HashSet vs TreeSet vs LinkedHashSet 성능테스트
특징
- HashSet
데이터를 해쉬 테이블에 담는 클래스로 순서 없이 저장
- TreeSet
red-black 이라는 트리에 데이터를 저장,
값에 따라서 순서가 정해짐, 데이터를 담으면서 동시에정렬하기 때문에 HashSet보다 성능상 느림
- LinkedHashSet
해쉬 테이블에 담는데
저장된 순서에 따라 순서가 결정됨
데이터 추가 테스트
메서드가 수행될때마다 1000번을 for문으로 돌면서 데이터를 추가하는 테스트를 진행
테스트 코드
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import javax.annotation.processing.Generated;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.MICROSECONDS) //밀리세컨드 단위로 출력
@Fork(value = 2, jvmArgs= {"-Xms4G", "-Xmx4G"}) //측정을 한번만 하는것은 벤치마크의 신뢰성에 문제가 있을 수 있다.
// 특정 시점에 시스템이 다른 이유로 갑자기 느려지거나 하는 상황이 있을 수 있기 때문에 최대한 외부 변수의 영향을 배제하기 위해 측정을 2회 실시한다.
//그리고 힙 영역의 공간 부족으로 인한 gc 오버헤드를 최소화 하기 위해 힙 영역의 크기를 4GB 로 설정한다.
public class SetAdd {
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(SetAdd.class.getSimpleName())
.forks(2)
.build();
new Runner(opt).run();
}
int LOOP_COUNT = 1000;
Set<String> set;
String data = "abcdefghigklmnopqrstuvwxyz";
@Benchmark
public void addHashSet(){
set = new HashSet<String>();
for (int loop=0; loop<LOOP_COUNT; loop++){
set.add(data+loop);
}
}
@Benchmark
public void addTreeSet(){
set = new TreeSet<String>();
for (int loop=0; loop<LOOP_COUNT; loop++){
set.add(data+loop);
}
}
@Benchmark
public void addLinkedHashSet(){
set = new LinkedHashSet<>();
for (int loop=0; loop<LOOP_COUNT; loop++){
set.add(data+loop);
}
}
}
테스트 결과
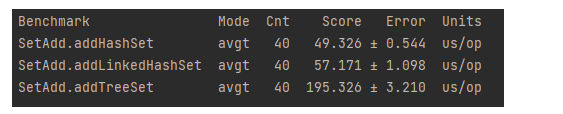
데이터 추가 테스트는
HashSet과LinkedHashSet이 성능이 비슷하다.
TreeSet은 데이터 추가시 동시에 정렬로 인해서 성능상 느리다.
부가 테스트
HashSet에서 미리 사이즈를 알고 있다면?
@Benchmark
public void addHashSetKnowSize(){
set = new HashSet<String>(LOOP_COUNT);
for (int loop=0; loop<LOOP_COUNT; loop++){
set.add(data+loop);
}
}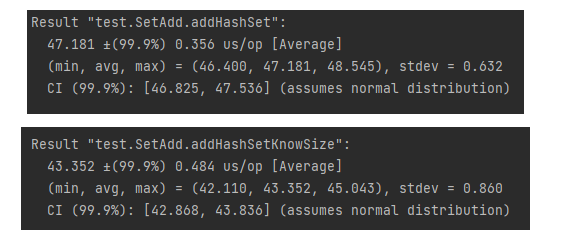
미세한 차이지만 사이즈를 알고있다면 데이터를 추가하는 속도가 미세하게 빠른것을 확인할 수 있다.
데이터 찾기(읽기) 테스트
LOOP_COUNT 까지의 데이터를 각 Set에 넣어두고 랜덤으로 생성한 데이터를 Set에서 찾는 테스트
테스트코드
package test;
import org.apache.commons.math3.genetics.RandomKey;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.*;
import java.util.concurrent.TimeUnit;
@State(Scope.Thread)
@BenchmarkMode({Mode.AverageTime})
@OutputTimeUnit(TimeUnit.MICROSECONDS) //밀리세컨드 단위로 출력
public class SetIterate {
int LOOP_COUNT = 1000;
Set<String> hashSet;
Set<String> treeSet;
Set<String> linkedHashSet;
String data = "abcdefghigklmnopqrstuvwxyz";
String[] keys;
String result = null;
@Setup(Level.Trial)
public void setUp(){
hashSet=new HashSet<>();
treeSet=new TreeSet<>();
linkedHashSet=new LinkedHashSet<>();
for (int loop=0; loop<LOOP_COUNT; loop++){
String tempData=data+loop;
hashSet.add(tempData);
treeSet.add(tempData);
linkedHashSet.add(tempData);
}
if(keys==null || keys.length!=LOOP_COUNT){
keys= RandomKeyUtil.generateRandomSetKeysSwap(hashSet);
}
}
@Benchmark
public void containHashSet(){
for(String key:keys){
hashSet.contains(key);
}
}
@Benchmark
public void containTreeSet(){
for(String key:keys){
treeSet.contains(key);
}
}
@Benchmark
public void containLikedSet(){
for(String key:keys){
linkedHashSet.contains(key);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(SetIterate.class.getSimpleName())
.forks(2)
.warmupIterations(5)
.measurementIterations(5)
.build();
new Runner(opt).run();
}
}
public class RandomKeyUtil {
public static String[] generateRandomSetKeysSwap(Set<String> set){
int size = set.size();
String[] result = new String[size];
Random random = new Random();
int maxNumber = size;
Iterator<String> iterator=set.iterator();
int resultPost=0;
while (iterator.hasNext()){
result[resultPost++]=iterator.next();
}
for(int loop=0; loop<size; loop++){
int randomNum1 = random.nextInt(maxNumber);
int randomNum2 = random.nextInt(maxNumber);
String temp=result[randomNum2];
result[randomNum2]=result[randomNum1];
result[randomNum1]=temp;
}
return result;
}
}
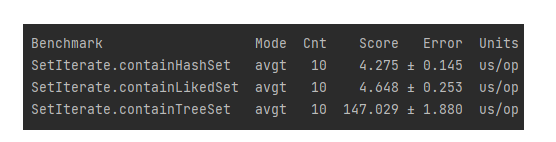
TreeSet이 가장 느렸으며나머지 두개는 비슷하게 빨랐다.
데이터를 순서에 따라서 탐색하는 작업에는
TreeSet이 좋으나그럴 필요가 없을땐
HashSet또는LinkedHashSet을 사용하자
+추가)
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable
TreeSet은
NavigableSet인터페이스를 구현하고 있으며 해당 인터페이스는 특정값보다 큰값/작은값,가장 큰값/가장 작은값 등을 추출하는 메서드를 지원한다.
따라서 순서에 따라 탐색하는 작업이 필요할땐 TreeSet을 사용하는것이 좋다.
