강의 목표
-
페이지와 페이지 테이블로 이루어지는 페이징 메모리 관리의 개념을 이해한다
-
페이징에서 논리 주소와 물리 주소의 관계를 이해하고
주소 변환에 대해서 안다 -
페이지 테이블로 인한 2가지 문제점을 이해하고 해결 방법을 안다
-
TLB(Translation Look-aside Buffer)에 대해 알고
TLB가 프로그램의 메모리 액세스 성능을 향상시킴을 사례를 통해 이해한다 -
페이지 테이블의 낭비를 줄이는 방법으로
역페이지 테이블과 멀티 레벨 페이지 테이블에 대해 이해한다
01. 페이징 메모리 관리 개요
1.1 페이징 개념
페이징(paging)
-
프로세스의 주소 공간과 물리 메모리를 페이지 단위로 분할하고,
프로세스의 각 페이지를 물리 메모리의 프레임에 분산 할당하여 관리 -
프로세스의 주소 공간을 0번지부터 동일한 크기의 페이지(page)로 나눔
코드, 데이터, 스택 등 프로세스의 구성 요소에 상관없이
(논리적 의미로 구분하지 않음)
0번지부터 고정 크기로 분할한 단위 -
물리 메모리 역시 0번지부터 페이지 크기로 나누고, 프레임(frame)이라고 부름
물리 메모리에서 페이지 크기의 메모리 블록을
프레임(frame),
페이지 프레임(page frame),
물리 페이지(physical page)로 부름 -
페이지의 크기는 주로 4KB로 설정되지만,
시스템에 따라 8KB, 16KB (2) 등 가능
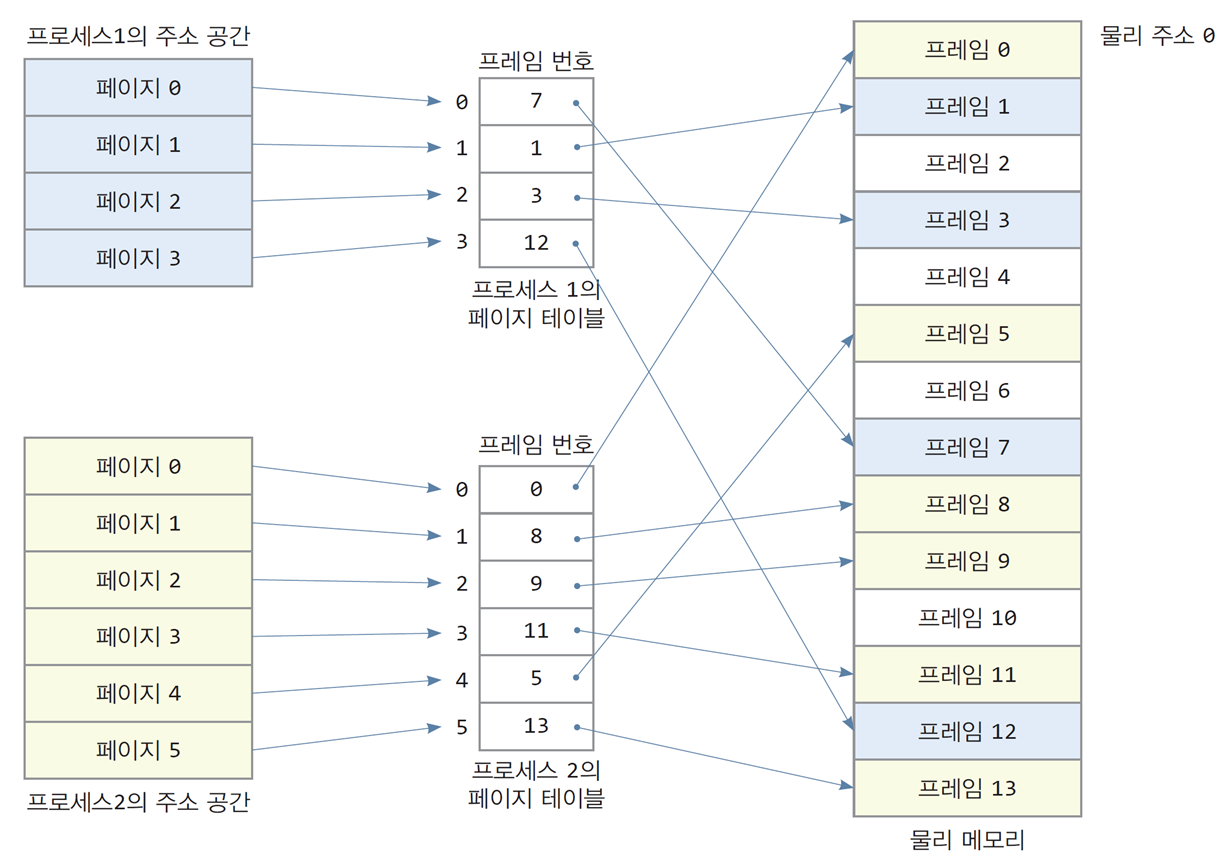
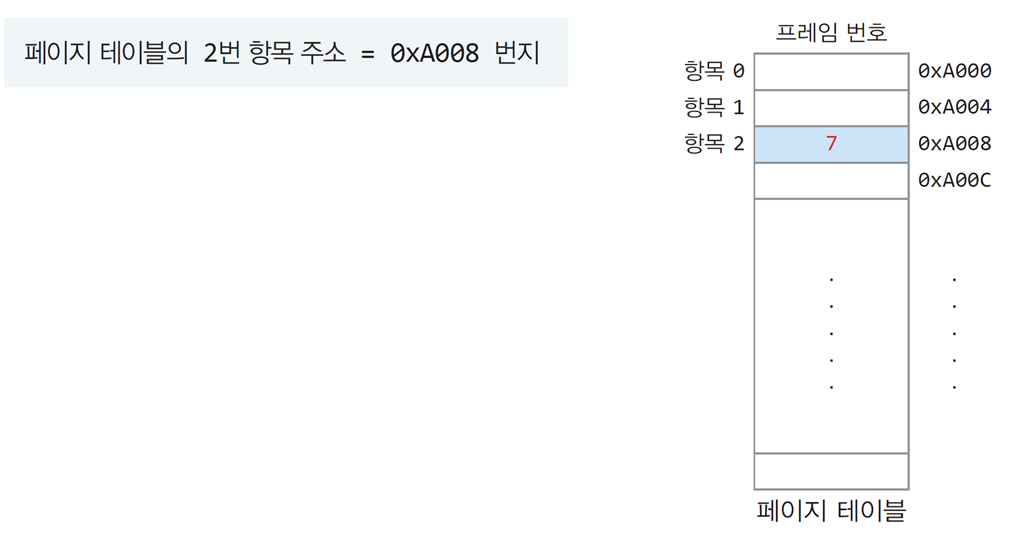
페이지 테이블
-
각 페이지에 대해 페이지 번호와 프레임 번호를 1:1로 저장하는 테이블
페이지 테이블의 크기는 표현 가능한 주소 공간의 크기와 동일함 -
프로세스의 주소 공간은 논리 주소 0번지부터 연속적
물리 메모리에는 분산 할당되어 있음 -
페이지 테이블은 프로세스마다 만들어지며,
프로세스에 속한 모든 스레드는 실행 시 프로세스의 페이지 테이블을 이용
페이징의 우수성
구현이 쉬움(easy)
- 메모리를 0번지부터 고정 크기의 페이지로 분할하기 때문에
세그먼테이션보다 이해·구현이 쉬움
높은 이식성(portable)
- CPU에 의존적이지 않기 때문에
다양한 컴퓨터 시스템에 동일한 방식으로 쉽게 구현 가능
높은 융통성(flexible)
- 시스템·응용에 따라 페이지의 크기를 다르게 설정할 수 있음
외부 단편화 발생 없음
- 홀 선택 알고리즘이 필요하지 않음
- 메모리 활용 및 시간 오버헤드 면에서 우수함
- 내부 단편화가 발생하지만 그 크기가 매우 작음
가장 마지막에 있는 페이지에만 내부 단편화가 발생하기 때문
1.2 페이지 테이블
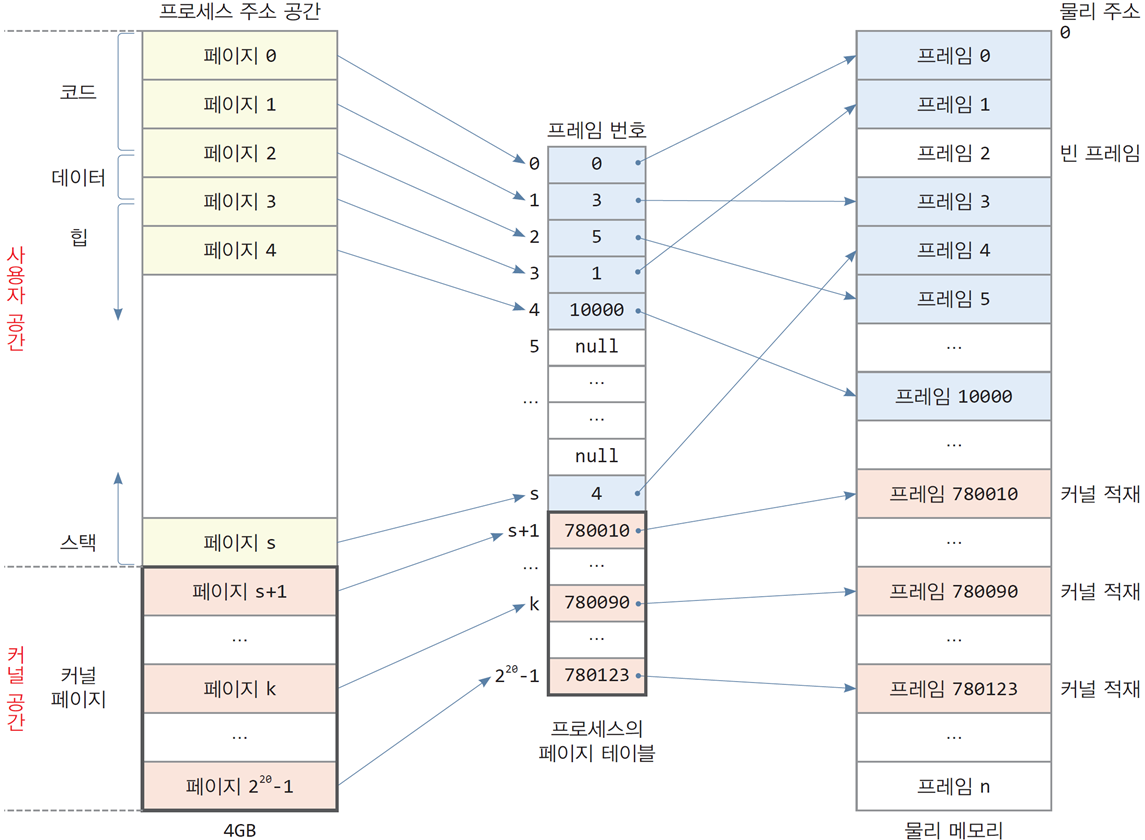
4GB 주소 공간을 가지는 프로세스이며, 페이지 크기는 4KB
사례 프로세스
- 코드: 페이지0 ~ 페이지2
- 데이터: 페이지2 ~ 페이지3
- 힙: 페이지3 ~ 페이지4
- 스택: 사용자 공간의 맨 마지막에 할당
총 프로세스의 크기: 6(할당된 페이지) x 4KB(페이지 하나의 크기) = 24KB
- 페이지 테이블의 대부분의 항목은 비어 있음
프로세스가 동적 할당 받을 때
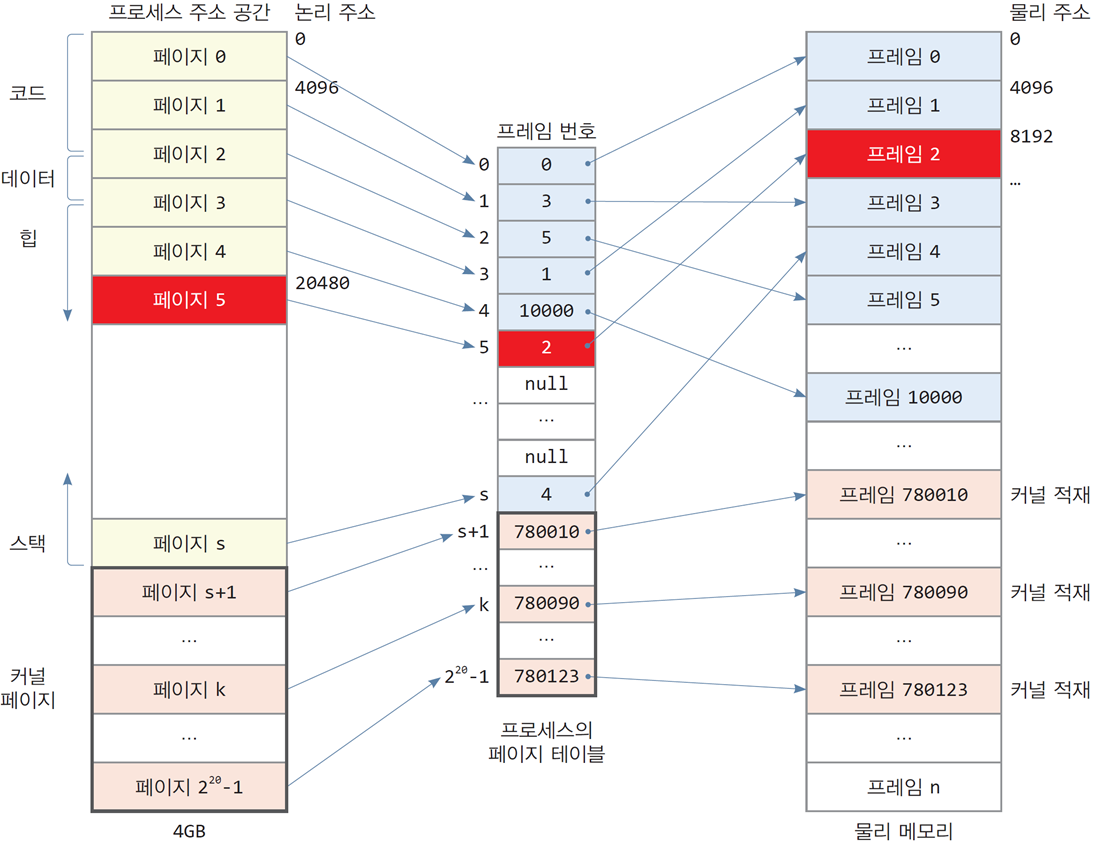
char *p = (char*)malloc(200);
// 프로세스의 힙 영역에서 200 바이트 동적 할당-
운영체제는 200바이트의 메모리를 할당하기 위해
프로세스의 힙 영역에 페이지 5를 할당
페이지 단위로 할당 -
비어 있는 물리 프레임 2를 할당하고
프로세스 테이블의 항목 5에 프레임 번호 2를 기록
페이지 5의 논리 주소
5 x 4KB(4 x 1024 = 4096 bytes) = 20KB = 20 x 1024 = 20480 번지
프레임 2의 물리 주소
2 x 4KB(4096 bytes) = 8192 번지
*p = 'a'; // 페이지 5에 문자 'a' 기록-
CPU는
20480번지에'a'를 저장하는 프로그램을 시작 -
