KMOOC 실습으로 배우는 머신러닝 강의 정리 내용
4 -2,3
경사하강법
- gradient descent (steepest descent 방법)
- 함수 값이 낮아지는 방향으로 독립 변수 값을 변형시켜가면서 최종적으로는 최소 함수 값을 갖도록 하는 독립 변수 값을 찾는 방법
- gradient descent는 함수의 기울기(즉, gradient)를 이용해
x의 값을 어디로 옮겼을 때 함수가 최소값을 찾는지 알아보는 방법
- step size
: 이동 거리의 조정 값
장점step size가 큰 경우 한 번 이동하는 거리가 커지므로 빠르게 수렴할 수 있음. (step size를 너무 크게 설정해버리면 최소값을 계산하도록 수렴하지 못하고 함수 값이 계속 커지는 방향으로 최적화가 진행될 수 있음.)
단점step size가 너무 작은 경우 발산하지는 않을 수 있지만 최적의 x를 구하는데 소요되는 시간이 오래 걸림.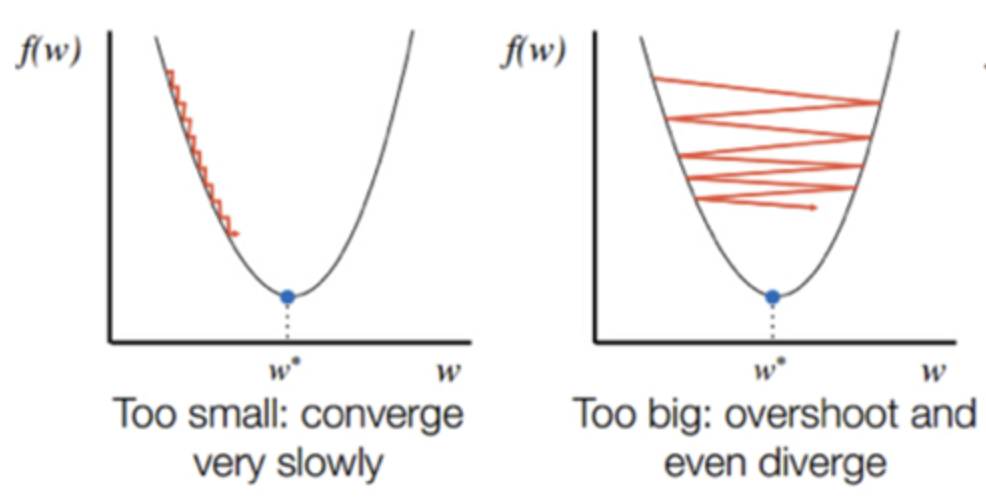
6 -1,2
Decision Tree
: 분류와 회귀 작업 및 다중출력 작업도 가능한 다재다능한 머신러닝 방법론
- IF-THEN 룰에 기반해 해석이 용이함
- 일반적으로 예측 성능이 우수한 랜덤 포레스트 방법
- CART 훈련 알고리즘을 이용해 모델을 학습
- 전체적인 모양이 나무를 뒤짚어 높은 것과 같아서 이름이 Decision Tree
결정 트리에서 질문이나 정답을 담은 네모 상자를 노드(Node), 맨 처음 분류 기준
(즉, 첫 질문)을 Root Node, 맨 마지막 노드를 Terminal Node 혹은 Leaf Node
- 불순도 (Impurity)
: 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지
아래 그림에서 위쪽 범주는 불순도가 낮고, 아래쪽 범주는 불순도가 높다. 바꾸어 말하면 위쪽 범주는 순도(Purity)가 높고, 아래쪽 범주는 순도가 낮습니다. 위쪽 범주는 다 빨간점인데 하나만 파란점이므로 불순도가 낮다고 할 수 있습니다. 반면 아래쪽 범주는 5개는 파란점, 3개는 빨간점으로 서로 다른 데이터가 많이 섞여 있어 불순도가 높습니다.
 출처: https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
출처: https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
- CART (Classification And Regression Tree)
:불순도를 최소화하도록 최종 노드를 계속 이진 분할하는 방법론

Today I Learn