강의 목표
-
저장 장치의 특징과
저장 장치가 시스템의 성능과 신뢰성에 미치는 영향을 이해한다. -
하드 디스크 장치의 구조와 입출력 과정을 통해
디스크 입출력 성능을 결정하는 요소에 대해 이해한다. -
디스크 스케줄링 알고리즘에 대해 이해하고 이들의 성능을 비교한다.
FCFS, SSTF, SCAN, C-SCAN, LOOK C-LOOK -
디스크의 저수준 포맷과 고수준 포맷에 대해 이해한다.
-
최근에 많이 이용되는
SSD 저장 장치의 구조와 입출력 과정 등에 대해 이해한다.
01. 저장 장치 개요
1.1 저장 장치의 특징
주기억장치
-
현재 실행 중인 프로그램 코드와 데이터를 적재
-
CPU가 직접 접근하는 기억장치
RAM 반도체 메모리가 사용됨
저장 장치

-
전원이 꺼져도 프로그램과 데이터를 보조 저장할 수 있는 대용량 장치
-
CPU가 직접 접근하지 않고 입출력 전용 처리기에 의해 입출력됨
하드 디스크, SSD, 자기테이프, CD, RAID, USB 스틱 등 -
대용량
몇 백 기가바이트(GB Giga Byte)에서 수십 테라바이트(Tera Byte) -
비휘발성(non-volatile)
컴퓨터의 교체 시기보다 긺 -
가상 메모리의 스왑 공간으로 활용
메모리 계층 구조의 최하위단으로
데이터베이스나 파일 저장 및 가상 메모리의 스왑 공간으로 이용됨
1.2 저장 장치의 성능 및 신뢰성
- 저장 장치의 입출력 병목(I/O bottleneck) 문제 - 시스템 성능에 영향
- 저장 장치의 데이터 신뢰성(data reliability) 문제 - 시스템 신뢰성에 영향
저장 장치의 입출력 병목
-
저장 장치가 입출력에 과부하가 걸려 있는 상태
-
여러 프로세스로부터 유발된 입출력 요청들로 인해,
사용자나 프로세스는 입출력이 끝나기를 오래 기다리는 현상 -
CPU와 메모리의 처리 속도에 저장 장치의 속도 향상은 미치지 못한 것이 원인
-
주기억장치 메모리 늘리기
메모리를 늘려 저장 장치로의 입출력 횟수를 줄이기 -
디스크 캐시 늘리기
디스크 블록의 다음 블록들을 미리 디스크 캐시에 읽어두어
순차 읽기 응용의 입출력 응답 속도를 높인다. -
디스크 스케줄링
디스크 암의 움직임을 최소화함으로써
디스크 장치의 물리적인 입출력 시간을 단축하는 기법 -
SSD와 같은 빠른 저장 장치나 RAID와 같은 병렬 저장 장치 사용
속도가 빠른 저장 장치나 디스크를 병렬로 동작시키는
RAID(Redundant Array of Inexpensive Disks)를 이용하여
물리적인 입출력 성능 향상
데이터 신뢰성
디스크 미러링(disk mirroring)
- 2개의 디스크에 항상 동일한 데이터가 기록되도록 구현하고
사용자에게는 1개의 디스크처럼 보이게 하는 기법
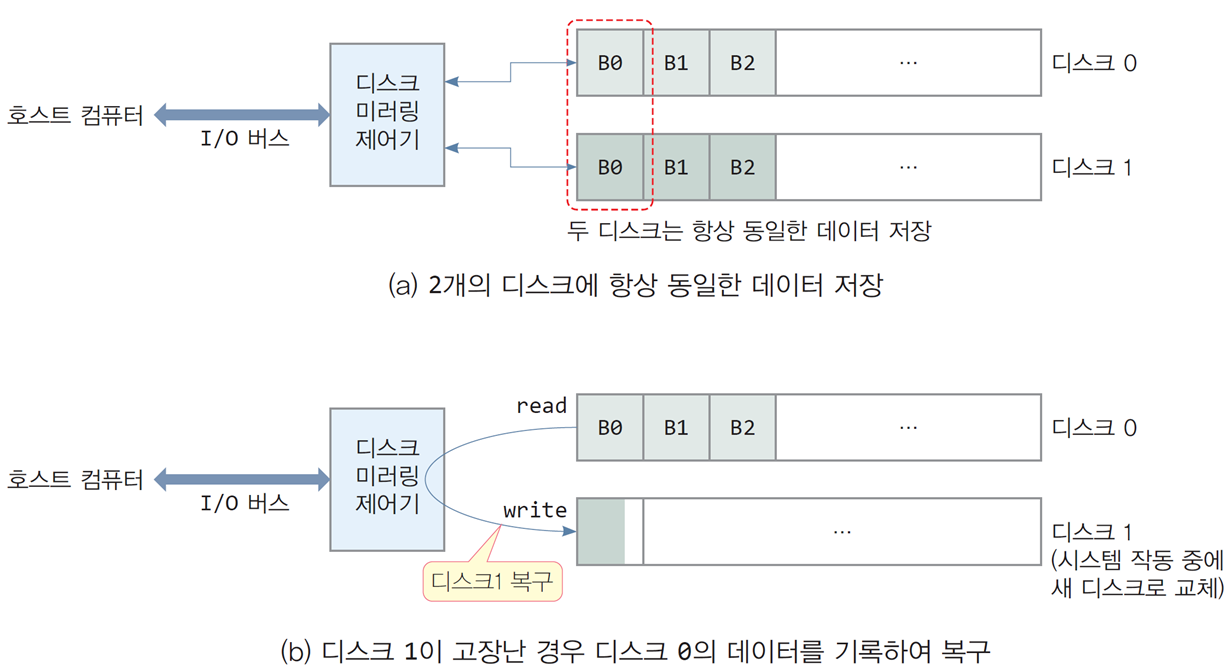
-
디스크 미러링은 RAID 기법 중 하나로 RAID 레벨 1이라고 부름
-
RAID는 디스크의 입출력 병목 및 데이터의 신뢰성을 높이는 기법
-
핫 스와핑(hot swapping)
시스템 동작 중 디스크가 고장나면, 시스템이 동작 중인 상태에서
고장난 디스크를 제거 및 새 디스크를 삽입
RAID
- 디스크에 패리티(parity) 정보와 함께 분산 기록하여
디스크가 손상될 때 자동으로 복구하는 기법
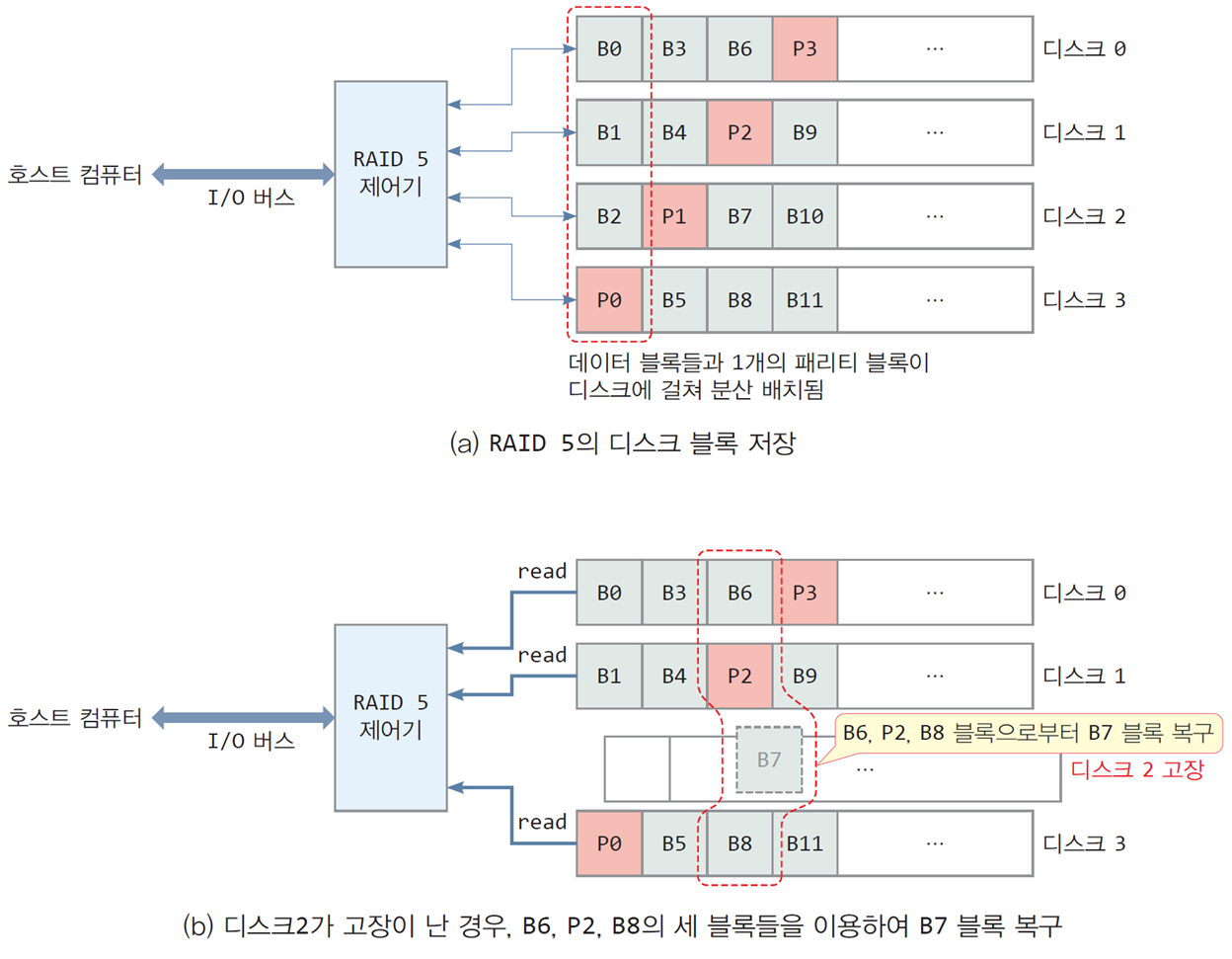
-
RAID 기법 중 가장 많이 사용되는 레벨 5의 모형
-
3개의 디스크에 돌아가면서 배치하며,
그중 한 디스크에는 패리티(parity) 블록을 저장 -
작동 중 디스크 2가 고장이 나면 디스크 0, 1, 2를 통해 디스크 2를 복구
TIP 패리티 비트
-
데이터를 전송할 때, 오류를 검출하기 위해 추가되는 비트
-
짝수/홀수 패리티 비트
데이터와 패리티 비트를 합쳐
1의 개수가 짝수(홀수)개가 되도록 패리티 비트를 만듦
데이터 비트가001일 때, 짝수 패리티 비트는1, 홀수 패리티 비트는0 -
홀수 패리티 비트 생성 방법은
모든 데이터 비트들에 XOR(exclusive OR, ⊕)
홀수패리티 비트 p = b0 ⊕ b1 ⊕ b2
사용 중 B2 블록 손상 시, B2 = P0 ⊕ B0 ⊕ B1
02. 하드 디스크 장치
2.1 하드 디스크 장치의 구조
하드 디스크(HDD, Hard Disk Driver)
- 자성체(magnetic meterial)로 코팅된 여러 개의 원형 판(platter, 플래터)에
디지털 정보를 저장하고 읽어 내는 저장 장치
디스크 제어 모듈
-
호스트로부터 명령을 받아 디스크 매체 모듈에 지시하여
디스크 캐시와 디스크 매체 사이에 입출력이 이루어지도록 함 -
입출력 버스 인터페이스를 통해
디스크 캐시에 저장된 데이터를 호스트로 전송 또는
호스트로부터 디스크 캐시로 데이터 수신
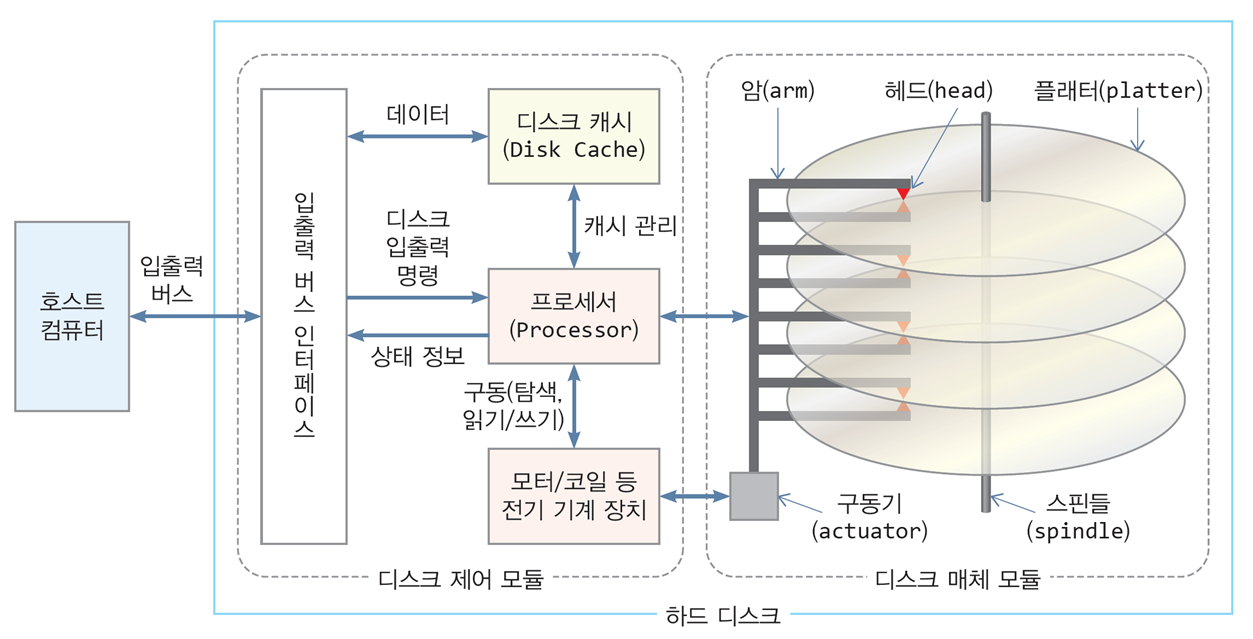
입출력 버스 인터페이스
- 입출력 버스를 통해 호스트로부터 입출력 명령을 수신하고
데이터를 주고받는 하드웨어
PCI/SCSI/SATA/USB 버스 인터페이스 등 다양한 종류 존재
프로세서
-
운영체제로부터 전달받은 디스크 입출력 명령을 해석하여
기계 장치를 구동시켜 하드 디스크의 암(arm)을 움직이거나
디스크 헤드(disk head)를 제어하여 플래터에서 읽거나 씀 -
내부에 명령 큐를 두고 호스트로부터 받은 여러 개의 입출력 명령 저장
-
스케줄링을 통해 디스크 액세스 시간 단축 및 캐시 관리
디스크 캐시
-
입출력되는 데이터의 임시 저장소 역할을 하는 빠른 반도체 메모리
몇 십 MB 크기 -
운영체제가 저장하기 위해 보낸 데이터는 디스크 캐시에 먼저 저장 후,
프로세서에 의해 플래터에 기록됨 -
프로세서는 예측 읽기(prefetch)를 통해 다음에 읽을 것으로 예측되는 데이터를 디스크 캐시에 읽어 놓아 호스트의 응답 시간을 단축
디스크 매체 모듈
플래터(platter)
- 완전한 원형 판의 자성체로 디지털 정보가 기록되는 곳
디스크 헤드(disk head)
-
플래터 위를 움직이며 디지털 정보를 읽거나 쓰는 장치
-
디스크 헤드는 플래터 표면 위에 일정한 간격을 유지한 채 정보를 읽거나 기록
플래터 표면에 닿게 되면 해당 부분이 손상되어 불량 섹터(bad sector) 가능성
암(arm)
- 디스크 헤드를 원하는 위치로 움직이는 장치
구동기(actuator)
- 암들은 모두 하나의 구동기에 달려 있으며, 함께 이동한다.
