HashMap vs HashTable vs LinkedHashMap vs TreeMap 성능테스트
데이터 추가 속도 테스트는 비슷함으로 데이터 get 테스트만 진행한다.
1. 데이터 get 테스트
key값에 1000개의 랜덤데이터를 추가하여 하였으며,
순차적으로 데이터를 get하기, 랜덤으로 데이터를 get하기 2가지의 테스트를 진행하였다.
테스트코드
@State(Scope.Thread)
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.MICROSECONDS) //밀리세컨드 단위로 출력
@Fork(value = 2, jvmArgs= {"-Xms4G", "-Xmx4G"})
public class MapGet {
static int LOOP_COUNT=1000;
Map<Integer,String> hashMap;
Map<Integer,String> hashtable;
Map<Integer,String> treeMap;
Map<Integer,String> linkedHashMap;
int keys[];
@Setup
public void setUp(){
if(keys==null || keys.length!=LOOP_COUNT){
hashMap = new HashMap<>();
hashtable = new Hashtable<>();
treeMap = new TreeMap<>();
linkedHashMap = new LinkedHashMap<>();
String data = "abcdefghijklmnopqrstuvwxyz";
for (int i=0; i<LOOP_COUNT; i++){
String tempData = data+i;
hashMap.put(i,tempData);
hashtable.put(i,tempData);
treeMap.put(i,tempData);
linkedHashMap.put(i,tempData);
}
keys = RandomKeyUtil.generateRandomSetKeysSwap(LOOP_COUNT);
}
}
@Benchmark
public void getSeqHashMap(){
for (int i=0; i<LOOP_COUNT; i++){
hashMap.get(i);
}
}
@Benchmark
public void getRandomHashMap(){
for (int i=0; i<LOOP_COUNT; i++){
hashMap.get(keys[i]);
}
}
@Benchmark
public void getSeqHashTable(){
for (int i=0; i<LOOP_COUNT; i++){
hashtable.get(i);
}
}
@Benchmark
public void getRandomHashTable(){
for (int i=0; i<LOOP_COUNT; i++){
hashtable.get(keys[i]);
}
}
@Benchmark
public void getSeqTreeHash(){
for (int i=0; i<LOOP_COUNT; i++){
treeMap.get(i);
}
}
@Benchmark
public void getRandomTreeHash(){
for (int i=0; i<LOOP_COUNT; i++){
treeMap.get(keys[i]);
}
}
@Benchmark
public void getSeqLinkedHashMap(){
for (int i=0; i<LOOP_COUNT; i++){
linkedHashMap.get(i);
}
}
@Benchmark
public void getRandomLinkedHashMap(){
for (int i=0; i<LOOP_COUNT; i++){
linkedHashMap.get(keys[i]);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(MapGet.class.getSimpleName())
.forks(2)
.warmupIterations(10)
.measurementIterations(10)
.build();
new Runner(opt).run();
}
}
public class RandomKeyUtil {
public static int[] generateRandomSetKeysSwap(int n){
int size = n;
int[] result = new int[size];
Random random = new Random();
int maxNumber = size;
int resultPost=0;
while (size>0){
result[resultPost++]=size--;
}
for(int loop=0; loop<size; loop++){
int randomNum1 = random.nextInt(maxNumber);
int randomNum2 = random.nextInt(maxNumber);
int temp=result[randomNum2];
result[randomNum2]=result[randomNum1];
result[randomNum1]=temp;
}
return result;
}
}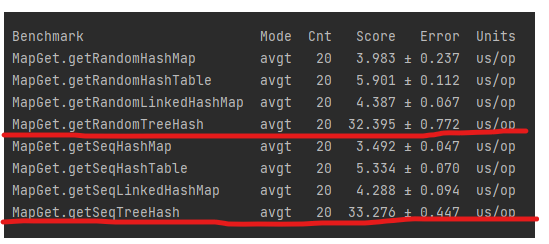
다른건 대부분 비슷한 성능으로 나왔으며
TreeMap이 가장 느리게 나왔다.각 클래스의 용도가 모두 다르기 때문에 용도에 맞게 쓰여야 한다.
용도 정리
- HashMap, HashTable
비슷한점
ArrayList 와 Vector의 관계랑 비슷함으로
HashTable보단HashMap사용이 권장된다.
데이터가 많은경우초기에크기를 크게 지정하는것이 권장됨해싱을 사용하기 때문에
검색처리에서 뛰어난 성능을 보인다.다른점
HashTable은Thread-Safe하여동기화를 지원
- LinkedHashMap
일반적으로 Map 자료구조는 순서가 없지만
LinkedHashMap는데이터가 들어온 순서를 알 수 있다.LFU(Least Frequencd Used) 캐시에서도 쓰여 removeEldestEntry() 메서드를 오버라이드 하면 오랫동안 사용되지 않은 데이터를 삭제해주는 기능을 제공한다.
@Override protected boolean removeEldestEntry(Map.Entry<String, Integer> eldest) { //최대 수용량을 넘는경우 가장 오래된 요소를 삭제 return size()>capacity; }
- TreeMap
데이터를 추가하거나 삭제할때 동시에 내부적으로 정렬을 한다.(레드 블랙 트리)
때문에 저장 삭제 변경과 같은 작업은 느리다.
범위 검색 같은 경우에 뛰어난 성능을 보인다.
TreeSet도레드 블랙 트리로 구현되어있다.
TreeSet과의 차이점은TreeSet은 키값만 저장하지만TreeMap은 키, 값이 저장된 Map.Entry를 저장한다,

5 Seconds rule