강의 목표
- 응용프로그램과 저장 장치 사이의 파일 입출력 과정을 안다.
- 디렉터리와 파일의 계층 구조에 대해 이해한다.
- 파일 메타 정보와 파일 시스템 메타 정보에 대해 이해한다.
- FAT 파일 시스템의 저장 구조에 대해 이해한다.
- Unix 파일 시스템의 저장 구조에 대해 이해한다.
- 파일 입출력 연산이 이루어지는 과정을 이해한다.
파일 찾기, 파일 열기, 파일 읽기, 파일 쓰기, 파일 닫기
01 파일 시스템과 저장 장치
1.1 파일과 저장 장치
파일(file)
-
사용자나 응용프로그램에게 정보를 저장하고 관리하는 논리적 단위
-
내용과 형식은 파일을 만드는 사용자나 응응프로그램에 의해 결정
컴퓨터 시스템은 0/1로 다룸 -
파일이 생성되고 기록되고 읽혀지는 모든 과정은 운영체제에 의해서만 통제됨
저장 장치를 통제하는 것은 운영체제 본연의 기능이기 때문이며,
저장 장치에 관한 정보(빈 공간, 파일 저장 위치)는 운영체제에 의해서 통제됨
비휘발성 영구 저장 장치(non-volatile)
-
전원이 꺼져도 정보가 지워지지 않는 저장 장치
-
예)
하드 디스크(HDD, Hard Disk Drive)
USB 플래시 드라이버(USB Flash Drive)
SSD(Solid-State Drive)
테이프 저장 장치 -
램 디스크(RAM Disk)와 같이 메모리의 일부분을 저장 장치로 활용하기도 함
이는 전원이 꺼지면 파일이 모두 사라지므로 영구 저장 장치는 아님
1.2 디스크 장치 개요
- 운영체제의 파일 시스템은 저장 장치의 종류나 구조에 무관하게 설계됨
하드 디스크
-
자성체(magnetic material)로 코팅된 여러 개의 원판(플래터, platter)에
디지털 정보를 저장하고 읽어 내는 장치 -
디스크 장치는 디스크 매체 모듈과 디스크 제어 모듈로 구성됨
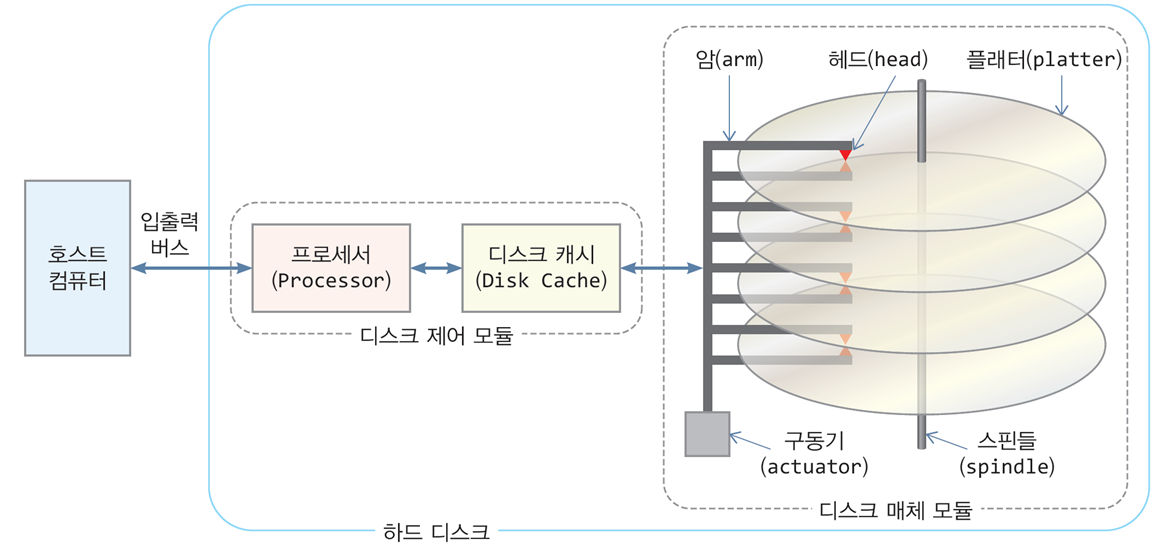
디스크 매체 모듈
플래터(platter)
-
정보가 기록되는 저장소로 스핀들(spindle)에 연결되어 함께 회전
-
디스크 헤드(disk head)는 플래터에서 정보를 읽거나 기록
아래 윗면 모두 정복 저장됨
플래터 당 2개의 디스크 헤드가 존재 -
모든 암(arm)들은 하나의 구동기(actuator)에 달려 있어 안팎으로 움직임
디스크 제어 모듈
-
프로세서(processor)가 위치하는 곳으로, 운영체제로부터 명령을 받고 해석 후
디스크 매체 모듈을 제어하여 물리적인 디스크 액세스 진행 -
입출력 데이터를 임시 저장하는 디스크 캐시를 두고 있음
1MB~몇 십 MB 크기의 빠른 반도체 메모리 -
운영체제가 전달한 데이터는 디스크 캐시에 가장 먼저 저장되며,
프로세서에 의해 디스크 캐시 → 플래터로 저장됨 -
읽기 요청을 받은 경우,
프로세서는 플래터 → 디스크 캐시로 이동 후 호스트로 전송 -
디스크 캐시는 운영체제나 응용프로그램에게 디스크 입출력 시간 단축
호스트(host)
-
원격 네트워크에서 사용자가 연결하여 사용하는 장치를 터미널(terminal)
-
원격에 있는 컴퓨터를 호스트 또는 호스트 컴퓨터라고 함
디스크장치의 경우 입출력 버스를 통해 메인 컴퓨터와 연결되는데,
메인 컴퓨터를 호스트라고 함
트랙, 섹터, 실린더
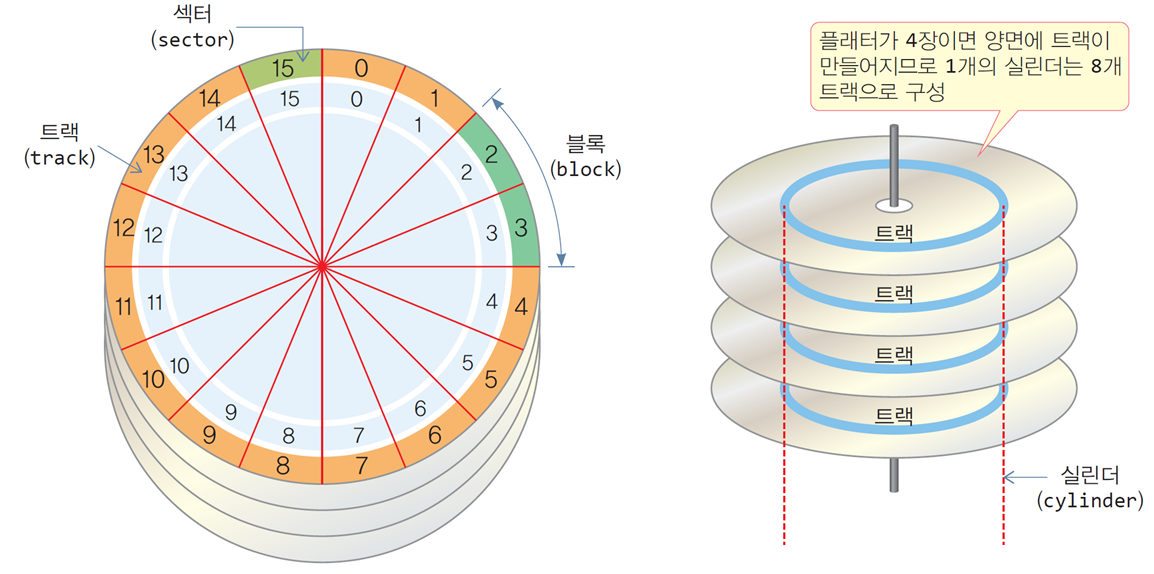
섹터(sector)
- 디스크에서 읽고 쓰는 최소 단위
512바이트 혹은 4096바이트
트랙(track)
- 플래터에 정보가 저장되는 하나의 동심원
여러 개의 섹터로 구성됨
실린더(cylinder)
- 모든 플래터를 통틀어 같은 반지름의 트랙 그룹
4장의 플래터를 가진 디스크는 헤드가 8개이므로,
실린더는 8개의 트랙으로 구성됨
섹터와 블록
섹터(sector)
- 디스크가 입출력하는 물리적인 최소 단위
블록(block)
-
운영체제가 파일 데이터를 다루는 논리적인 단위
-
운영체제는 파일을 블록 단위로 나누어
하드 디스크에 분산 배치하고, 블록 단위로 읽고 씀 -
블록의 크기는 운영체제마다 다르며, 몇 개의 섹터로 구성됨
1.3 파일 입출력 주소
디스크 물리 주소와 논리 블록 주소
- 응용프로그램 - 파일 내 바이트 주소
- 운영체제 - 논리 블록 주소
- 디스크 장치 - 디스크 물리 주소
디스크 물리 주소
- 디스크 장치는 플래터에서 섹터 단위로 읽고 씀
