study
1.transformer

2023년 9월 22일
2.DistillBERT
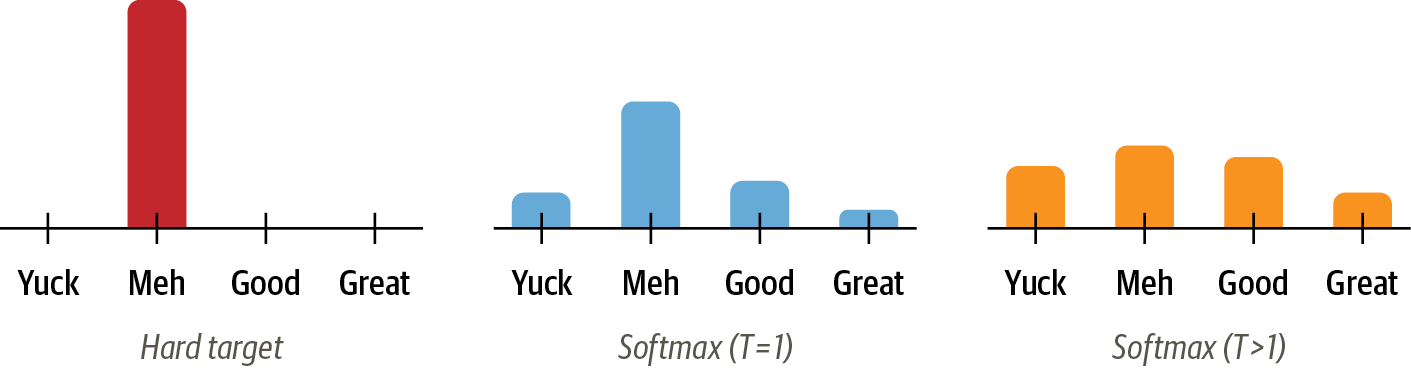
실시간 서빙이 필요한 환경에서는 대규모 model 을 사용하기 곤란함.latency 및 computing 자원 비용이 높기 때문 -> 이를 해결하기 위해 대규모 model 을 작은 model로 축소시키는 연구 진행: 특히 대규모 ensemble model의 결과를 하나
2023년 10월 9일
실시간 서빙이 필요한 환경에서는 대규모 model 을 사용하기 곤란함.latency 및 computing 자원 비용이 높기 때문 -> 이를 해결하기 위해 대규모 model 을 작은 model로 축소시키는 연구 진행: 특히 대규모 ensemble model의 결과를 하나