MMU에 의해 논리 주소
20480이 물리 주소8192로 바뀌어,
물리 메모리 8192 번지에 'a' 저장
free(p);-
반환 후 페이지 5 전체가 비게 되므로
페이지 5와 프레임 2 모두 반환 -
페이지 테이블의 항목 5에
null이 기록됨
시스템 호출시 프로세스의 페이지 테이블 활용
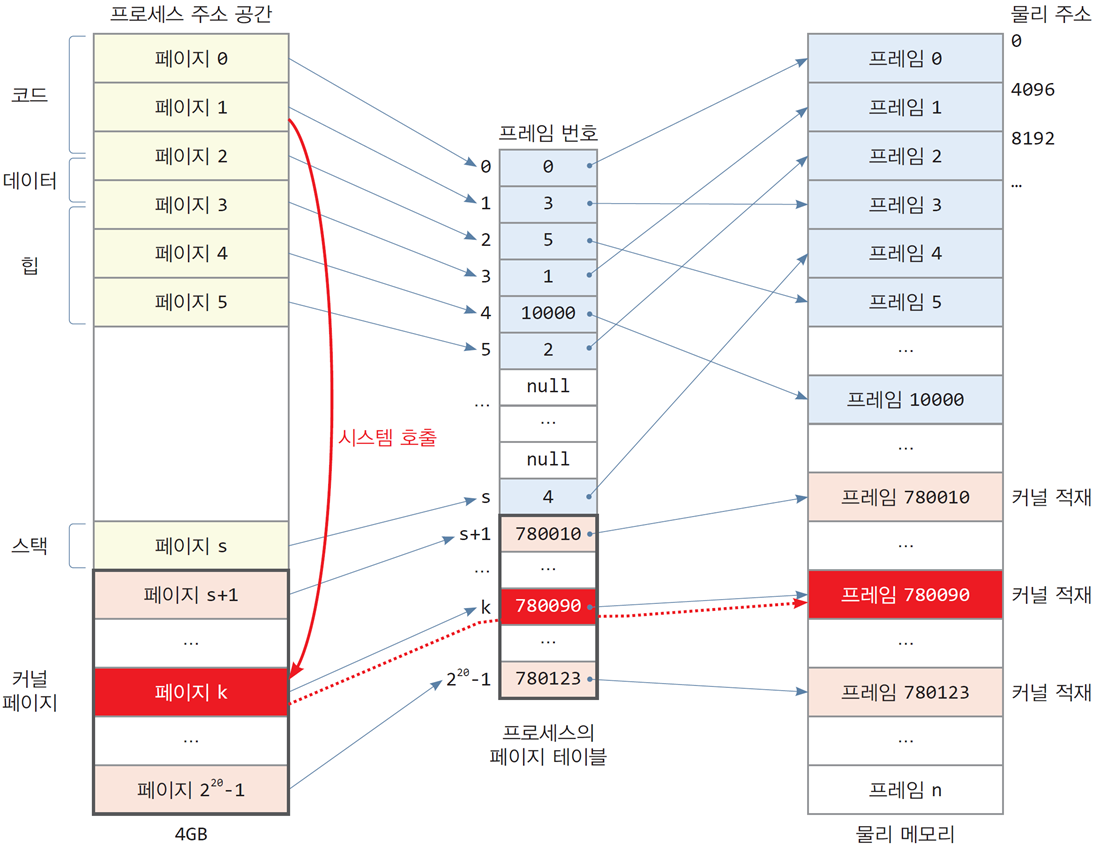
프로세스가 페이지 1의 코드에서 시스템 호출을 하는 경우
-
커널 공간의 페이지 k에 담긴 커널 코드 실행
-
커널 코드 역시 논리 주소로 되어 있음
-
현재 프로세스 테이블을 통해 페이지 k의 물리 프레임
780090을 알아내고
물리 프레임780090에 저장된 커널 코드 실행
커널 페이지를 위한 페이지 테이블
-
페이지 테이블 항목 중 커널 공간에 대한 항목들은
모든 프로세스에 대해 동일하므로 프로세스마다 두면 메모리 낭비가 됨 -
운영체제에서는 커널 페이지에 대한
페이지 테이블 항목을 분리하여 공유하도록 구현함
페이지와 페이지 테이블에 대한 정리
32비트 CPU에서, 페이지 크기가 4KB인 경우
-
Q1. 물리 메모리의 최대 크기는?
A: 32비트 컴퓨터이므로 물리 주소의 범위는 0 ~ 2 - 1
2 x 2 = 4GB -
Q2. 프로세스의 주소 공간의 크기는?
A: 위와 같은 이유로 4GB
물리 메모리는 1/2/4GB 등 다양하게 설치될 수 있지만,
프로세스의 주소 공간은 물리 메모리 크기에 상관없이 4GB -
Q3. 한 프로세스는 최대 몇 개의 페이지로 구성되는가?
A: 4GB/4KB = 2 / 2 = 2 = 1MB = 100만개 -
Q4. 프로세스당 하나의 페이지 테이블이 있다. 페이지 테이블의 크기는?
A: 32비트 컴퓨터이므로 엔트리 하나의 크기는 32비트(= 4바이트)
페이지의 개수는 2개 이므로 2 x 4 = 2 = 4MB
페이지 번호 | 프레임 번호(엔트리)
0번 | (4byte)
1번 | (4byte)
2번 | (4byte)
...
2²⁰-1번 | (4byte)-
Q5. 그림 9-2의 상황에서 프로세스가 사용자 공간에서 사용하고 있는 크기는?
A: 총 6개 페이지 사용 -
Q6. 응용프로그램이 하나의 프로세스라고 할 때, 응용프로그램의 최대 크기, 즉 개발자가 작성할 수 있는 프로그램의 최대 크기는?
A: 사용자 공간의 크기와 동일 -
Q7. 페이지 테이블 모양은?
A: 대부분의 항목들이 비어 있는 희소 테이블(sparse table)
낭비가 심해 줄이는 기법이 필요 -
Q8. 페이지 테이블은 어디에 존재하는가?
A: 메모리에 저장 -
Q9. 커널 코드는 논리 주소로 되어있는가 물리 주소로 되어있는가?
A: 커널 코드 역시 논리 주소로 되어 있음
커널 코드가 실행될 때 물리 주소로 바뀌어야 하는데,
이 때 현재 프로세스의 페이지 테이블을 사용함
1.3 단편화
-
외부 단편화 발생하지 않음
-
내부 단편화 발생
프로세스의 마지막 페이지에만 발생
단편화의 평균 크기 = 페이지의 1/2
탐구 9-1
32비트 CPU에서, 페이지 크기 2KB, 설치된 물리 메모리 1GB, 프로세스 A는 사용자 공간에서 54321바이트를 차지한다고 할 때,
-
Q1: 물리 메모리의 프레임 크기는?
2KB. 페이지 크기와 동일 -
Q2: 물리 메모리의 프레임 개수는?
물리 메모리를 프레임 크기로 나누면 됨. 1GB/2KB = 2/2 = 2개, 약 50만개 -
Q3: 프로세스의 주소 공간 크기와 페이지의 개수는?
프로세스의 주소 공간 크기는 2 = 4GB
페이지의 개수 = 2/2= 2개 =2M개 = 약 2백만개 -
Q4: 프로세스 A는 몇 개의 페이지로 구성되는가? 프로세스 A를 모두 적재하기 위한 물리 프레임의 개수는?
프로세스 A의 실제 크기가 54321바이트이므로, 2KB(2048)로 나누면 54321/2048=26.5이므로 27개 페이지로 구성되며, 물리 프레임 역시 27개 필요 -
Q5: 페이지 테이블 항목 크기가 4바이트라고 할 때, 프로세스 A의 페이지 테이블 크기는?