CHS(Cylinder-Head-Sector) 물리 주소 = [실린더 번호, 헤드 번호, 섹터 번호]논리 블록 주소(Logical Block Address)
-
디스크의 모든 블록들을 일차원 배열로 나열하고 번호를 매긴 주소
-
블록 번호는 맨 바깥쪽 실린더 → 안쪽 실린더 순서
맨 위의 트랙 → 아래 트랙으로 이동 -
디스크의 물리적인 구조와 무관함
바이트 번호
- 파일 내 바이트의 위치, 즉 옵셋
파일 주소 변환
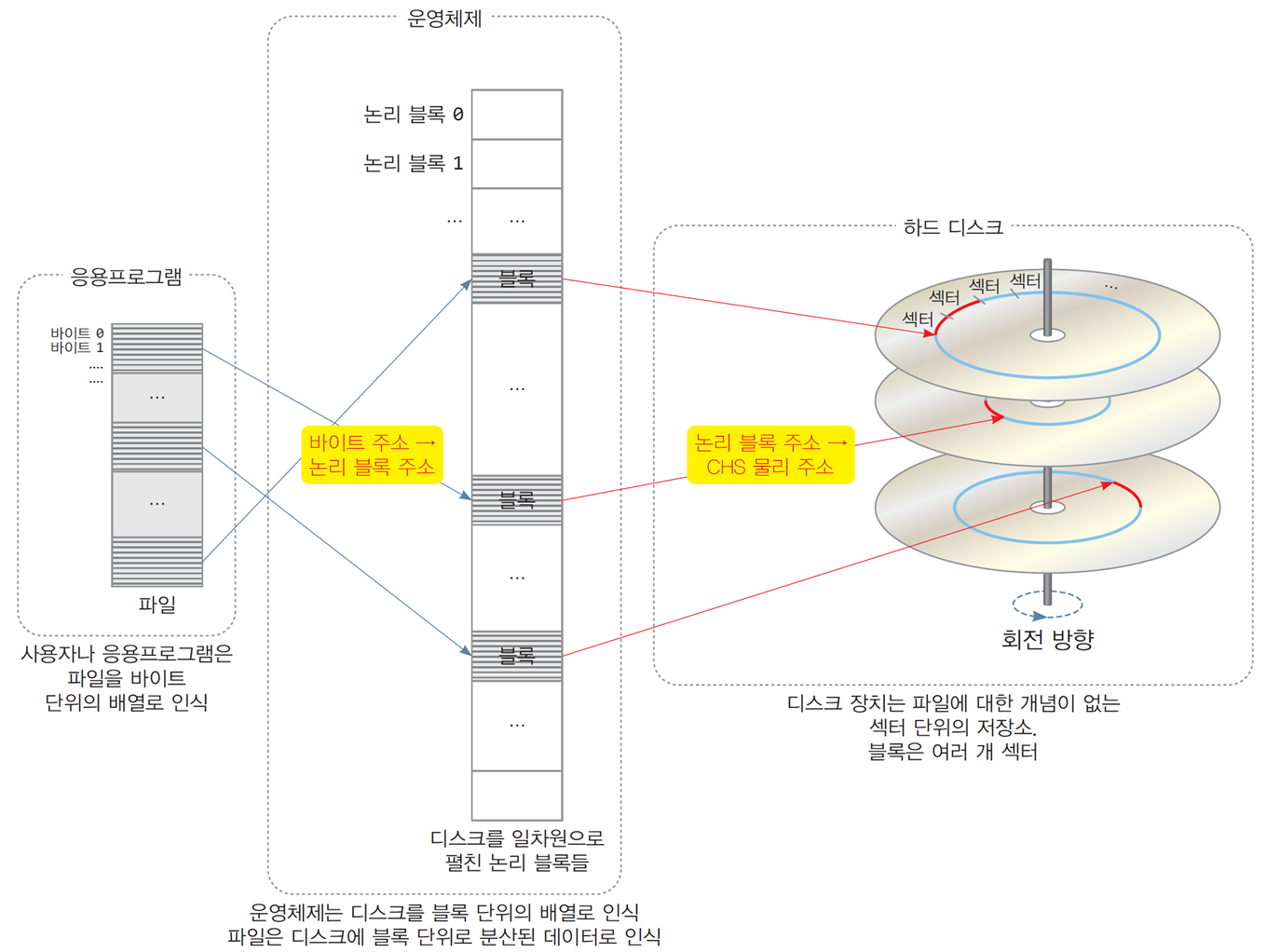
-
사용자나 응용프로그램은 파일 데이터가
바이트 단위로 연속해서 저장된다고 생각함 -
운영체제는 파일을 블록 크기로 분할하고, 각 블록을 디스크에 분산 저장
-
파일 블록 배치 정보(파일의 각 블록이 저장된 디스크 블록 번호)를
별도로 저장 및 관리 -
응용프로그램에서 파일 내 바이트 주소의 변환 과정
파일 내 바이트 주소
→ 논리 블록 주소(운영체제에 의해)
→ CHS 물리 주소(디스크 장치에 의해)주소 계층화 의미
-
응용프로그램, 운영체제, 디스크 장치 사이에서
파일 데이터를 바라보는 시각은 계층화되어있음 -
계층 구조로 인해 사용자나 응용프로그램, 운영체제, 그리고 디스크 장치가
상호 독립적으로 정의된 기능 수행 가능 -
응용프로그램 작성자는 저장 매체의 하드웨어 구조나 특성에 대한 지식 없이
파일 입출력을 가능하게 함 -
운영체제는 저장 장치의 종류나, 실린더 수, 헤드 수, 트랙당 섹터 수 등
저장 장치의 하드웨어와 무관하게 개발될 수 있음
SSD와 같은 실린더나 트랙 등 디스크 포맷을 가지지 않는 저장 매체도
동일한 방식으로 입출력 가능
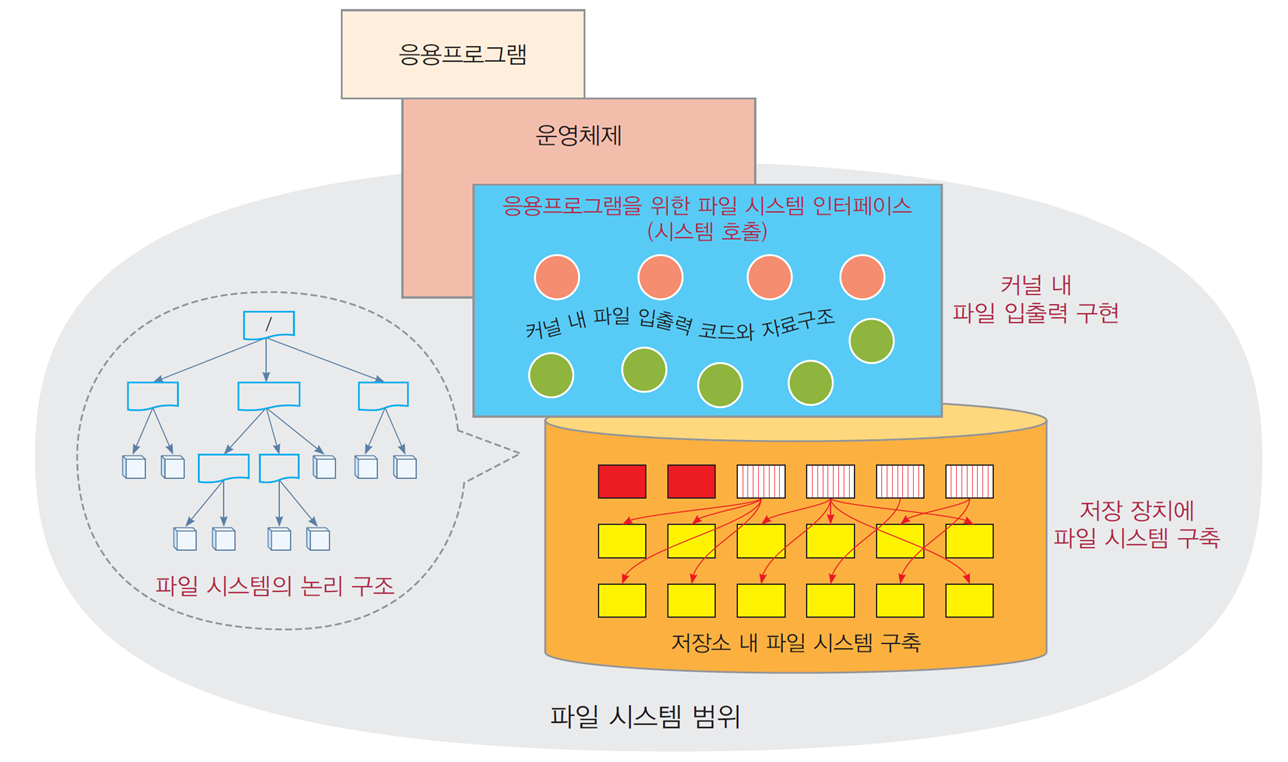
1.4 파일 시스템의 정의와 범위
파일 시스템
- 저장 매체에 파일을 생성·저장·읽기·쓰기의 기능을 가진 운영체제를 통칭
파일 시스템을 구성하는 4가지 요소
- 파일 시스템의 논리 구조
- 저장 장치에 파일 시스템 구축
- 커널 내 파일 입출력 구현
- 응용프로그램을 위한 파일 시스템 인터페이스
파일 시스템의 논리 구조
- 운영체제는 여러 파일을 다루기 위해,
디렉터리와 파일들로 이루어지는 트리 계층 구조로 파일 시스템을 구성
저장 장치에 파일 시스템 구축
- 파일들을 저장 매체 속에 블록 단위로 분산 저장·관리하기 위한 체계
저장 매체 속 사용/미사용 블록에 관한 정보 등의 설계
커널 내 파일 입출력 구현
1) 파일 생성
- 저장 매체의 빈 공간에 물리적으로 파일 이름과 속성 등을 기록
2) 파일 열기
- 파일을 읽고 쓰기 전, 파일의 존재, 접근 권한 등을 확인하는 작업과 함께
파일을 읽고 쓰고 공유할 수 있도록 커널 내 구조 형성
3) 파일 읽기
- 파일 블록이 저장된 위치를 알고 파일 데이터 읽기
4) 파일 쓰기
- 저장 매체에 파일 데이터를 기록하는 기능
이미 존재하는 파일 데이터를 갱신하는 경우엔 데이터를 덮어 쓰고,
새로운 파일 데이터를 기록하는 경우 저장 매체의 빈 공간을 할당받아 기록
5) 파일 닫기
- 파일 열기 시에 형성된 커널 내 자료 구조 해제
6) 파일 삭제
- 저장 매체에서 파일이 저장된 영역을 빈 영역 리스트에 반환
7) 파일 메타 정보 읽기/변경
- 파일의 속성 등 메타 정보를 읽거나 변경
응용프로그램을 위한 파일 시스템 인터페이스(시스템 호출)
- 커널 내에 구현된 파일 입출력 기능을 활용할 수 있도록
open(),close(),read(),write,seek()등 다양한 시스템 호출 제공
응용프로그램은 시스템 호출을 통해서만 파일 시스템 사용 가능
1.5 파일 시스템 입출력 계층
- 파일 시스템은 파일이 입출력되는 모든 과정에서 관여
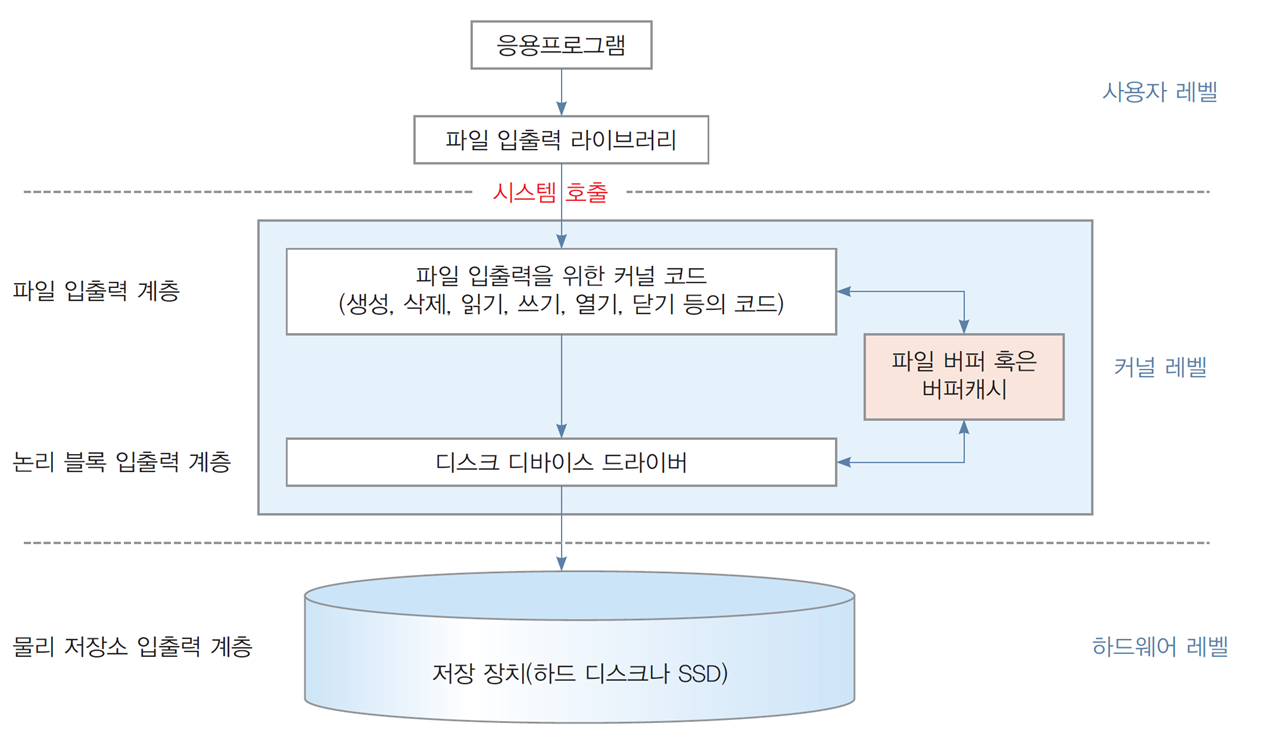
- 응용프로그램은 일반적으로 파일 입출력 라이브러리를 이용하여 작성됨
라이브러리
- 필요에 따라 시스템 호출을 이용하여
운영체제에게 파일 입출력을 요청
파일 입출력 계층
- 요청이 정상인지 검사하고
요청된 파일 데이터의 바이트 주소 → 논리 블록 주소(LBA)로 변환
논리 블록 입출력 계층
-
논리 블록 주소에 해당하는 디스크 블록이
커널 내의 버퍼(버퍼 캐시)에 있는지 확인 -
있으면 버퍼 캐시에서 읽거나 쓰기 작업으로 완료
-
없으면 디스크 장치 드라이버(disk driver)를 통해
