TechSpec
Technical Specification, 기술 설계 문서
정의
-
기획된 기능을 구현하기 위해 필요한
아키텍처, 데이터 구조, 알고리즘, 인프라 구성 등을 상세히 기록한 문서 -
PRD에서 정의한 기능들을 실제로 컴퓨터가 이해하고 실행할 수 있도록 기술적인 언어로 번역해 놓은 상세 설계도
목적
- 개발 시작 전 잠재적인 기술적 문제를 파악하고,
팀원들과 구현 방향에 대한 합의를 이끌어내기 위함
주요 내용 포함
- 시스템 아키텍처(어떤 기술 스택을 사용할 것인가)
- 데이터베이스 스키마(데이터를 어떻게 저장할 것인가)
- API 명세(서버와 클라이언트가 어떻게 통신할 것인가)
- 성능 및 보안 고려 사항 등
PRD vs TechSpec 예시: 로그인 기능
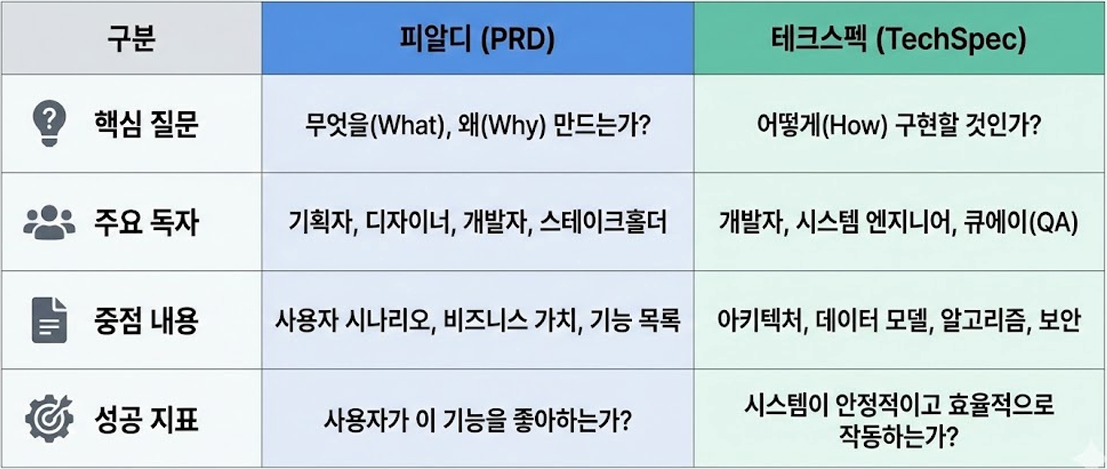
PRD
-
"무엇을 만들지"에 집중한 문서
"사용자에게 어떤 가치를 줄 것인가?" -
사용자가 우리 제품을 통해 어떤 문제를 해결할 수 있는지
그 과정에서의 사용자 경험, 즉 UI/UX가 얼마나 매끄러운지가 성공의 지표
"사용자가 이 기능을 정말 좋아하는가?" -
기획자와 디자이너 뿐만 아니라
마케팅이나 경영진 같은 다양한 이해관계자(stakeholder)들을 포함
-
비즈니스의 성공을 보장
TechSpec
-
"어떻게 구현할 것인가"에 모든 에너지를 쏟는 문서
-
철저한 엔지니어링의 관점, 기술적인 검증
"시스템이 얼마나 안정적이고 효율적으로 돌아갈 것인가?"
"기능을 확장할 때 얼마나 유연하게 돌아갈 것인가?" -
"시스템이 장애 없이 안정적으로 작동하며, 코드의 유지보수가 쉬운가?"
