폐CT 이미지를 가지고 코로나 발병을 예측하는 모델을 만들게 되었다.
제약사항은 다음과 같았다.
- pretrained 된 모델을 사용할 수 없다는 조건
- 외부 데이터셋을 사용할 수 없다는 조건
- 이미지 데이터의 수는 550개 남짓이었다.
그래서 한정된 데이터를 늘리고자 하였고 다음과 같은 방법을 사용하게 되었다.
1. DataLoader 구성
augmentation 관련해서는 transform 부분만 살펴보면 된다.
aug_mode라는 인자를 추가하여 crop, h_flip등등을 구현해두었다.
class CustomDataset(Dataset):
def __init__(self, data_dir, mode, input_shape,aug_mode):
self.data_dir = data_dir
self.mode = mode
self.input_shape = input_shape
self.aug_mode = aug_mode
# Loading dataset
self.db = self.data_loader()
# Dataset split
if self.mode == 'train':
self.db = self.db[:int(len(self.db) * 0.9)]
elif self.mode == 'val':
self.db = self.db[int(len(self.db) * 0.9):]
self.db.reset_index(inplace=True)
else:
print(f'!!! Invalid split {self.mode}... !!!')
# Transform function
if self.aug_mode == "normal":
self.transform = transforms.Compose([
transforms.Resize(self.input_shape),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
elif self.aug_mode == "radom_crop":
self.transform = transforms.Compose([
transforms.RandomCrop(self.input_shape),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
elif self.aug_mode == 'H_flip':
self.transform = transforms.Compose([
transforms.Resize(self.input_shape),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
elif self.aug_mode == 'V_flip':
self.transform = transforms.Compose([
transforms.Resize(self.input_shape),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
elif self.aug_mode == 'rotate':
self.transform = transforms.Compose([
transforms.Resize(self.input_shape),
transforms.RandomRotation([-180, 180]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
def data_loader(self):
print('Loading ' + self.mode + ' dataset..')
if not os.path.isdir(self.data_dir):
print(f'!!! Cannot find {self.data_dir}... !!!')
sys.exit()
# (COVID : 1, No : 0)
db = pd.read_csv(os.path.join(self.data_dir, 'train.csv'))
return db
def __len__(self):
return len(self.db)
def __getitem__(self, index):
data = copy.deepcopy(self.db.loc[index])
# Loading image
cvimg = cv2.imread(os.path.join(self.data_dir,'train',data['file_name']), cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
if not isinstance(cvimg, np.ndarray):
raise IOError("Fail to read %s" % data['file_name'])
# Preprocessing images
trans_image = self.transform(Image.fromarray(cvimg))
return trans_image, data['COVID']2. 사용하기
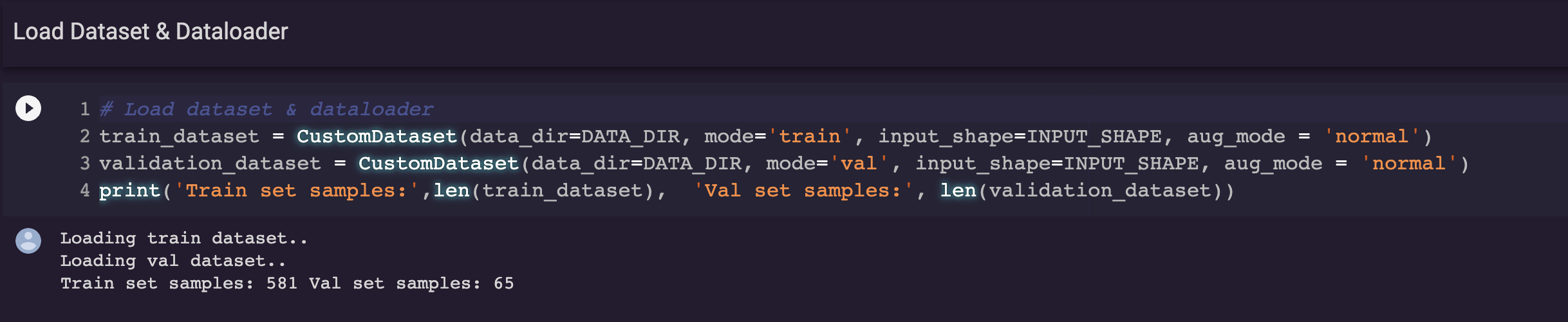
이런식으로 불러올 수 있는데 지금 현재는 normal 즉 평범한 이미지만 가져온 데이터셋을 불러보았다.
train, valid set의 길이는 각각 581, 65이다.