그 중 하나의 플래터에서만 입출력을 진행함
디스크 파킹(disk parking)
park
디스크 암을 플래터 바깥의 안전한 위치로 이동시키는 명령어
디스크 암이 플래터 위에 있는 상태에서 컴퓨터를 옮기면 플래터 훼손 가능성
TIP 최초의 하드 디스크 IBM RAMAC 350
2.2 입출력 버스
- 입출력 버스는 다음과 같이 여러 종류가 있으며, 하드 디스크 제조업체는
버스 인터페이스 회로를 포함하는 하드 디스크를 만듦
ATA, SATA(Serial ATA), SCSI, IEEE 1394, Fiber Channel, USB
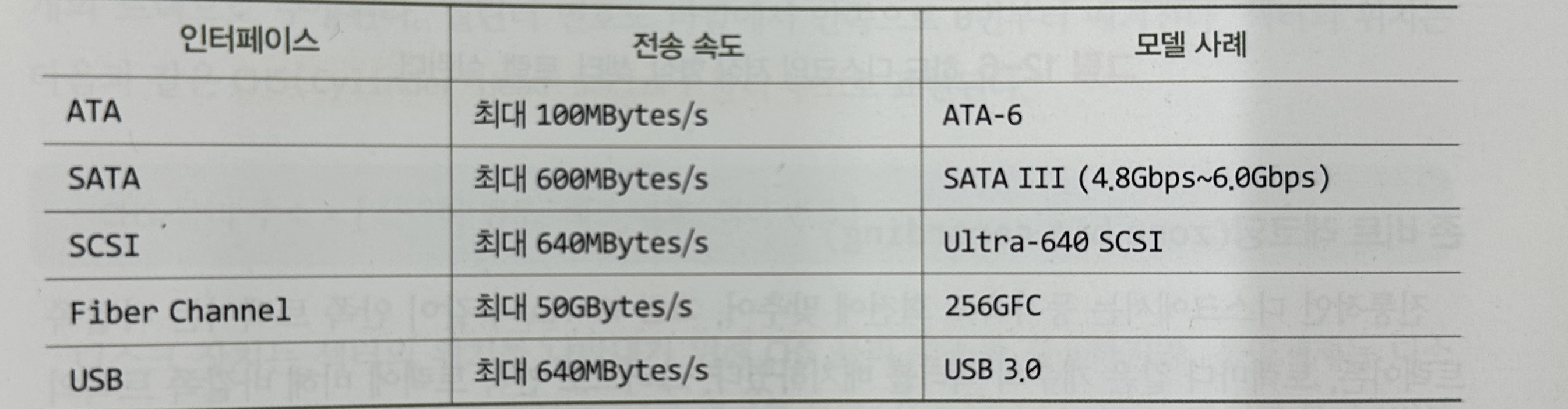
ATA(Advanced Technology Attachment)
- 하드 디스크나 CD-ROM 장치를 PC에 연결하는 표준 입출력 버스
상업적으로 IDE, EIDE 라는 이름으로 사용됨
SATA
- 현대 컴퓨터에서 디스크 장치를 연결하는 가장 보편적인 버스
PC나 노트북의 하드 디스크에 사용됨
SCSI(Small Computer System Interface)
- 하나의 버스에 하드 디스크, CD-ROM, DVD, 스캐너 장치 등
여러 개의 장치들을 동시에 연결하는 입출력 버스
서버급 컴퓨터나 워크스테이션에서 사용됨
2.3 디스크 저장 구조
섹터, 트랙, 실린더
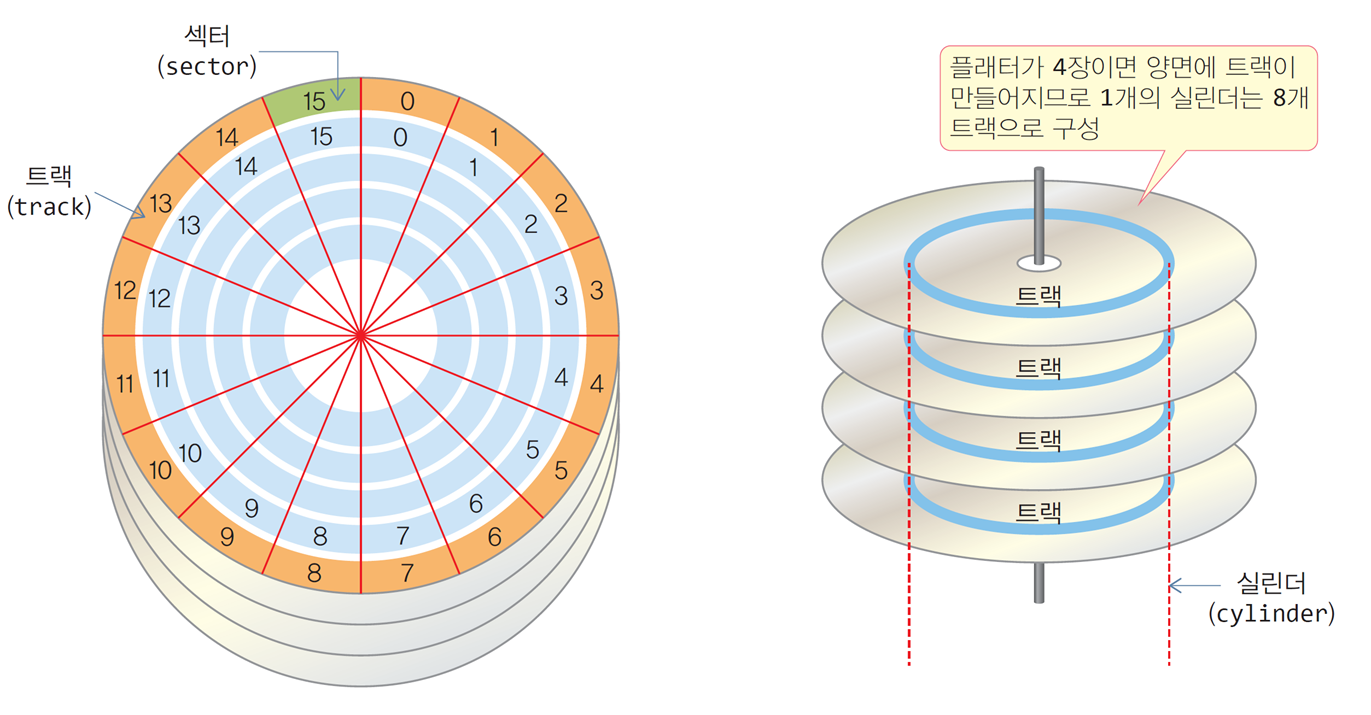
-
하드 디스크의 모든 플래터들은
하나의 구동축(spindle, 스핀들)에 연결되어 동시에 회전 -
언제나 동일한 속도인 등각속도(CAV, Constant Angular Velocity)로 회전
트랙(track)
- 플래터의 표면에는 여러 개의 동심원을 따라 정보가 저장되는데,
이 때의 각 동심원
실린더(cylinder)
- 같은 동심원을 가진 트랙들의 모임
섹터(sector)
-
디스크 장치가 저장하고 읽는 최소 단위
-
전통적으로 512바이트 크기이지만,
최근에는 4KB 크기의 고급 포맷(Advanced Format)을 사용
존 비트 레코딩(zone bit recording)
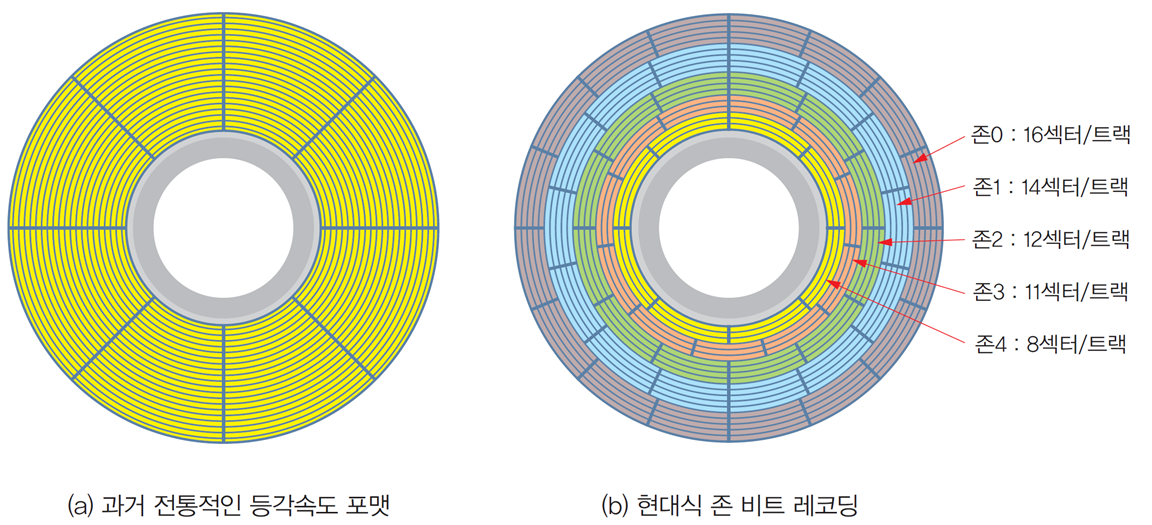
전통적인 디스크
- 전통적인 디스크에서는 안쪽 트랙과 바깥쪽 트랙에 같은 개수의 섹터를 배치
안쪽 트랙에 비해 바깥쪽 트랙의 저장 밀도가 낮음
존 비트 레코딩
-
밀도가 낮은 바깥쪽 트랙에 더 많은 섹터를 배치하는
존 비트 레코딩(zone bit recording, ZBR) 방식의 하드 디스크 등장 -
전체 트랙을 몇 개의 존(zone, 영역)으로 나눔
-
바깥 존에 더 많은 트랙 당 섹터를 배치하여
디스크의 저장 용량을 늘리고 입출력 속도를 높임 -
바깥 존일수록 더 많은 섹터가 있으므로
시간당 입출력되는 섹터가 많아, 입출력 속도가 더 높음
디스크 물리 주소
-
트랙과 섹터는 바깥에서 안으로 0부터 증가하는 순서로 번호가 매겨짐
플래터의 개수가 4개일 때, 헤드는 8개, 한 실린더는 8개의 트랙으로 구성 -
실린더 번호도 바깥에서 안쪽으로 0번부터 매겨짐
-
섹터의 위치는 CHS(Cylinder-Head-Sector) 물리 주소로 표현됨
CHS 물리 주소 = [실린더 번호, 헤드 번호, 섹터 번호] -
운영체제는 디스크의 모든 섹터를 일차원으로 펼치고,
여러 섹터를 블록(disk block)이라는 단위로 묶어 0번부터 블록에 번호를 매긴
논리 블록 주소(LBA, Logical Block Address)를 사용
하드 디스크의 회전 방향
- 하드 디스크의 모터는 반시계 방향으로 회전함
명확한 이유는 존재하지 않음
하드 디스크를 세워 놓으면 고장 나지 않을까?
- 하드 디스크는 세워 놓든 눕혀 놓든 반대로 세워놓든 전혀 영향이 없음
2.4 디스크 용량
디스크 용량 = 실린더 개수 x 실린더 당 트랙 수 x 트랙 당 섹터 수 x 섹터 크기- 실린더 당 트랙 수 = 디스크 헤드의 개수
용량 계산 사례 1
실린더: 1000개
실린더 당 트랙 수: 8개
트랙 당 섹터 수: 200개
섹터 크기: 512바이트
디스크 용량 = 1000 x 8 x 200 x 0.5KB = 약 800MB(819.2MB)용량 계산 사례
실린더: 4000개
실린더 당 트랙 수: 2개
트랙 당 섹터 수: 2000개
섹터 크기: 512바이트-
(1) 디스크에는 총 몇 개의 트랙이 있는가?
4000 x 2 = 8000개 -
(2) 트랙당 저장 용량은 얼마인가?
2000 x 512바이트 = 약 1MB -
(3) 디스크의 총 저장 용량은 얼마인가?