테이블 항목이 총 2개이므로 2x 4바이트 = 2바이트 = 8MB -
Q6: 페이징에서 단편화 메모리의 평균 크기는?
프로세스의 코드와 데이터 연속되어 있으므로, 마지막 페이지에만 단편화가 생긴다. 단편화 메모리의 평균은 페이지의 반이므로 1KB -
Q7: 페이지의 크기와 단편화의 관계는?
페이지의 크기가 크면 단편화도 커진다. -
Q8: 페이지의 크기와 페이지 테이블의 크기 관계는?
페이지 크기가 크면 페이지 개수가 작아지고
페이지 테이블의 크기도 작아진다.
02. 페이징의 주소 체계
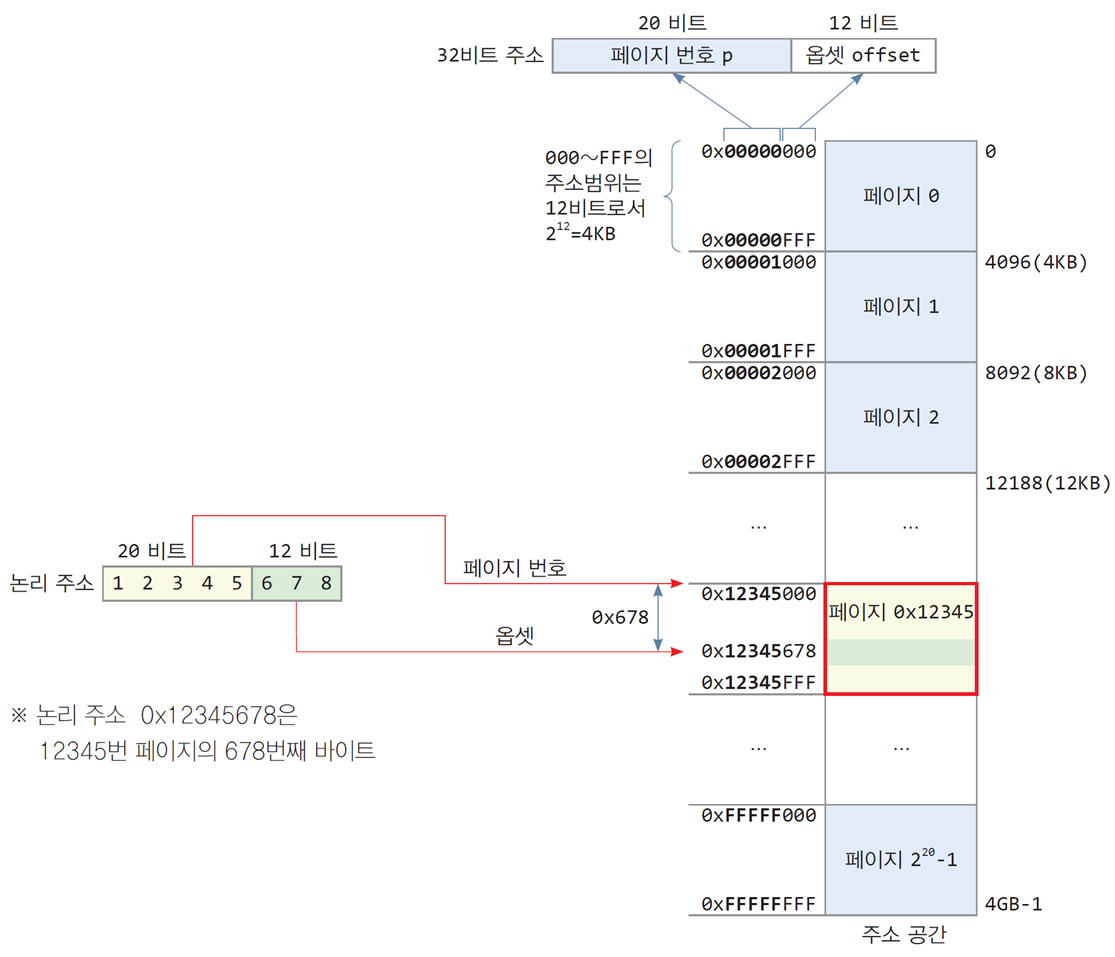
2-1. 페이징의 논리 주소
논리 주소 = [페이지 번호(p), 옵셋(offset)]
-
페이지 크기가 4KB라면, 페이지 내 각 바이트 주소는 12비트
4KB = 4 x 1024 = 4096 bytes
페이지 내 0 ~ 4095번지까지 존재
→ 4096가지를 표현하려면 2
→ 12비트로 0 ~ 4095 표현 가능
→ 페이지 안의 모든 위치를 표현하려면 12비트 필요 -
32비트 논리 주소 체계에서
상위 20비트는 페이지 번호
하위 12비트는 옵셋

-
16진수(
0x)는 한 자리에 0 ~ F까지의 총 16가지를 표현해야 하므로,
2 = 16, 즉 한 자리당 4비트를 가짐
→ 따라서 하위 3자리가 12비트가 되고, 옵셋이 됨 -
논리 주소
0x12345678은
12345번 페이지의 678번째 바이트
2.2 논리 주소의 물리 주소 변환
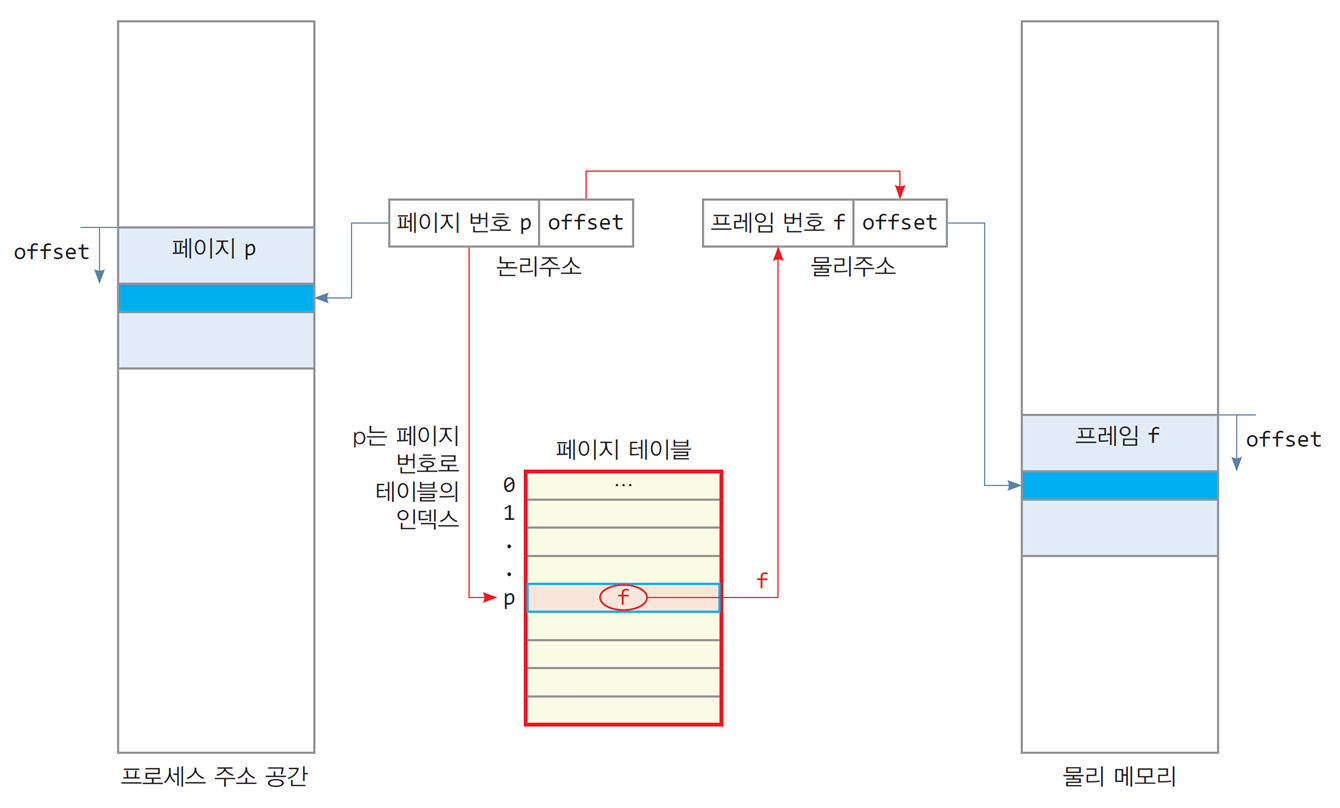
- 페이지 번호
p를 테이블의 인덱스로 하여 페이지 테이블 항목을 찾으면
페이지p가 할당된 프레임 번호f를 얻을 수 있음
→ 페이지 번호p를 프레임 번호f로 바꾸고 옵셋을 그대로 사용하면
논리 주소를 물리 주소로 바꿀 수 있음
2.3 페이징 구현
- 페이징 기법이 컴퓨터 시스템에 구현되기 위해서는
CPU와 MMU, 그리고 운영체제의 공동 지원이 있어야 함
하드웨어 지원
-
CPU
CPU 칩 내에는 현재 실행 중인 프로세스의 페이지 테이블이 적재된
물리 메모리 주소를 가진 PTBR(Page Table Base Register)이 필요함 -
이 레지스터 값은 PCB에 저장되며, 운영체제에 의해 제어됨
-
논리 주소를 물리 주소로 바꾸기 위한 MMU 장치가 CPU 칩에 패키징됨
운영체제 지원
-
물리 프레임의 동적 할당/반환
물리 메모리의 빈 프레임 리스트 생성, 관리 유지
프로세스의 생성/소멸에 따라 동적으로 프레임 할당/반환 -
페이지 테이블 관리 기능 구현
프로세스마다 페이지 테이블 생성, 관리 유지