가 테크스펙 성공의 지표가 됨 -
주로 개발팀 내부, 시스템 엔지니어, 품질을 책임지는 QA팀 사이에서
기술적인 합의를 위한 문서 -
기술적인 완성도를 책임
아키텍처(Architecture)
- PRD는 우리가 도달해야 할 목적지를 알려주며,
아키텍처는 그곳까지 안전하고 튼튼하게 이동할 수 있는
가장 효율적인 길을 설계하는 과정
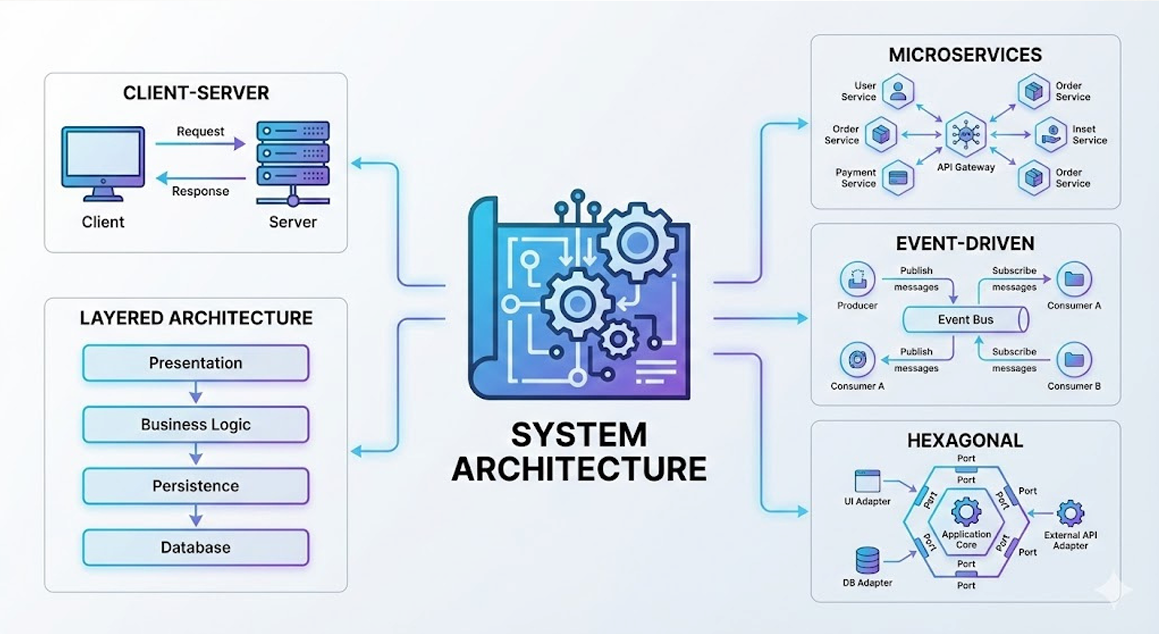
CLIENT-SERVER
- 가장 기본이 되는 구조
LAYERED ARCHITECTURE
- 로직을 층층이 쌓아 관리하는 계층형 아키텍처
MICROSERVICE
- 현대 대규모 서비스에서 사용되는 아키텍처
EVENT-DRIVEN
HEXAGONAL
- 외부 시스템과의 결합도를 낮추는 아키텍처
"어떤 아키텍처를 선택했는가?" 가 아닌,
"왜(WHY)" 선택했는지에 대한 논리적인 근거를 기술하는 것
예)
초기 사용자 대응 속도가 중요 → CLIENT-SERVER 구조
추후 기능 확장이 빈번할 것으로 예상됨
→ 서비스 간 독립성이 높은 MOCROSERVICE
클라이언트-서버(CLIEN-SERVER) 아키텍처
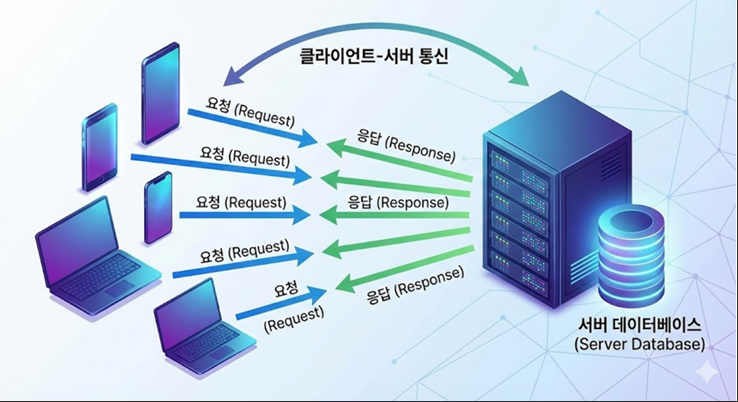
개념
- 서비스를 요청하는 클라이언트와 서비스를 제공하는 서버로 역할을 분리하는
가장 기본적인 구조
특징
- 데이터와 비즈니스 로직을 서버에서 중앙 집중식(centralized)으로 관리
장점
-
구조가 단순하여 개발 속도가 빠르고 관리가 용이
-
데이터의 일관성을 유지하기 쉬움
-
보안 패치나 업데이트를 한 곳에서만 진행하면 모든 사용자에게 즉시 적용
단점
-
사용자가 급격히 늘어나면
서버에 과부화가 걸리는 안정성(scalability) 문제 발생 -
서버 한 대가 고장나면 전체 서비스가 마비됨(Single Point of Failure 현상)
-
response와 request
적용 예시
- 웹 서비스, 소규모 모바일 앱 백엔드 등
계층형 아키텍처(Layered Architecture) 패턴
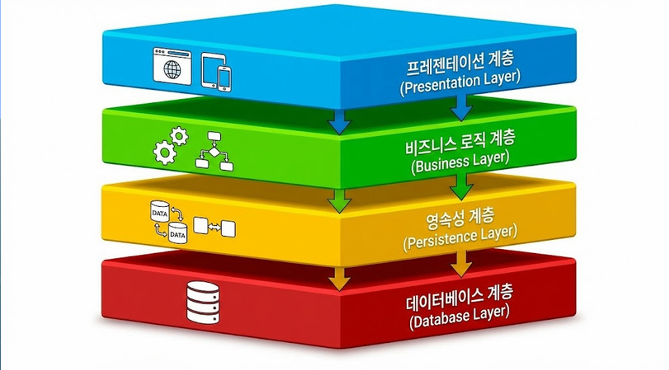