8000 x 1MB = 8GB
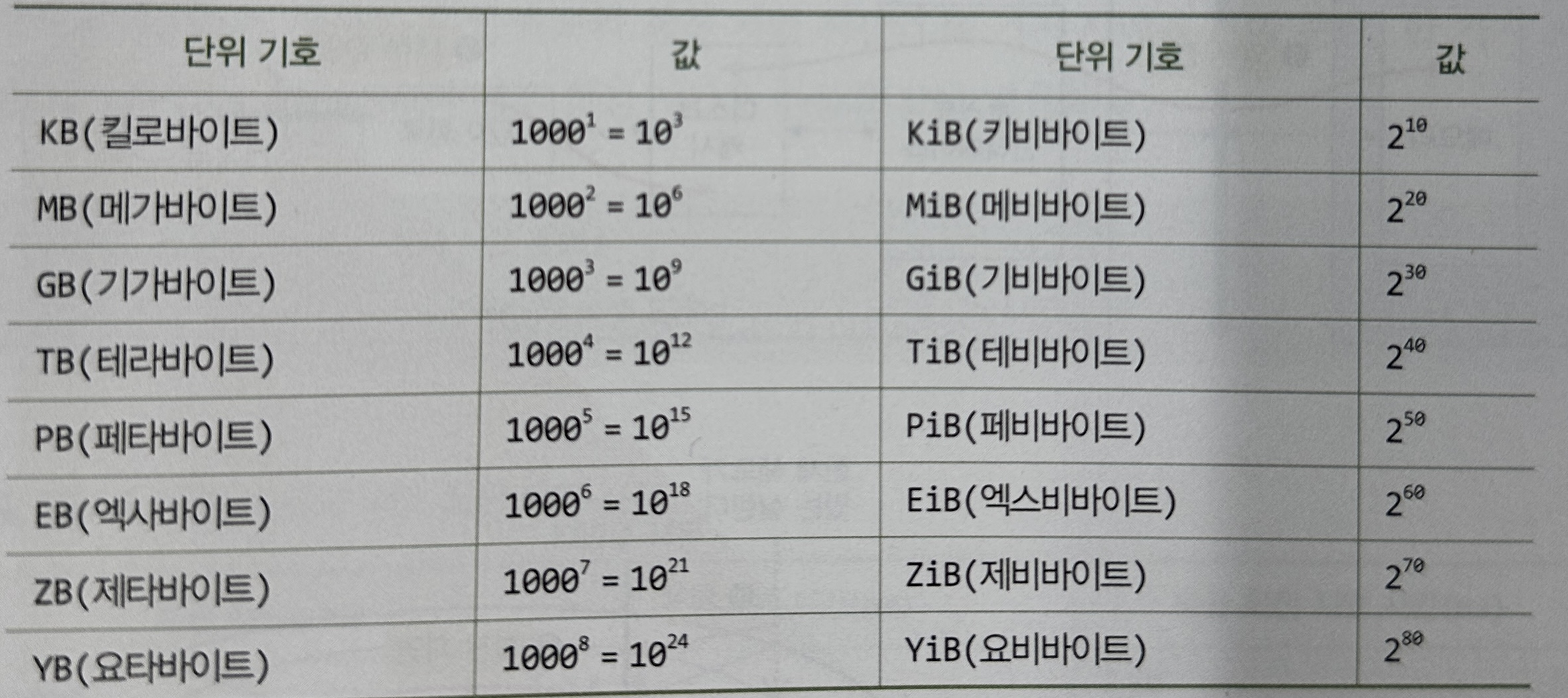
TIP 저장용량을 나타내는 단위, KB와 KiB
KB,MB,GB의 단위는1000을 단위로 하고,
KiB,MiB,GiB의 단위는1024를 단위로 함
2.5 디스크 입출력 과정 및 성능 파라미터
-
디스크 장치는 운영체제의 디스크 드라이버로부터 받은 입출력 명령을 실행
-
운영체제는 논리 블록 주소를 사용하기 때문에,
디스크 장치가 운영체제로부터 받는 명령의 구성은 다음과 같다
읽기/쓰기, 논리블록번호(LBA), 호스트의 메모리 주소, 읽거나 쓰는 블록 수 -
디스크 입출력 명령이 내려지면, 디스크 장치 내 프로세서가
논리 블록 번호 → CHS 물리 주소 후, 디스크 헤드를 목표 실린더로 이동
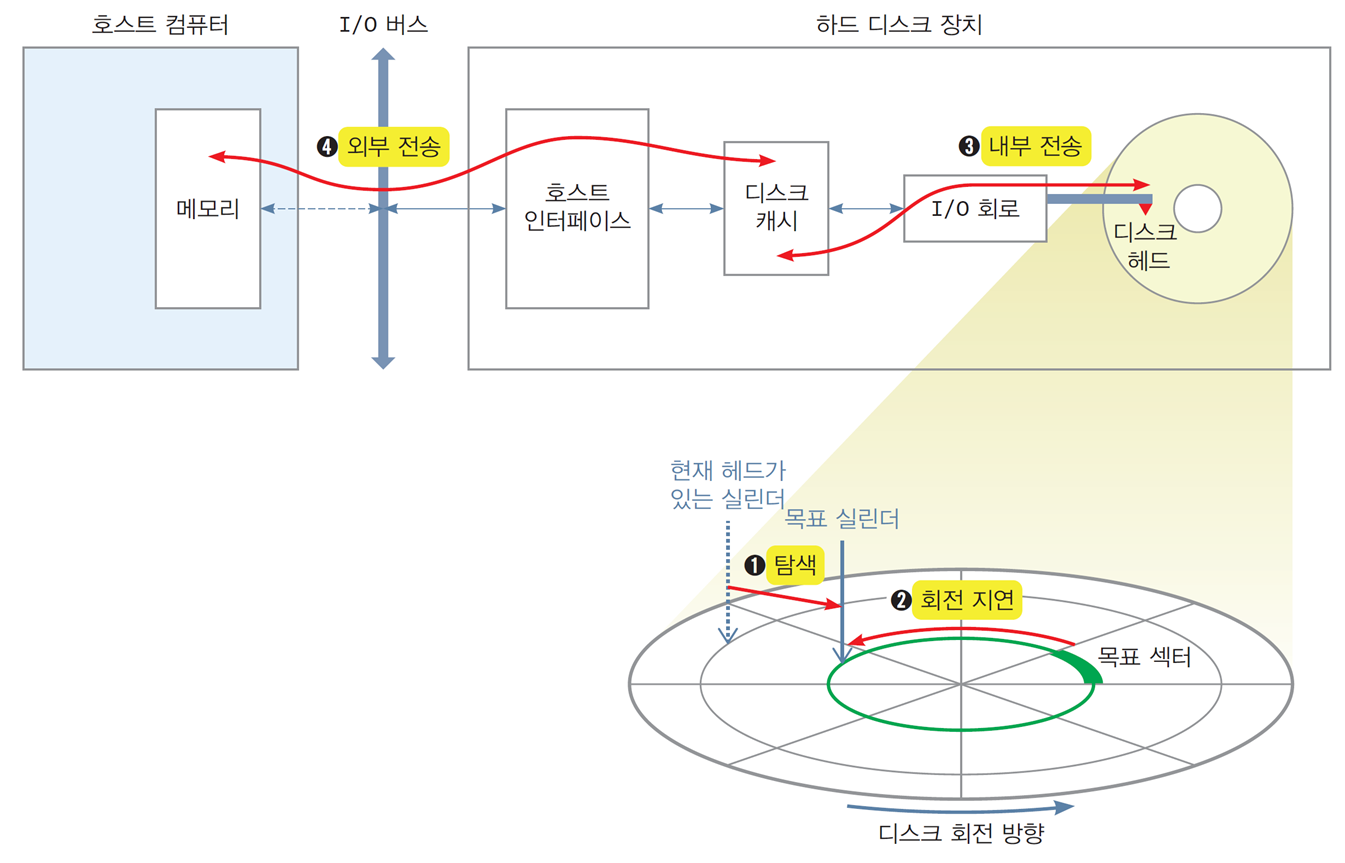
-
1) 탐색(seek)
디스크 헤드를 목표 실린더로 이동 -
2) 회전 지연(rotational latency)
플래터가 회전하여 목표 섹터가 디스크 헤드 밑에 도달할 때 까지 대기 -
3) 전송(transfer)
디스크 헤드와 호스트 사이의 데이터 전송. 내부 전송과 외부 전송으로 나뉨 -
4) 오버헤드(overhead)
프로세서가 호스트에서 명령을 받고 해석하는 등 부가 과정
탐색
-
디스크 장치 내 모터를 이용하여
디스크 헤드를 현재 실린더에서 목표 실린더로 이동시키는 과정 -
이동하는 실린더 개수를 탐색 거리(seek distance)라고 함
탐색 시간은 탐색 거리에 선형적으로 비례 -
탐색 거리가 매우 짧은 경우 탐색 시간이 많이 걸리는 현상이 일어남
모터가 디스크 암을 가속시키는 탐색 초기와
목표 실린더 앞에서의 감속에 많은 시간이 걸리기 때문 -
오늘날 상용 하드 디스크의 평균 탐색 시간은 5ms 내외(1ms~10ms)
회전 지연
-
탐색 후 플래터가 회전하여
헤드 밑에 목표 섹터가 도달할 때 까지 걸리는 시간 -
평균 회전 지연 시간 = 1/2 회전 시간
-
디스크의 회전 속도는 분당 회전수로 나타내며,
단위는 RPM(Rotations Per minute) -
7200RPM인 경우
1회전 시간 = 60초/7200 = 8.33ms
평균 회전 지연 시간 = 8.33ms / 2 = 4.17ms
전송
내부 전송
-
디스크 헤더가 플래터 표면에서 디스크 캐시로 데이터를 읽어오거나,
반대로 디스크 캐시에서 플래터 표면에 데이터를 기록하는 시간 -
한 트랙이 1000개의 섹터로 구성되고 섹터 크기는 512바이트(0.5KB)
한 트랙의 크기 = 1000 x 0.5KB = 500KB
디스크의 회전 속도가 7200RPM일 때, 1회전 시간 = 8.3ms
→ 8.3ms에 500KB를 읽어 전송
500KB/8.3ms = 약 60.24KB/ms = 60240KB/초 = 60MB/초-
디스크의 회전 속도가 빠를수록 내부 전송 속도가 빠름
-
디스크 제조업체에서 공개하는 디스크의 데이터 전송률(data transfer rate)은
보통 내부 전송 속도를 의미함 -
바깥쪽 트랙을 액세스할 경우, 전송률이 더 높음
외부 전송
-
디스크 캐시와 호스트 컴퓨터 사이에 데이터가 전송되는 시간
-
디스크 장치와 호스트 컴퓨터가 연결되는 I/O 버스의 속도에 달려 있음
일반적으로 외부 전송 시간 < 내부 전송 시간
오버헤드 시간
- 호스트로부터 명령을 받고 해석하는 시간
- 디스크 헤드의 변경 시간(head switch time)
이러한 시간들은 몇 마이크로초(us) 수준으로 매우 작기 때문에
디스크 입출력 시간에서 배제하기도 함
디스크 액세스 시간과 디스크 입출력 응답 시간
디스크 액세스 시간(disk access time)
- 디스크가 명령을 받은 후, 목표 섹터에 접근하여 읽거나 쓰기까지 걸리는 시간
디스크 액세스 시간 = 탐색 시간 + 회전 지연 시간 + 내부 전송 시간
디스크 입출력 응답 시간(disk I/O response time)
- 호스트나 응용프로그램 입장에서 디스크 입출력에 걸리는 전체 시간
디스크 입출력 응답 시간 = 탐색 시간 + 회전 지연 시간 + 전체 전송 시간 + 오버헤드- 디스크의 캐시에 요청된 섹터가 있는 경우, 내부 전송 과정 없이
바로 디스크 캐시에서 호스트로 전송하기 때문에 가변적
디스크 액세스 시간의 정의
-
디스크 액세스 시간에서 전송 시간을 뺀
탐색 시간과 회전 지연 시간만으로 정의하기도 함 -
혹은 디스크 입출력 응답 시간을 단순히 디스크 액세스 시간이라고 부름
탐구 12-1 평균 디스크 액세스/응답 시간 계산
- 평균 디스크 탐색 시간: 5ms
- 디스크의 회전 속도: 10000rpm
- 섹터 크기: 512바이트
- 트랙당 섹터 수: 1000개
- 디스크 장치와 호스트 사이의 인터페이스 전송 속도: 100MB/s
- 디스크 장치의 오버헤드: 0.1ms
평균 디스크 액세스 시간 = 평균 탐색 시간 + 평균 회전 지연 시간 + 내부 전송 시간
디스크의 1회전 시간 = 60초 x 1000(ms 변환) / 10000 = 6ms
디스크의 평균 1회전 시간 = 6ms / 2 = 3ms
내부 전송 속도 = 1000 x 0.5KB / 6ms = 500KB/6ms
= 83.3KB/ms = 83.3KB / 1000(MB 변환) x (1000 초 단위 변환)
= 83.3MB/초
1 섹터를 읽는데 걸리는 내부 전송 시간 = 0.5KB / (83.3MB/초) = 0.006ms
평균 디스크 액세스 시간 = 5ms + 3ms + 0.006ms = 8.006ms평균 디스크 입출력 응답 시간 = 8ms + 0.5KB/(100MB/s) + 0.1ms
= 8ms + 0.005ms + 0.1ms
= 8.105ms- 해당 문제는 1섹터 기준의 문제이므로 값이 매우 작기 때문에
내부/외부 전송 시간을 무시 가능하지만, 수십 섹터가 되면 무시할 수 없다.
