0702
- 다양한 변수의 타입을 확인해보고 hist를 활용해 카테고리형 변수와 연속형 변수를 구분
- 분류해준 연속형 변수를 hist를 통해서 분포를 확인
- 왜도와 첨도를 확인하여 분포가 치우쳐진 연속형 변수를 확인
(모델 학습 결과를 더 끌어올리기 위해서) - 분포가 치우쳐진 변수를 확인 후 추출하여 로그 변환
- 왜도, 첨도
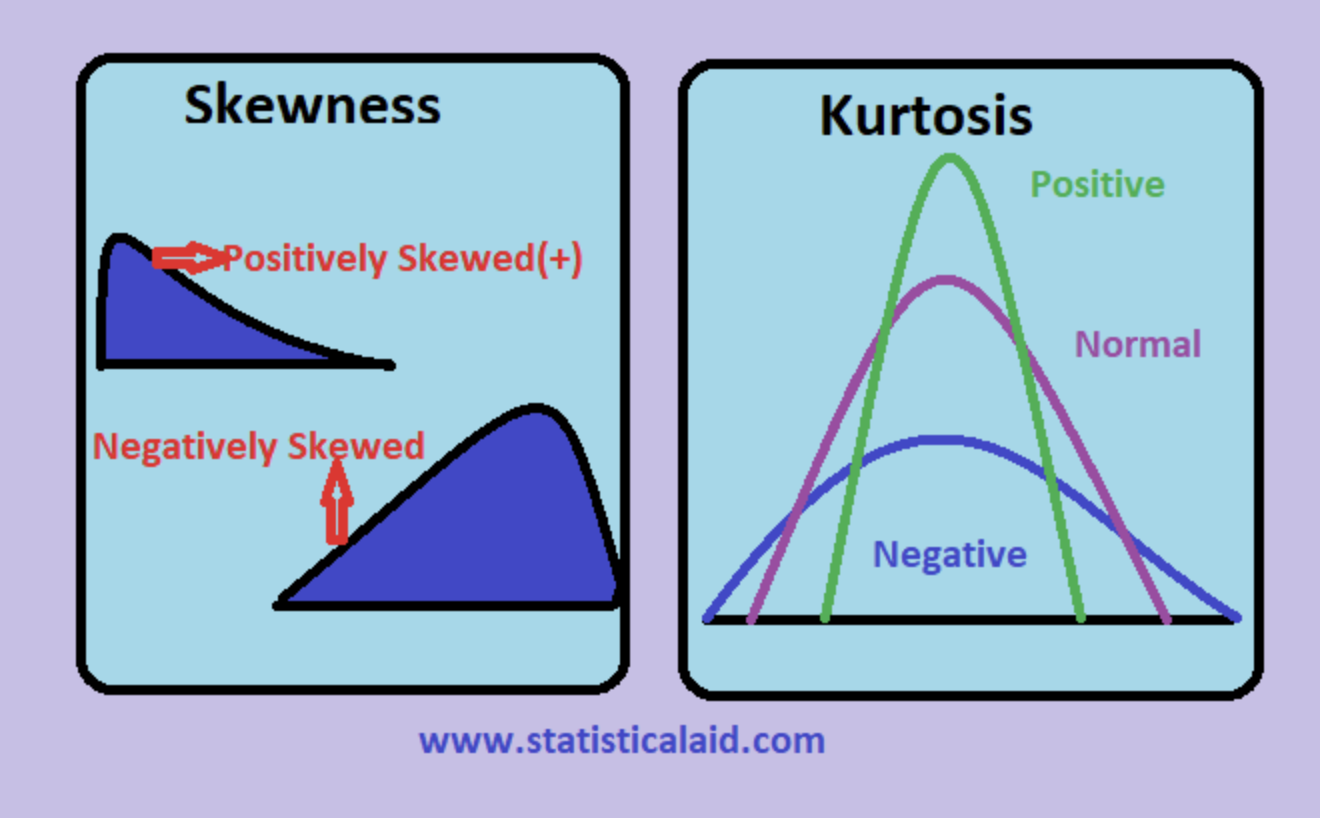
Positive Skewness는 오른쪽 꼬리가 왼쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 크는 것을 의미합니다.