페이지 테이블이 저장된 물리 주소를 PCB에 저장 -
프로세스 실행 시
페이지 테이블의 물리 메모리 주소를 CPU의 PTBR에 적재
03. 페이지 테이블의 문제점과 TLB
3.1 페이지 테이블의 문제점
- 페이징 기법은 단순하여 구현이 쉬운 장점이 있는 반면,
페이지 테이블로 인한 성능 저하와 공간 낭비의 2가지 문제가 있음
문제1:
페이지 테이블은 MB 단위의 큰 크기로 인해 CPU 칩이 아닌 메모리에 저장
- CPU가 메모리를 액세스할 때마다
페이지 테이블 액세스 1번, 데이터의 물리 메모리 액세스 1번의
총 2번의 물리 메모리 액세스로 인한 프로세스의 실행 속도를 심각하게 저하
문제2: 페이지 테이블의 낭비
- 페이지 테이블의 크기는 프로세스의 최대 크기(주소 공간)에 맞춰서 생성됨
→ 대부분의 페이지 테이블 항목이 비어 있어 메모리 낭비 발생
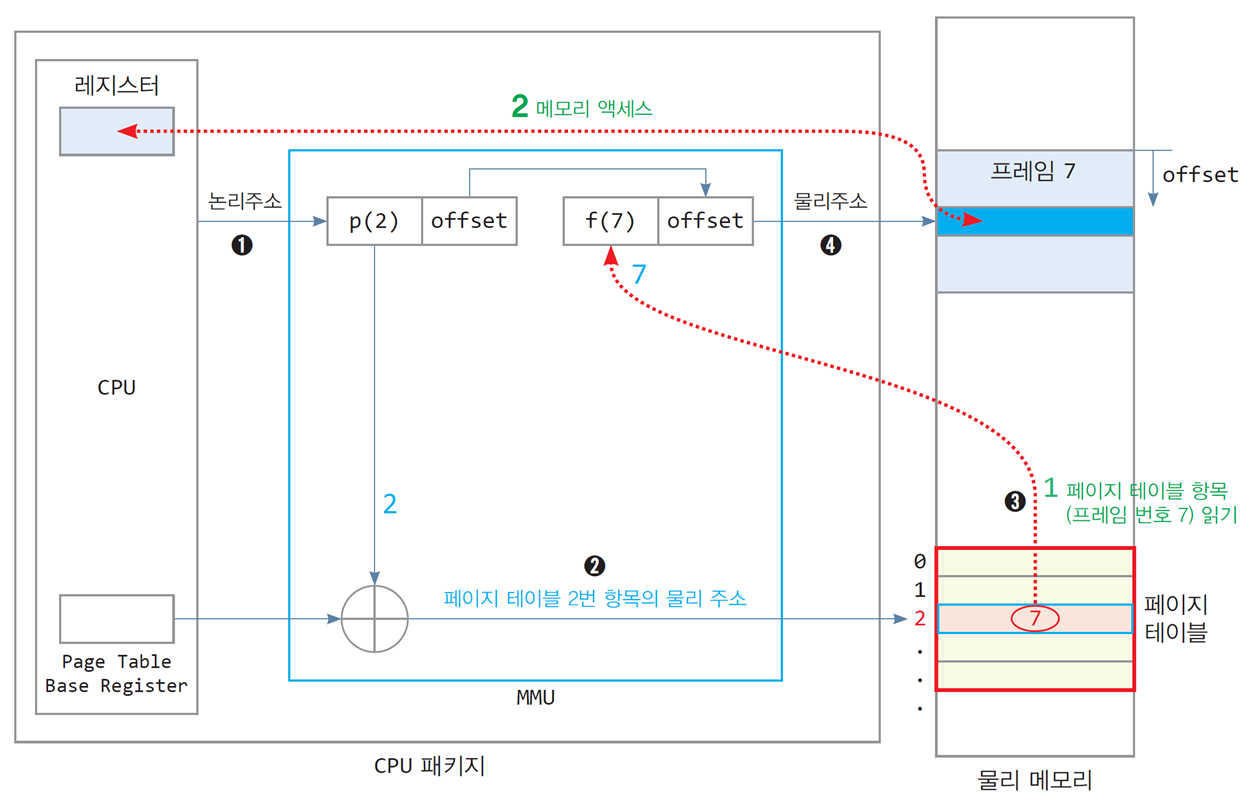
3.2 2번의 물리 메모리 액세스
메모리 액세스 = 페이지 테이블 항목 읽기 1번 + 데이터 액세스 1번
탐구 9-2
C 프로그램이 실행될 때 메모리 액세스 과정 분석
int n[100]; // 400바이트, 전역변수
int sum = 0; // 전역 변수
…
for(int i=0; i<100; i++)
sum += n[i];- 32비트 CPU, 페이지는 4KB
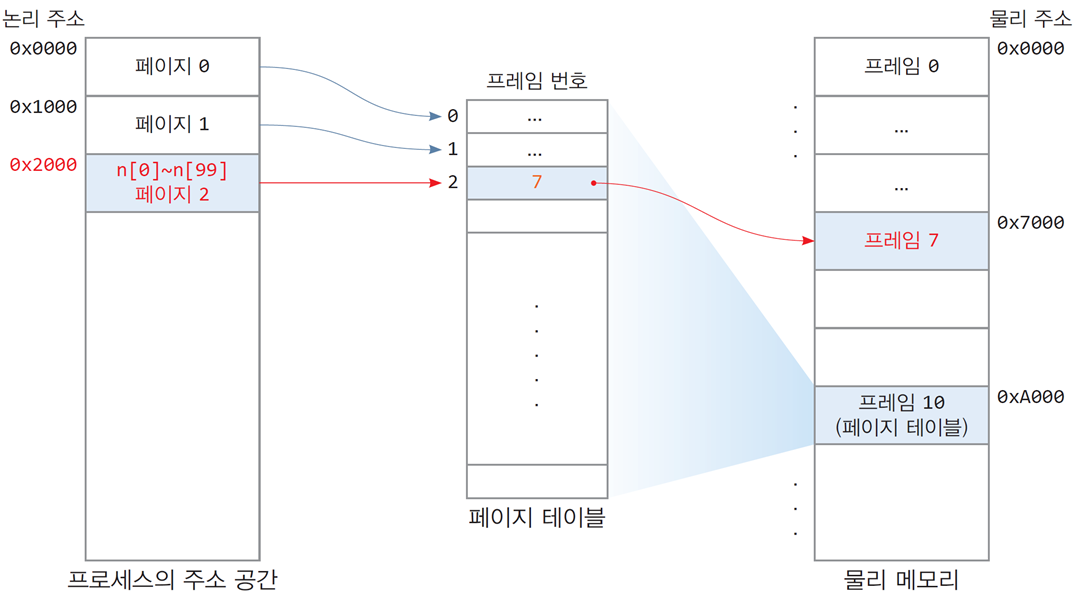
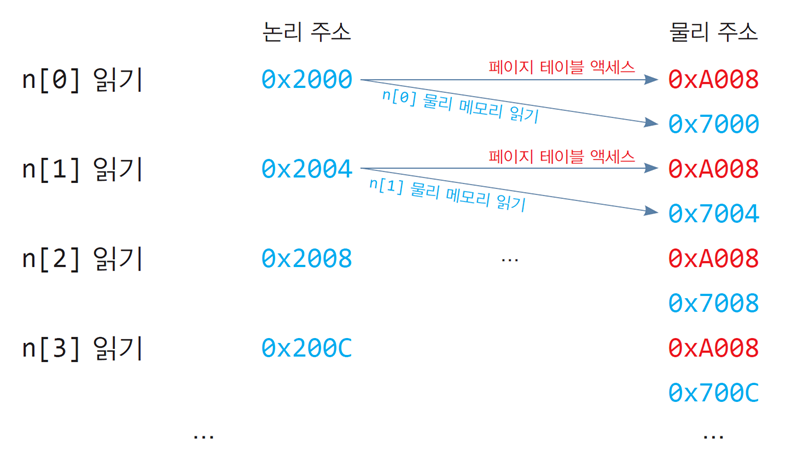
- 배열 n[100]의 논리 주소는 0x2000(페이지 2)부터 시작
- 배열 n[100]의 물리 주소는 0x7000(프레임 7)부터 시작
- 배열 n[100]의 크기는 400바이트이며 페이지2에 모두 들어 있음
- 페이지 테이블은 물리 메모리 0xA000번지부터 시작
-
n[i]를 읽기 위해
2번 물리 메모리(페이지 테이블 항목 + n[i]의 물리메모리)가 액세스됨 -
배열
n이 모두 한 페이지에 들어있으므로
배열 n을 읽는 동안(n[0], n[1], n[2], ..., n[99])를 읽는 동안
모두 페이지 테이블 항목 2를 액세스함
만약 테이블 항목 2를 MMU에 저장해놓는다면?
3.3 TLB를 이용한 2번의 물리 메모리 액세스 문제 해결
- 논리 주소 → 물리 주소 과정에서
페이지 테이블을 읽어 오는 과정을 없앤다면 실행 속도의 획기적인 증가 가능
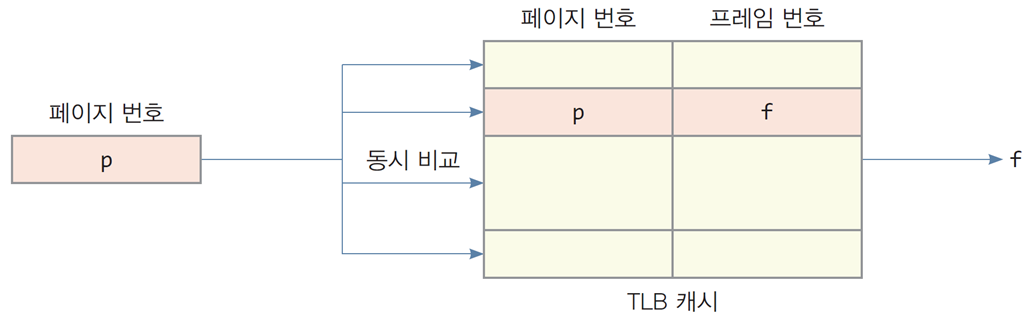
TLB (Translation Look-aside Buffer)
-
주소 변환용 캐시(address traslation cache)로 불림
-
