What is BERT?
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 개발한 자연어 처리(NLP)를 위한 pre-trained 언어 모델이다.
BERT는 Transformers 아키텍처를 기반으로, 대규모 텍스트 Corpus에서 pre-trained 언어 표현을 제공하여 다양한 자연어 처리 작업에 사용된다.
BERT 특징
-
양방향 학습(Bidirectional Learning)
: 기존의 자연어 처리 모델은 문맥을 좌에서 우로만 고려하거나 우에서 좌로만 고려하는 단방향 학습 방식을 사용한다. 하지만 BERT는 Transformer 모델을 사용하여 문장을 양방향으로 고려하여 더욱 풍부한 문맥 정보를 학습한다. -
사전 훈련된 언어 모델(Pre-trained Language Model)
: BERT는 대량의 텍스트 데이터(ex. 책, 웹 문서)를 사용하여 사전 훈련된 모델이다. 이로 인해 BERT는 다양한 언어 표현을 학습하고, 이를 다른 자연어 처리 작업에 적용할 수 있다. -
파인 튜닝(Fine-tuning)
: BERT는 사전 훈련된 모델을 가져와서 특정한 자연어 처리 작업에 맞게 추가적인 훈련을 할 수 있다. 이를 통해 적은 양의 데이터로도 높은 성능을 달성할 수 있다. -
다양한 자연어 처리 작업에 적용
: BERT는 다양한 자연어 처리 작업(문장 분류, 텍스트 유사도 측정, 질문 응답, 개체명 인식 등)에 적용할 수 있다.
What is Transformer?
Transformer 아키텍처는 자연어 처리와 기타 시퀀스 기반 작업에 대한 혁신적인 딥러닝 아키텍처이다.
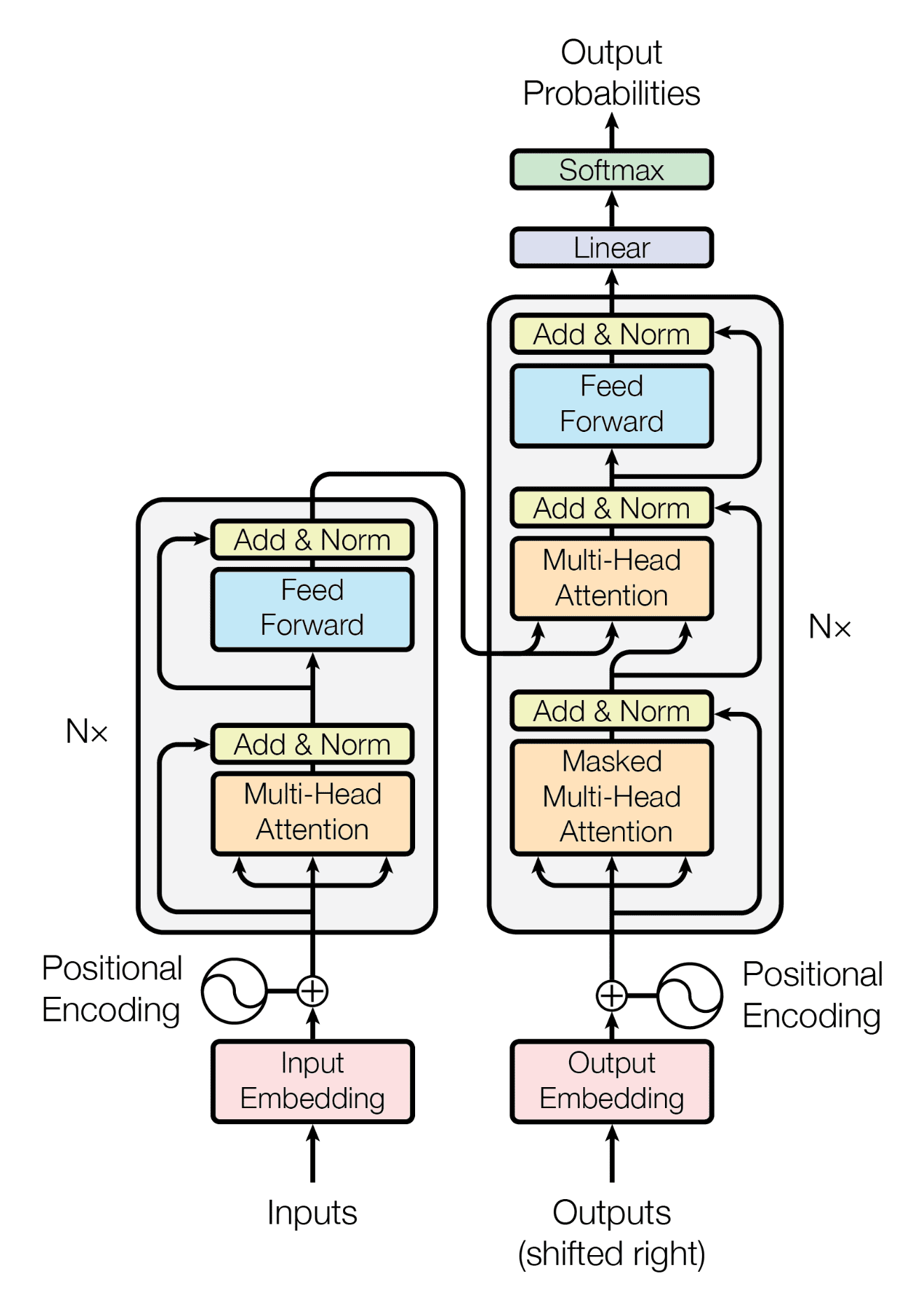
기존 아키텍처 모델과의 차이점
Transformer는 RNN(Recurrent Neural Network)이나 LSTM(Long Short-Term Memory)과 같은 이전의 모델보다 더욱 병렬화가 쉽고, 긴 시퀀스에 대한 정보를 더욱 효과적으로 캡처할 수 있다.
Transformer 특징
-
Attention Mechanism
: Transformer의 핵심은 Attention 메커니즘이다. Attention은 입력 시퀀스의 각 요소에 가중치를 할당하여 출력을 계산하는 메커니즘으로, 입력의 모든 요소를 고려하여 출력을 생성한다. -
인코더-디코더 구조(Encoder-Decoder Architecture)
: Transformer는 인코더와 디코더로 구성된다.
인코더는 입력 시퀀스를 임베딩하고 다음 레이어로 전달하여 특성을 추출한다. 디코더는 출력 시퀀스를 생성하는 데 사용된다. -
포지셔널 인코딩(Positional Encoding)
: Transformer는 시퀀스의 상대적인 위치 정보를 인코딩하는데 사용되는 포지셔널 인코딩을 도입했다. 이를 통해 Transformer는 시퀀스의 위치 정보를 유지하면서도 위치 정보를 임베딩에 결합할 수 있다.