03. 디스크 스케줄링 알고리즘
3.1 디스크 큐와 디스크 스케줄링
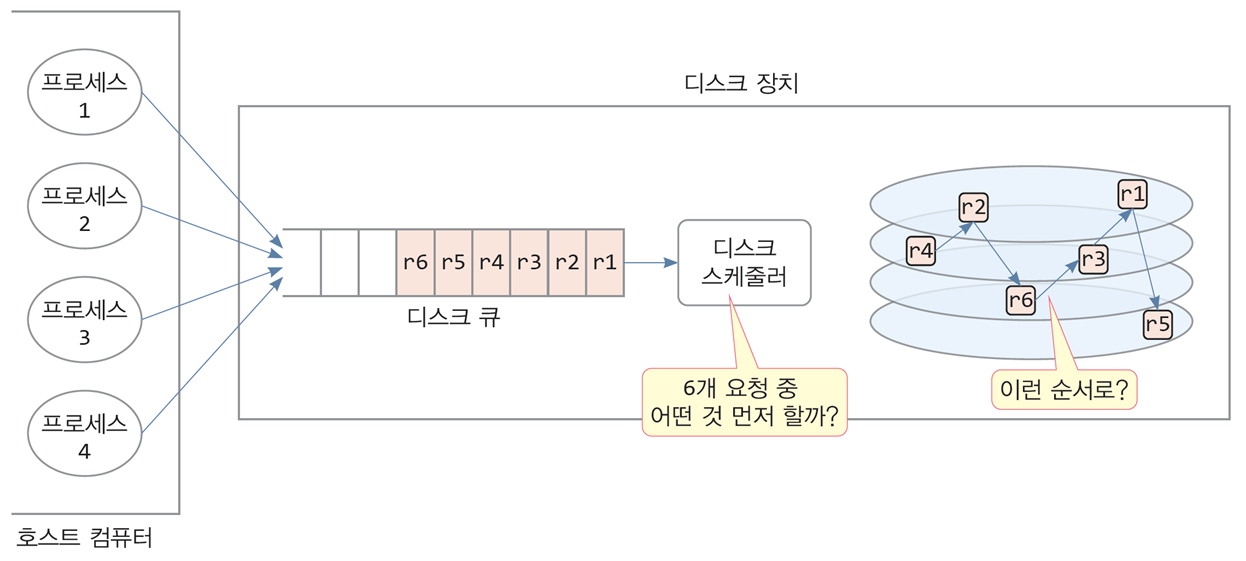
-
디스크 큐에는 디스크 입출력 명령들이
여러 프로세스나 스레드로부터 동시 다발적으로 도착하거나,
하나의 프로세스로부터 연속적으로 도착
후자의 경우 한 파일을 순차적으로 읽는 경우 -
디스크 큐에 들어 있는 입출력 요청들의 요청 실린더는
중구난방으로 예상되므로, 도착 순서대로 처리하기보다
디스크 헤드의 현재 위치와 목표 실린더의 위치를 고려하여 처리
해당 방법으로 순서를 재조정하는 디스크 스케줄링 기법 필요
3.2 디스크 스케줄링의 목표
-
디스크 스케줄링의 기본 목표는
디스크 암이 움직이는 평균 탐색 거리를 최소화하는 것
평균 디스크 탐색 시간과 평균 디스크 액세스 시간을 줄이는 것 -
디스크 장치 내 프로세서는 디스크 입출력 요청을 받으면
CHS 물리 주소로 변환하여 디스크 큐에 저장 -
평균 탐색 거리를 최소화하는 동시에
입출력 요청들의 응답 시간 편차를 최소화하는 것도 고려
3.3 디스크 스케줄링 알고리즘
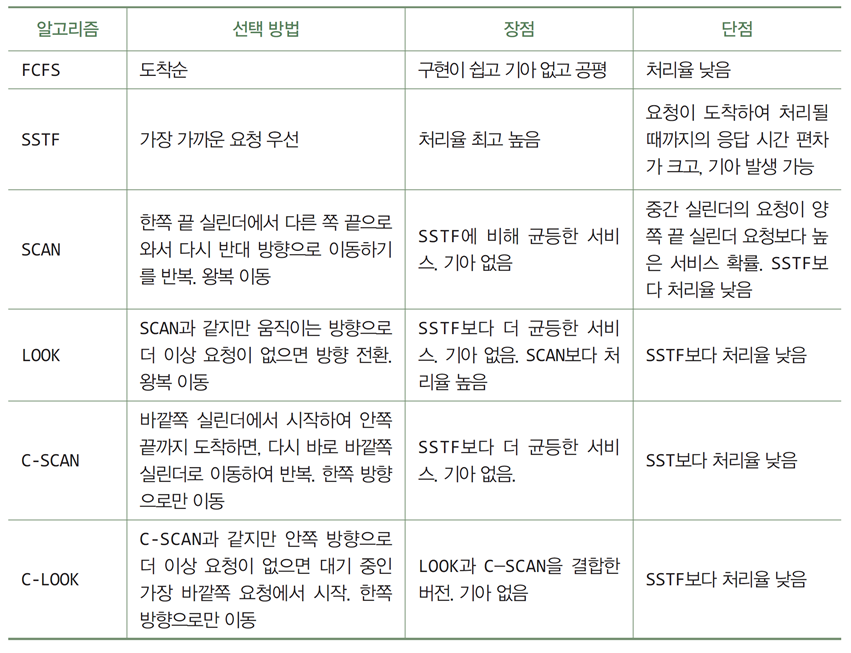
- FCFS
- SSTF
- SCAN
- LOOK
- C-SCAN
- C-LOOK
- 디스크 스케줄링 알고리즘을 평가하는 기준은 평균 탐색 거리
총 탐색 거리 / 입출력 요청의 개수
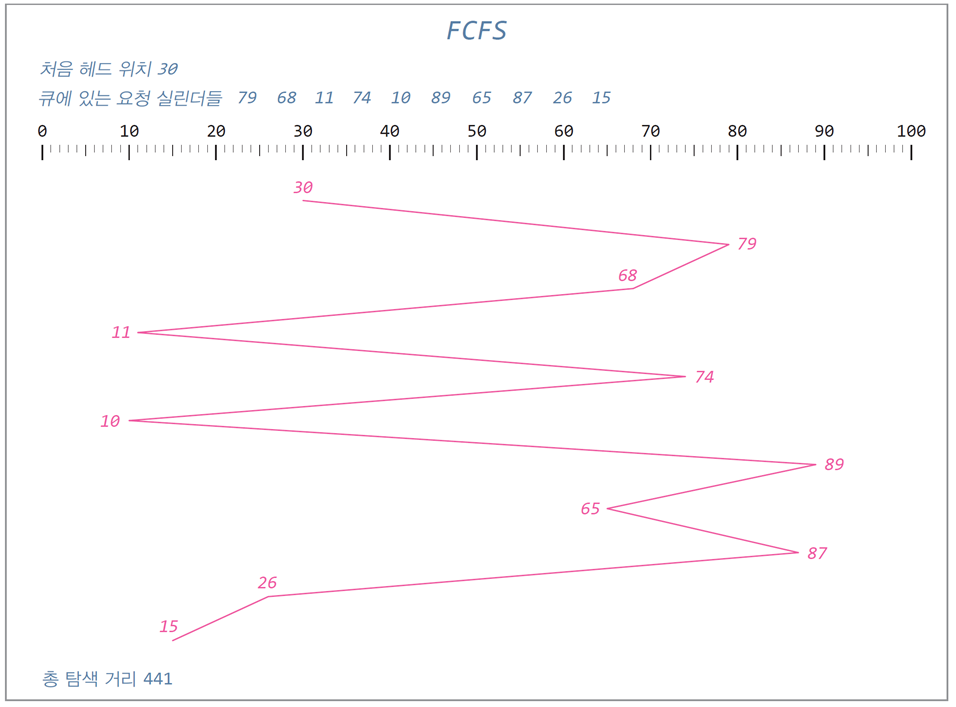
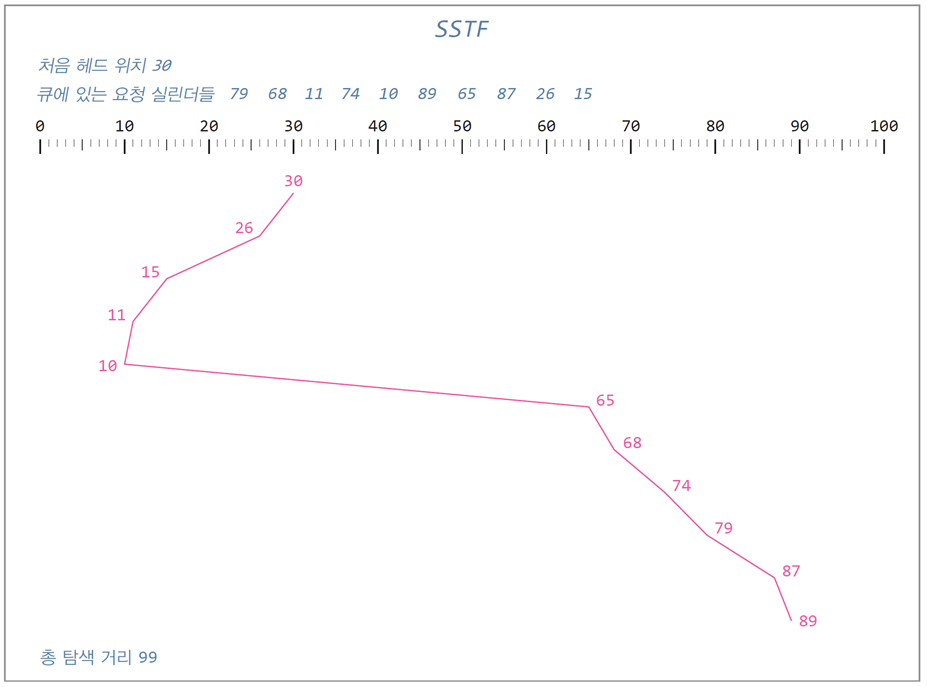
처음 디스크 헤드 위치: 실린더 30
요청 실린더들: 79, 68, 11, 74, 10, 89, 65, 87, 26, 15
FCFS(First Come First Served)
-
디스크 큐에 도착한 순서대로 요청들을 처리
-
디스크 큐 전체를 검색할 필요가 없어
구현이 쉽고, 기아가 발생하지 않으며 공평함 -
요청 실린더들의 위치를 고려하지 않기 때문에 성능이 나쁨
SSTF(Shortest Seek Time First)
-
현재 디스크 헤드가 있는 실린더에서 방향에 관계없이 가장 가까운 요청 선택
-
기아가 발생할 수 있으며, 중간 범위의 실린더에 요청이 많은 경우
양 끝쪽 실린더는 오래 대기할 수 있음 -
요청이 도착하여 응답하기까지의 편차가 큼
SCAN
-
한쪽 실린더 끝에서 다른 쪽 실린더로 방향을 정한 후,
그 방향으로 있는 요청들을 처리하면서 이동 -
엘리베이터(elevator) 알고리즘이라고도 부름
-
SSTF에 비해 입출력 요청이 균등하게 처리됨
높은 처리율보다 입출력 요청을 공평하게 스케줄링하고자 하는 경우
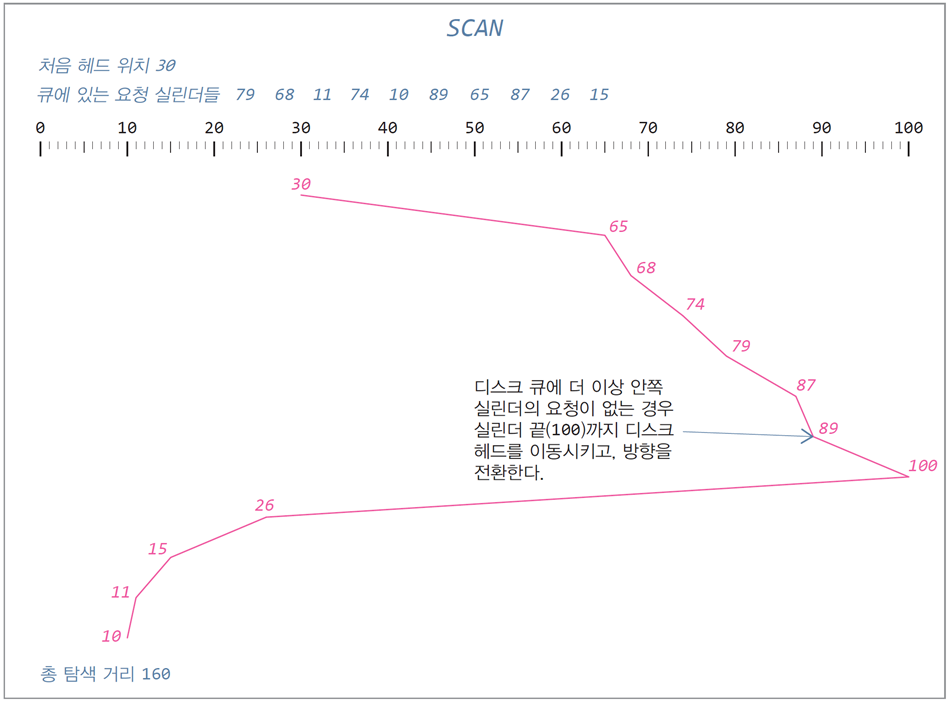
- 실린더 끝까지 이동 후 방향 전환
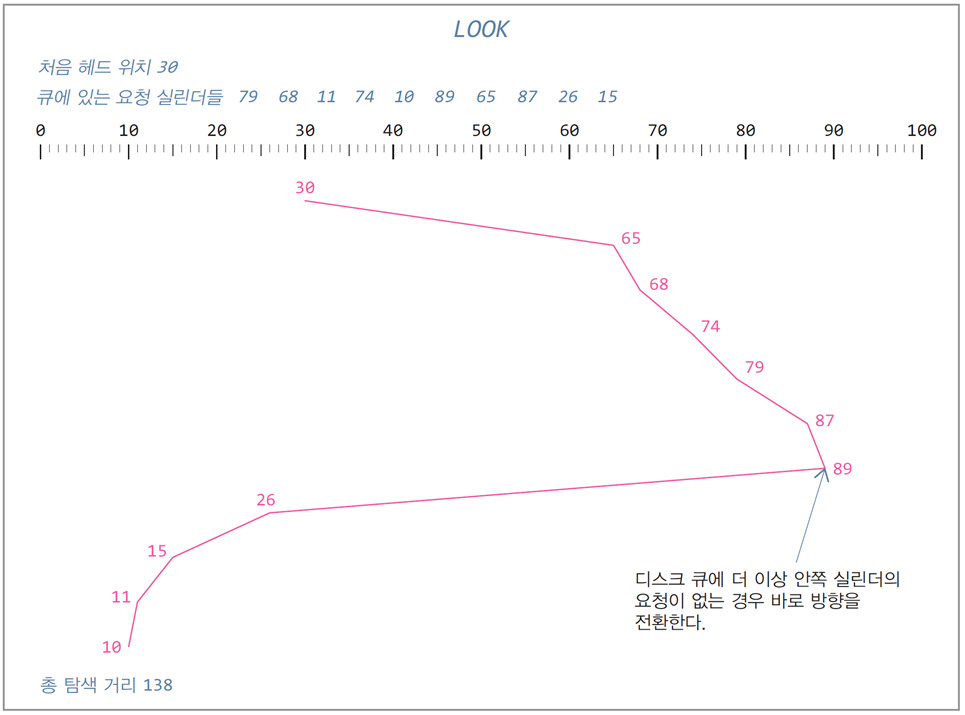
LOOK
- SCAN과 같이 작동하지만, 현재 이동 방향으로 더 이상의 요청이 없는 경우
실린더 끝까지 가지 않고 즉시 이동 방향을 바꿈
대기 중인 요청이 없음에도 불구하고 맨 끝 실린더까지 이동하는
SCAN의 단점을 보완
C-SCAN(Circular SCAN)
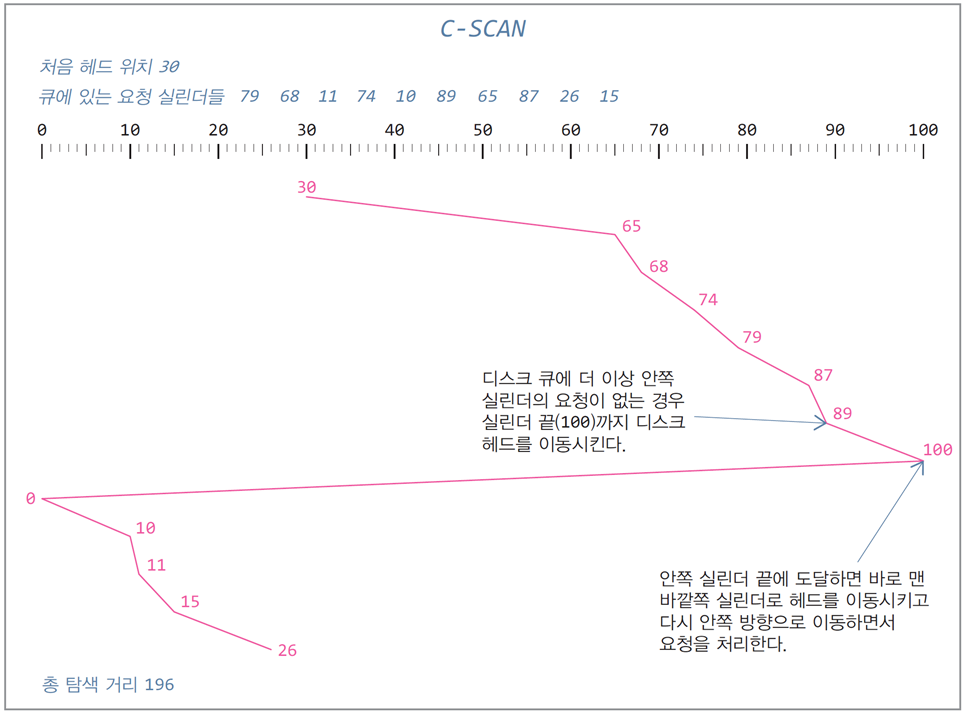
-
SCAN의 수정 버전으로, SCAN보다 더 균등한 서비스를 위해 보완된 알고리즘
-
맨 바깥쪽 실린더에서 맨 안쪽 실린더로
한 방향으로만 이동하면서 요청을 처리 -
SCAN의 경우 중간 실린더에 위치한 요청들이 선택될 확률이 높음
요청 실린더 위치에 따라 서비스가 균등하지 않음 -
바깥쪽으로 더 이상 요청이 없어도
실린더 끝까지 헤드를 이동시키는 비효율성
C-LOOK
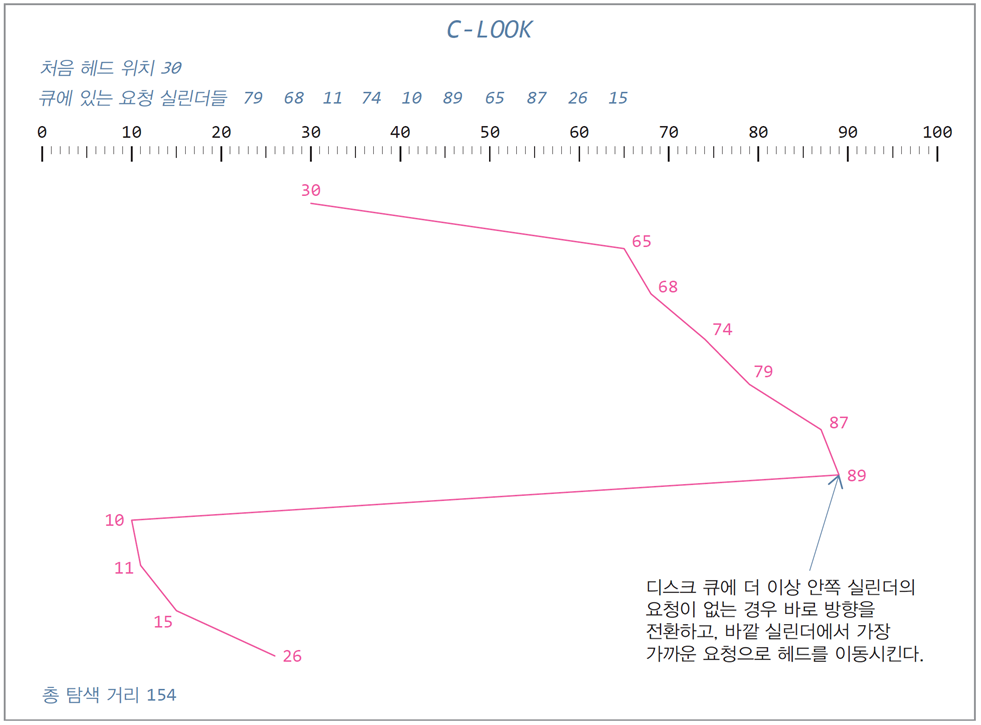
-
LOOK + C-SCAN
-
요청이 없어도 디스크 헤드를 끝 실린더로 이동시키는 C-SCAN의 단점 보완
-
이동하는 방향으로 요청이 없는 경우
바로 바깥쪽 실린더에서 가장 가까운 요청으로 한 번에 이동
디스크 알고리즘 성능 비교

디스크 알고리즘 특성 비교
디스크 스케줄링에 대한 최근 경향
-
SSD(Solid State Disk)의 사용이 늘어나고 있어
디스크 스케줄링은 과거보다 덜 중요해짐 -
SSD는 디스크 장치와 달리
헤드를 움직이는 모더와 기계 장치가 없는 반도체식 기억 장치
탐색과 회전 지연 시간이 없어 디스크 스케줄링이 필요하지 않음
04. 디스크 포맷
4.1 저수준 포맷팅(LLF, Low Level Formatting)
-
하드 디스크의 플래터에 트랙과 섹터를 구분하는 정보를 기록하여
디스크 헤드가 섹터와 트랙을 인식할 수 있게 하는 작업 -
초기에는 하드 디스크 사용자가 직접 저수준 포매팅 진행