최근에 접근한 페이지 번호와 프레임 번호의 쌍을 항목으로 저장
TLB의 항목 = [페이지번호 p, 프레임 번호 f] -
MMU 내에 존재
-
논리 주소의 페이지 번호와 TLB 내의 각 항목을 순차적으로 비교하지 않고, 모든 항목과 동시에 비교하여 단번에 출력 (고속 검색)
-
번지를 사용하지 않고, 내용을 직접 비교하여 찾는 메모리라고 해서
내용-주소화 기억 장치(content-addressable memory, CAM) 또는
연관 메모리(associative memory) 라고 부름 -
고가이며, 크기가 작음(64~1024개 정도의 항목 저장)
TLB를 활용한 메모리 액세스
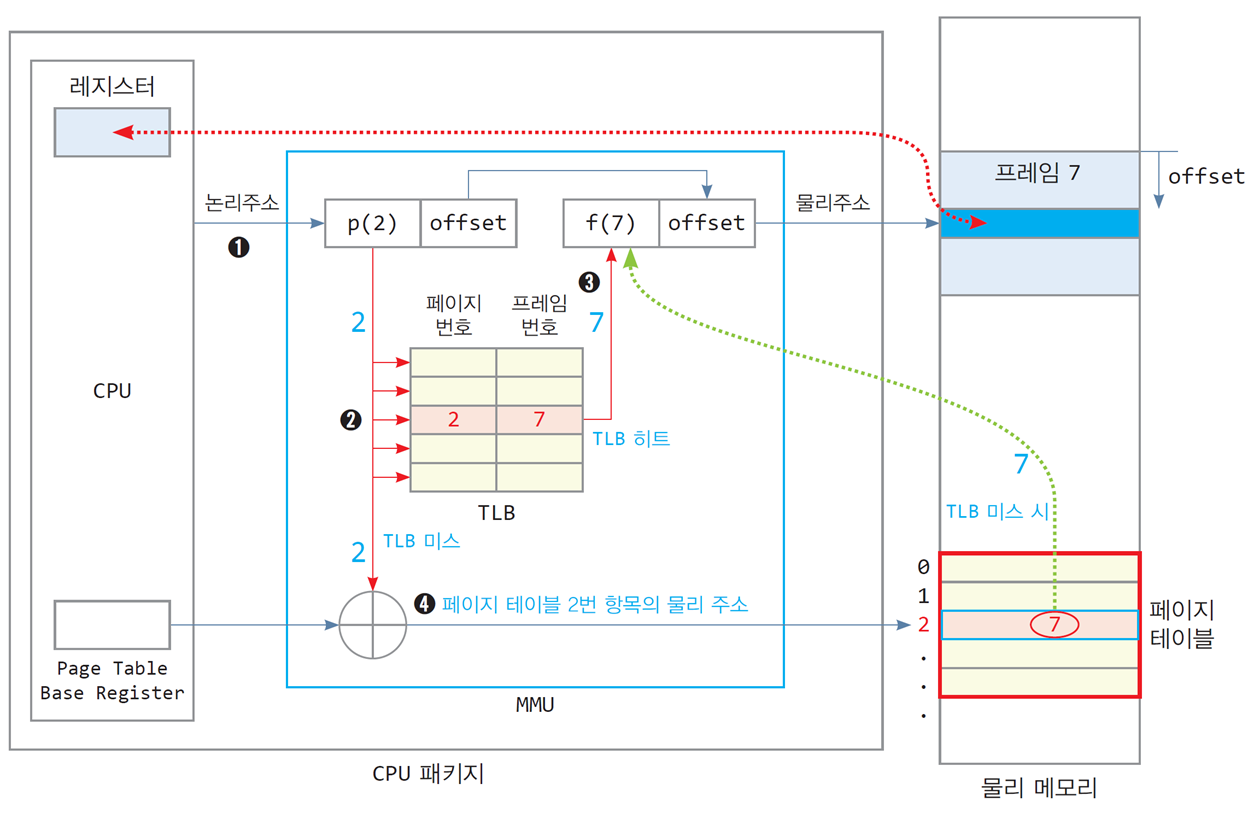
1) CPU로부터 논리 주소 발생
2) 논리 주소의 페이지 번호가 TLB로 전달
3) 페이지 번호와 TLB 내 모든 항목 동시 비교
-
TLB hit: TLB에 페이지 번호가 있는 경우
TLB에서 출력되는 프레임 번호와 offset 값으로 물리 주소 완성 -
TLB miss: TLB에 페이지 번호가 없는 경우
TLB는 miss 신호 발생
MMU는 페이지 테이블로부터 프레임 번호를 읽어와서 물리 주소 완성
미스한 페이지의[ 페이지번호(p), 프레임번호(f) ]항목을 TLB에 삽입
TLB hit 발생 시 1번만 물리 메모리 액세스를 하기 때문에,
CPU의 메모리 액세스 시간을 반으로 줄임
탐구 9-3
TLB가 있는 경우 C 프로그램의 실행 과정 분석
int n[100]; // 400 바이트, 전역변수
int sum = 0; // 전역 변수
…
for(int i=0; i<100; i++)
sum += n[i];-
32비트 CPU, 페이지는 4KB
-
배열 n[100]의 논리 주소는 0x2000(페이지 2)부터 시작
-
배열 n[100]의 물리 주소가 0x7000(프레임 7)부터 시작
-
배열 n[100]의 크기는 400바이트이며 페이지 2에 모두 들어 있음
-
페이지 테이블이 메모리의 0xA000번지에서 시작
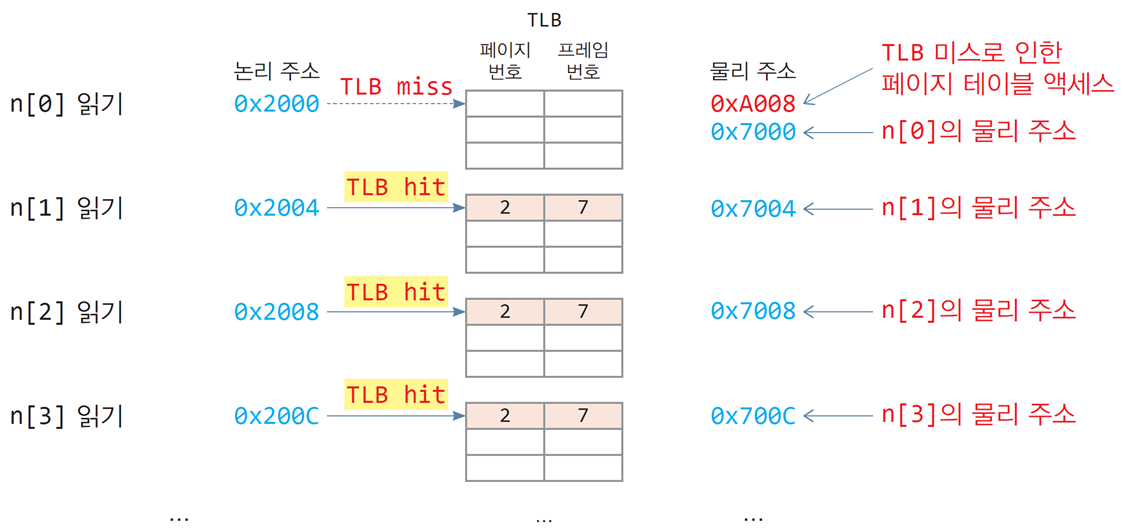
-
처음에 TLB 미스가 발생하는 한 번의 경우에만 물리 메모리를 2번 액세스한다
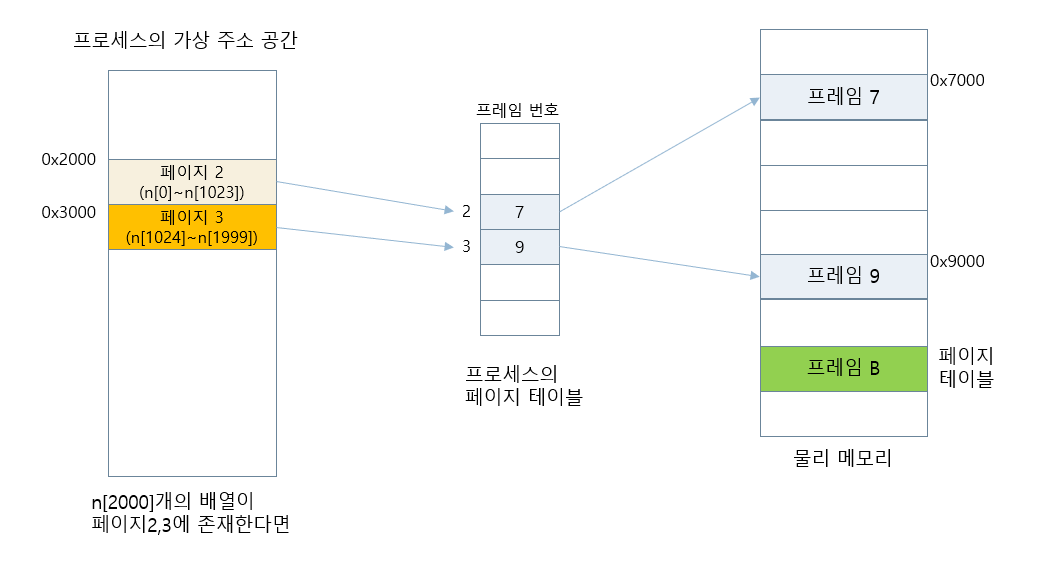
탐구 9-4
배열이 2개의 페이지에 걸쳐 있는 경우 TLB 활용 사례
int n[2000]; // 8000 바이트, 전역변수
int sum = 0; // 전역 변수
…
for(int i=0; i<2000; i++)
sum += n[i];-
배열 n[2000]의 논리 주소는 0x2000부터 시작하여