개념
- 시스템을 논리적으로 유사한 책임을 가진
여러 개의 계층(Layer)으로 나누어 쌓는 방식
특징
-
각 계층은 하위 계층에만 의존(단방향 의존성)
이 때 상위 계층은 하위 계층이 제공하는 공개 통로인 인터페이스만을 사용 -
각 계층의 캡슐화
-
관심사의 분리(Seperation of Concerns)를 통해
시스템의 복잡도를 완벽하게 통제
이러한 특징은 교체 가능성 확보를 위함
- 유지보수가 쉽고, 특정 계층만 교체하기 유리함
일반적인 구성
-
다른 레이어가 어떤 구체적인 일을 수행하는지 참견해서는 안됨
-
프레젠테이션 레이어(presentation layer)
사용자에게 버튼을 어떻게 보여줄 것인지, 화면 구성을 어떻게 할 것인지 -
데이터베이스 레이어(database layer)
데이터가 오라클/MySQL, NoSQL 데이터베이스를 사용할지 -
비즈니스 로직 레이어(business logic layer)
기업의 핵심 규칙을 계산 및 처리
마이크로서비스(MicroService Architecture, MSA) 아키텍처
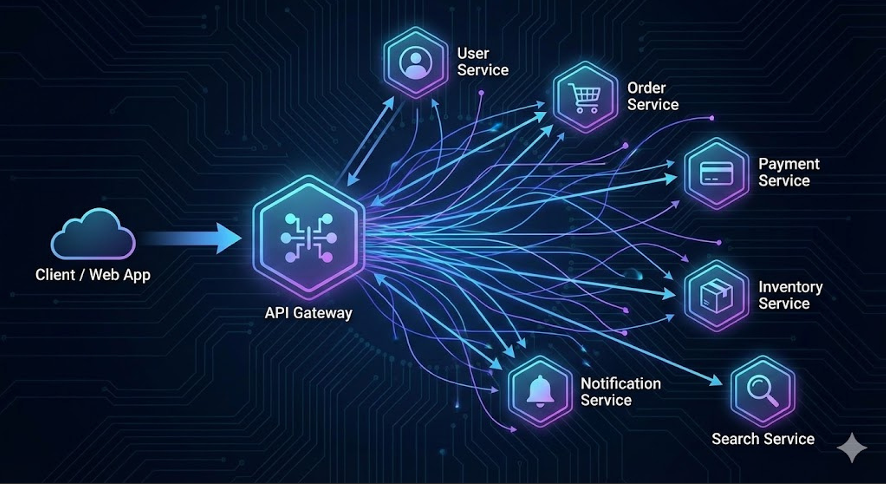
개념
- 하나의 큰 애플리케이션을
독립적으로 배포 가능한 작은 서비스들의 집합으로 구축하는 방식
특징
-
서비스별로 각기 다른 기술 스택을 사용할 수 있고,
독립적인 확장(Independent scalibility)이 가능하며,
독자적인 배포가 가능함 -
서비스의 특성에 맞춰 가장 적합한 프로그래밍 언어나
데이터베이스를 선택할 수 있는 polyglot 구조를 가짐 -
서비스 당 하나의 데이터베이스를 가짐
→ 데이터 간의 결합도를 낮춤
한 서비스의 데이터베이스 장애가 다른 서비스에 영향을 주지 않는 격리 실현
→ 각 도메인에 최적화된 데이터 저장 기술을 고를 수 있게 해줌 -
장애가 발생해도 전체 시스템으로 번지지 않는
높은 회복 탄력성(resilience)을 가짐
API gate
- 클라이언트의 요청을 적절한 서비스로 안내하는 라우팅
- authentication, authorization(인증과 인가) 같은
