NLP
1.BERT에 대하여
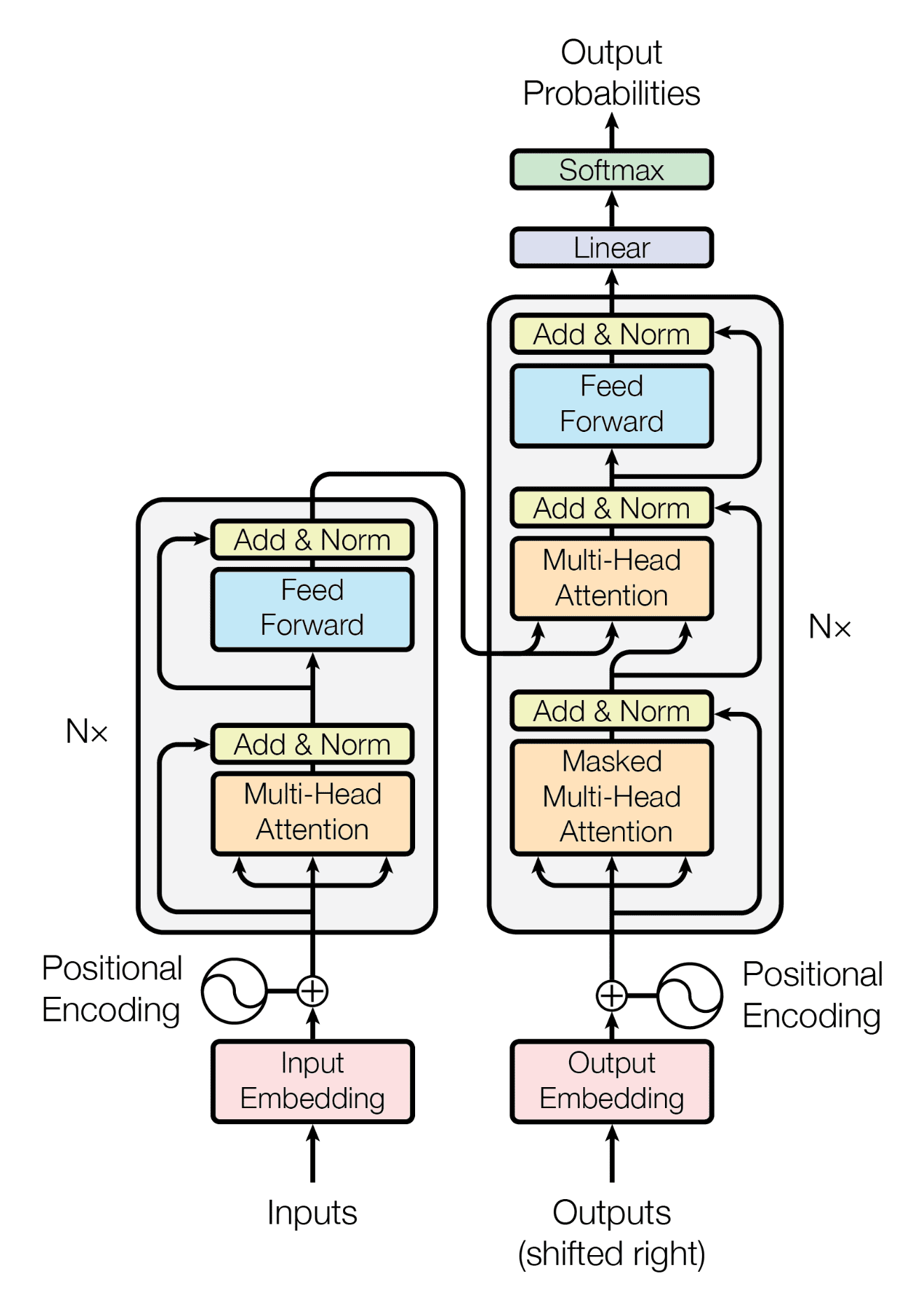
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 개발한 자연어 처리(NLP)를 위한 pre-trained 언어 모델이다.BERT는 Transformers 아키텍처를 기반으로, 대규모 텍스트 Cor
2.What is 자연어 처리(NLP, Natural Language Processing)
자연어(natural language) : 우리가 일상 생활에서 사용하는 언어 자연어 처리(natural language processing) : 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일예시음성 인식내용 요약번역사용자의 감성 분석텍스트 분류 작