페이지 2, 3에 걸쳐 존재 (4 (int 바이트 수) x 2000 = 8000 바이트) -
배열 n[2000]의 물리 주소는 0x7000부터 시작하여
프레임 7과 9에 나누어 할당 -
페이지 테이블이 메모리 0xA000번지에서 시작
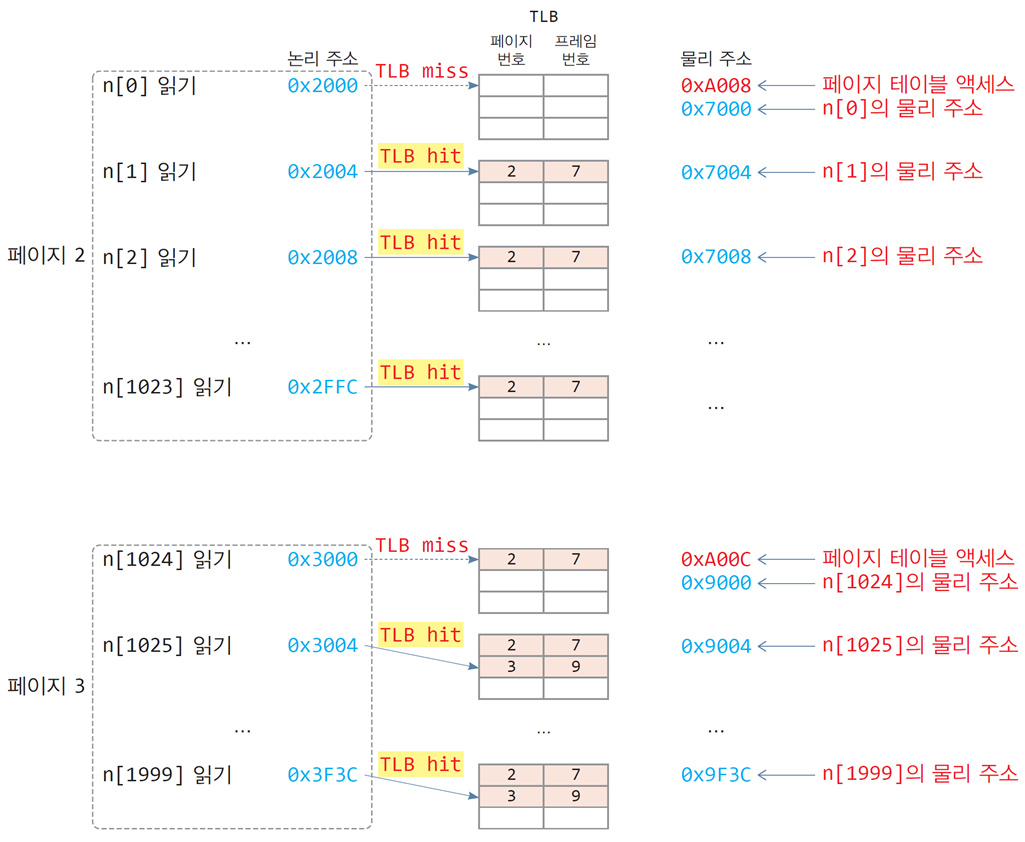
int의 크기는 4바이트
4바이트 크기의 int를 1024개의 주소로 표현하려면
페이지 크기 = 4KB
TLB와 참조의 지역성
-
TLB는 참조의 지역성(locality of reference)으로 인해 효과적인 전략임
참조의 지역성: 일정 구간의 메모리 영역을 반복 액세스 하는 프로그램의 특징
방금 전 사용한 데이터나, 그 데이터 근처에 있는 데이터 두 가지를 의미 -
TLB는 순차 메모리 액세스 패턴을 가진 프로그램에 매우 효과적
-
프로그램이 랜덤하게 메모리를 액세스할 경우,
참조의 지역성이 잘 형성되지 않기 때문에 TLB 미스가 자주 발생
TLB 사용으로 얻는 실행 속도 향상은 크지 않음
TLB 성능과 TLB 도달 범위(TLB reach/TLB coverage)
-
TLB 성능 = TLB 히트율(TLB hit ratio)
메모리 액세스 횟수에 대한 TLB의 히트 횟수 비율 -
페이지가 클수록 TLB 히트율이 증가하지만,
내부 단편화가 증가하여 메모리 낭비
TLB 히트율과 내부 단편화의 Trade-off
디스크 입출력의 성능 향상을 위해 페이지의 크기가 커지는 추세임 -
TLB 도달 범위(TLB reach)
TLB의 모든 항목이 채워졌을 때 TLB 미스 없이 작동하는 메모리 액세스의 범위
TLB 항목 수 x 페이지 크기
TLB를 고려한 컨텍스트 스위칭 재정립
동일한 프로세스의 다른 스레드가 실행될 때
- TLB 항목의 교체가 필요 없음
동일한 프로세스의 주소 공간 내에서 실행되기 때문
다른 프로세스의 스레드로 컨텍스트 스위칭되는 경우
- TLB 항목의 교체가 필요함
1) CPU의 모든 레지스터를 TCB에 저장
2) 새 프로세스의 PCB에 저장된 페이지 테이블 주소를
CPU의 PTBR(Page Table Base Register)에 적재
3) TLB의 모든 항목 지우기
이전 프로세스의 매핑 정보 없애기
TLB 캐시를 비운 채 실행 시 지속적으로 TLB 미스가 발생
4) 새로 스케줄된 스레드의 TCB에서 레지스터 값을 CPU에 적재
04. 심화 학습: 페이지 테이블의 낭비 문제 해결
4.1 페이지 테이블의 메모리 낭비
페이지 테이블로 인해 메모리가 낭비되는 요인 2가지
-
페이지 테이블의 일부 항목만 사용
-
프로세스마다 페이지 테이블 존재
32비트 주소 체계, 한 페이지의 크기가 4KB인 운영체제에서
