-
실시간 서빙이 필요한 환경에서는 대규모 model 을 사용하기 곤란함.
-
latency 및 computing 자원 비용이 높기 때문 -> 이를 해결하기 위해 대규모 model 을 작은 model로 축소시키는 연구 진행
: 특히 대규모 ensemble model의 결과를 하나의 small model 에 transfer 하는 연구가 주목 받고 있음 -
model 을 학습하는 목적은 real data에서 좋은 성능을 내기 위함
-> 이를 위해서는 model 을 training 하는 데이터에서 general 한 특성을 뽑아내 학습해야 하는데, 실제로는 train data 내부의 special pattern 까지 학습을 하려 함.
e.g. classification task
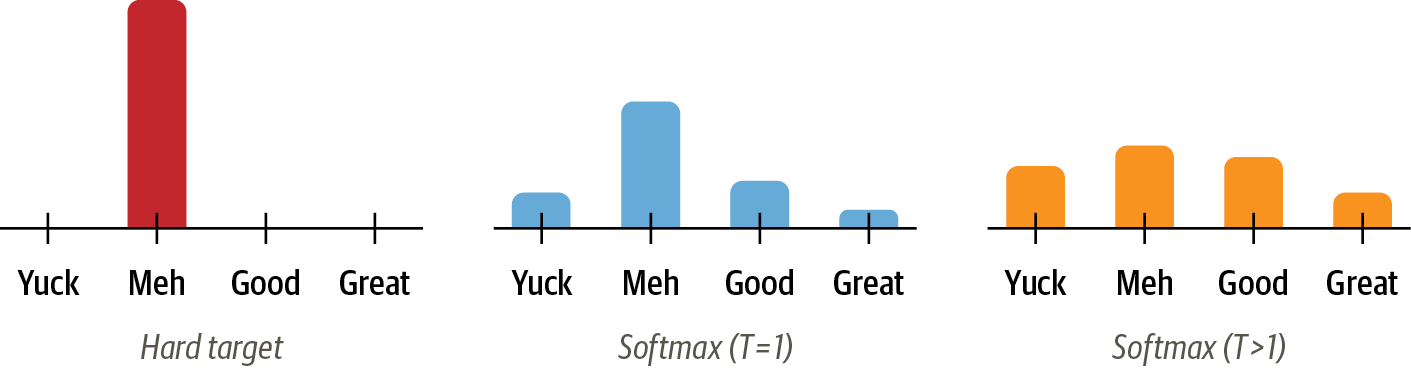
- 마지막 softmax logit 값은 대개 정답 category 값만이 높은 확률값을 가지고, 다른 category 는 낮은 값을 가져 최종적으로 가장 높은 category 값이 1로 도출됨
- 그러나, 조금이라도 확률이 존재한다는 것은 다른 category 에 비해 정답 category 와 유사성을 가진다는 것과 같음
- 이렇게 data의 상관 관계를 찾아내는 것이 general 한 특성을 학습하는 것인데, 해당 값들은 0에 가까운 값이기에 사실상 무시되기 마련
- 이 문제를 해결하기 위해 temperature 개념 도입
- softmax 함수에 값을 그대로 넣지 않고 temperature T로 나눈 값을 넣음.
- if T == 1 일 때, 기존 softmax 와 동일한 값이 나오지만 T가 증가할수록 더욱 soft한 값이 나온다.
- 구체적으로 large model 의 knowledge를 small model 로 distilling 하기 위해서는 large model 의 최종 softmax output 을 'soft target' 으로 지정해 small model 의 학습 과정에서 사용하는 것
- 결론적으로 small model은 2개의 target을 가짐
- large model 의 output 인 soft target
- 원래 label인 hard target
- 두 개의 target에 대해 loss 를 계산하며 학습을 해나간다.
- classification task 라고 가정했을 때 hard target 은 대개 one-hot encoding 방식으로 표현(정답 category = 1, 그외는 0으로 예측하고 싶음; but 현실에 존재 불가능), soft target은 실제로 model이 학습을 통해 도출된 결과
Distillation
해당 논문에서 모든 softmax 함수는 temperature T가 도입된 형태로 변경됨.
학습 과정
1. training set (x, hard target) 을 이용해 large model 학습
2. large model이 충분히 학습된 뒤에, large model의 output을 soft target으로 하는 transfer(x, soft target) 생성. 이때 soft target 의 T는 1이 아닌 높은 값을 생성 (클래스에 대한 완만한 확률붙포를 만들어 정보량을 많게 함)
3. transfer set을 사용해 small model 학습, T는 soft target을 생성할 때와 같은 값 사용
4. training set 사용해 small model 학습, T는 1로 고정
각각의 loss function 은 모두 cross-entropy-ross 를 사용함. 결국, small model 의 최종 loss function은 soft target 과의 cross-entropy-loss + hard-entropy-loss 가 됨
