
모의 캐글 비매너 댓글 식별과제
원래 데이터의 일부를 한번 살펴보자.

이런식으로 특수문자, ..., 띄워쓰기가 제대로 되어있지 않다.
그럼 이제 전처리를 해보자
이모티콘 제거
import re
# 이모지 제거 전처리
def remove_emoji(inputString):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', inputString) # no emoji🔥🔥과 같은 이모티콘들을 모두 제거 해준다.
pandas column에 적용하고 싶다면 다음과 같이 해주면 된다.
train_df['title'].apply(remove_emoji)특수문자 제거
# 특수문자 제거 전처리
def remove_special_str(df, column):
df[column] = df[column].str.replace(pat=r'[^\w]', repl=r'', regex=True)
return df[],?!{}() 이런 녀석들을 한번에 싹 지워주는 역할을 해준다.
column 적용은 다음과 같이 하자
remove_special_str(train_df,'title')띄워쓰기
- py-hanspell
py-hanspell은 네이버 맞춤법 검사기를 이용한 파이썬용 한글 맞춤법 검사 라이브러리입니다.
파이썬 2.7 및 3.4 모두 호환됩니다. 라고 친절하게 설명이 되어있다. 사용법은 링크를 참조하자.
필자는 다음과 같은 형태로 사용하였다.
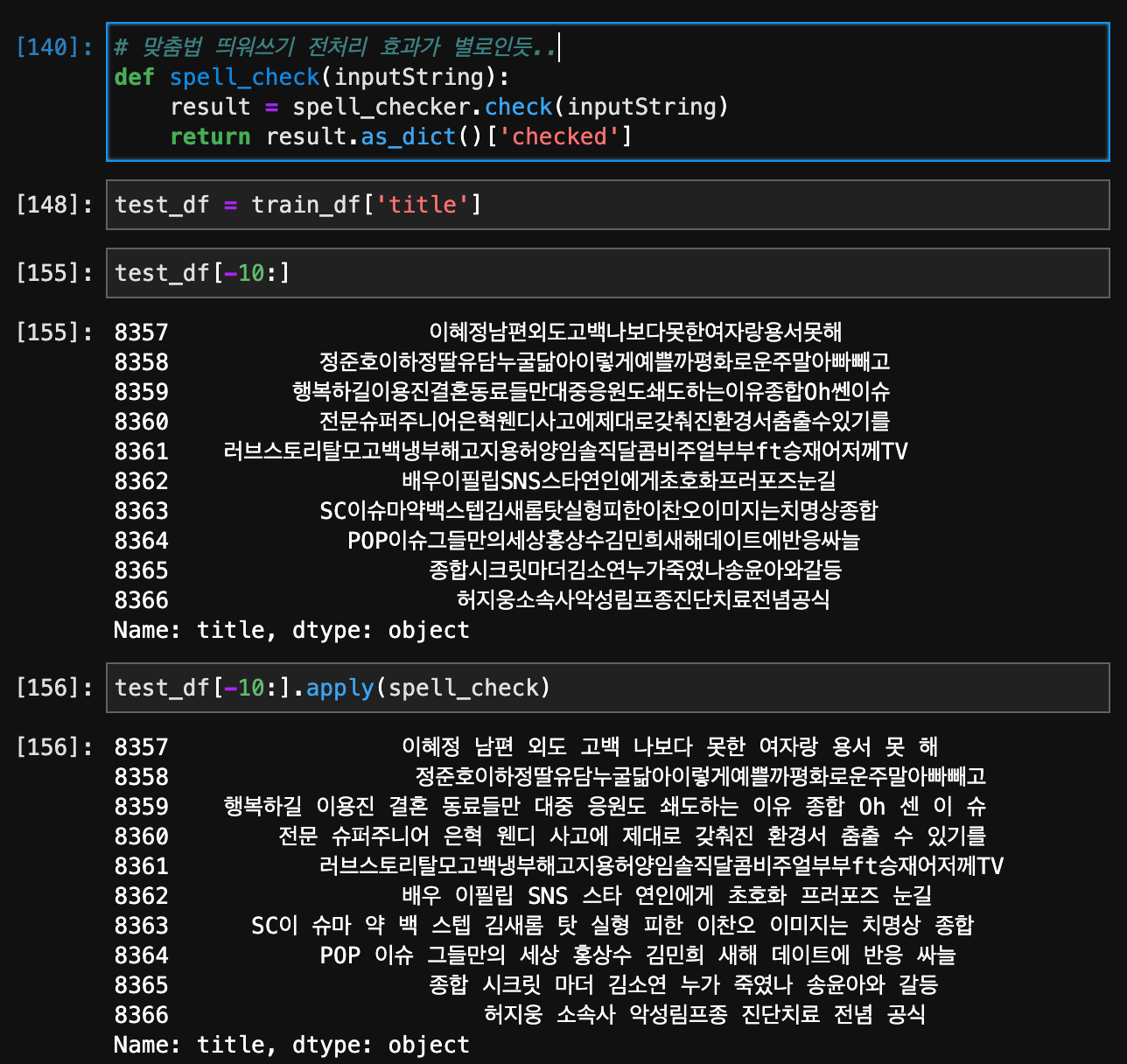
맞춤법은 잘 모르겠으나 몇몇 문장들에는 아에 띄워쓰기를 적용하지 않는데 그래서 다른 대안을 찾게 되었다.
이 녀석은 띄워쓰기 만을 목적으로 사용하였다. 코랩에서 사용하게 된다면
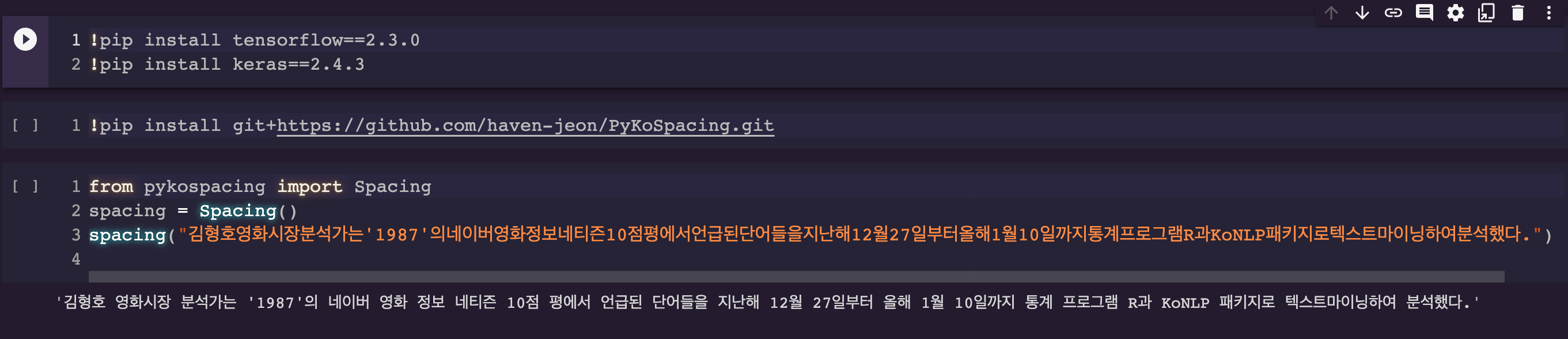
이렇게 설치해서 사용하면 된다. 그냥 pip install tensorflow, keras를 하면 어딘가에서 에러가 뜨면서 제대로 실행이 되지 않는데, 조금 찾아보니 버전과 관련된 문제였다.

웹 개발자로 활동하고 있습니다.