-
디스크 용량이 증가함에 따라, 디스크 밀도가 높아지고
일반 사용자가 하기 힘들어지며 공장에서 저수준 포맷이 된 채로 출시됨 -
공장에서 저수준 포맷이 된 채로 출시되기 때문에
저수준 포맷을 하는 상용 소프트웨어들은
디스크에 기록된 정보를 모두 지우는 제로필(zero fill) 작업만 진행 -
저수준 포맷팅은 섹터 크기에 따라
512 바이트 섹터 포맷과 4K 포맷(4096바이트 섹터 포맷)으로 나뉨
512바이트 섹터 포맷
- 과거 플로피 디스크나 하드 디스크에서 전통적으로 사용
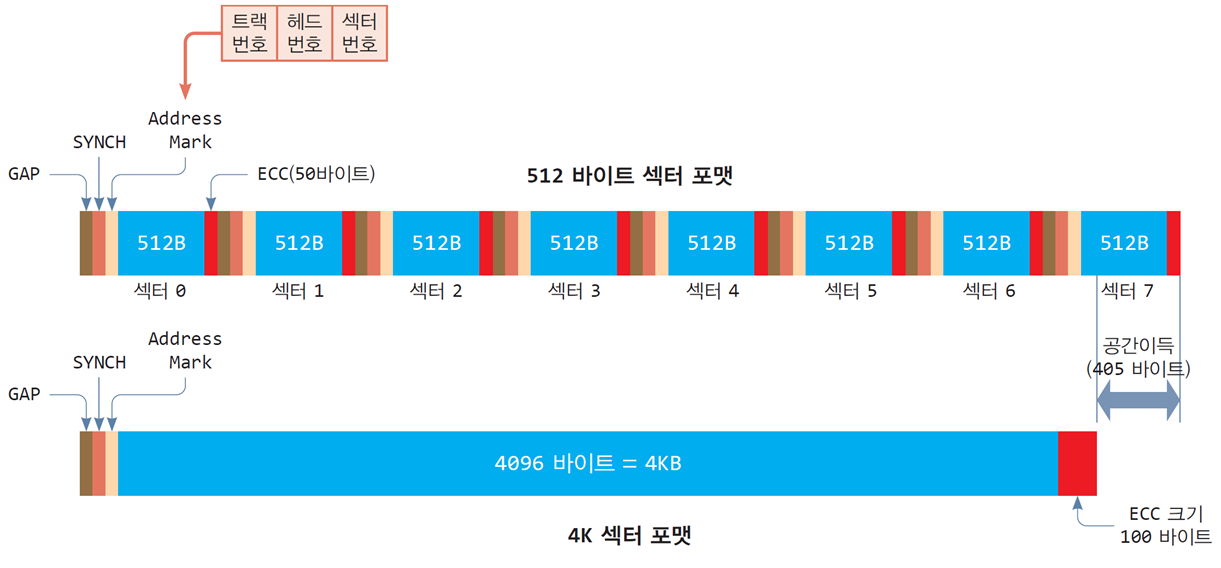
GAP
다음 섹터를 읽기 전 플래터가 회전하는 동안
디스크 헤드가 준비하는 약간의 시간을 벌기 위해 삽입된 공간
SYNCH
디스크 헤드가 GAP의 끝을 인식하도록 약속된 코드
Address Mart
섹터의 물리적 주소가 새겨지는 공간
[트랙 번호, 헤드 번호, 섹터 번호]
512바이트의 섹터 공간
ECC(Error Correction Code)
읽거나 쓰는 과정에서
손상된 섹터의 복구나 교정을 위해 추가 기록되는 데이터
4K 포맷
-
기존의 8개의 섹터를 하나의 섹터로 만든 것
-
고급 포맷(Advanced Format) 혹은 4K 섹터 포맷
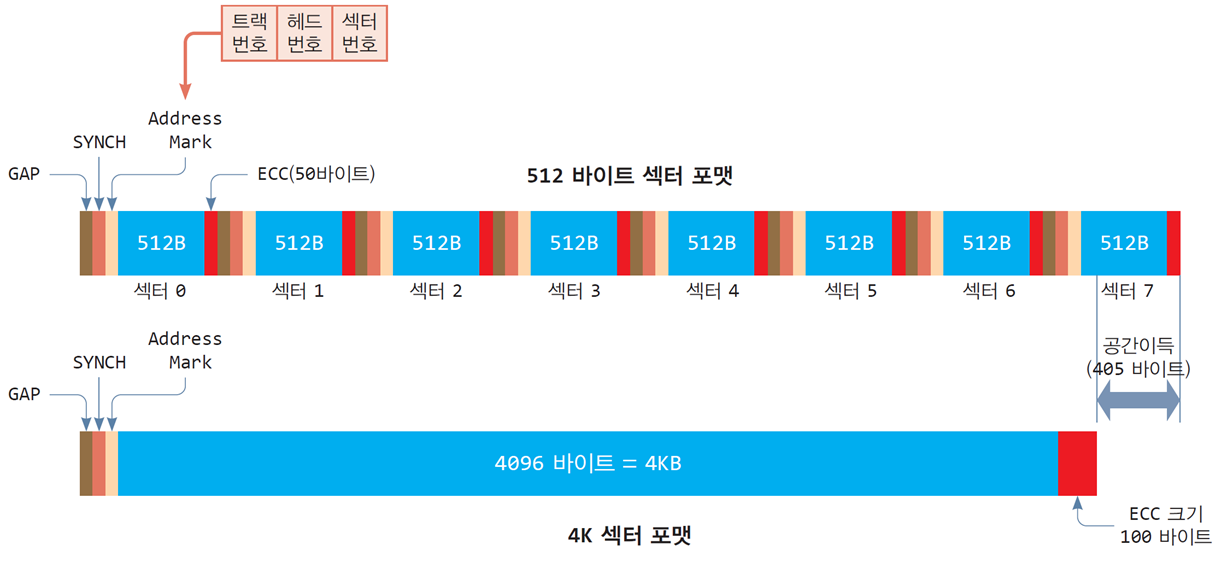
디스크의 저장 효율 향상
- 4KB당 405바이트의 저장 공간 이득을 볼 수 있음
오류 수정 능력을 대폭 향상
- ECC를 4KB당 하나만 두는 것으로 하는 대신
기존 50바이트의 ECC를 100바이트로 늘림
디스크 입출력 성능 향상
-
현대의 응용프로그램의 크기가 커짐에 따라 4KB 단위의 입출력이 효율적
-
가상 메모리 체제에서의 페이지 크기가 4KB
가상 메모리 크기와 섹터 크기를 맞춤에 따라 섹터 위치 계산이 편해짐
과거부터 사용하던 512바이트 버퍼를
4K 섹터 디스크 컴퓨터에서 실행 시 문제가 발생함
-
4K 섹터로 포맷된 디스크 장치들 중에는
물리적으로는 한 섹터를 4K 단위로 읽고 쓰지만
호스트에게는 한 섹터가 512바이트인 것처럼 보이도록 함-emulate -
이러한 4K 디스크를 512 에뮬레이션 디스크 장치 혹은 512e라고 부름
읽기 요청 시, 4K 섹터를 물리적으로 읽고 그 중 요청된 512 바이트를 전송
TIP 불량 섹터(bad sector)
- 하드 디스크의 플래터에 결함이 발생하여 읽고 쓸 수 없는 섹터
물리적 불량 섹터
-
디스크 헤드의 플래터 직접 접촉이 원인
-
SSD의 경우 저장 셀(cell)의 노후화
-
하드 디스크는 제조 과정에서 발생할 수 있음
-
물리적 불량 섹터는 고칠 수 없음
논리적 불량 섹터
-
섹터를 기록하는 도중에 갑작스럽게 컴퓨터가 꺼지는 경우 발생
-
섹터에 기록된 코드와 ECC(오류 정정 코드)의 불일치
디스크 장치가 불량 섹터로 처리 -
기록된 정보의 손실은 일어날 수 있으나 수리 과정을 통한 재사용 가능
불량 섹터의 관리 주체
-
1990년대 이전, 여분 섹터가 존재하지 않아,
운영체제가 파일 시스템을 통해 관리 -
운영체제의 파일 시스템에 의해 관리되지 않고,
디스크 장치의 펌웨어에 의해 관리됨 -
디스크 장치는 불량 섹터 리스트, 여분의 온전한 섹터(spare sectors)를 가짐
-
불량 섹터 발견 시, 스스로 여분 섹터로 매핑시켜
운영체제는 불량 섹터에 대해 알지 못함
4.2 고수준 포맷팅(HLF, High Level Formatting)
-
저수준 포맷된 하드 디스크를 여러 개의 파티션(논리적인 공간)으로 나누고,
각 파티션에 파일 시스템을 구축하는 과정 -
디스크의 저장 공간을 파티션(partition)으로 분할하는 과정부터 시작
-
디스크에는 여러 개의 파티션을 둘 수 있으며,
파티션마다 서로 다른 운영체제를 선택할 수 있음
단, 부팅은 그 중 한 파티션에서만 이루어짐 -
디스크를 포맷하고 파티션 나누는 방법은 두 방식이 있음
MBR/GPT 포맷
MBR 포맷 - 전통 방식
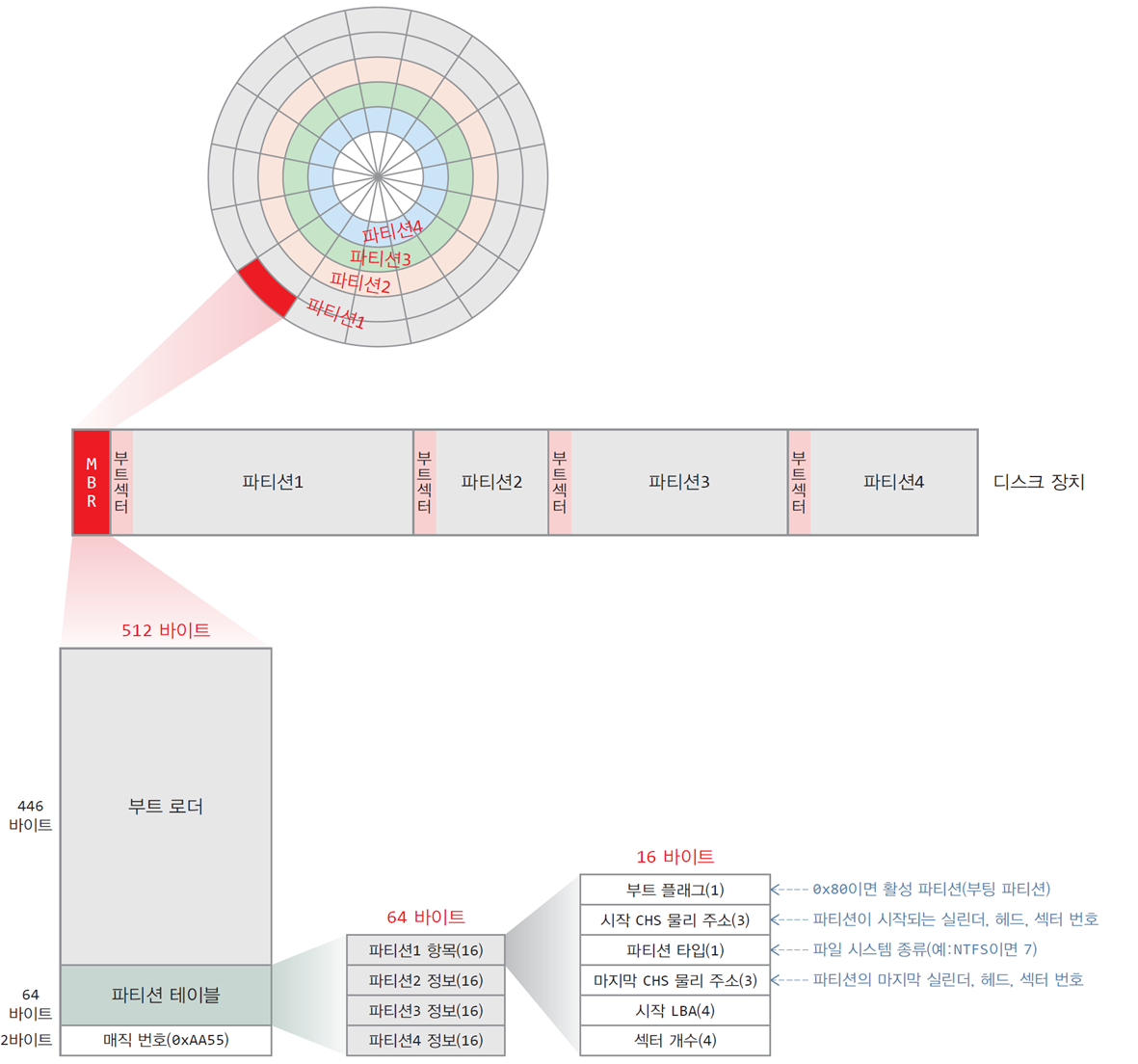
- 파티션에 관한 정보는 부트 섹터에 기록됨
이 부트 섹터를 MBR(Master Boot Record)이라고 하며, 크기는 512바이트
MBR의 구성
-
부트 로더
446바이트로 부팅시 실행되는 프로그램 -
파티션 테이블
64바이트로 최대 4개의 파티션 정보 기록. 각 파티션 정보는 16바이트 -
매직 번호
2바이트 크기로0xAA55값 기록.0xAA55가 아니면 MBR이 아니라고 판단
-
파티션을 나누지 않았을 때에는 파티션이 1개만 있는 것
파티션 테이블에도 1개만 유효함 -
부팅이 시작되면 MBR에 저장된 부트 로더 프로그램이 메모리에 적재/실행됨