보안 검사를 중앙에서 일괄 처리
→ 개별 서비스는 핵심 비즈니스 로직에만 집중할 수 있음
circuit-breaker
-
한 서비스의 장애가 도미노처럼 번지는 것을 막기 위함
-
문제가 생긴 서비스로의 요청을 즉시 차단하고,
미리 준비된 대체 응답인 fallback을 내보냄
service discovery
- 생성·소멸하는 서비스들의 위치 정보를 실시간으로 관리하는 서비스
단점
- 서비스의 개수가 늘어나면, 관리해야 할 복잡도가 늘어나게 됨
적용 예시
- 넷플릭스, 쿠팡 등 대규모 서비스
Event driven 아키텍처
개념
- 상태의 변화인 이벤트(Event)를 생성하고 소비하는 방식으로
시스템 구성 요소 간에 통신하는 구조
핵심 구성 요소
- 발행자(Producer): "결제가 완료되었습니다."와 같은 이벤트를 던짐
- 이벤트 채널(Bus/Broker): 이벤트를 수신자들에게 전달하는 통로
- 구독자(Consumer): 자신에게 필요한 이벤트를 감지하여 독립적으로 작업 수행
실제 예시: 온라인 쇼핑몰 결제
-
결제 완료 이벤트 발생 → (배송팀)운송장 출력 → (마케팅팀) 감사 메일 발송 → (재고팀) 재고 수량 차감
-
각 구독자는 공용 통로(message broker)에 자신의 메시지를 전달하는 것으로
작업을 끝냄
강점
-
각 팀은 서로를 기다릴 필요가 없음
-
업무가 늘어나도 message broker에 새로운 팀(구독자)만 추가하면 됨
-
느슨한 결합도(loose coupling)
-
비동기 처리 능력(asynchronous)
-
수많은 사용자가 몰려 와도,
메시지 브로커가 이벤트를 차곡차곡 쌓아두었다가,
각 서비스가 감당할 수 있는 속도로 처리함
Hexagonal 아키텍처
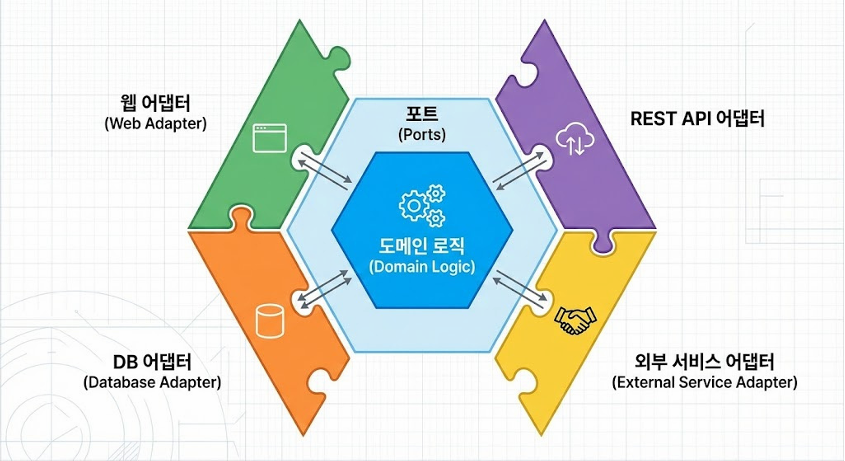
개념
애플리케이션의 핵심 비즈니스 로직을 외부 환경(데이터베이스, 유이, 외부 API)으로부터 분리하는 포트와 어댑터(Ports and Adapters) 구조
기술적 구현 방식
-
포트(Port): 도메인 내부에서 정의한 인터페이스
