Link to pandas cheat sheet document
🐶 pandas 가독성 좋게 출력하기
import pandas as pd
import numpy as np
from tabulate import tabulate
col_name2 = ['title', 'img', 'url']
list2 = [['test title',2,3],
['test title 02',12,13]]
arr2 = np.array(list2)
# print('arr2 shape : ', arr2.shape)
df_list2 = pd.DataFrame(list2, columns=col_name2)
print('2차원 리스트로 만든 DataFrame:\n\n', df_list2)
print('\n\ntabulate 로 출력한 결과물')
print(tabulate(df_list2, headers='keys', tablefmt='psql', showindex=True))위 코드 출력결과 아래 사진 참조
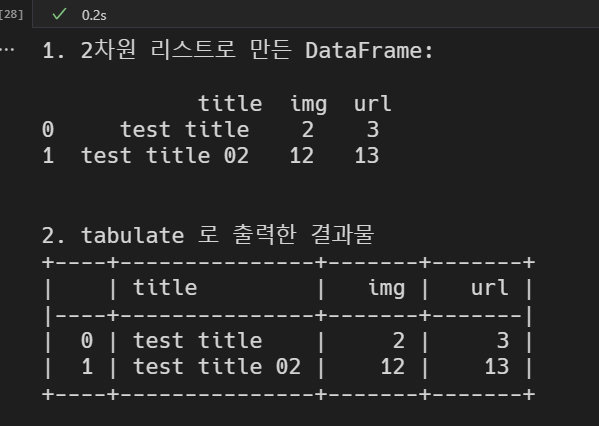
- 설명
💖 headers='keys'
이것은 각 컬럼의 이름(header)을 명시할지에 대한 여부입니다.
이것을 생략하면 컬럼이름이 보여지지 않습니다.
(dataframe의 key(column name)를 column name(header)로 사용하라는 의미)
💖 showindex=True
이 부분은 dataframe의 row index를 표시할지를 결정하는 부분입니다.
True -> row index 표시
False -> row index 표시 안함
💖 numalign='left' -> '숫자' 데이터를 어디로 정렬할지 결정합니다.
numalign='left' -> 숫자 왼쪽 정렬
numalign='right' -> 숫자 오른쪽 정렬
numalign='center' -> 숫자 가운데 정렬
💖 stralign='center' -> '텍스트' 데이터를 어디로 정렬할지 결정합니다.
stralign='left' -> 텍스트 왼쪽 정렬
stralign='right' -> 텍스트 오른쪽 정렬
stralign='center' -> 텍스트 가운데 정렬
💖 tablefmt='psql'
tablefmt 은 매우 다양합니다.
심지어 html 포맷으로 출력도 가능합니다.
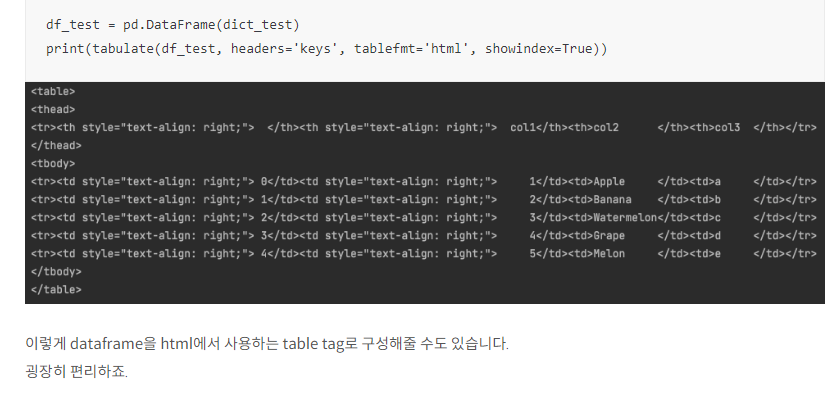
Table format
There is more than one way to format a table in plain text. The third optional argument named tablefmt defines how the table is formatted.
Supported table formats are:
"plain"
"simple"
"github"
"grid"
"simple_grid"
"rounded_grid"
"heavy_grid"
"mixed_grid"
"double_grid"
"fancy_grid"
"outline"
"simple_outline"
"rounded_outline"
"heavy_outline"
"mixed_outline"
"double_outline"
"fancy_outline"
"pipe"
"orgtbl"
"asciidoc"
"jira"
"presto"
"pretty"
"psql"
"rst"
"mediawiki"
"moinmoin"
"youtrack"
"html" 🤩
"unsafehtml" 🤩
"latex"
"latex_raw"
"latex_booktabs"
"latex_longtable"
"textile"
"tsv"
🐰 두 개의 판다스 데이터프레임에서 중복데이터(교집합)만 걸러내는 방법
아쉽지만 판다스에서 제공하는 join과 merge만 이용해서는 차집합만 바로 추출해서 볼 수가 없고, 3단계를 거쳐야 한다.
- join
- merge
import pandas as pd
df = pd.merge(df_a, df_b, how='outer', indicator=True) # dataframe merge
# 삭제할 2개의 dataframe을 병합(merger)합니다.
# print(df)
# 병합된 dataframe df 출력해보기
duplicates_data_removed_df = df.query('_merge == "right_only"').drop(columns=['_merge']) # dataframe query & some drop
print("중복 data 를 제거완료 하였습니다.")
print(duplicates_data_removed_df)🐮 명령어 모음