디스크 장치로 논리 블록 주소를 보내 입출력 지시
물리 저장소 입출력 계층
-
저장 장치에서 구현되는 계층으로,
논리 블록 주소 → 저장 장치의 물리 주소로 변환하여 데이터를 액세스 -
저장 장치가
하드 디스크 → CHS 물리 주소
SSD → 플래시 메모리 상의 블록 주소
1.6 파일 읽기 사례
- C 표준 라이브러리 함수
fread()를 이용하여 파일에서n바이트 읽기
char buf[SIZE]
FILE* fp = fopen(...);
fread(fp, buf, n);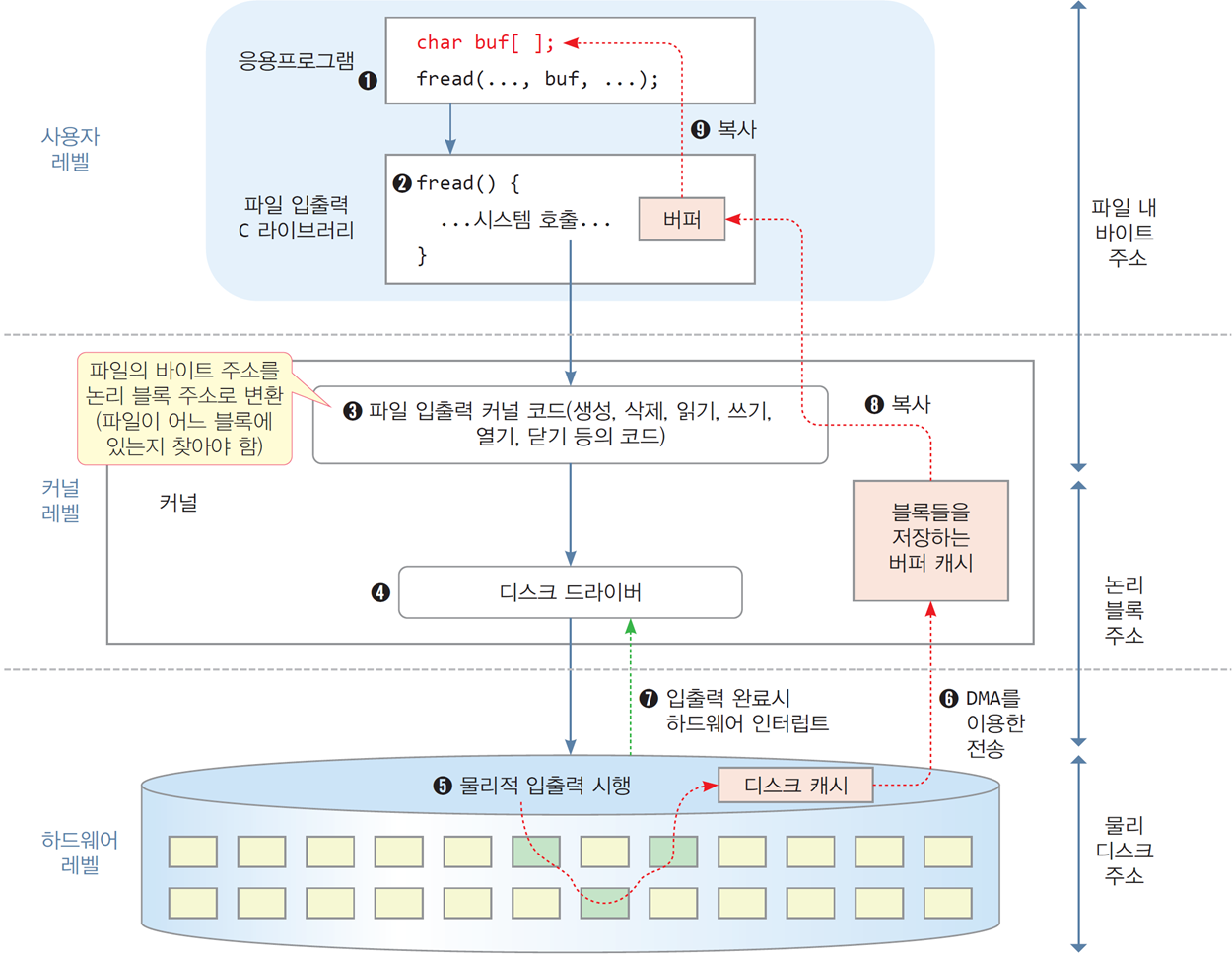
파일 데이터의 복사 경로
디스크 캐시 → 커널의 버퍼 캐시 → C 라이브러리의 버퍼 → 응용프로그램의 buf[]배열
파일 읽기 과정을 통한 주목 사항
1) 파일 읽기의 과정은 계층 구조로 이루어지고 그 역할이 잘 구분됨
2) 운영체제 커널의 역할은 사용자나 응용프로그램이 파일이 저장되는
저장 장치의 종류나 구조, 위치 등 물리적인 특성에 무관하게 입출력 지원
3) 디스크 드라이버에 의해 파일에 대한 논리적 구조와 물리적 저장 공간을 분리
4) 파일 데이터는 여러 번의 복사를 거쳐 이동
- 버퍼들로 인해 많은 시간이 소요되기도 하지만,
동일한 파일 블록 액세스,
여러 스레드에 의해 동일한 파일이 공유되는경우
입출력 성능 향상
02. 파일 시스템의 논리 구조
2.1 파일 시스템 구조
- 오늘날 운영체제는 대부분
트리 계층 구조(tree hierarchical structure)로 파일 시스템을 구성
파일이 몇 십 개 수준이라면 계층 구조 없이 일차원적으로 저장
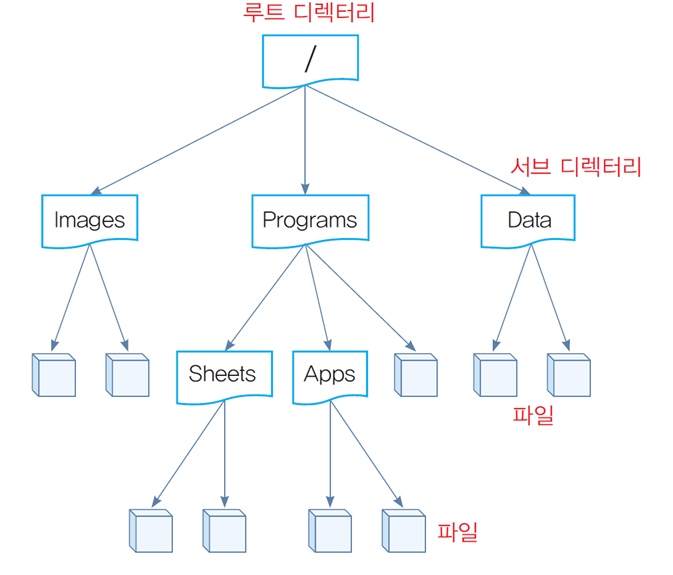
디렉터리와 파일의 계층 구조
디렉터리(directory)
-
파일과 서브 디렉터리를 담기 위한 컨테이너
-
루트 디렉터리(root directory)
파일 시스템 계층 구조의 최상위 디렉터리 -
서브 디렉터리(sub directory)
루트 디렉터리의 하부에 존재하는 디렉터리
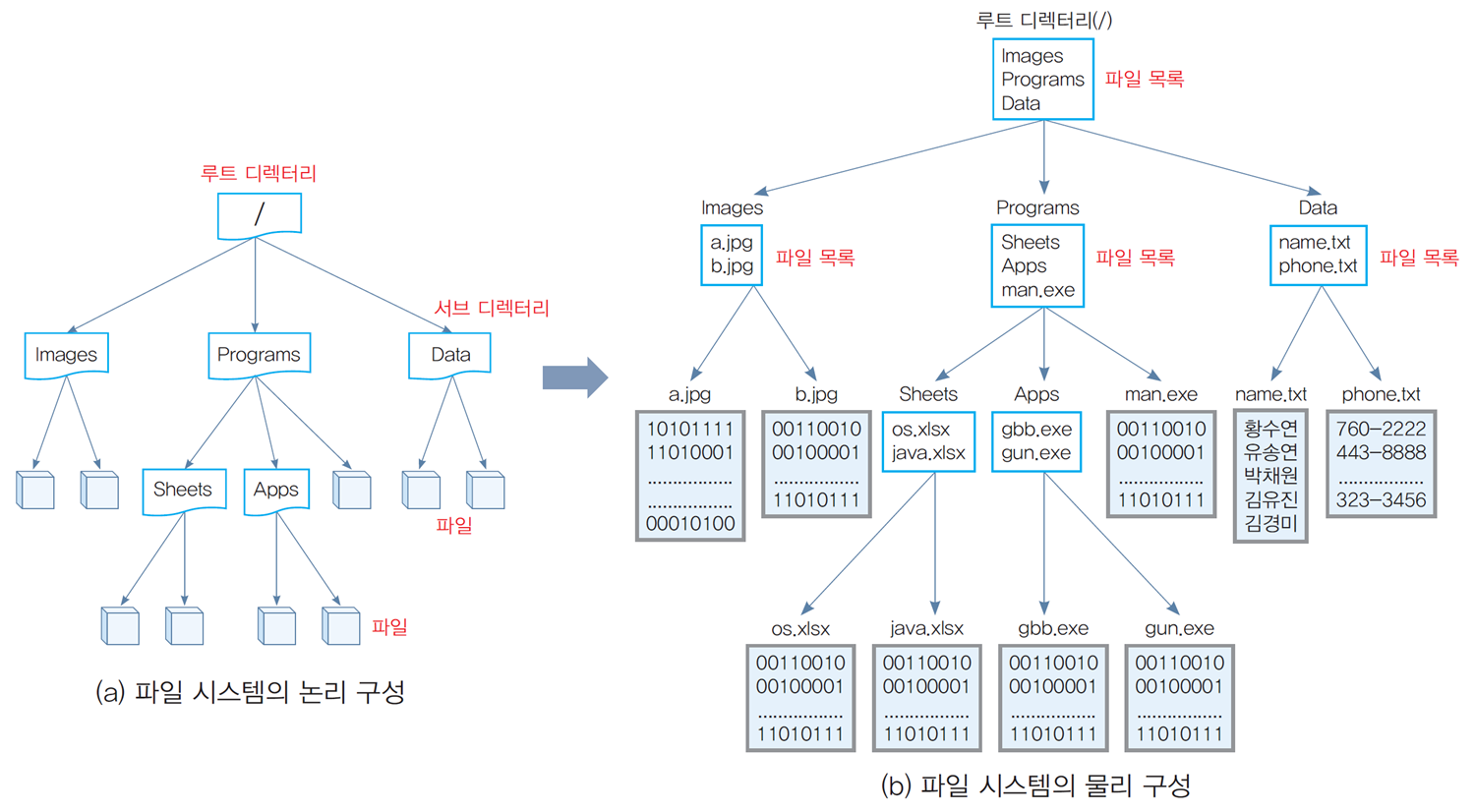
-
대부분의 파일 시스템에서는
파일 블록의 저장 위치는 디렉터리에 두지 않고 다른 곳에 저장함
FAT 파일 시스템의 경우 FAT 테이블에,
유닉스나 리눅스 파일 시스템의 경우 i-node -
디렉터리는 서브 디렉터리나 파일들의 목록을 저장한 파일
디렉터리와 폴더
-
디렉터리는 파일을 담는 물리적인 컨테이너
-
폴더는 파일뿐 아니라 네트워크 환경, 내 컴퓨터, 제어판 등
파일 개념이 아닌 여러 요소들도 담을 수 있는 논리적인 컨테이너 -
디렉터리는 폴더의 일종이지만, 디렉터리와 폴더는 같은 개념으로 사용됨
파일 이름과 경로명
-
파일 이름은
a.jpg,main.cpp등 이름(name)과 확장자(extension)으로 구성
확장자는 없을 수도 있음 -
파일의 경로명(pathname)은 루트 디렉터리에서
계층구조를 포함하는 완전한 파일 이름 -
gun.exe
리눅스:/Programs/Apps/gun.exe
Windows:C:\Programs\Apps\gun.exe
2.2 파일 시스템 메타 정보와 파일 메타 정보
운영체제는 파일 시스템을 다루기 위해 다음 2개의 매타 정보를 만들고 활용함
- 파일 시스템 메타 정보
- 파일 메타 정보
파일 시스템 메타 정보
-
파일 시스템 전체에 대한 정보로, 운영체제나 파일 시스템 종류마다 다름
-
공통적으로는 다음과 같다
파일 시스템 전체 크기
저장 장치에 구축된 파일 시스템의 현재 사용 크기
저장 장치에 구축된 파일 시스템의 비어 있는 크기
저장 장치 상에 비어 있는 블록들의 리스트 -
저장 매체 속 예약된 특별한 위치에 저장하여,
파일이나 디렉터리와 섞이지 않도록 하고
운영체제가 쉽게 읽고 쓸 수 있도록 함
파일 메타 정보
-
파일에 관한 여러 정보로서 파일 데이터(실제 파일 내용)는 포함되지 않음
-
파일마다 메타 정보는 별도로 관리되며 운영체제에 따라 조금씩 다름
-
공통적으로 다음과 같다
파일 이름
파일 크기
파일이 만들어진 시간
파일이 수정된 시간
파일이 가장 최근에 액세스된 시간
파일을 만든 사용자(소유자)
파일 속성(접근 권한)
파일이 저장된 위치(파일 블록 배치 정보)
-
파일에는 파일 데이터만 저장되고 파일 메타 정보는 다른 곳에 저장됨
파일 메타 정보는 어디에 저장되는가?