-
파티션 테이블을 검사하여 현재 부팅할 운영체제를 담고 있는
활성 파티션(active partition)을 찾음
이후 활성 파티션의 부트 섹터를 메모리에 적재시키고 코드를 실행 -
파티션 개수가 제한적이고 파티션 정보에서 섹터 개수를 나타내는 비트가 32
한 파티션이 2개의 섹터까지 가능
한 섹터의 크기가 512바이트이면, 2 x 0.5K = 2TB가 파티션의 최대 크기 -
4K 섹터 디스크의 경우, 섹터 크기가 8배이므로
파티션의 크기가 16TB까지 가능 -
그러나 MBR 포맷 사용 시,
섹터 크기를 512바이트로 다루고 있기 때문에 파티션의 크기가 2TB로 고정됨
MBR 방식의 단점은 파티션의 크기가 2TB로 제한되며 부팅 속도가 느림
GPT(GUID partition table) 포맷 - 현대 방식
-
UEFI(Unfixed Extensible Firmware Interface) 펌웨어를 가진
컴퓨터에서만 사용하는 포맷 방식 -
2TB 이상의 파티션을 만들 수 없는 MBR의 문제점을 개선
-
최근에 나온 대부분의 컴퓨터는 UEFI 펌웨어를 내장하고 있기 때문에
MBR 포맷이나 GPT 포맷 중 선택하여 사용할 수 있음
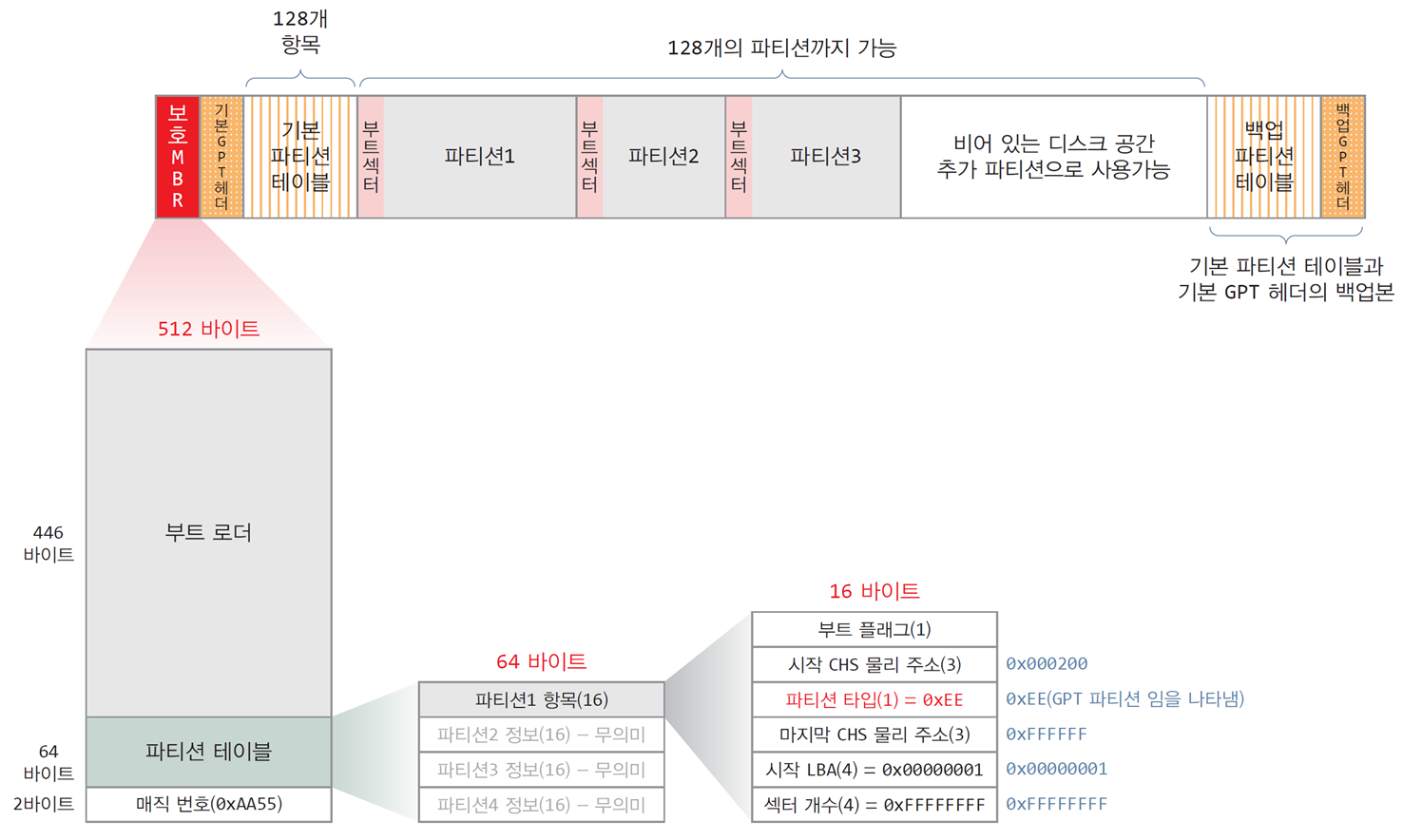
1) 보호 MBR 섹터가 첫 번째 섹터에 있는 이유
-
GPT 포맷 디스크를 MBR 포맷 디스크로 보이게 하려는 목적
사용자가 GPT 포멧 디스크에 MBR 포맷만 다루는 유틸리티를 실행했을 때,
이 유틸리티가 현재 디스크에 훼손이 발생한 것으로 오인하여
디스크를 포맷하거나 훼손하는 등의 오작동을 막기 위함 -
보호 MBR 섹터의 구조를 MBR 포맷의 첫 섹터와 동일하게 구성
-
파티션 테이블의 첫 번째 항목의 섹터 개수를 최대치(
0xFFFFFFFF)로 기록
전체 디스크를 모두 사용하고 있다고 착각하게 만듦 -
보호 MBR은 MBR 포맷과의 호환성은 유지하면서
MBR 포맷만 지원하는 유틸리티가 GPT 포맷 디스크를 잘못 인식하여
덮어쓰는 것을 방지하기 위함
2) MBR 섹터의 파티션 테이블에서
첫 번째 파티션 항목의 파티션 타입 필드 값을 0xEE로 기록
- GPT 포맷을 다루는 소프트웨어들에게
현재 디스크가 GPT 포맷임을 나타내기 위해
3) 진짜 파티션 테이블은 GPT 헤더 다음에 구성됨
-
총 128개까지 파티션이 가능
한 파티션의 크기는 18엑사바이트(Exa Byte)까지 가능 -
GPT헤더의 구성 요소
파티션 테이블의 개수
파티션 테이블이 시작하는 디스크의 위치
각 항목의 크기
파티션 테이블 항목 개수
파티션 테이블의 오류 확인을 위한 체크섬(checksum) 정보 등
4) GPT 헤더와 파티션 테이블을 이중화
- GPT 헤더와 파티션 테이블은 디스크의 마지막 영역에 백업본을 둠
기본 GPT 헤더와 파티션 테이블이 손상될 때 복구 가능-높은 신뢰도
MBR 포맷 디스크의 부팅
- UEFI를 지원하지 않는 컴퓨터 디스크는 MBR 포맷으로 포맷팅되어야 하며,
기존 BIOS 펌웨어에 의해 부팅됨
1) 전원이 켜지면 CPU는 BIOS 펌웨어 코드의 실행을 시작하여
메모리나 기타 장치들을 테스트하고 초기화
2) BIOS 안에 작성된 부트스트랩 코드를 실행
3) 부트스트랩 코드는 하드 디스크의 첫 번째 섹터인
MBR 섹터를 메모리로 읽어들이고 그곳으로 점프
MBR 섹터의 첫 번째 부분에 부트 로더가 작성되어 있음
4) CPU가 이 코드를 실행하면 활성 파티션을 찾고
활성 파티션의 부트 섹터를 메모리로 읽어들이고 실행시킴
5) 부트 섹터의 코드는 자신의 파티션에 설치된 운영체제 커널을 메모리로 적재
6) 커널로 제어를 넘기고, 커널 코드로 점프하여
커널 코드를 실행하면 필요한 프로세스가 생성됨
GPT 포맷 디스크의 부팅
1) 전원이 켜지면 컴퓨터에 장착된 UEFI 펌웨어가 실행됨
2) UEFI 펌웨어에 저장된 EFI 변수를 읽음
EFI 변수에는 부팅 순서, 부트 로더의 경로명 등 부팅에 관한 정보가 저장됨
3) 기본 파티션 테이블에서 EFI 시스템 파티션 탐색
-
EFI 파티션은 FAT32로 포맷된 특별한 파티션
권장 크기는 100~550MB -
이 파티션 안에 디스크에 설치된
모든 운영체제들의 부트 로더 프로그램이 저장되어 있음
4) UEFI 펌웨어는 EFI 변수에 지시된 부팅 순서에 따라
EFI 파티션에서 부트 로드 프로그램을 찾아 실행
5) 부트 로더 프로그램은 해당 운영체제를 메모리에 적재한 후
커널 코드로 점프하여 커널 코드에 의해 프로세스 생성
BIOS와 UEFI 펌웨어
-
BIOS(Basic Input Output System)나 UEFI는
컴퓨터 마더보드(mother board 또는 main board)에 장착된