(외부 기술이 무엇이든 이 규칙만 지키라고 선언) -
어댑터(Adapter): 외부 기술을 포트에 맞게 변환해주는 구현체
(DB 연동 코드, 외부 API 호출 코드 등이 해당)
driving adapter
웹 브라우저나, CLI(Command Line Interface) 같은 입력 수단이 로직을 깨움(아래 진행 과정 참조)
driven adapter
데이터베이스나 외부 API같은 수단은 로직의 요청을 수행 -
도메인 → 포트에 규칙 선언 → 어댑터가 실제 구현
도메인(Domain/Business Logic)
- 오로지 서비스의 규칙과 비즈니스 언어만 남게 되는 퓨어 도메인 상태
// domain
class Expense {
void validate() {
if (amount <= 0) throw Exception("지출은 0원 이하일 수 없습니다");
}
}// port (인터페이스)
abstract class ExpenseRepository {
void save(Expense expense);
List<Expense> findAll();
}// adapter (실제 구현)
class HiveExpenseRepository implements ExpenseRepository {
void save(Expense expense) { /* Hive 저장 로직 */ }
List<Expense> findAll() { /* Hive 조회 로직 */ }
}진행 과정
개발 시점
- 도메인이 비즈니스 규칙을 메서드로 정의
- 도메인이 필요한 기능을 포트(인터페이스)로 선언
- Driven Adapter가 포트를 보고 실제 구현
- 런타임에 포트 자리에 Driven Adapter 주입
런타임 시점
- 이벤트 발생 (사용자 버튼 클릭 등)
- Driving Adapter가 이벤트 수신 → 도메인 메서드 호출
- 도메인이 비즈니스 규칙 판단
- 도메인이 포트의 메서드 호출
- 포트에 이미 주입된 Driven Adapter의 구현 코드가 실행
- DB/외부에 실제 처리
순수성을 유지하는 이유
-
비즈니스 로직(Business/Domain Logic)은