-
프로세스의 주소 공간
프로세스의 최대 페이지 개수 = 4GB/4KB = 1M = 약 100만개의 페이지 -
프로세스당 페이지 테이블의 크기
한 항목이 4바이트라고 하면 1M x 4 = 4M
프로세스를 생성할 때, 4MB의 페이지 테이블을 물리 메모리에 할당
한 프로세스가 10MB를 사용한다고 할 때
-
실제 활용되는 페이지 테이블 항목 수
10MB/4KB = 2560 -
페이지 테이블 항목 사용률
10 x 2⁸/2²⁰ = 10/2¹² = 0.0024
페이지 테이블로 인한 메모리 낭비의 해결책
- 역 페이지 테이블 (IPT, inverted page table)
- 멀티레벨 페이지 테이블 (multi-level page table)
4.2 역 페이지 테이블
역 페이지 테이블의 구성
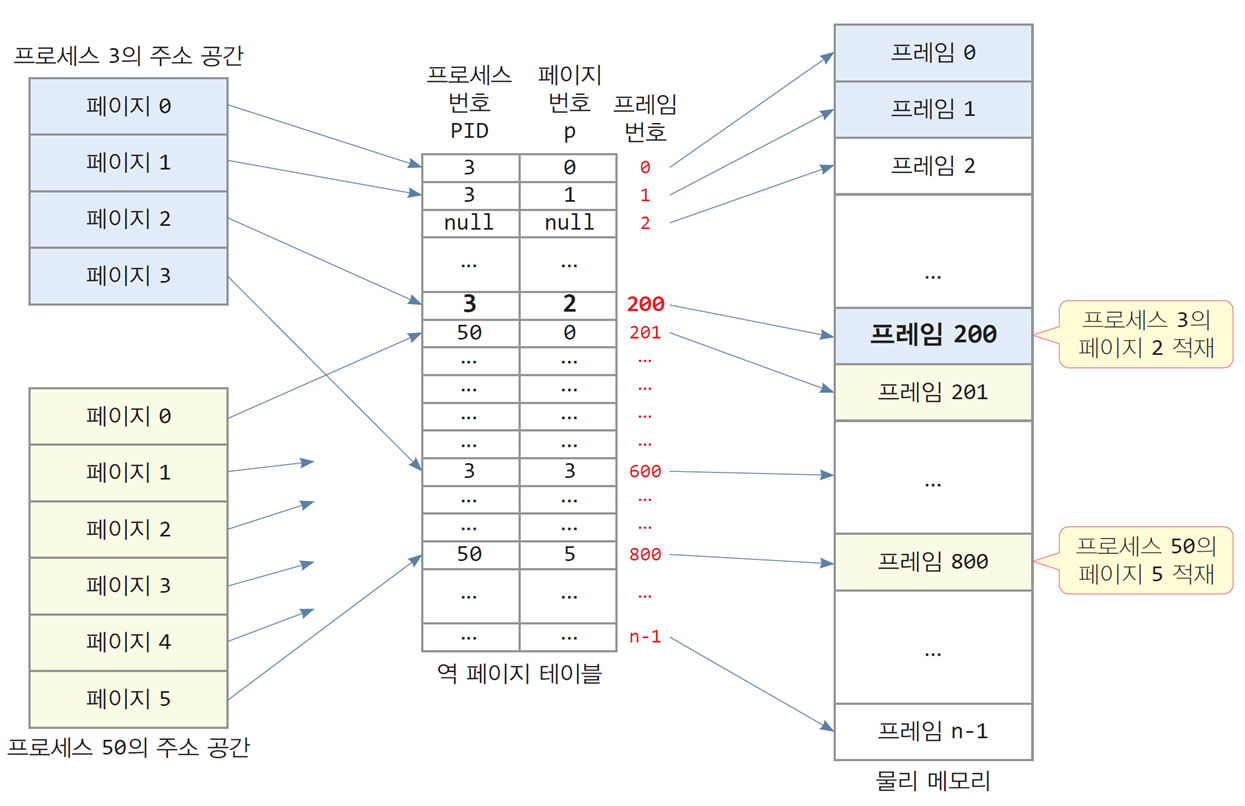
-
물리 메모리 전체 프레임에 대해
각 프레임이 어떤 프로세스의 어떤 페이지에 할당되었는지를 나타내는 테이블 -
시스템에 1개의 역 페이지 테이블을 둠
역 페이지 테이블의 항목 수 = 물리 메모리의 프레임 수 -
역 페이지 테이블 항목
[프로세스번호(pid), 페이지 번호(p)] -
역 페이지 테이블의 인덱스
프레임 번호
논리 주소의 물리 주소로의 변환
-
역 페이지 테이블의 논리 주소 형식
논리 주소 = [프로세스번호, 페이지 번호, 옵셋]
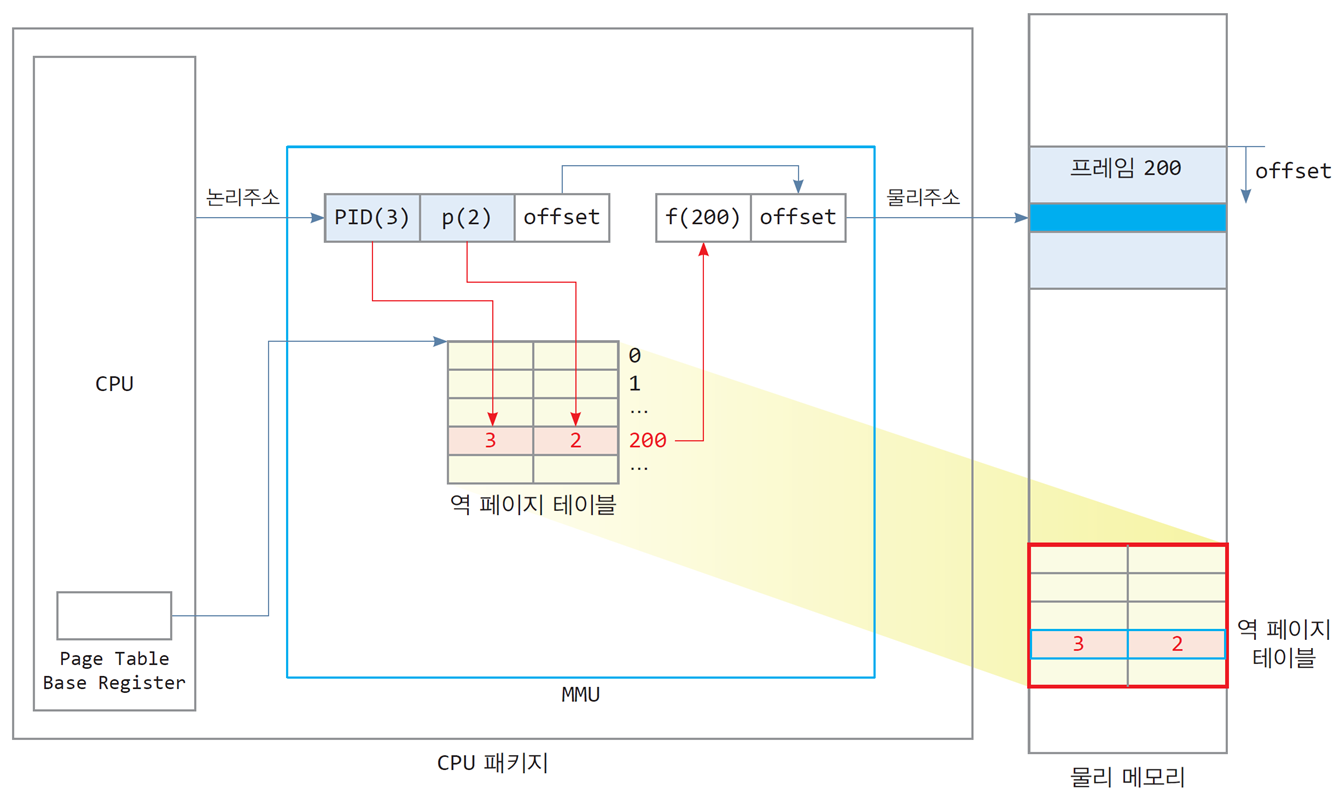
-
역 페이지 테이블을 이용한 주소 변환
1) 논리 주소에서 프로세스 번호, 페이지 번호로 역 페이지 테이블 검색
2) 일치하는 항목을 발견하면 항목 번호가 바로 프레임 번호
3) 프레임 번호와 옵셋을 연결하면 물리 주소 -
역 페이지 테이블은 물리 메모리에 저장해두며,
그 위치는 CPU 내에 있는 PTBR이 가리킴
역 페이지 테이블의 크기
-
역 페이지 테이블은 시스템에 1개만 존재
-
역 페이지 테이블의 크기는 컴퓨터에 설치된 물리 메모리의 크기에 따라 다름
물리 메모리: 4GB, 프레임 크기: 4KB,
한 항목(프로세스(4Byte) + 페이지 번호(4Byte)): 8Byte
4GB/4KB x 8Byte = 8MB -
기존 페이지 테이블은 프레임과 1:1로 매핑되므로
(주소 공간의 크기에 따라 페이지 테이블 크기가 결정됨)
각 프로세스마다 모든 주소 공간을 포함한 페이지 테이블을 가지고 있어야 함
실행 중인 프로세스의 개수가 많을수록 더 효과적
역 페이지 테이블 구현
-
선형 역 페이지 테이블(linear inverted page table)
주소 변환 시 역 페이지 테이블 항목을 처음부터 하나씩 비교