- 파일 메타 정보는 파일 데이터와 분리하여 따로 저장됨
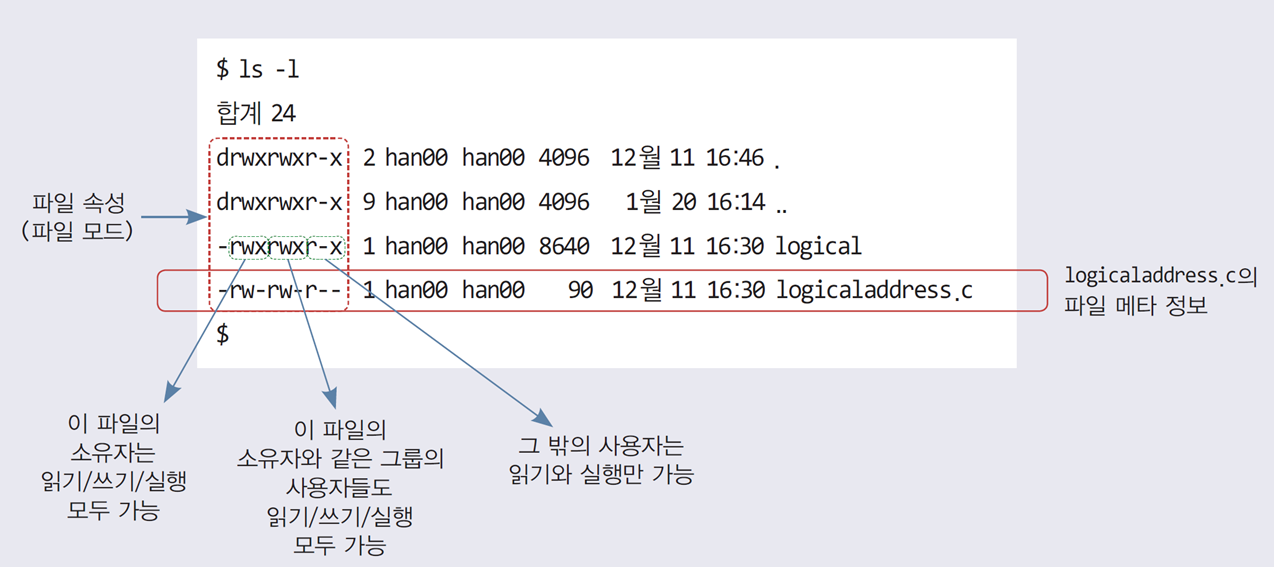
TIP 파일 메타 정보 중 파일 속성(file attributes)
03. 파일 시스템 구축
3.1 파일 시스템 종류와 구현 이슈
파일 시스템 종류
- FAT(File Allocation Table) - MS-DOS
- UFS(Unix File System) - Unix
- ext2, ext3, ext4 - Linux
- HFS(Hierarchical File System) - Mac
- NTFS(New Technology File System) - 윈도우즈 3.1~, FAT를 개선, 리눅스 지원
모두 트리 구조의 계층적 파일 시스템이지만, 저장 장치에서 구성 방식은 다름
파일 시스템 구현 이슈
- 디스크 장치에 비어 있는 블록들의 리스트를 어떻게 관리할 것인가?
- 파일 블록들을 디스크의 어느 영역에 분산 배치할 것인가?
- 파일 블록들이 저장된 디스크 내 위치들을 어떻게 관리할 것인가?
3.2 FAT 파일 시스템
- 1980년대 PC의 개인용 운영체제인 MS-DOS의 파일 시스템으로 개발
- 파일 개수와 크기가 작았던 당시에 적합하도록 설계
- 진화된 모습으로 지금도 사용
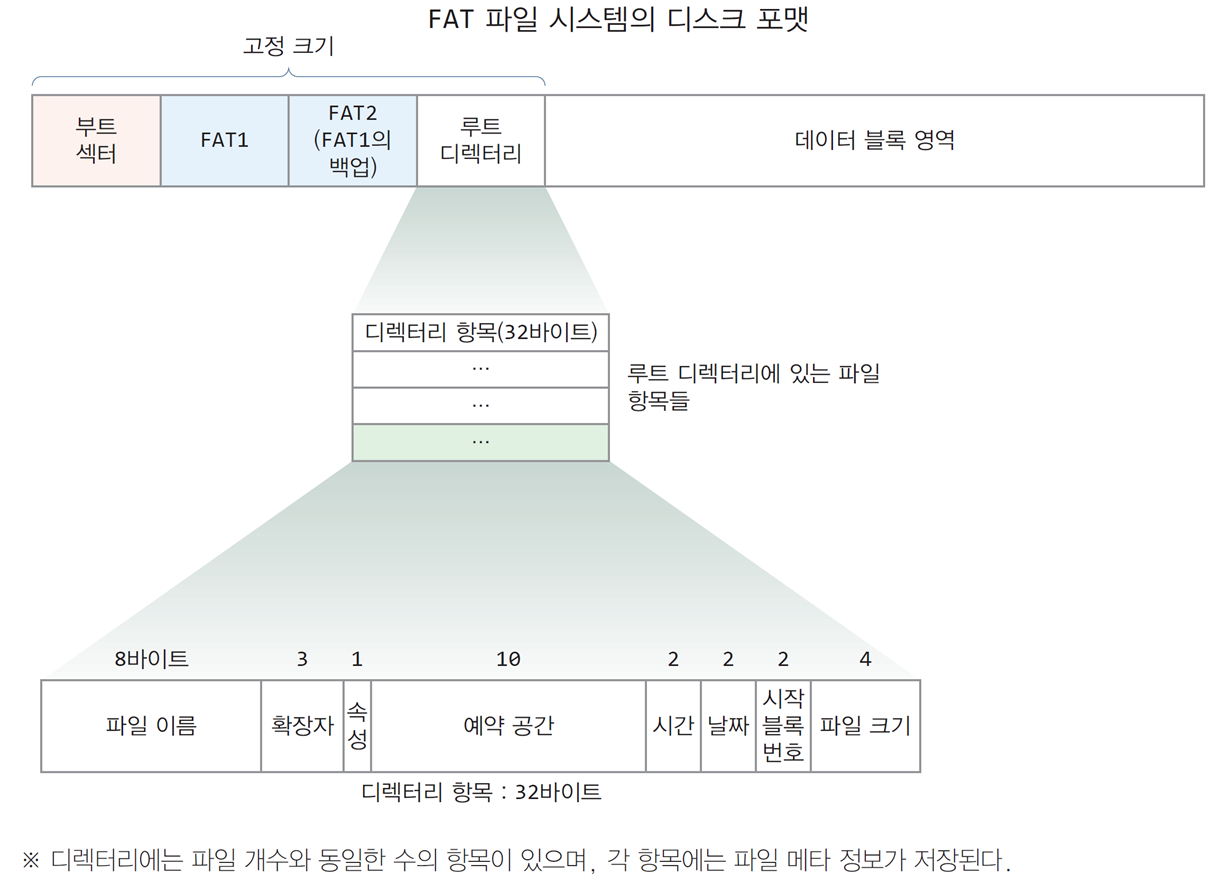
FAT 파일 시스템의 구조
- 디스크의 맨 첫번째 섹터인 부트 섹터(boot sector)에서
루트 디렉터리까지의 공간은 FAT 파일 시스템을 구축할 때(포맷할 때)
고정 크기로 설정됨
부트 섹터
- 한 섹터 크기로 파일 시스템 메타 정보 및 디스크에 관련된 정보들과
컴퓨터가 부팅할 때 실행되는 코드가 저장되는 영역
DOS 버전, 섹터 당 바이트 수, 블록 당 섹터 수, FAT 개수, 루트 디렉터리 항목 개수,
전체 섹터 수, FAT 당 섹터 수, 트랙 당 섹터 수, 디스크 헤드 개수 등-
FAT 테이블 항목들을 조사하면 현재 파일 시스템 내에서
사용 중인 블록들과 비어 있는 블록들을 알 수 있음 -
MS-DOS 운영체제의 커널 코드는
IO.SYS와MSDOS.SYS파일에 들어 있으며,
이들은 모두 루트 디렉터리(C:/)에,
hidden,read-only,system속성으로 저장됨 -
부팅이 시작되면 부트 섹터에 들어있는 코드가 메모리에 적재되고 실행됨
FAT1과 FAT2
-
파일 시스템의 전체 파일에 대해 파일이 저장된 디스크 블록들의 번호 저장
-
FAT가 훼손되면 파일을 찾을 수 없기 때문에 FAT2를 복사본으로 둠
루트 디렉터리
-
루트 디렉터리는 FAT2 바로 뒤에 구성됨
파일을 찾을 때 루트 디렉터리에서부터 시작하므로,
루트 디렉터리를 찾기 쉽도록 위치를 고정시키기 위함 -
루트 디렉터리의 크기는 고정되어 있으므로
루트 디렉터리에 생성되는 파일이나 서브 디렉터리의 개수도 고정됨 -
루트 디렉터리에는 분산된 파일 블록들 중 시작 블록 번호를 저장
-
루트 디렉터리의 바로 아래에 있는 디렉터리의 메타데이터 저장
데이터 블록 영역
-
루트 디렉터리를 제외한 모든 파일의 데이터 블록들이 저장되는 영역
-
각 파일은 블록 단위로 데이터 블록 영역 내에 분산 저장됨
디렉터리
-
파일의 목록을 담은 특별한 파일
-
루트 디렉터리나 서브 디렉터리 모두 구조는 동일함
-
파일 하나당 하나의 디렉터리 항목이 생기므로,
디렉터리 항목의 개수는 디렉터리에 존재하는 파일 개수와 동일함 -
FAT 파일 시스템에서 디렉터리 항목은 하나의 파일 메타 정보를 모두 저장
가장 중요한 것은 시작 블록 번호로 파일이 저장된 첫 번째 디스크 블록 번호
정리
/usr/usrs/a.txt에서
usr,usrs는 디렉터리로 이 곳에 저장되는 데이터는
하위 디렉터리/파일의 메타데이터이고
a.txt는 파일로 실제 데이터가 저장됨즉, 데이터 블록에서
usr에는 usrs의 메타데이터가 저장되고,
usrs에는 a.txt의 메타데이터가 저장됨
a.txt에는 실제 데이터가 저장됨
255개 문자의 긴 파일 이름(Long File Name, LFN)
파일 블록 배치(File Allocation)
- 파일 데이터를 블록 단위로 디스크에 분산 저장하고
저장된 위치는 FAT(File Allocation Table) 라고 불리는 테이블에 기록
이 테이블의 항목들은 연결 리스트(Linked List)로 연결됨
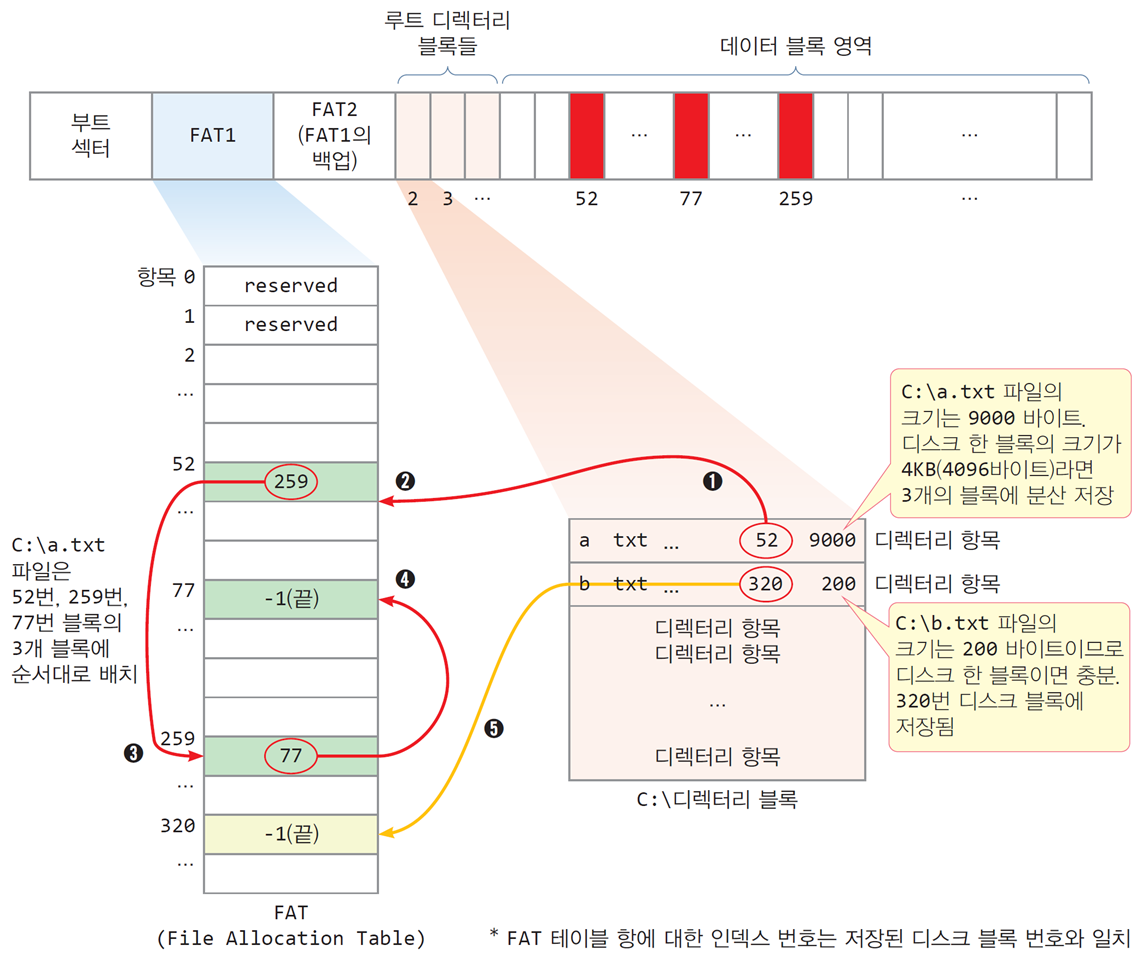
-
FAT 테이블의 항목별 의미
-1: 파일의 마지막 블록
0: 사용 가능한 자유 블록
2~: 파일의 다음 블록 번호 -
FAT 파일 시스템은 구축 시 모두
0으로 초기화되며,
운영체제는 블록을 할당할 때 FAT 항목이0인 블록을 찾아 할당함 -
FAT 테이블의 항목 크기는 12, 16, 32비트로 진화함에 따라
파일 시스템 이름도 FAT12/16/32로 바뀌어 옴 -