3.텍스트 전처리(Text Preprocessing)
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업토큰(Token) : 텍스트 데이터의 의미있는 단위토큰화에서 고려해야 할 사항구두점이나 특수 문자를 단순 제외해서는 안됨마침표(.)와 같은 경우는 문장의 경계를 알 수 있는데 도움이 되므로
4.언어 모델(Language Model)
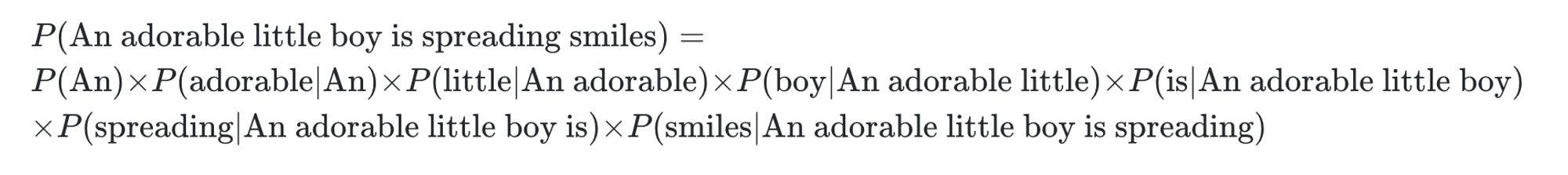
단어 시퀀스(문장)에 확률을 할당(assign)하는 모델가장 자연스러운 단어 시퀀스를 찾아내는 모델확률 할당 방법 : 이전 단어들이 주어졌을 때 다음 단어를 예측 → 언어 모델링(Language Modeling)언어 모델 만드는 방법통계를 이용한 방법Statistica
5.카운트 기반의 단어 표현(Count based word Representation)