외부 라이브러리나 특정 데이터베이스 전용 코드를 포함하지 않음 -
데이터베이스를 MySQL에서 MongoDB로 바꿔도, 도메인이 필요가 없음
(어댑터만 새로 만들면 됨) -
의존성 역전 원칙 (dependency inversion)
도메인은 포트에만 의존
도메인이 외부(DB)를 바라봐야 하지만, DB(어댑터)가 도메인(포트)를 바라봄
데이터베이스 설계
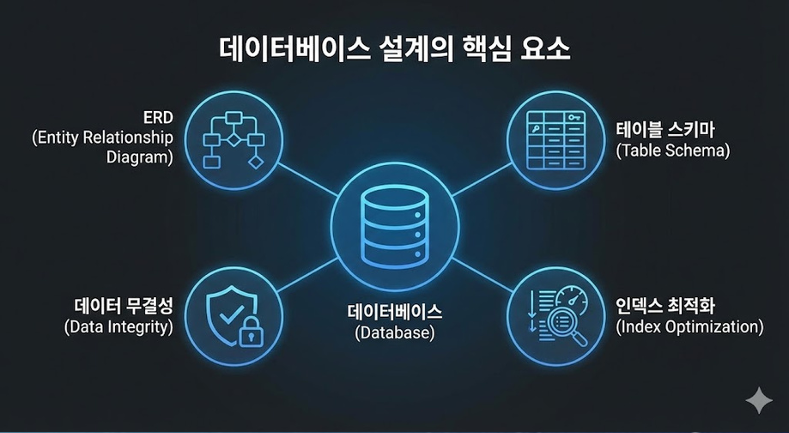
정의
- 애플리케이션이 사용하는 데이터를 논리적, 물리적으로 구조화하여
데이터의 무결성과 효율성을 보장하는 과정
주요 포함 내용
-
ERD(Entity Relationship Diagram): 엔터티 간의 관계 시각화
-
스키마 설계(Schema Dsign): 테이블 구조, 컬럼 타입, 제약 조건(PK, FK) 정의
-
데이터 저장 전략: 데이터베이스 종류(RDBMS vs NoSQL) 선정 및 인덱스 설계
-
sharding: 데이터를 여러 서버에 나누어 저장하는 기법
-
replication: 읽기 성능을 분산시키는 전략
목적
-
정규화 과정을 통해 중복 데이터를 최소화하고,
서비스 성장에 따른 데이터 확장성 확보 -
실제 서비스 환경에서는 조회 성능을 위해
의도적으로 정규화를 깨뜨려야 할 때도 있음
RESTful API 설계 원칙
- 일관성 있는 API 설계를 위해 널리 사용되는 규칙
자원 중심(Resource-based)
- URL은 동사가 아닌 명사를 사용할 것
예)
/get-cards→/cards
HTTP) 메서드의 활용
GET: 정보 조회(카드를 가져올 때)POST: 새로운 자원 생성(게임을 시작할 때)PUT/PATCH: 자원 수정(점수를 업데이트 할 때)DELETE: 자원을 삭제할 때(기록을 지울 때)
상태 코드(Status Code)
200/201: 성공400/401/404: 클라이언트 오류500: 서버 내부 오류
API 설계 예시
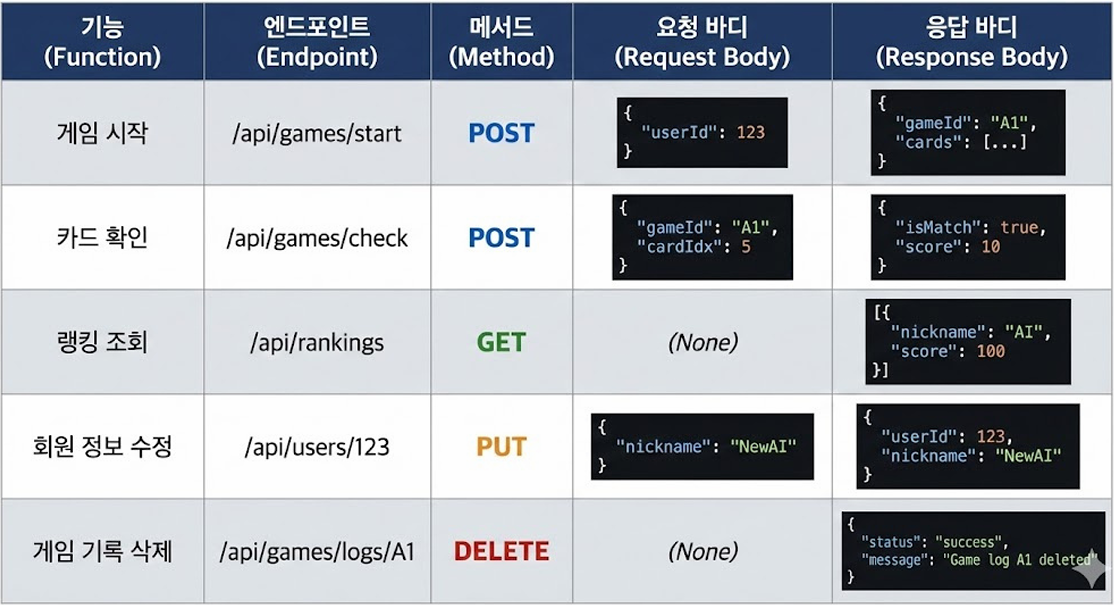
-
자원 간의 관계는 계층 구조를 이용하여 표현한다.