FAT 테이블의 항목 크기가 16비트일 때,
한 항목이 가질 수 있는 주소의 경우의 수 = 2개
디스크 블록 크기가 4KB라면 파일 시스템이 저장할 수 있는 데이터의 양은
2 x 2 = 2 = 256MB
FAT 파일 시스템의 장단점
장점
- 단순하여 구현이 쉽고 외부 단편화가 없음
단점
- 파일 당 ½ 블록 크기로 내부 단편화 발생
- 하나의 파일을 순차적으로 읽는 경우, 디스크 전체에 걸쳐 블록을 읽느라 디스크 헤드를 움직이는 탐색 시간(seek time)이 큼
- FAT 테이블 영역이 손상되면 파일 시스템 전체를 읽을 수 없음
3.3 Unix 파일 시스템
Unix 파일 시스템의 구조
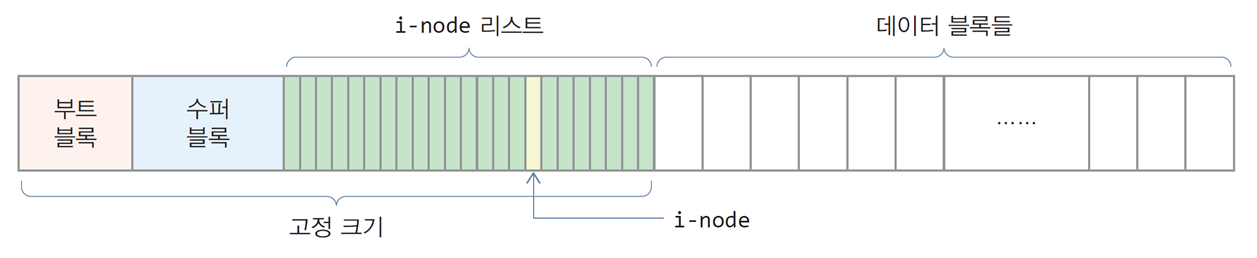
부트 블록(boot block)
-
부팅이 진행될 때 처음에 메모리에 적재되는 디스크 블록
-
운영체제를 적재하는 코드와 부팅 시 필요한 정보가 저장됨
-
하나의 디스크를 여러 개의 파티션으로 나누고
각 파티션마다 파일 시스템을 구축할 수 있음 -
부팅에 참여하지 않는 파일 시스템의 부트 블록은 비어 있음
수퍼 블록(super block)
-
파일 시스템의 유지 관리를 위한 파일 시스템 메타 정보가 기록되는 공간
파일 시스템 크기와 상태 정보
블록 크기
자유 블록 수
자유 블록 리스트
자유 블록 리스트에서 요청시 할당할 다음 블록 인덱스
i-node 리스트의 크기
자유 i-node 수
자유 i-node 리스트
자유 i-node 리스트에서 요청시 할당할 다음 자유 i-node 인덱스
루트 디렉터리의 i-node 번호
수퍼 블록이 갱신된 최근 시간 -
파일이 생성되고 읽고 쓰는 동안 자유 i-node를 찾거나 자유 블록을 찾는 등
커널에 의해 자주 액세스됨
디스크의 입출력을 줄이기 위해 부팅 초기에 메모리에 적재됨 -
메모리에 적재된 수퍼 블록은 파일 입출력 동안 계속 갱신하기 때문에
주기적으로 디스크의 수퍼 블록에 기록되어야 함
메모리 적재 후 갱신되었을 때, 디스크에 기록되지 못한 채 컴퓨터 종료 시
파일 시스템이 깨지는 상황 발생 -
디스크에 저장된 수퍼 블록 손상 시 심각한 문제 발생
→ 파일 시스템마다 디스크에 백업 수퍼 블록(backup super block)을 만들고,
기본 수퍼 블록(primary super block)과 같은 상태 유지
기본 수퍼 블록이 망가지면 백업 수퍼 블록을 이용해 복구
i-node와 i-node 리스트
i-node(index node)
- 파일 메타 정보가 기록되는 구조체로서 파일마다 한 개씩 사용됨
i-node 리스트
- i-node들의 테이블로서 수퍼 블록 다음에 저장되며,
파일 시스템이 구축될 때 크기가 고정되므로 i-node개수도 고정
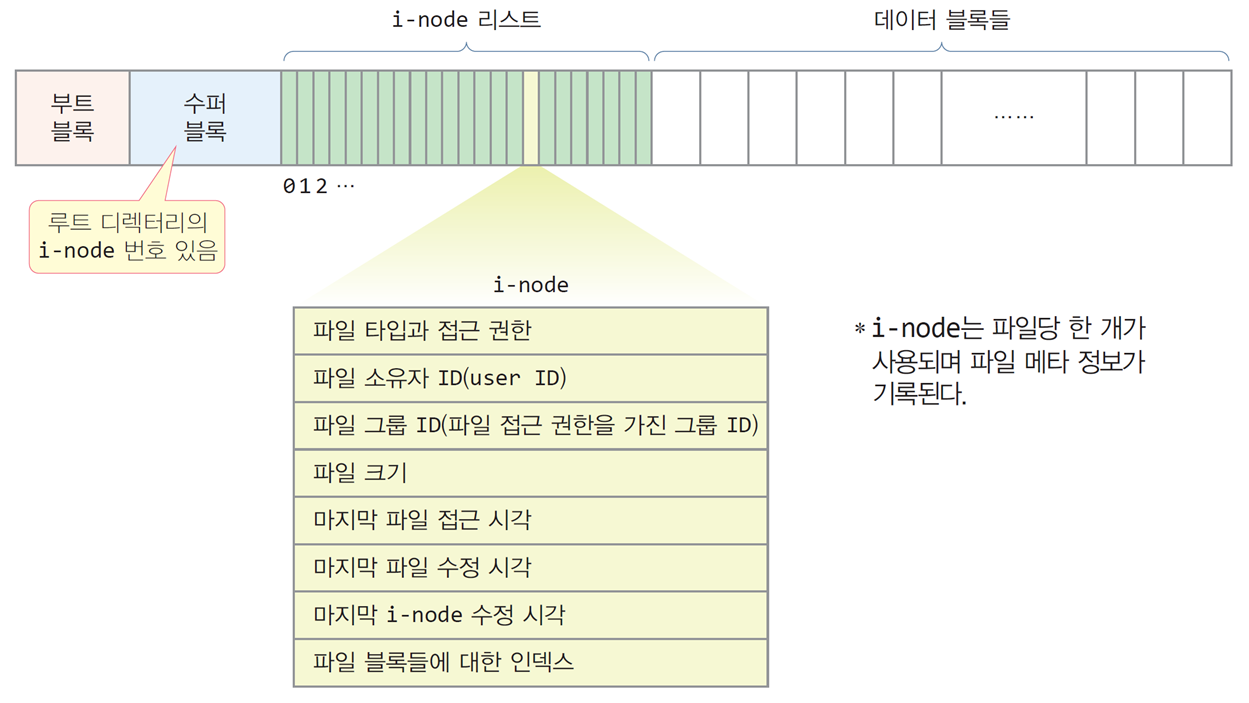
-
파일이 만들어지면 운영체제는 i-node 리스트에서
자유 i-node를 하나 할당받아 파일 메타 정보들을 기록·관리 -
i-node 리스트에서 i-node를 다 사용하게 되면 파일을 생성할 수 없음
-
i-node 리스트의 크기와 자유 i-node에 관한 정보는 수퍼 블록에 기록됨
-
각 i-node는 리스트에서 인덱스로 구분됨
i-node 번호 = i-node 리스트 인덱스와 동일 -
i-node의 번호는 0부터 시작되지만
사용할 수 있는 첫 i-node는 파일 시스템마다 다름
Unix는 1번, 리눅스는 2번부터 사용 가능
0번은 오류 처리를 위해 예약되어 있음
데이터 블록들
- 파일과 디렉터리가 저장되는 공간
- 파일은 블록 단위로 분산 저장됨
- 블록의 크기는 수퍼 블록에 기록되어 있으며, 보통 4KB
디렉터리

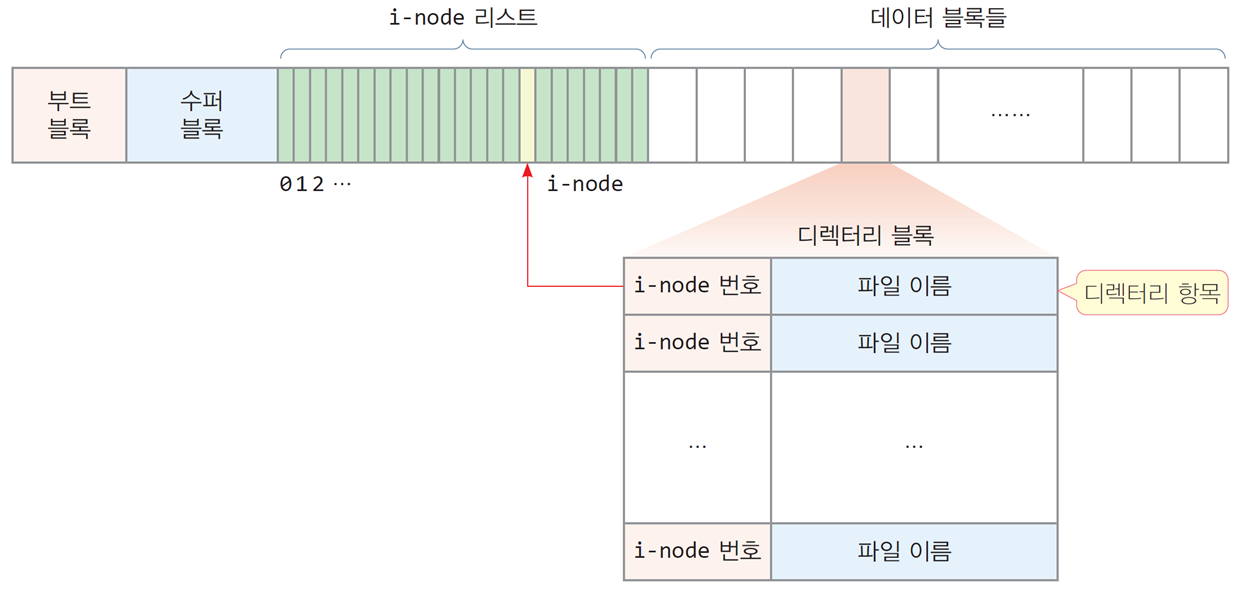
- FAT 파일 시스템이 각 파일의 메타 정보를 디렉터리에 두는 것과 달리,
Unix 파일 시스템은 파일 메타 정보를 i-node에 둔다.
탐구 11-1 Unix 파일 시스템의 Q&A
Q1. Unix 파일 시스템을 사용할 때 만들 수 있는 파일 개수는?
- 파일 하나당 하나의 i-node가 필요하므로
i-node 리스트에 있는 i-node의 개수와 같음
Q2. 수퍼 블록이 메모리에 적재된 채 사용되어야 하는 이유는?
-
커널은 파일이 생성될 때마다 자유 i-node를 찾아야 하고,
파일이 삭제될 때마다 i-node를 반환하기 위해
수퍼 블록을 읽고 쓰는 작업이 발생하기 때문에,
커널 코드의 실행을 빨리 하기 위해 수퍼 블록을 메모리에 적재하여 사용 -
메모리에 적재된 수퍼 블록은 주기적으로 디스크의 수퍼 블록에 저장됨
Q3. Unix 파일 시스템에서
파일 시스템 메타 정보와 파일 메타 정보는 어디에 기록되는가?
- 파일 시스템 메타 정보는 수퍼 블록에 저장되고,
파일 메타 정보는 i-node에 기록된다.
파일 이름은 디렉터리 항목(데이터 블록에 위치)에 기록된다.