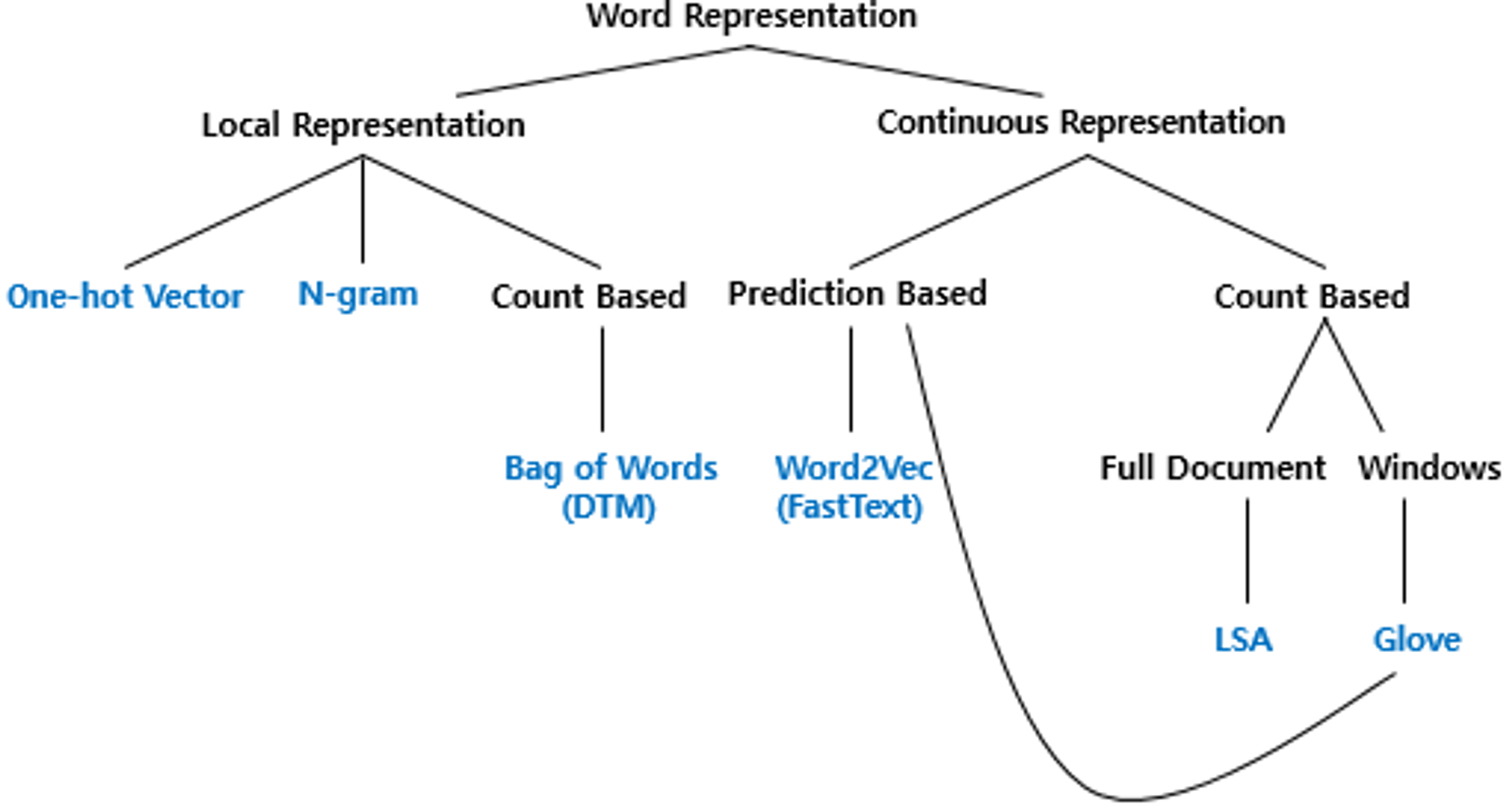
정보 검색과 텍스트 마이닝 분야에서 주로 사용Count based word Representation 방법DTMTF-IDF위 방법으로 수치화하여 통계적 접근방법으로 아래와 같은 작업을 할 수 있다.특정 문서 내에 어떤 단어가 얼마나 중요한 지 나타내기핵심어 추출검색 엔
6.벡터의 유사도(Vector Similarity)
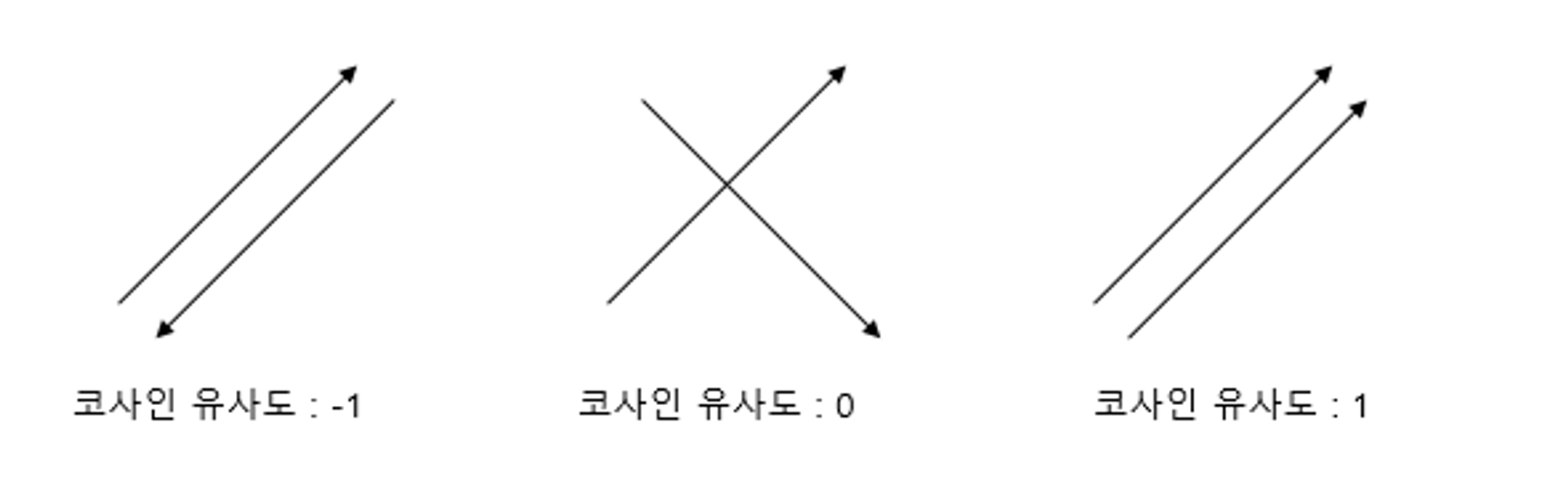
두 벡터 간의 코사인 각도$similarity=cos(Θ)=\\frac{A⋅B}{||A||\\ ||B||}=\\frac{\\sum{i=1}^{n}{A{i}×B{i}}}{\\sqrt{\\sum{i=1}^{n}(A{i})^2}×\\sqrt{\\sum{i=1}^{n}(B\_