ROM(BIOS의 경우)이나 플래시 메모리와 같은
비휘발성 메모리에 저장된 소프트웨어 -
전원이 켜지는 시점에 실행되는 최초의 프로그램
-
컴퓨터 메모리나 하드웨어들을 테스트하고 초기화하며 컴퓨터를 부팅시킴
-
UEFI는 운영체제와 마더보드나
주변 장치 내에 장착된 펌웨어 사이의 매개 역할 -
실질적으로 장치들과 입출력 버스 등을 제어하는
마더보드 펌웨어 위에서 실행되는 작은 운영체제 -
과거 BIOS를 레거시 BIOS라고 하는게 좋음
UFEI와 BIOS를 구분하지 않기 때문
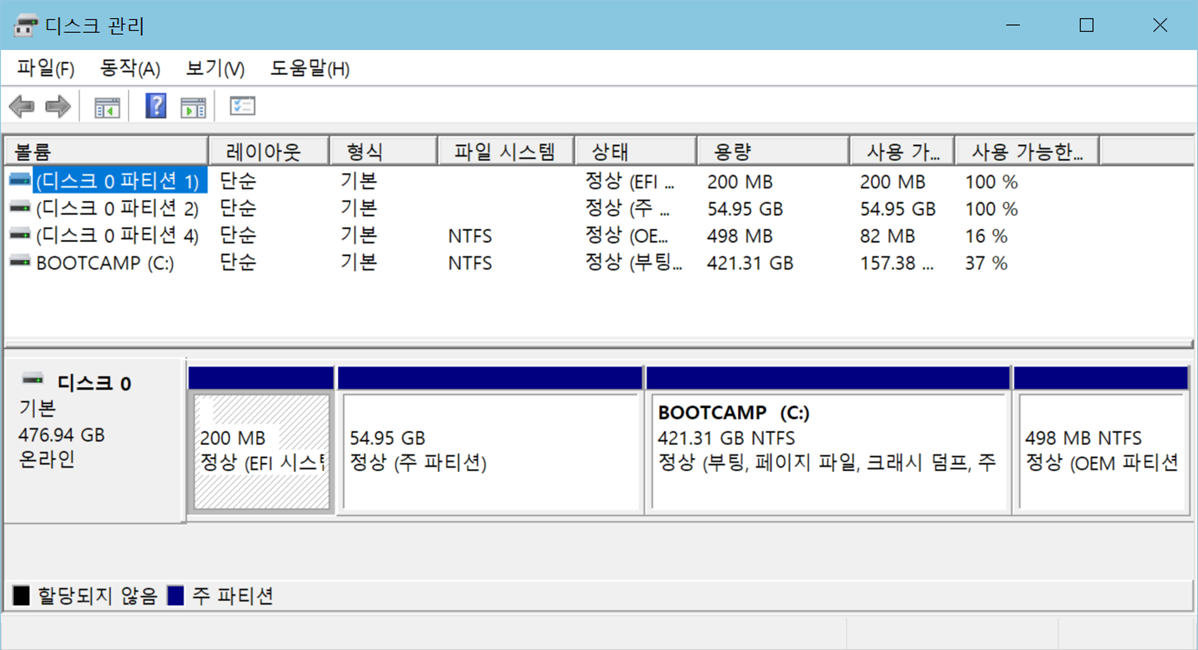
Windows에서 파티션 나누고 사용하기
- D:, E: 등의 논리 드라이브로 사용
- 복구 파티션(recovery partition)
- 진단 도구나 진단 데이터를 저장하는 파티션
리눅스에서 파티션 나누고 활용하기
- 리눅스, MacOS 등 Unix-like 운영체제에서 각 디스크 파티션에는
파일 시스템이 구축되거나 파티션이 통째로 스왑 영역으로 사용됨
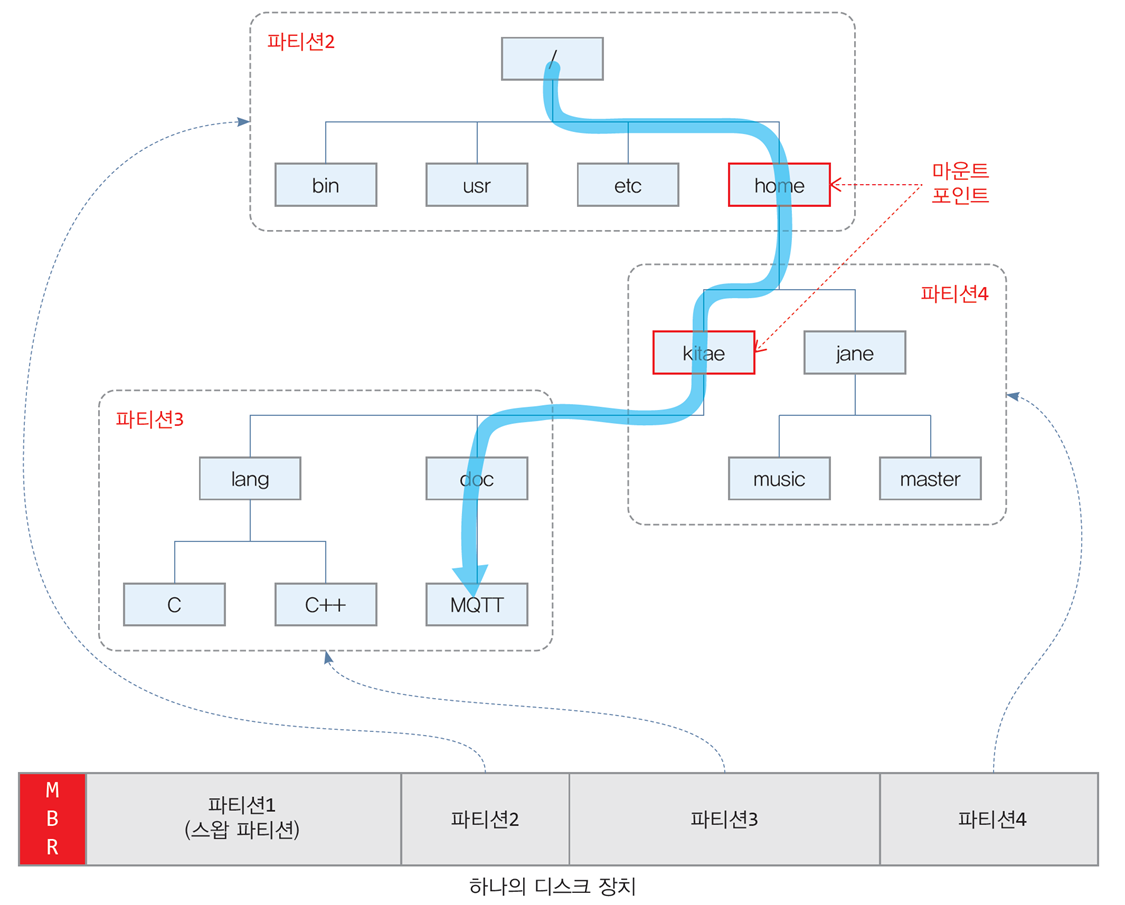
-
많은 경우 파티션을 디렉터리에 연결하여
전체를 하나의 파일 시스템으로 사용
이 것을 마운트(mount) 라고 함 -
3개의 파일 시스템을 디렉터리에 마운트시켜
전체를 하나의 파일 시스템처럼 사용 -
다른 파티션에 연결하기 위해 사용되는
home이나kitae디렉터리를
마운트 포인트(mount point)라고 함
마운트 포인트는 다른 파티션에 설치된 파일 시스템의 루트 디렉터리가 됨
05. SSD 저장 장치
-
SSD(Solid State Drive, Solid State Disk)는
플래시 메모리(flash memory)를 저장소로 사용한 비휘발성 기억 장치 -
메모리 계층 구조의 최하단에 위치하는 보조 기억 장치
-
하드 디스크와 달리 회전하는 디스크나 모터, 움직이는 헤드 등
기계 부품을 사용하지 않는 순수한 반도체 기억 장치 -
디스크보다 값이 비싸지만 입출력 속도가 5~50배 정도 빠름

5.1 SSD 장치의 구조와 인터페이스
- SSD는 4개의 하드웨어 요소로 구성됨
플래시 메모리
DRAM 캐시
호스트 인터페이스
SSD 제어기
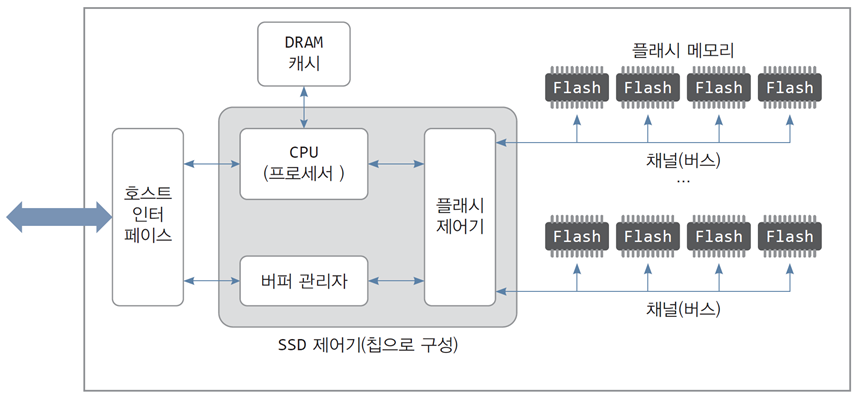
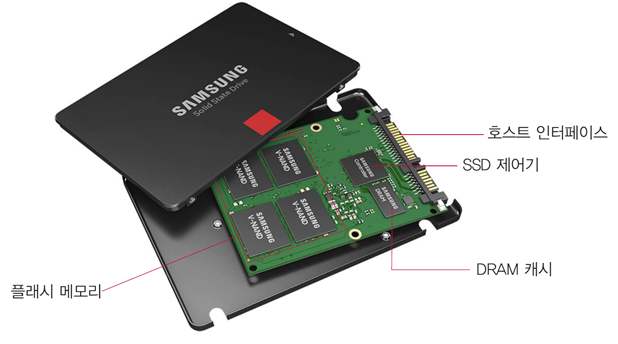
플래시 메모리
-
SSD의 내부 저장소
-
플래시 제어기에 의해 읽혀지고 기록됨
DRAM 캐시
-
입출력 성능을 높이기 위해 DRAM 캐시를 두고 있음
-
DRAM을 장착한 SSD는 상대적으로 고가
-
디스크 캐시와 비슷한 목적으로 사용되어
읽은 데이터나 쓸 데이터를 임시 저장 -
정전이 발생하면 DRAM 캐시에 들어 있는 데이터를 모두 잃음
이 때문에 DRAM을 사용하지 않는 제조업체도 있음
호스트 인터페이스 회로
-
SSD 장치와 호스트를 연결하는 물리적인 인터페이스
-
SATA(Serial ATA)
SAS(Serial attached SCSI)
PCIe(PCI express) 등의 여러 가지가 존재함 -
가장 많이 사용되는 타입은 PCIe이며,
PCIe 인터페이스를 가진 SSD를 NVMe 드라이브라고 함
SSD 제어기(SSD Controller)
-
SSD 장치에서 가장 중요한 부분
-
호스트로부터 받은 데이터를 플래시 메모리에 기록하고
플래시 메모리로부터 읽은 데이터를 호스트로 전송
전반적인 작업을 제어함 -
논리 블록 주소를 물리 블록 주소로 바꾸는 매핑 테이블을 만들고 관리
-
논리 주소의 물리 주소 변환
-
wear leveling와 같은
플래시 메모리에서 새로운 페이지를 저장할 장소 찾기나
garbage collection 등의 기능을 수행함 -
SSD 제어기는 하나의 칩(SoC, System on Chip)으로 만듦
-
SSD 제어기 내부 플래시 메모리 알고리즘은 SSD 제조업체의 경쟁력
공개하지 않고 있음
5.2 SSD 메모리의 논리 구조
페이지와 블록
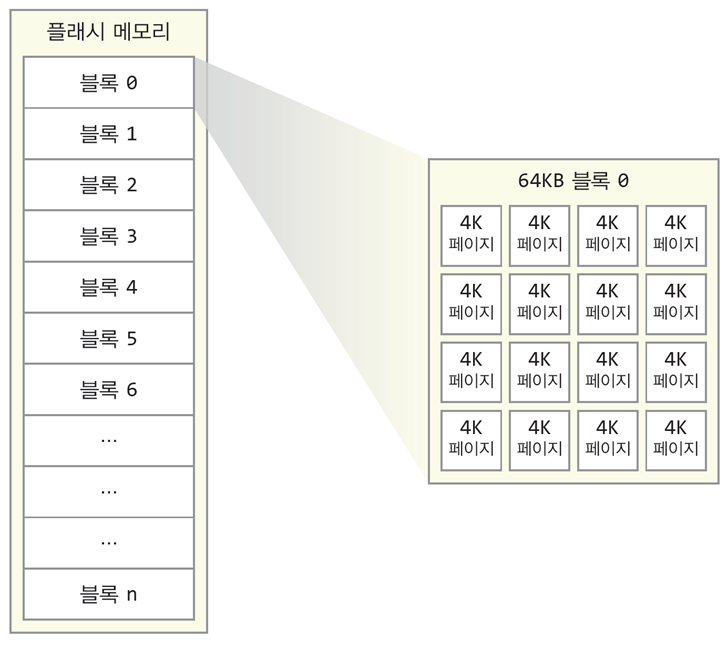
- 플래시 메모리는 여러 개의 블록들로 구성되며
각 블록은 다시 페이지(page)들로 구성됨
SSD 장치 내에서 플래시 메모리에 읽고 쓰는 단위는 페이지
-
플래시 메모리의 페이지는
운영체제의 가상 메모리에서 다루는 페이지와는 아무런 관계가 없음 -
응용프로그램이 한 바이트를 읽거나 쓰고자 했어도, 페이지 단위로 읽고 씀
-
페이지 크기는 보통 4KB~16KB, 블록 크기는 128KB~256KB
공정 기술이 발전함에 따라 크기도 커지는 추세 -
하드 디스크와 달리,
블록이나 페이지의 위치에 따라 액세스 하는 시간이 다르지 않음
주소 변환
-