여기서는 아까 class에서 지정해준 여러가지 augmentation 옵션들을 다 불러다가
ConcatDataset을 사용하여 하나의 dataset으로 만들어주었다.
다양한 방법들이 있지만 이렇게 처리하는 것이 가장 편했다.
(원래는 valid set은 건드리면 안되지만 실험상 한번 해보았다.)
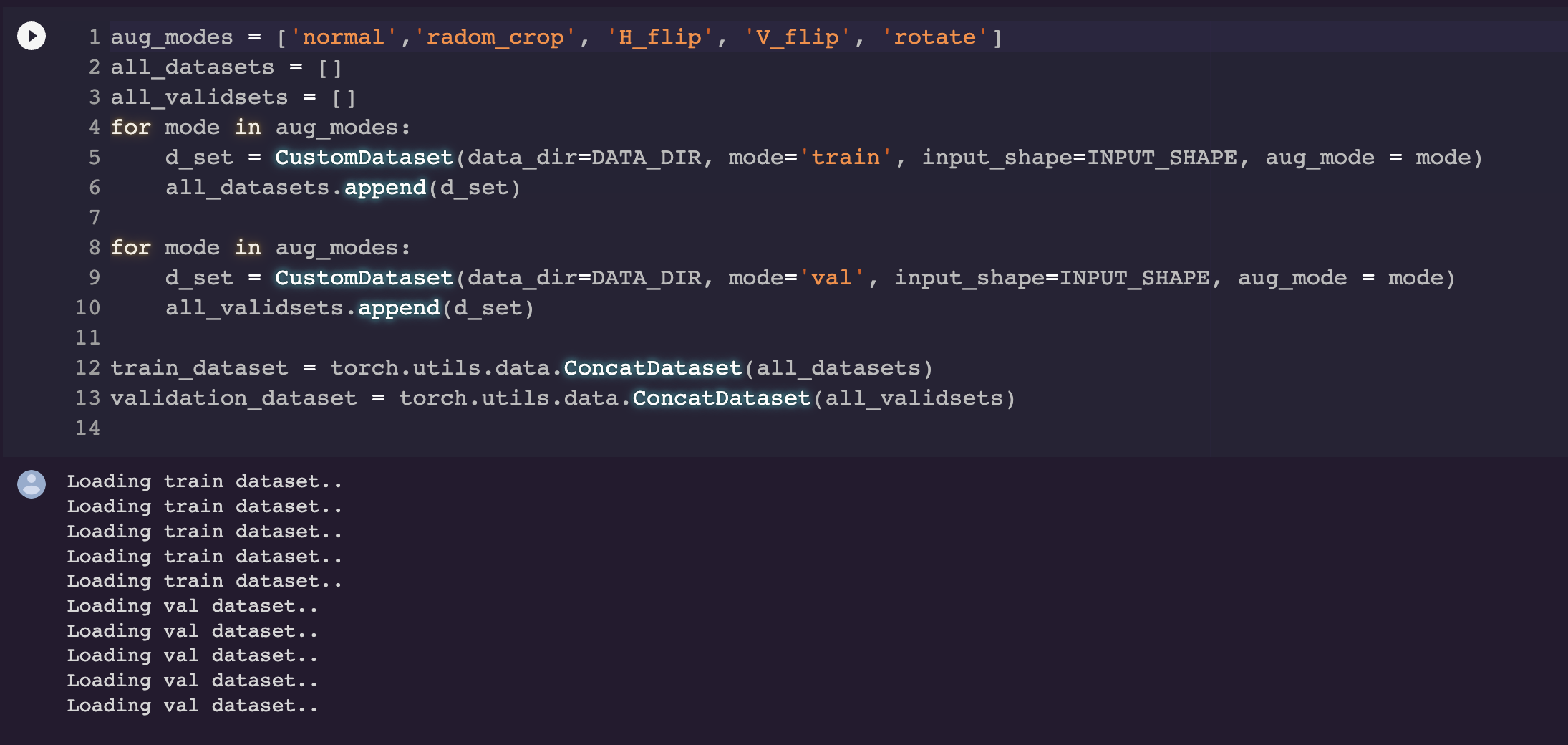
이제 길이를 찍어보면 2900개로 늘었음을 확인할 수 있다!!

혹시나 전체 코드가 궁금하다면 highway92 여기서 확인해 볼 수 있다.

웹 개발자로 활동하고 있습니다.