0801
-
import os
: Operating System의 약자로서 운영체제에서 제공되는 여러 기능을 파이썬에서 수행할 수 있게 해줌.
(ex. 파이썬을 이용해 파일을 복사하거나 디렉터리를 생성하고 특정 디렉터리 내의 파일 목록을 구하고자 할 때 os 모듈을 사용하면 됨. os 모듈은 다양한 기능을 제공.) -
Hold-out-validation
-> Hold-out-validation이 cross validation에 비해 빠름.
-> 단점 : 성능 추정에 민감한 영향을 미침.
(만약 데이터셋 전체가 개수가 크지 않다면, 이러한 분할은 치명적일 수 있다.
즉, 홀드아웃 셋을 만들어 내는 것 자체에 대단한 신경을 써야한다는 것이다.)
🪄 randome_state?
scikit learn에서 사용하는 randome_state는 성능을 위해서라기 보다는, 수행 시마다 동일한 결과를 얻기 위해 적용합니다.
예를 들어 random_state=1 이라고 하면 random 함수의 seed 값을 고정시키기 때문에 여러번 수행하더라도 같은 레코드를 추출합니다.
random 함수의 seed값을 random_state라고 생각하시면 됩니다.
train_test_split 시에 역시 random 함수가 적용되기 때문에
random_state에 따라서 점수가 아주 조금씩 차이날 수는 있습니다
- 선형회귀란?
: 한 개 이상의 독립 변수 x와 y의 선형 관계를 모델링
(변수 x의 값은 독립적으로 변할 수 있는 것에 반해, y값은 계속해서 x의 값에 의해서, 종속적으로 결정되므로 x를 독립 변수, y를 종속 변수라고도 한다.)
0802
: 다른 트리모델을 사용해 보는 것이 목적
그래디언트 부스팅 트리 모델
: from sklearn.ensemble import GradientBoostingRegressor
- 흔히 GBT라고 줄여 부르는 Gradient Boosting Tree 모델은 트리를 이용한 앙상블 모델
- 앙상블은 내부적으로 여러 모델을 생성한 후 모델들을 종합해 최종 모델을 생성하는 방법론
- GBT는 부스팅이라는 앙상블 기법을 사용
엑스트라 트리 모델
: from sklearn.ensemble import ExtraTreesRegressor
-
엑스트라 트리 모델은 극도로 무작위화(Extremely Randomized Tree)된 모델
-
랜덤 포레스트에서와 같이 후보 기능의 무작위 하위 집합이 사용되지만 가장 차별적인 임계값을 찾는 대신 각 후보 기능에 대해 임계값이 무작위로 그려지고 무작위로 생성된 임계값 중 가장 좋은 것이 분할 규칙으로 선택
-
랜덤 포레스트와 거의 유사한 작동법
-
이것은 일반적으로 약간 더 큰 편향 증가를 희생시키면서 모델의 분산을 조금 더 줄일 수 있음.
-
Bagging vs Boosting
-> Bagging : 데이터 셋 모델마다 독립적
배깅은 훈련세트에서 중복을 허용해서 샘플링하여 여러개 모델을 훈련 하는 앙상블 방식입니다. 같은 훈련 샘플을 여러 개의 모델에 걸쳐 사용해서 모든 모델이 훈련을 마치면 앙상블은 모든 예측기의 예측을 모아서 새로운 샘플에 대한 예측을 만들게 됩니다.
배깅 방식은 부트스트래핑을 해서 트리를 병렬적으로 여러 개 만들기 때문에 오버피팅 문제에 좀 더 적합합니다.
-> Boosting : 앞 모델이 데이터 셋 정해줌
부스팅은 약한 모델을 여러개 연결해서 강한 모델을 만들어 내기 위한 앙상블 방식입니다. 부스팅의 아이디어는 앞의 모델들을 보완해 나가면서 일련의 모델들을 학습시켜 나가는 것입니다.
개별 트리의 낮은 성능이 문제일 때는 이전 트리의 오차를 보완해 가면서 만들기 때문에 부스팅이 좀 더 적합니다.
✔️ GBM, XGBoost, LightGBM 모델이름에 들어가는 G 는 무엇을 의미?
-> G(Gradient, 경사/기울기)
-> 그래디언트 부스팅은 에이다 부스트와 달리 샘플의 가중치를 수정하는 대신 이전 모델이 만든 잔여 오차에 대해 새로운 모델을 학습시키게 됨.
-> 부스팅에서 대표적인 모델 중 하나는 에이다입니다. 에이다 부스트는 앙상블에 이전까지의 오차를 보정하도록 모델을 순차적으로 추가
✔️ Gradient(경사, 기울기)는 어떻게 사용할까?
-> 오차를 측정할 때 사용
-> 손실함수 그래프에서 값이 가장 낮은 지점으로 경사를 타고 하강합니다. 머신러닝에서 예측값과 정답값간의 차이가 손실함수인데 이 크기를 최소화시키는 파라미터를 찾기 위해 사용합니다.
🪄 경사하강법 이란?