시간이 오래 걸림 -
해시 역 페이지 테이블(hashed inverted page table)
PID와p를 키로 해싱하여 단번에 일치하는 항목 탐색
PowerPC, UltraSPARC 등의 몇몇 CPU에서 사용됨
4.3 멀티레벨 페이지 테이블
-
멀티레벨(다단계) 페이지 테이블은 오늘날 대부분의 운영체제에서 사용
-
프로세스에게 할당된 페이지들에 대해서만 페이지 테이블을 만드는 방식
-
32비트 운영체제에서는 2-레벨과 3-레벨이 사용되며,
64비트 운영체제에서는 4-레벨 또는 5레벨까지 사용되고 있음
2-레벨 페이지 테이블 개요
- 프로세스의 주소 공간을 1024개의 페이지들로 나누고,
1024개의 페이지를 1개의 페이지 테이블로 나타냄
페이지 테이블의 항목은 1024개
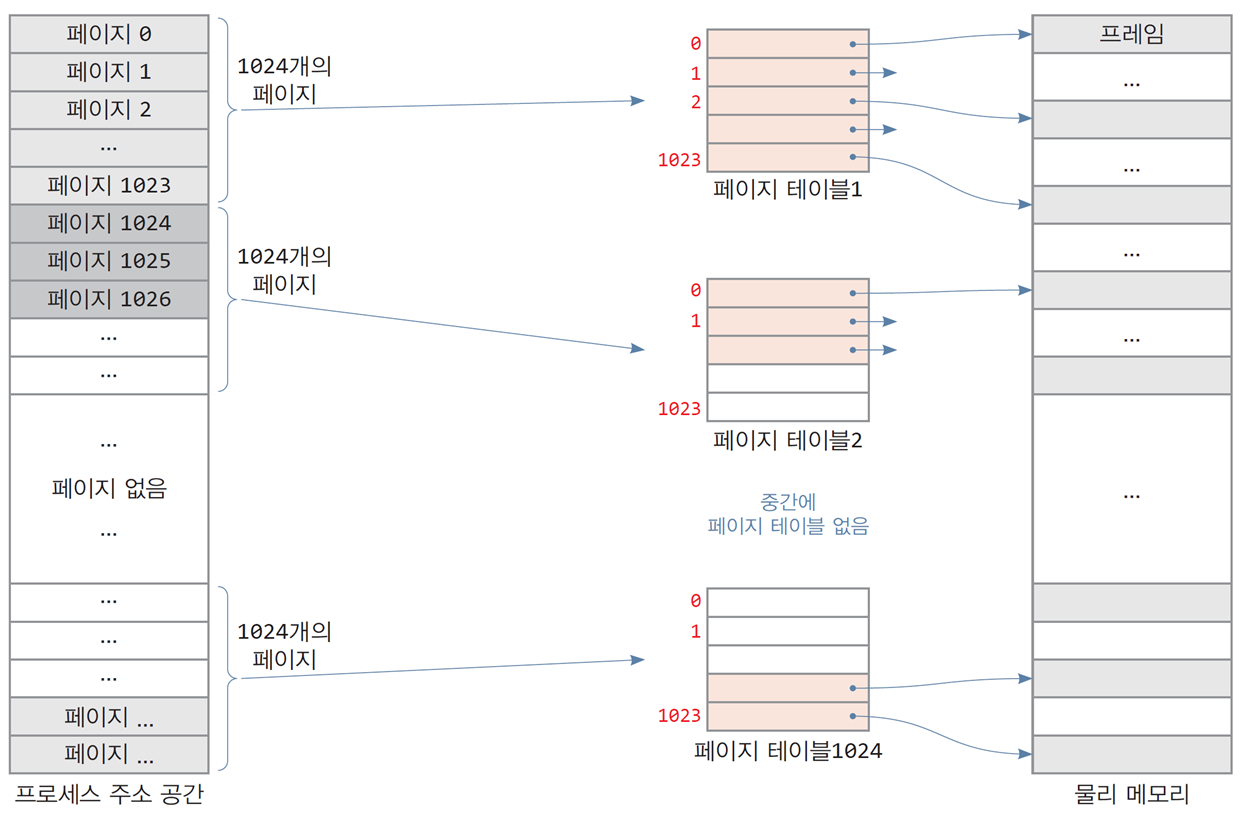
- 페이지 디렉터리(page directory)
각 페이지 테이블이 저장된 메모리 프레임의 번호를 기억하는 테이블
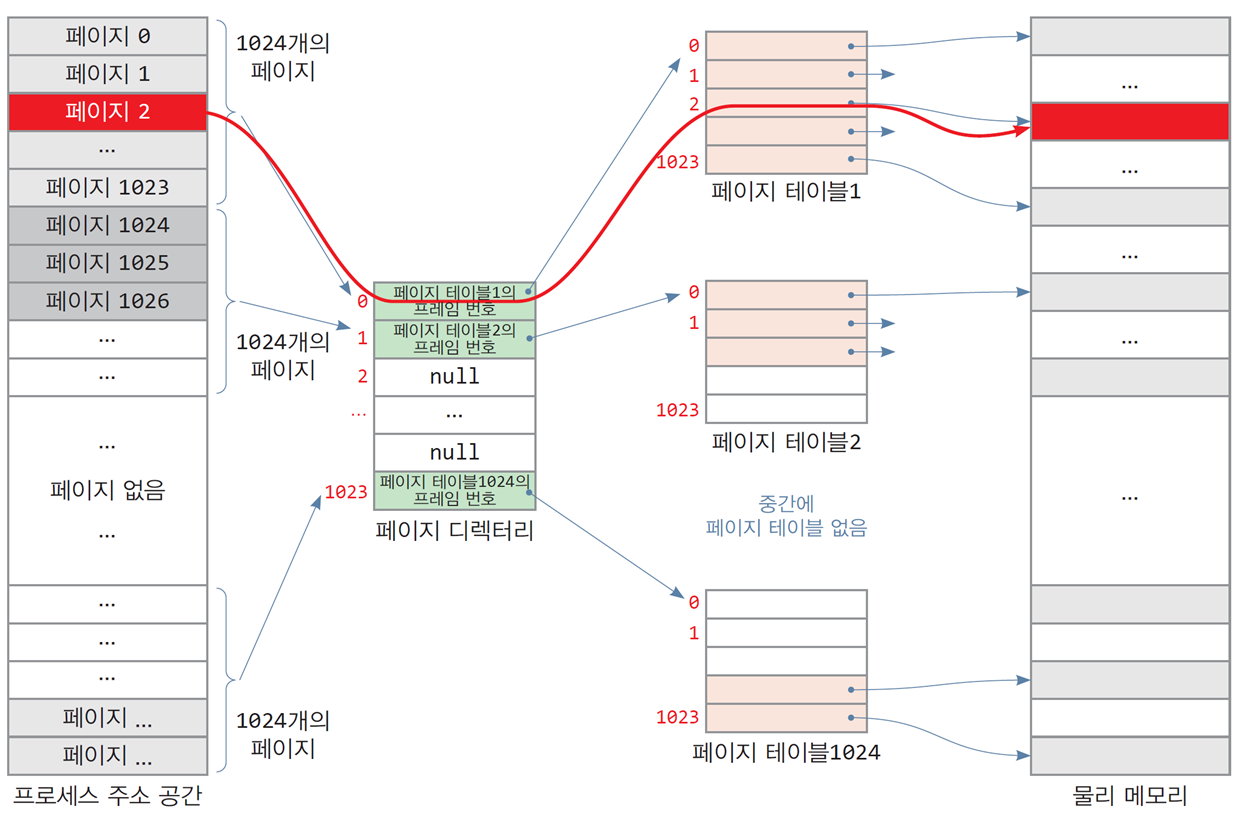
2-레벨 페이지 테이블의 구성
논리 주소 = [ 페이지 디렉터리 인덱스, 페이지 테이블 인덱스, 옵셋 ]
"어던 페이지 테이블"에서 "어떤 페이지" 내에 "어떤 옵셋"에 저장된 데이터
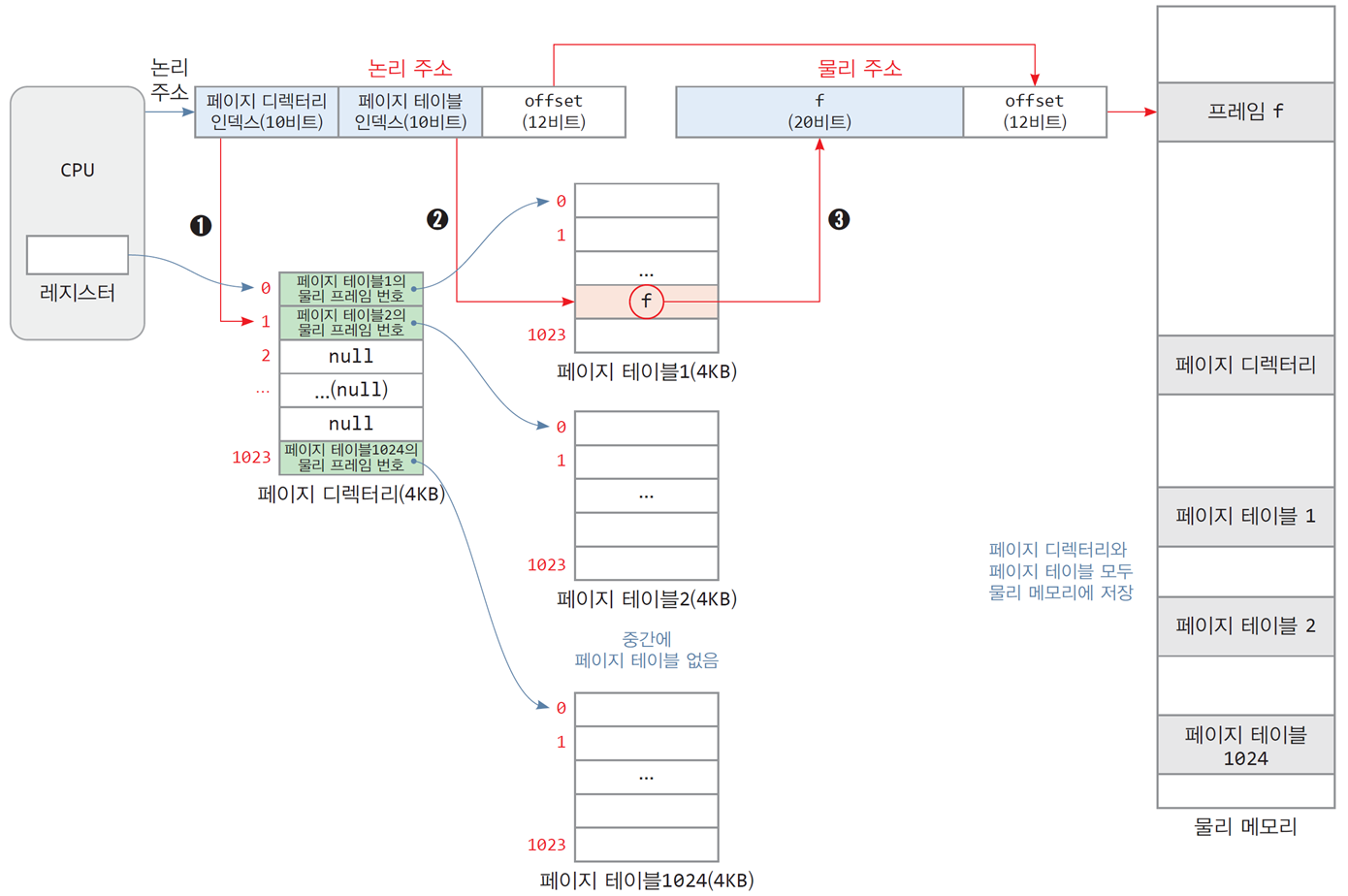
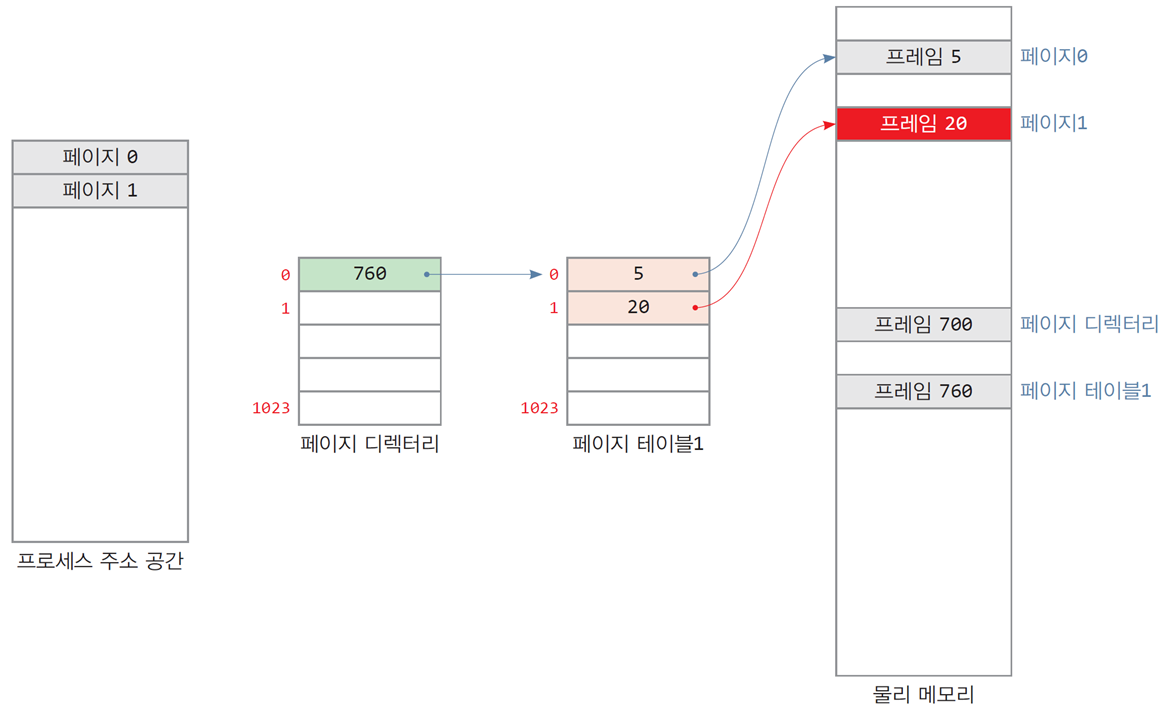
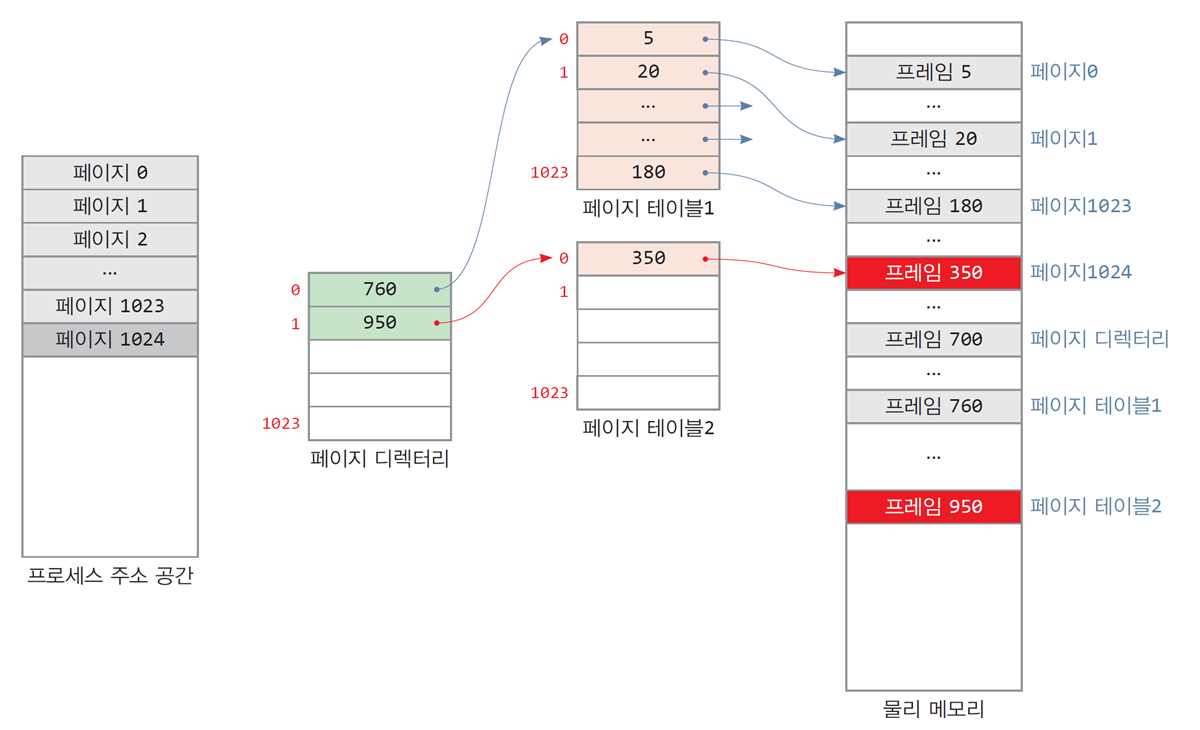
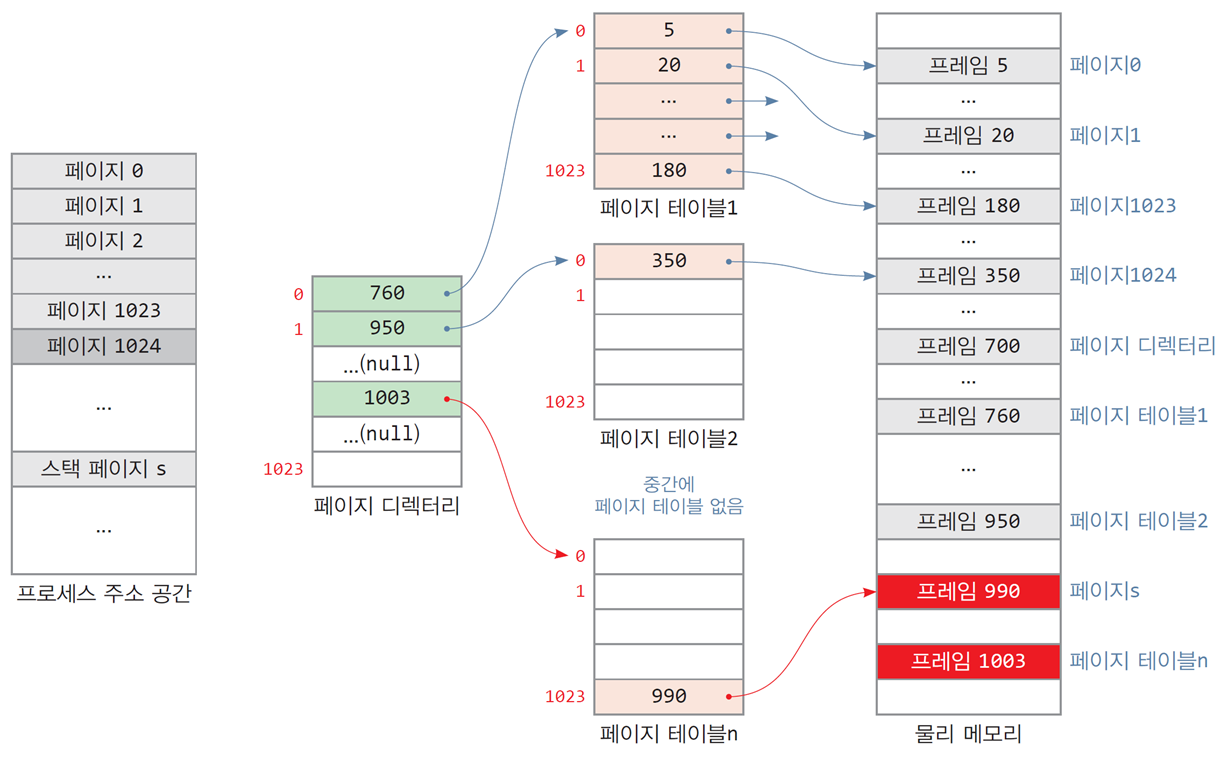
2-레벨 페이지 테이블이 형성되는 과정
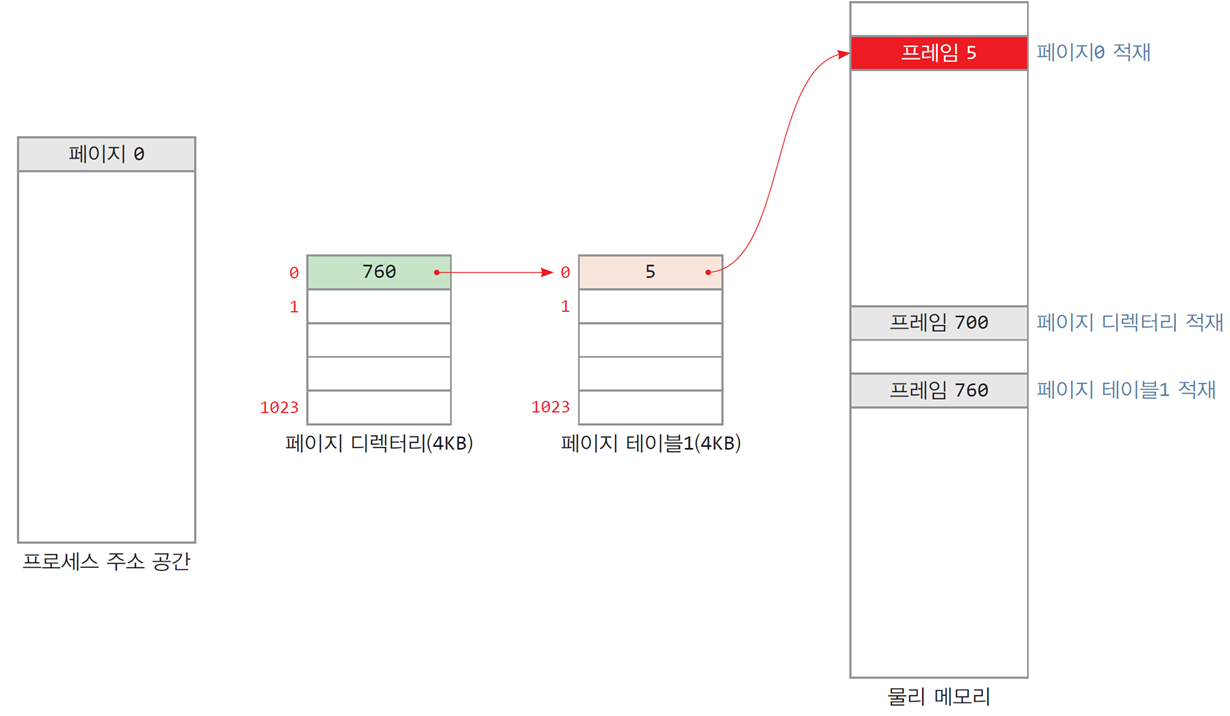
- 페이지 디렉터리에 페이지 테이블의 물리 주소인 프레임 760의 주소가 저장됨
2-레벨 페이지 테이블의 크기
-
2-레벨 페이지 테이블의 최대 메모리 소모량
4KB(페이지 디렉터리) + (1024 x 4KB)(페이지 테이블) = 4MB + 4KB -
프로세스가 1000개의 페이지로 구성되는 경우
1000개 페이지는 1개의 페이지 테이블에 의해 매핑 가능
4KB(페이지 디렉터리) + 4KB(페이지 테이블) = 8KB -
프로세스의 크기가 400MB인 경우
필요한 페이지의 개수 = 400MB / 4KB(한 페이지의 크기) = 100 x 1024
한 페이지 테이블이 1024개의 페이지를 관리하므로
100개의 페이지 테이블 필요
메모리 소모량 = 4KB(페이지 디렉터리) + 100 x 4KB = 404KB -
기존 페이지 테이블의 경우, 프로세스 크기에 관계없이 프로세스당 4MB