운영체제의 파일 시스템은 SSD를 디스크 장치로 인식
-
SSD에 대해서도 똑같이 액세스하고자 하는 데이터의
논리 블록 번호(LBA) 발생 -
플래시 메모리에 저장된 각 논리 블록에 대해
플래시 메모리의 블록 번호와 페이지 번호를 나타내는
주소 변환 테이블을 만들고 유지 및 관리
블록 읽기/쓰기 시 주소 변환 테이블 참조
5.3 SSD의 플래시 변환 계층
-
하드 디스크를 기반으로 하는 운영체제의 파일 시스템은
디스크를 섹터 단위로 인식함 -
SSD에서는 페이지 단위로 인식함
섹터를 기반으로 하는 기존 파일 시스템은 SSD를 읽고 쓸 수 없음
-
이를 해결하기 위해 SSD 제어기 내에
플래시 변환 계층(FTL, Flash Translation Layer)이라는 펌웨어를 둠 -
플래시 변환 계층은 SSD 내부의 물리적 특성을
운영체제로(파일 시스템)부터 숨김
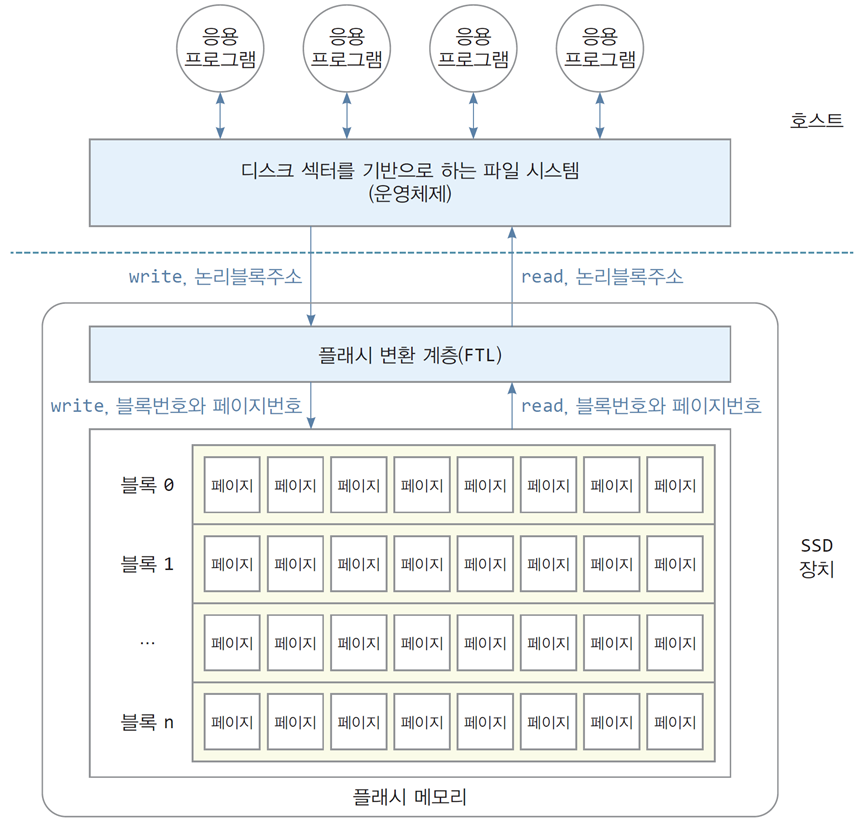
-
플래시 변환 계층은 운영체제의 파일 시스템에게
SSD가 섹터 기반의 저장소로 보이게 함 -
하드 디스크와 달리 SSD에서는
논리 블록이 저장된 물리 페이지 주소와 함께 주소 변환 테이블도 계속 바뀜
특이한 페이지 쓰기 방식과 가비지 컬렉션 때문 -
주소 변환 테이블은
SSD 제어기의 내부 메모리(RAM)과 SSD 플래시 메모리에 저장됨
작동을 시작할 때 플래시 메모리로부터 내부 메모리로 읽어 들임
SSD의 용량이 커지면 주소 변환 테이블도 같이 커지는 약점 존재
5.4 SSD 입출력 동작
페이지 읽기(read)
- 플래시 메모리에서의 페이지 읽기는 단순히 해당 페이지를 읽기만 하면 됨
페이지 쓰기/프로그램(write/program)
-
플래시 메모리에 쓰기를 프로그램(program)이라고 부름
-
동일한 페이지에 덮어쓰기는 불가능하며,
오직 빈 페이지에만 쓸 수 있음 -
SSD가 빈 페이지를 찾고 그 곳에 데이터를 기록
-
빈 페이지를 만들기 위해서는 지우기 연산이 이루어져야 함
-
이미 기록된 페이지를 수정하는 경우 read-modify-write 연산을 실행
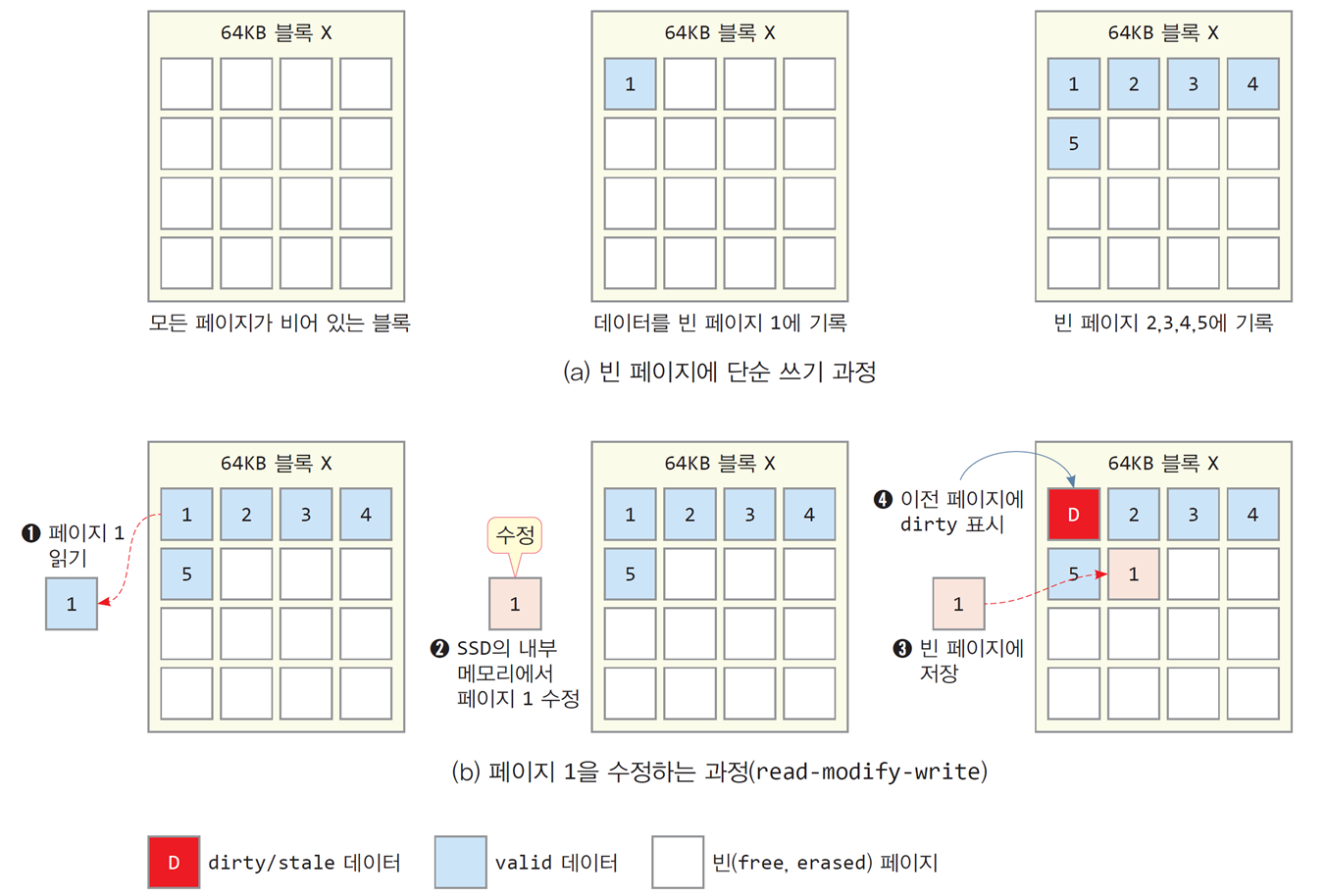
1) 페이지 읽기(read) - SSD 제어기의 메모리로 페이지 읽어 들이기
2) 페이지 수정(modify) - SSD 제어기의 메모리에서 페이지 수정
3) 페이지 쓰기(write) - 수정된 페이지를 새로운 빈 페이지를 찾아 기록
4) 플래시 메모리의 이전 페이지를 dirty 또는 stale로 표시
-
플래시 메모리는 쓰기와 지우기 횟수에 제한이 있기 때문에
특정 블록에 작업이 반복되면 블록의 수명이 빨리 다하게 됨 -
각 페이지에 대해 비거나,
dirty/stale, 유효한(valid)페이지 상태 정보는
SSD 제어기에 의해 따로 관리됨 -
SSD가 데이터를 읽거나 빈 페이지에 데이터를 쓰는 속도는 매우 빠르지만,
페이지를 수정하는 속도는 매우 느림
페이지를 수정하여 다시 기록할 때마다 주소 변환 테이블도 같이 수정됨 -
빈 페이지를 동일한 블록에서 찾을 필요는 없음
블록 지우기(erase)
-
플래시 메모리에서 쓰기와 지우기는 서로 다른 기능
-
플래시 메모리는 블록 단위로 데이터를 지움
높은 전압이 걸리면 주변 셀들의 값이 훼손될 수 있기 때문 -
블록 지우기는 SSD가 가비지 컬렉션을 수행할 때
빈 블록을 확보하기 위해 내부에서 벌어지는 동작
가비지 컬렉션(garbage collection)
-
블록 내 페이지들의 수정이 계속되어
dirty페이지가 많아지고 빈 페이지가 없을 때
SSD 제어기에 의해 가비지 컬렉션이 수행됨 -
값이 기록된 페이지(
valid)들을 다른 페이지들을
다른 블록의 빈 페이지로 복사하고 원본 블록들을 지우는 과정
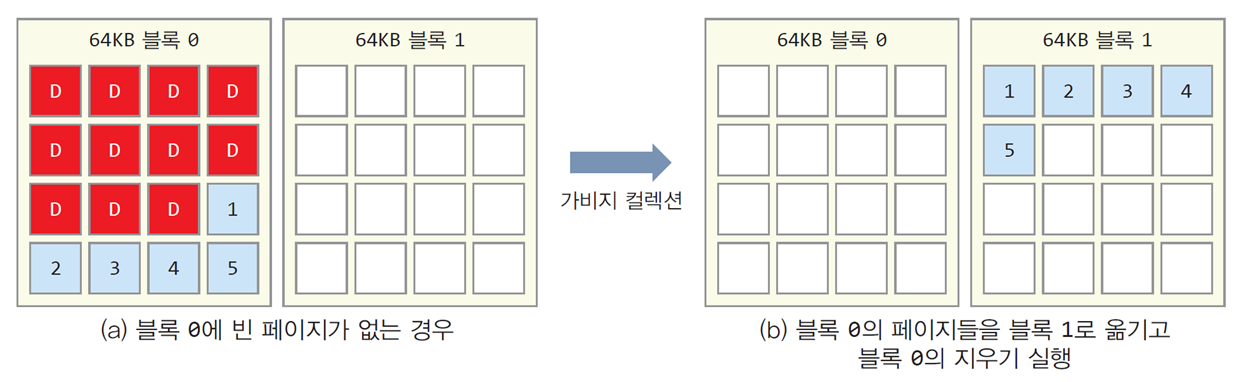
웨어 레벨링(wear leveling, 균등 쓰기 분배)
-
플래시 메모리의 모든 블록에 쓰기를 균등하게 분배하여
특정 블록에 대한 과도한 쓰기를 막음 -
플래시 메모리 블록은 쓰거나 지우기 횟수에 비례하여 닳아(wear)감
-
읽기는 영향을 주지 않고 쓰기가 영향을 줌
-
SSD 제어기는 플래시 메모리의 각 블록마다 지우기 횟수를 기억하고
쓰기 시, 지우기 횟수가 가장 적은 블록을 선택함
5.5 SSD의 용도
-
SSD의 저장소 역할을 하는 NAND 플래시는
오랜 시간 동안 전원이 공급되지 않으면 전하(charge)가 누출되어
저장된 데이터가 지워짐
백업 저장 목적에는 적합하지 않음 -
읽기가 많은 운영체제 코드나 프로그램을 설치하는 용도로는 적합하지만,
쓰기나 수정 작업이 많은 스왑 영역이나
파일이 임시로 생성되었다가 지워지는 임시 파일 시스템에 적합하지 않음