TIP 파일의 i-node 번호 보기
ls -ial 명령어를 통해 현재 디렉터리에 저장된 파일들의
i-node 번호와 i-node에 들어 있는 파일 메타 정보 출력

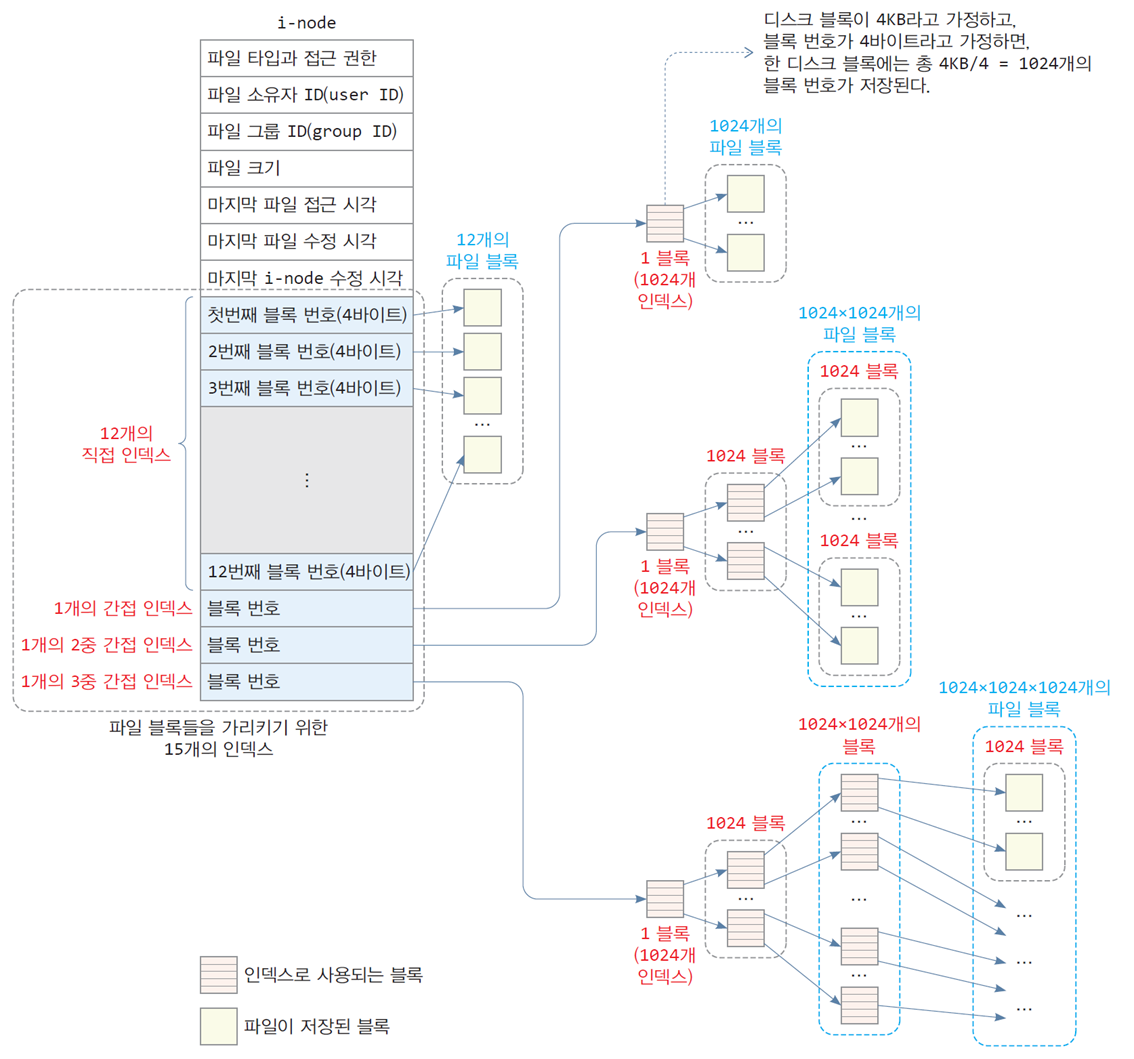
파일 블록 배치(File Allocation)
- 파일을 블록 단위로 디스크의 여러 블록에 분산 저장하고,
i-node에 15개의 인덱스를 통해 파일이 저장된 디스크 블록들의 번호를 기억
12개의 직접 인덱스
+ 1개의 간접 인덱스
+ 1개의 이중 간접 인덱스
+ 1개의 3중 간접 인덱스12개의 직접 인덱스(direct index)
-
파일이 저장된 처음 12개의 디스크 블록 번호를 가리킴
-
파일 생성 시, 데이터 블록들이 저장되는 곳에서 자유 블록 1개를 할당받고,
블록 번호를 12개의 인덱스 중 첫 인덱스에 기록 -
블록 크기가 4KB라고 할 때, 파일 크기가 4KB를 넘어서게 되면
다시 자유 블록을 할당받고 블록 번호를 2번째 인덱스에 기록 -
12개의 직접 인덱스만으로 파일이 저장된 블록을 가리킬 수 있음
-
블록 크기가 4KB일 때
12개의 직접 인덱스로 가리킬 수 있는 파일 블록 수 = 12개
12개의 직접 인덱스로 가리킬 수 있는 파일 크기 = 12 x 4KB = 48KB1개의 간접 인덱스(single indirect index)
-
파일이 12개의 블록을 넘어서 커지게 되면, i-node에 있는 간접 인덱스 사용
-
1개의 디스크 블록을 할당받아 간접 인덱스로 가리키게 하고
이 디스크 블록을 파일 블록에 대한 인덱스들로 사용
-
블록 크기가 4KB이고 블록 번호가 4바이트(32비트)일 때,
= 블록 번호를 표현하는 데 4바이트(32비트)를 사용할 때
간접 인덱스로 가리킬 수 있는 파일 블록 수 = 4KB/4바이트 = 1024
간접 인덱스로 가리킬 수 있는 파일 크기 = 1024 x 4KB = 4MB
인덱스로 사용되는 디스크 블록 수 = 1개
1개의 2중 간접 인덱스(double indirect index)
-
파일이 1034(12 + 1024)개의 블록을 넘어 커지게 되면,
i-node에 있는 2중 간접 인덱스가 사용됨 -
2중 간접 인덱스가 가리키는 1개의 블록은
1024(4KB/4바이트)개의 인덱스로 사용되고,
이 1024개의 인덱스는 또 다시 1024개의 블록 번호들을 가리킴
2중 간접 인덱스로 가리킬 수 있는 파일 블록 수 = 1024 x 1024 블록
2중 간접 인덱스로 가리킬 수 있는 파일 크기 = 1024 x 1024 x 4KB = 4GB
인덱스로 사용되는 디스크 블록 수 = 1 + 1024 = 1025개1개의 3중 간접 인덱스(triple indirect index)
- 파일이 더 커지게 되면
i-node에 있는 3중 간접 인덱스를 이용하여 파일 블록을 가리킴
3중 간접 인덱스로 가리킬 수 있는 파일 블록 수 = 1024 x 1024 x 1024
3중 간접 인덱스로 가리킬 수 있는 파일 크기 = 1024 x 1024 x 1024 x 4KB = 4TB
인덱스로 사용되는 디스크 블록 수 = 1 + 1024 + 1024 x 1024개블록 번호가 32비트(4바이트)이고, 한 블록의 크기가 4KB일 때,
Unix 파일 시스템에서 파일의 최대 크기
48KB + 4MB + 4GB + 4TB
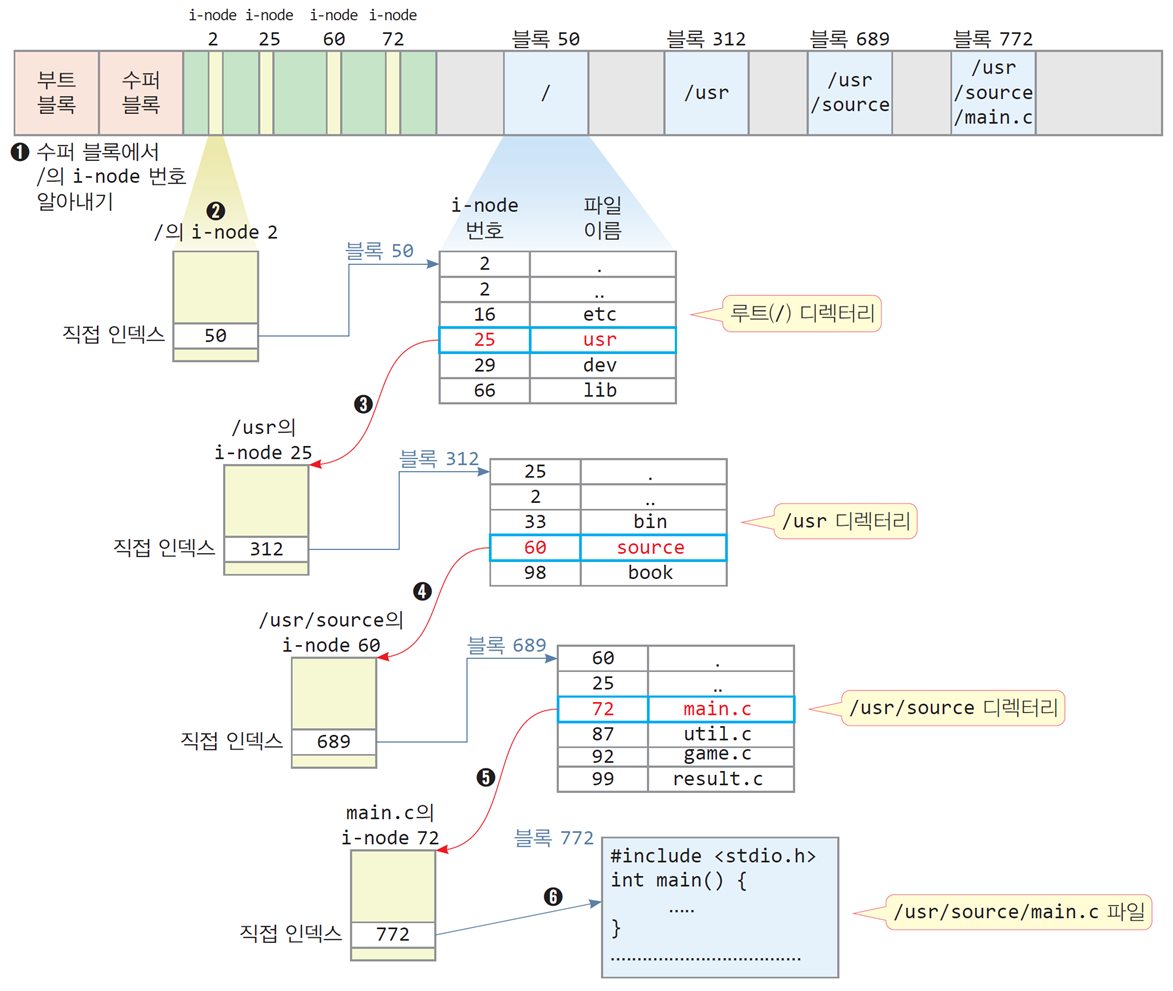
파일의 i-node를 찾는 과정
/usr/source/main.c를 찾는 과정
리눅스에서 긴 파일 이름을 위한 디렉터리 항목

-
파일 이름: 널문자('\0')로 끝나는 문자열로 최대 255문자까지 가능 -
파일 이름 길이: 파일 이름의 실제 길이가 기록됨 -
파일 타입: 파일인지, 디렉터리인지, FIFO인지, 네트워크 소켓인지, 링크인지 등 인지를 나타내는 값이 들어감 -
i-node 번호: 크기도 4바이트로 늘었으며, 값이 0이면 사용되지 않는 디렉터리
04. 파일 입출력 연산
- 파일 입출력은 커널에 의해서만 이루어지므로,
응용프로그램에게 파일 입출력 관련 시스템 호출 함수들이 제공됨