예)
/games/123/players
games: 전체 게임방 목록
123: 특정 게임의 고유 아이디
players: 그 방에 속한 하위 자원
계층이 너무 깊어지면 관리가 힘들어지기 때문에 보통은 2단계 정도에서 타협 -
특정 조건으로 데이터를 구분하고 싶을 때
URI 경로 뒤에 ? 쿼리 파라미터 사용
예)
승리한 기록만 보고 싶을 때?status=win
성능과 보안
성능 설계(Performance): 사용자가 느끼는 속도와 안정성의 지표
핵심 지표: 지연 시간(latency), 처리량(throughput)
-
최적화
캐싱(redis): 데이터베이스의 부하를 줄여주는 분산 캐싱 전략
부하 분산(로드 밸런싱): 몰려드는 트래픽을 여러 서버로 고르게 분산
트래픽 폭주 발생 시, 서버 인스턴스를 자동으로 늘려주는 오토 스케일링 전략 -
보안 설정 (Security)
데이터와 사용자를 지키는 다중 방어선 -
인증 및 인가
authentication: 시스템에 접근하는 사용자가 누구인지 확인
authorization: 사용자가 어떤 자원에 접근할 수 있는지 결정
위의 두 과정을 위한 JWT와 같은 토큰 기반의 보안 도구를 명확히 정의
권한 기반 제어(Role Based Access Control, RBAC) -
방어 전략
데이터 암호화(TLS)
입력값 검증
속도 제한(rate limiting): 디도스 공격 방지 -
상충 관계(Trade-off)
보안이 강화되면 성능에 영향을 줄 수 있으므로
최적의 균형점을 테크스펙에 명시
PRD vs Tech Spec: 보안 요구사항 기술 방식 비교
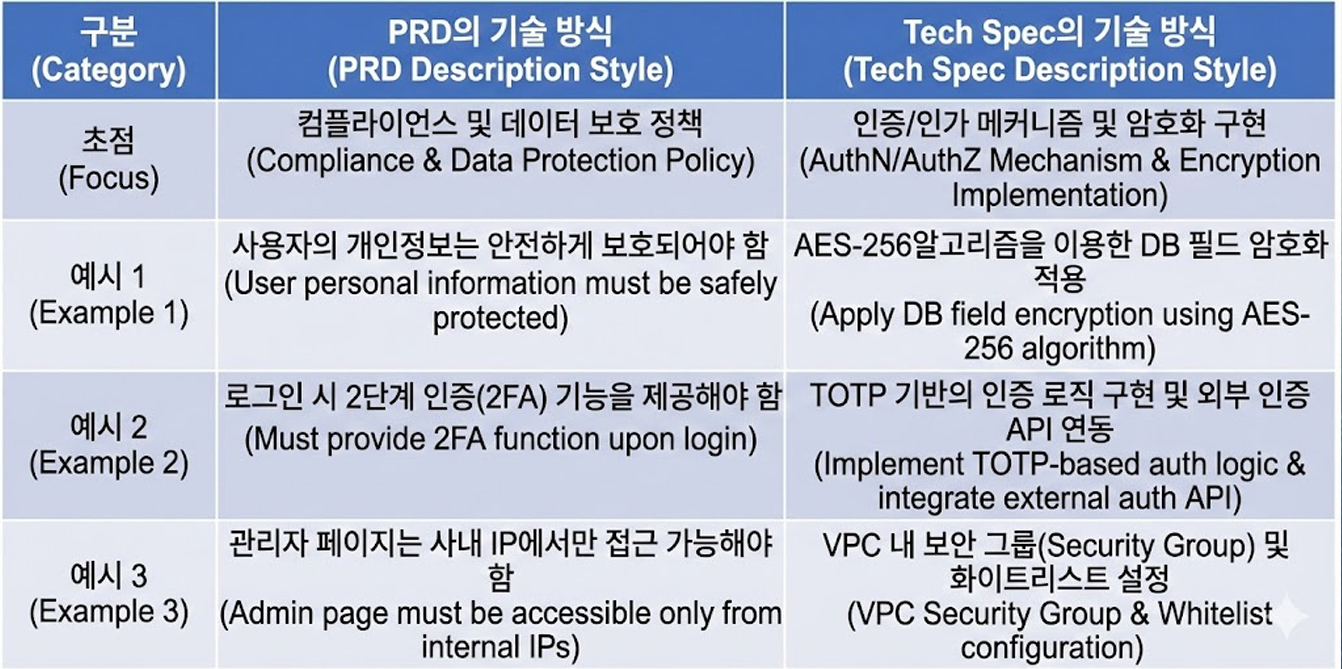
- PRD
SLO(Service Level Objective, 서비스 수준 목표)
정책적 목표 설정
- TechSpec
SLI(Service Level Indicator, 서비스 수준 지표)
기술적 수단으로 목적 실현
협업의 효율성 측면에서 중요함
AI를 활용한 TechSpec 생성
