 시작점으로부터 2번째 떨어진 곳
즉, 옵셋은 2가 됨
따라서 물리 주소 = base + offsetCPU
- 세그먼트 테이블의 시작 주소를 가리키는 레지스터
(segment table base register)
MMU 장치
- 논리 주소 → 물리 주소 변환 장치
- 논리 주소가 세그먼트 범위를 넘는지 판별(메모리 보호)
(offset ≥ limit) 판별, offset이 더 작아야 함 - 논리 주소의 물리 주소 변환(메모리 할당)
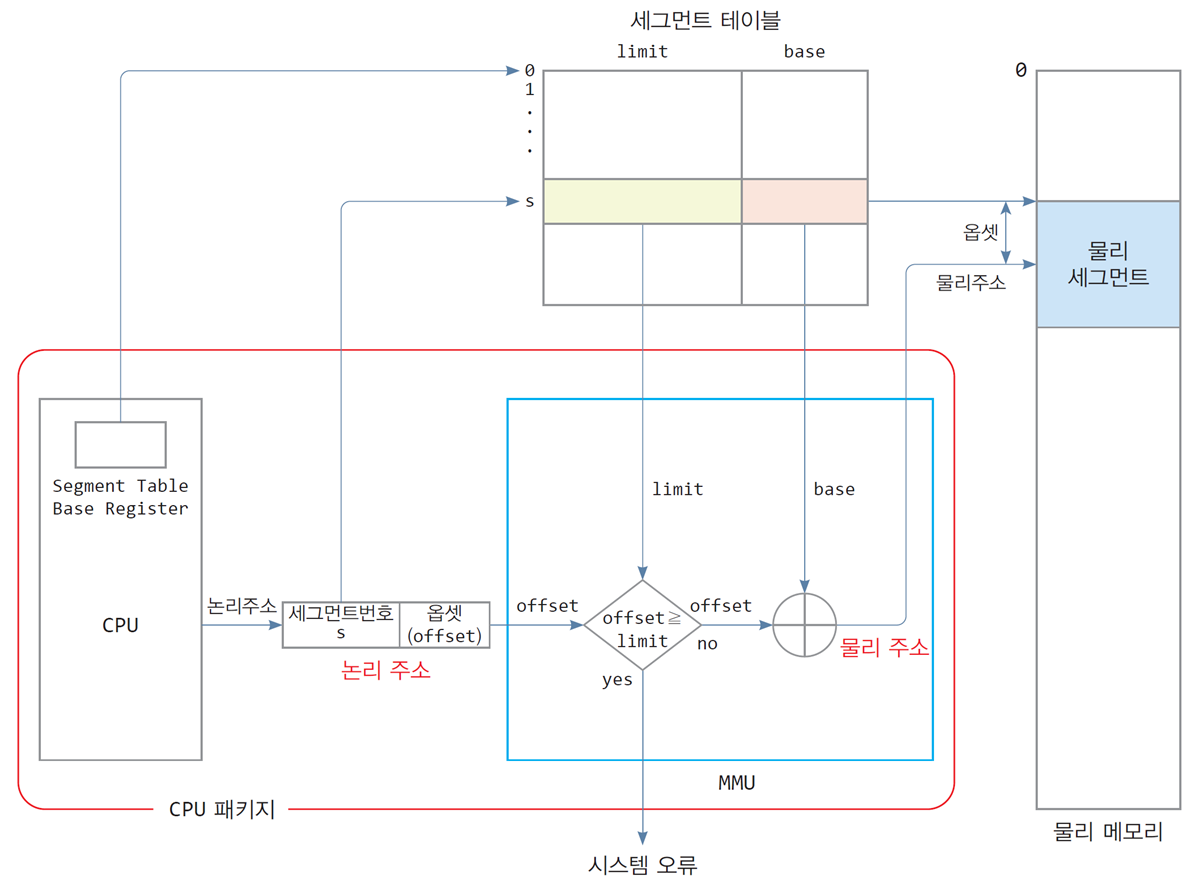
세그먼트 테이블
- 메모리에 저장
- 세그먼트별로 시작 물리 주소와 세그먼트 크기 정보
- 세그먼트 테이블의 일부를 MMU 내에 두기도 함
운영체제 지원
-
할당된 물리 세그먼트들과 빈 메모리(홀) 리스트로 만들고 관리
-
논리 세그먼트를 적재할 물리 세그먼트 할당·반환 기능
컴파일러, 링커, 로더 지원
-
사용자 프로그램은 컴파일러에 의해 사전에 정의된 세그먼트들로 분할·링킹
-
기계 명령에 들어가는 메모리 주소
[세그먼트 번호, 옵셋]형식으로 컴파일 -
로더는 실행 파일에서 만들어진 논리 세그먼트 인지·세그먼트 테이블 갱신
5.4 단편화
-
세그먼테이션 기법은 가변 크기로 물리 세그먼트들을 할당하므로
외부 단편화가 필연적으로 발생 -
내부 단편화는 발생하지 않음