open(), read(), write(), close(), chmode(), create, mount(), unmount() 등4.1 파일 찾기
-
파일 찾기의 과정은 파일의 경로명으로부터 파일의 i-node를 찾는 과정으로
커널에 의해 이루어짐 -
i-node를 찾아야 해당 파일 데이터가 담겨 있는 블록들의 번호도 알 수 있고,
파일 타입과 이 파일에 대한 현재 프로세스의 접근 권한 등을 확인 가능
4.2 파일 열기, open()
파일을 여는 이유
- 파일이 존재하는지 확인
- 현재 프로세스가 파일 연산(읽기/쓰기)할 수 있는지
파일에 대한 접근 권한을 확인
파일이 존재하지 않거나, 접근 권한이 없다면-1을 리턴 - 연이어 파일을 읽거나 쓰기 위한 커널 내에 자료 구조 형성
- 파일이 존재하는지 확인
- 파일이 존재한다면 디스크에서 메모리로 i-node를 읽어들임
- 파일에 대한 접근이 가능한지 권한 여부 판단
- 파일을 읽고 쓰기 위한 커널 자료 구조 형성
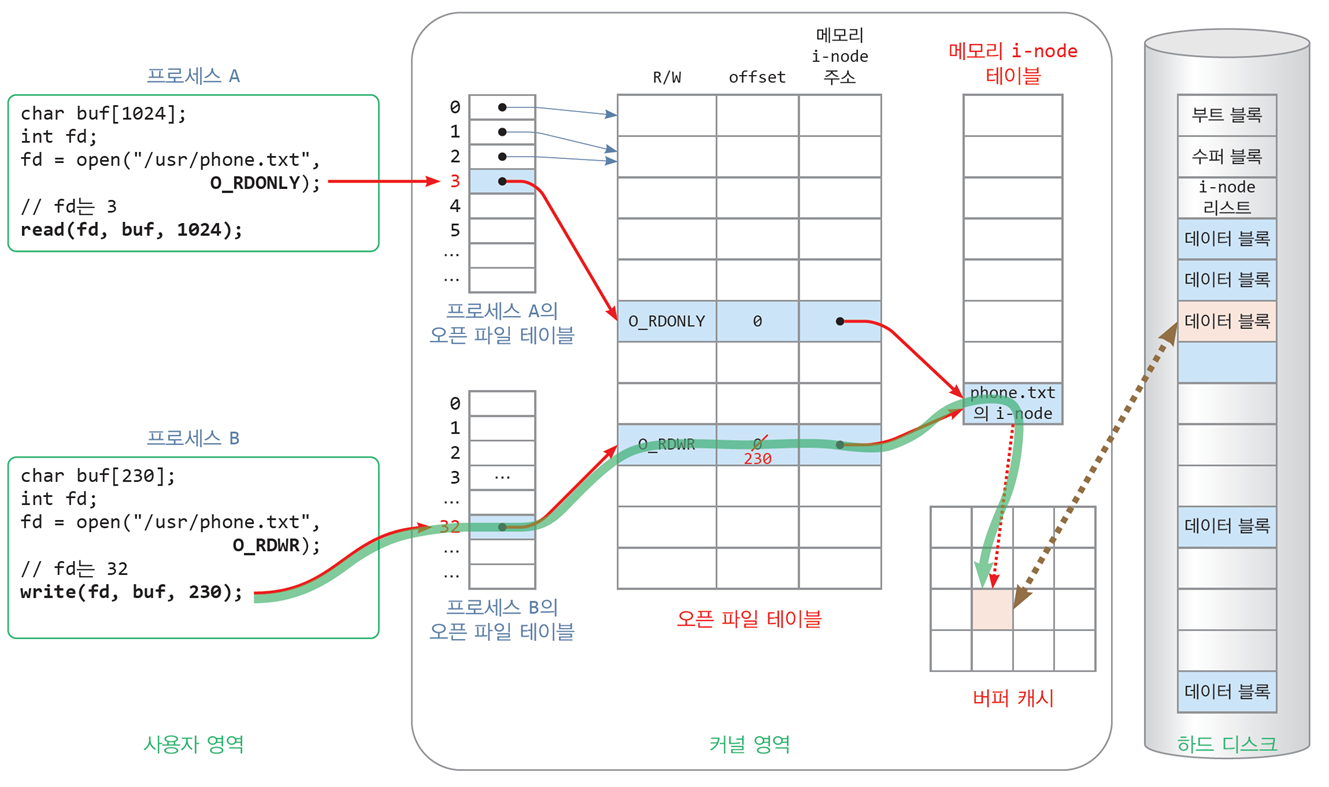
파일 입출력을 위한 커널 자료 구조
메모리 i-node 테이블
-
현재 열린 파일들에 대해 디스크에서 i-node를 읽어 메모리에 형성한 테이블
시스템에 1개 존재 -
i-node는 파일을 읽고 쓰는 과정에서 계속 액세스되므로,
디스크 입출력 시간을 줄이기 위해 메모리에 올려놓고 사용
오픈 파일 테이블(open file table)
-
열려 있는 모든 파일에 관한 정보를 기록해둔 테이블
-
시스템에 1개만 있기 때문에
시스템 파일 테이블(system file table), 전역 파일 테이블(global file table) -
파일이 열릴 때 마다 오픈 파일 테이블의 새 항목이 사용됨
-
열기 모드(R/W)
파일 옵셋(offset)
파일 내에 다음에 읽거나 쓸 바이트 위치를 나타내는 정수값
커널에 의해 파일을 읽은 만큼 또는 쓴 만큼 옵셋을 증가시켜,
다음에 액세스할 파일 내 바이트 위치를 가리키게 함
메모리 i-node의 메모리 주소
등으로 구성 -
오픈 파일 테이블의 항목 개수는
이중 링크드 리스트(doubly linked list)로 구성되어
오픈 파일 테이블의 항목들을 동적으로 할당함
무한정 많은 파일이 열리는 것은 허용하지 않음
프로세스별 오픈 파일 테이블(per-process open file table)
-
프로세스 당 하나씩 존재하며,
프로세스가 파일을 열 때마다 테이블에 1개의 항목이 사용됨 -
오픈 파일 테이블에 대한 메모리 주소가 기록됨
프로세스가 열어 놓은 모든 파일에 대해
오픈 파일 테이블에 대한 주소가 기록된 배열 -
프로세스가 생성될 때 생성되고, 종료하면 소멸됨
-
프로세스의 모든 스레드에 의해 공유됨
-
운영체제에 따라 다르지만 PCB에 저장됨
버퍼 캐시(buffer cache)
-
파일을 읽고 쓰는 과정에서
파일 블록들을 일시적으로 저장하는 메모리 공간 -
커널 공간에 만들어짐
-
어떤 프로세스 혹은 어떤 파일의 블록인지 표시되지 않고,
오직 디스크 블록 번호로만 관리됨 -
프로세스가 파일을 읽을 때 버퍼 캐시에서 바로 읽어갈 수 있으며,
파일 쓰기 시에는 버퍼 캐시에 블록을 쓰는 것으로 파일 쓰기를 마침
버퍼 캐시에 쓰여진 블록들은 커널에 의해 적절한 시점에 디스크에 기록됨
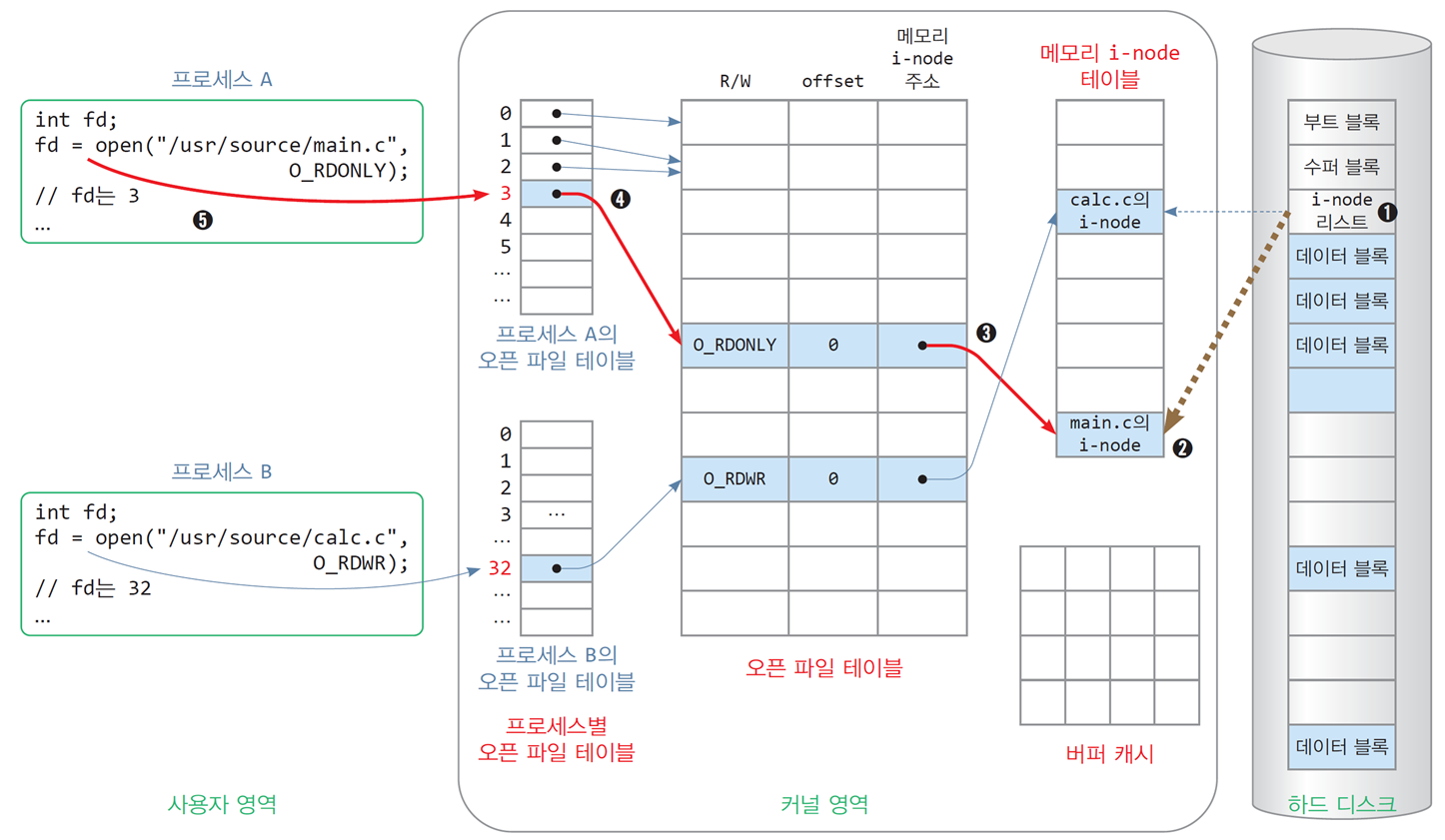
파일 열기 과정
int fd = open("/usr/source/main.c", O_RDONLY);
// /usr/source/main.c를 읽기 모드로 여는 코드(1) 파일 이름으로 i-node 번호 알아내기
(2) 디스크 i-node를 메모리 i-node 테이블에 적재
- 메모리 i-node 테이블에서 비어 있는 i-node를 할당받은 후, 적재
- 메모리 i-node 테이블에는 동일한 i-node가 여러 개 저장되지 않음
- 동일한 파일이 여러 번 열리면 메모리 i-node는 공유됨
- 파일이 수정될 때마다 메모리 i-node가 수정되고
적당한 시점에 디스크 i-node에 저장됨