Mean > Median > Mode
Negative Skewness 왼쪽 꼬리가 오른쪽보다 더 길 때를 의미하고 평균(Mean)과 중위수(Median)가 최빈값(Mode)보다 작는 것을 의미하게 됩니다.
Mode > Median > Mean
- .append() vs .extend()
# 봉지과자를 통째로 넣음
a = []
a.append([1, 2, 3])
a
> [[1, 2, 3]]# 봉지과자를 뜯어서 낱개로 넣음
a = []
a.extend([1, 2, 3])
a
> [1, 2, 3]여기서 말하는 과자의 봉지는 iterable 혹은 컨테이너라고 부른다.
list.append(x)는 리스트에 전달받은 요소(x)를 추가하는 메서드이며,
list.extend(iterable)은 순환 가능한 요소(iterable)를 인자로 받으며, 해당 컨테이너 안에 있는 모든 요소들을 리스트에 추가한다. 🪄 train, test가 concat 되어 있는 상태라면 get_dummies를 사용하는 것이 가장 간단
✔️ ELT vs ETL?
-
ETL
: 전통적으로 다양한 데이터를 추출(E)해서, 원하는 형식으로 변환(T)하여, 저장(L)하는 기술
🪄 데이터 웨어하우스에서 작동하며 데이터를 추출하고 (E) -> 변환하여 (T) -> 데이터를 적재하는 (L) 순서로 데이터를 처리하는 프로세스 -
ELT
: ETL과 달리 데이터를 추출(E)한 이후에 변환없이 그대로 저장(L)한 후 원하는 방식으로 변환(T)하는 방식
🪄 데이터 레이크에서 작동하며 데이터를 추출하고 (E) -> 적재한 다음 (L) -> 데이터를 변환하는 (T) 순서로 데이터를 처리하는 프로세스
수치형
- 결측치 대체(Imputation)
- 수치형 변수를 대체할 때는 원래의 값이 너무 왜곡되지 않는지도 주의가 필요
- 중앙값(중간값), 평균값 등의 대표값으로 대체할 수도 있지만,
- 당뇨병 실습에서 했던 회귀로 예측해서 채우는 방법도 있음.
- 당뇨병 실습에서 했던 인슐린을 채울 때 당뇨병 여부에 따라 대표값을 구한 것 처럼
- 여기에서도 다른 변수를 참고해서 채워볼 수도 있음.
- 스케일링 - Standard, Min-Max, Robust
- 변환 - log
- 이상치(너무 크거나 작은 범위를 벗어나는 값) 제거 혹은 대체
- 오류값(잘못된 값) 제거 혹은 대체
- 이산화 - cut, qcut
범주형
- 결측치 대체(Imputation)
- 인코딩 - label, ordinal, one-hot-encoding
- 범주 중에 빈도가 적은 값은 대체하기
0801
✔️ 이전에도 피자에 치즈가 적절히 뿌려졌는지를 확인하는 머신 비전 시스템을 설치했지만, 이는 여러 개의 토핑이 있는 피자의 결함은 감지하지 못했다.
어떻게 해석할 수 있을까?
->기존 피자치즈가 적절히 뿌려졌는지 확인하는 데이터에만 과대적합(오버피팅)이 되어 새로운 데이터가 들어왔을 때 일반화 하지 못하는 문제
✔️ nunique()값이 1인 데이터 처리 이유?
-> 변수를 살펴보고 변별력이 없는 변수(단일한 값만 가지고 있는 변수)를 삭제하는 과정
✔️ heatmap을 하는 이유?
-> 전체적인 수치데이터의 분포를 알아보기 위해
- OneHotEncoder(handle_unknown="ignore")
-> test 컬럼에 있으나 train 컬럼에 없는 경우에는 train 없는 컬럼에 대해서 원핫인코딩을 진행하지 않고 무시