예측값과 정답값 사이에 손실이 최소화될수록 좋은 모델이다.
손실이 가장 작은 지점을 찾기 위해서 기울기가 0인 지점을 찾기 위해서
경사를 점점 내리는 것을 경사하강법이라고 한다.
따라서 경사하강법의 목적은 손실함수가 가장 작고, 예측을 잘 하는 모델의 파라미터를 찾기 위함이다.
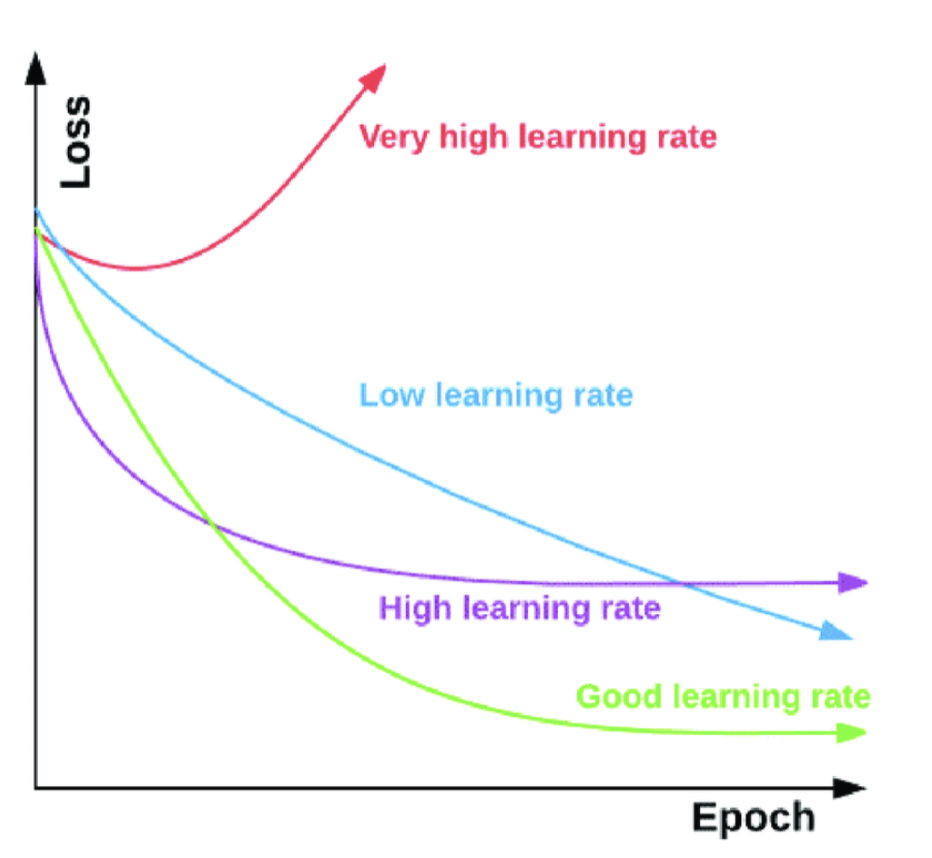 출처:
출처: -
epoch == n_estimators 같은 개념. 부스팅 트리에서 n_estimators는 몇 번째 트리인지를 의미.(epoch 학습 횟수)
-
Very high learnin rate == Big Learning Rate
✔️ Residual 란?
-> 오자, 잔차 같은 의미.(오차와 잔차도 다른의미로 보기도 하기 때문에 여기에서는 잔차에 더 가까움)
✔️ 성능에 고려 없이 GBM 에서 훈련시간을 줄이려면 어떻게 하면 좋을까?
보폭(learning_rate, 학습률, 보폭 보통 같은 의미)을 크게 하면 훨씬 빨리 걷게 됨. 그렇기 때문에 learning_rate를 올리면 학습시간은 줄어들지만 제대로 된 loss(손실)가 0이 되는 지점을 제대로 찾지 못할 수도 있음.
✔️ GBM 은 왜 랜덤 포레스트와 다르게 무작위성이 없을까?
-> 이전 오차를 보완해서 순차적으로 만들기 때문에 (ex. 오답노트)
✔️ 희소한 데이터란?
-> 0이 많은 데이터
✔️ 트리계열 알고리즘 하이퍼파라미터?
- criterion: 가지의 분할의 품질을 측정
- max_depth: 트리의 최대 깊이
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수
- min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
- max_leaf_nodes: 리프 노드 숫자의 제한치
- random_state: 추정기의 무작위성을 제어. 실행했을 때 같은 결과가 나오도록 함.
✔️ Boosting 알고리즘을 사용하는 모델 알고리즘?
- GBM
- XGBoost
- LightGBM
- CatBoost
✔️ Gradient Boosting 모델의 특징
- 랜덤 포레스트와 다르게 무작위성이 없음.
- 매개변수를 잘 조정해야 하고 훈련 시간이 김.
- 데이터 스케일에 구애받지 않음
- 고차원의 희소한 데이터에 잘 작동하지 않음.