(3) 오픈 파일 테이블에 새 항목 만들기
- 오픈 파일 테이블에 새 항목을 만들고 메모리 i-node의 주소를 기록
- 파일 열기 모드(
O_RDONLY)정보를 기록 offset값을0으로 초기화
offset값은 다음에 읽을 파일 내 바이트 위치를 나타냄
커널은 파일을 읽은 바이트만큼 offset을 증가시킴
(4) 프로세스별 오픈 파일 테이블에 새 항목 만들기
- 프로세스별 오픈 파일 테이블에 새 항목을 만들고
오픈 파일 테이블 항목에 대한 주소 기록
(5) 프로세스별 오픈 파일 테이블의 항목 번호를 리턴
- 프로세스별 오픈 파일 테이블에 방금 생성한 항목 번호 리턴
- 이 번호는 정수 값으로 응용프로그램에 선연된 변수
fd에 저장됨 - 리눅스, MacOS 등 Unix 계열의 운영체제에서는 이 정수를
파일 디스크립터(file descriptor, fd)
Windows 계열에서는 파일 핸들(handle)이라고 부름
파일 디스크립터(file descriptor)
-
프로세스별 오픈 파일 테이블의 인덱스로서
열린 파일마다 매겨진 고유한 정수 번호
응용프로그램이 열어 놓은 파일을 대변하는 값 -
파일을 연 응용프로그램에게 반드시 전달해야 함
-
open()의 리턴값
TIP 파일 디스크립터 0, 1, 2
0: 표준 입력 장치(키보드)
1: 표준 출력 장치(디스플레이)
2: 표준 오류 장치(디스플레이)
- 장치들은 운영체제에서 파일로 다루어짐
#include <stdio.h>
int main() {
char c;
read(0, &c, 1); // 0번 파일 디스크립터(키보드)에서 문자 1개를 읽어 변수 c에 저장
write(1, &c, 1); // 1번 파일 디스크립터(디스플레이)에 변수 c의 문자 출력
write(2, "hello\n", 6); // 2번 파일 디스크립터(디스플레이)dp "hello\n" 출력
}
// 출력 결과
// a
// ahello#include <unistd.h> // 이곳에 상수로 선언되어 있기 때문에 가능함
read(STDIN_FILENO, &c, 1);
write(STDOUT_FILENO, &C, 1);
write(STDERR_FILENO, "hello\n", 6);
// 출력 결과
// a
// ahello
// 또는
#include <stdio.h>
fscanf(stdin, "%c", &c);
fprintf(stdout, "%c", c);
fprintf(stderr, "hello\n");
// 출력 결과
// a
// hello // stderr에 출력하면 버퍼를 거치지 않고 바로 출력됨
// a- 처음부터
printf()나scanf()를 사용하여 입출력을 할 수 있는 것은 운영체제가 프로세스를 생성할 때, 프로세스별 오픈 파일 테이블에
파일 디스크립터 0, 1, 2 항목을 만들어 두었기 때문
4.3 파일 읽기, read()
char buf[1024];
int fd;
fd = open("/usr/source/main.c", O_RDONLY); // 파일 열기 후 fd는 3이라고 가정
read(fd, buf, 1024); // main.c 파일에서 1024 바이트를 읽어 buf에 저장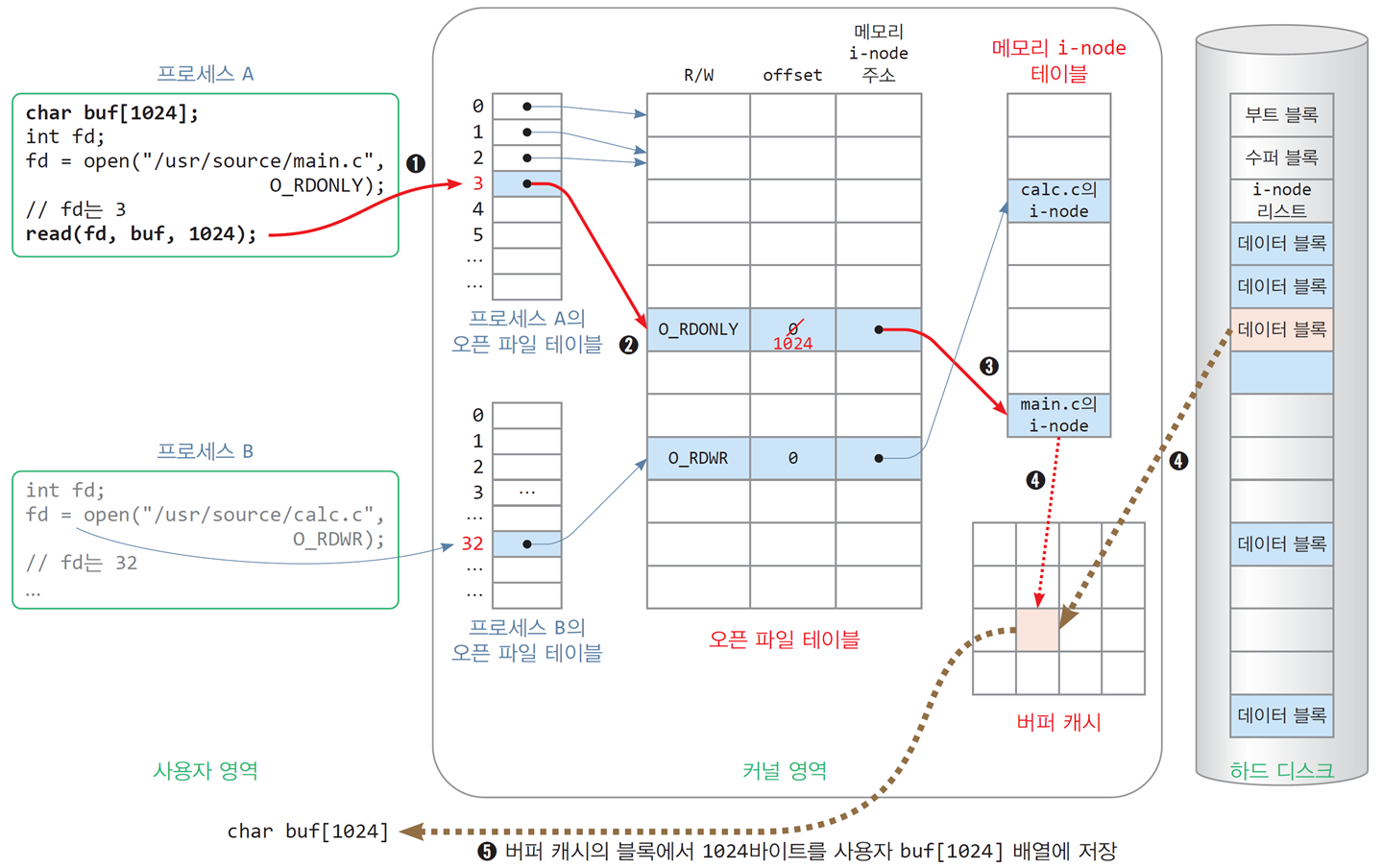
4.4 파일 쓰기, write()
char buf[230];
int fd;
fd = open("/usr/source/calc/c", O_RDWR);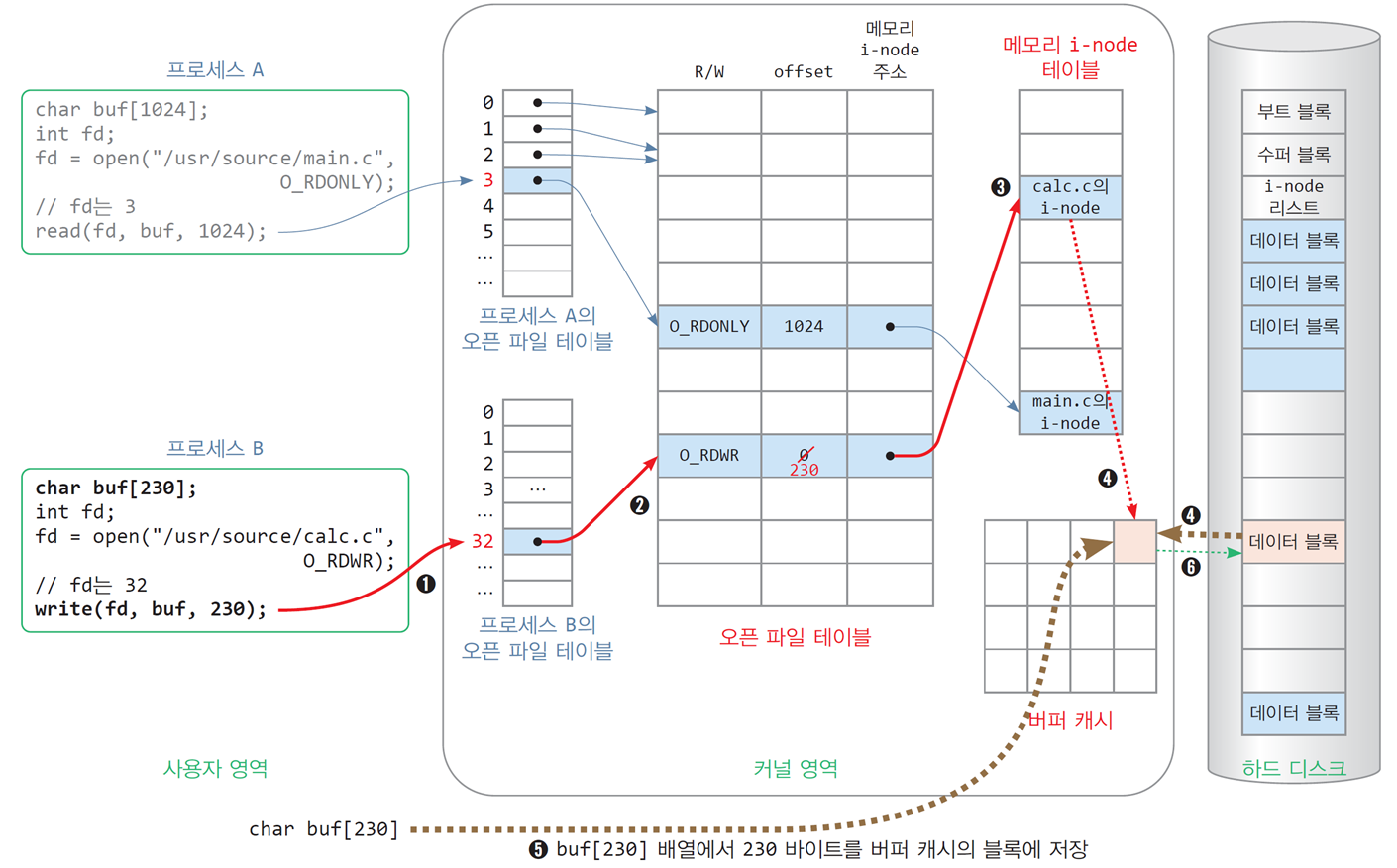
4.5 파일 닫기, close()
close(fd); // fd가 가리키는 calc.c 파일 닫기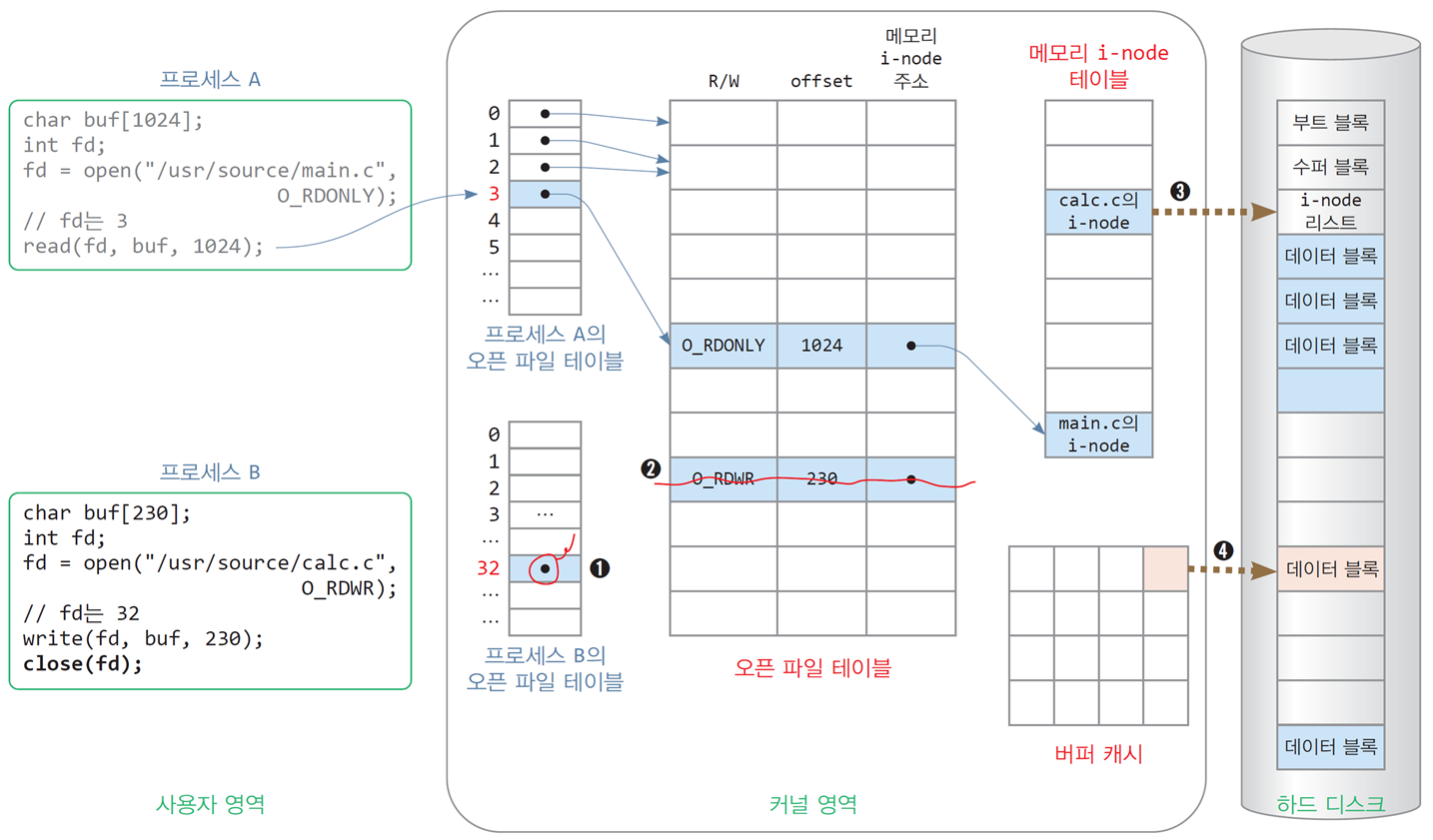
오픈 파일 테이블 항목의 참조카운트
-
오픈 파일 테이블의 항목은 서로 같은/다른 프로세스에 의해 공유될 수 있음
-
공유되는 개수를 기억하기 위해
참조카운트(reference count) 필드를 두고 있음
파일이 닫힐 때 참조카운트를 1감소, 0이 되면 항목 제거
탐구 11-2 동일한 파일을 동시에 여는 경우
- 두 프로세스 중 누가 먼저 실행되느냐에 따라 결과가 달라짐