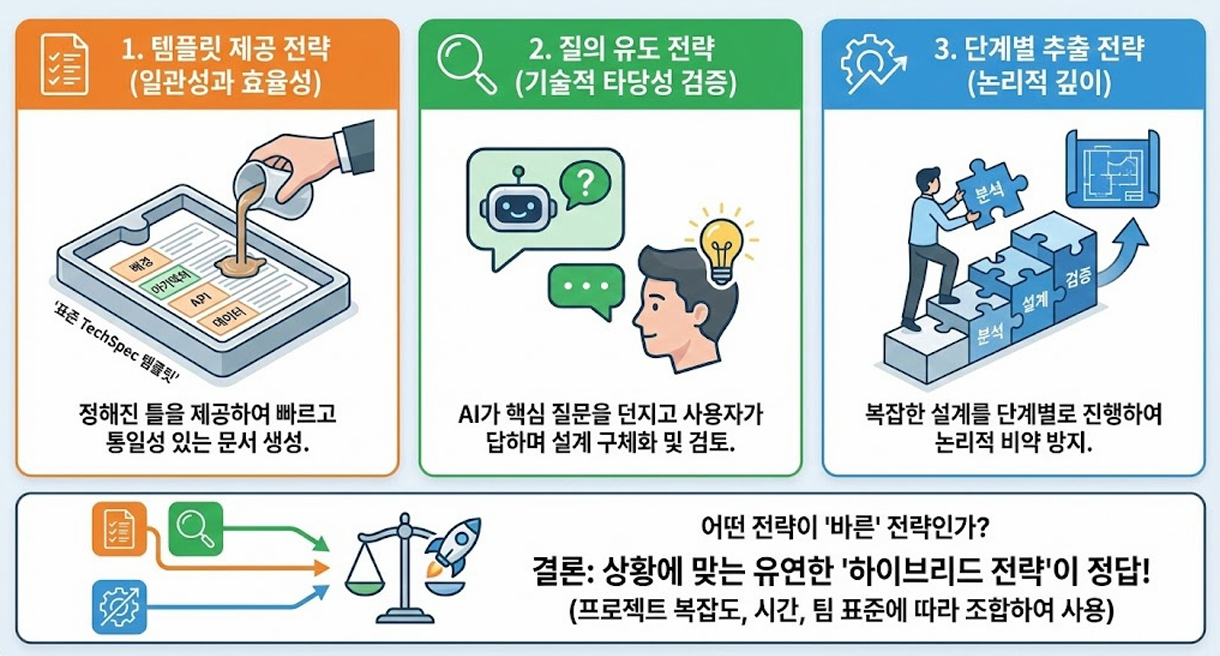
템플릿 기반 TechSpec 생성

- 가장 중요한 것은 TechSpec Template의 구조
TechSpec Template (출력 형식)
-
개요(Overview)
프로젝트의 목적 -
목표 및 비목표(Goals and Non-Goals)
이번 설계에서 다루는 범위와 다루지 않는 범위를 명확히 구분 -
시스템 아키텍쳐(System Architecture)
전체적인 구성도 및 요소 간 상호작용 설명
예)
React 기반의 프런트엔드와 nodejs 기반의 백엔드가
어떻게 http 통신을 주고받을 것인지 -
데이터 모델링(Data Model)
핵심 엔티티 구조 및 데이터베이스 스키마 설계
예)
카드 객체의 구조는 어떠한지 정의 -
API 설계(API Design)
주요 엔드포인트 명세 및 요청/응답 구조
도메인과 외부 사이에 어떤 데이터를 주고받을 지 결정
예)
게임 시작을 위한 엔드포인트는 무엇인가?
JSON의 응답 구조는 어떠해야 하는가? -
기술적 고려 사항(Technical Considerations)
보안, 성능, 확장성 등에 대한 전략
예)
사용자가 카드를 마구 클릭했을 때 발생하는 광클 문제 해결 방법 명시
이미지 로딩 속도를 어떻게 최적화할 지 명시
Input Data
- 기획한 PRD가 입력되는 곳
질의 유도 기반 프롬프트

-
"숙련된 시니어 소프트웨어 엔지니어 및 시스템 아키텍트"라는
아주 높은 수준의 자아를 부여하는 것으로 시작 -
가장 중요한 것은 작성 프로세스의 2번째 단계
설계를 작성하기 전, 확인이 필요한 질문을 5~7개 정도 먼저 던져달라고 명령
단계별 TechSpec 생성 프롬프트

-
각 단계가 끝날 때 마다 반드시 확인을 받은 후 넘어가야 한다라는
제약 조건을 거는 것
이를 통해 각 단계마다 사용자의 피드백이 반영됨 -
핵심 질문 단계가 가장 중요함
설계 확정을 위해 사용자에게 확인이 필요한 질문을 3~4개 던지게 함으로써
우리가 미처 생각치 못한 확장성이나 성능 문제를 점검하게 함
