KMOOC 실습으로 배우는 머신러닝 강의 정리 내용
7 -1,2,3
Ensemble Learning
: 대중의 지혜(집단지성)
앙상블 학습은 여러 개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법이다. 앙상블 학습의 핵심은 여러 개의 약 분류기 (Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 것이다. 그리하여 모델의 정확성이 향상된다.
-
일련의 분류나 회귀 모델로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측 성능을 얻을 수 있음.
-> 앙상블 학습 -
일반적으로 다양한 머신러닝 기법들을 Ensemble 시켜주면 성능이 향상되는 효과를 얻을 수 있음
-
랜덤 포레스트는 Decision Tree의 Ensemble을 의미하고, 일반적으로 굉장히 Robust하고 좋은 예측 성능을 보이는 것으로 알려져 있음.
-
데이터의 작은 변화에 민감한 Decision Tree의 한계점을 ensemble을 이용해 극복 가능
-
앙상블 학습법
-
배깅(Bootstrap Aggregation)
(복원추출) <-> Pasting (비복원추출)
: 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법
✓ 간단하면서도 파워풀한 방법
✓ 배깅 기법을 활용한 모델 : 랜덤 포레스트 -
부스팅
: 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법
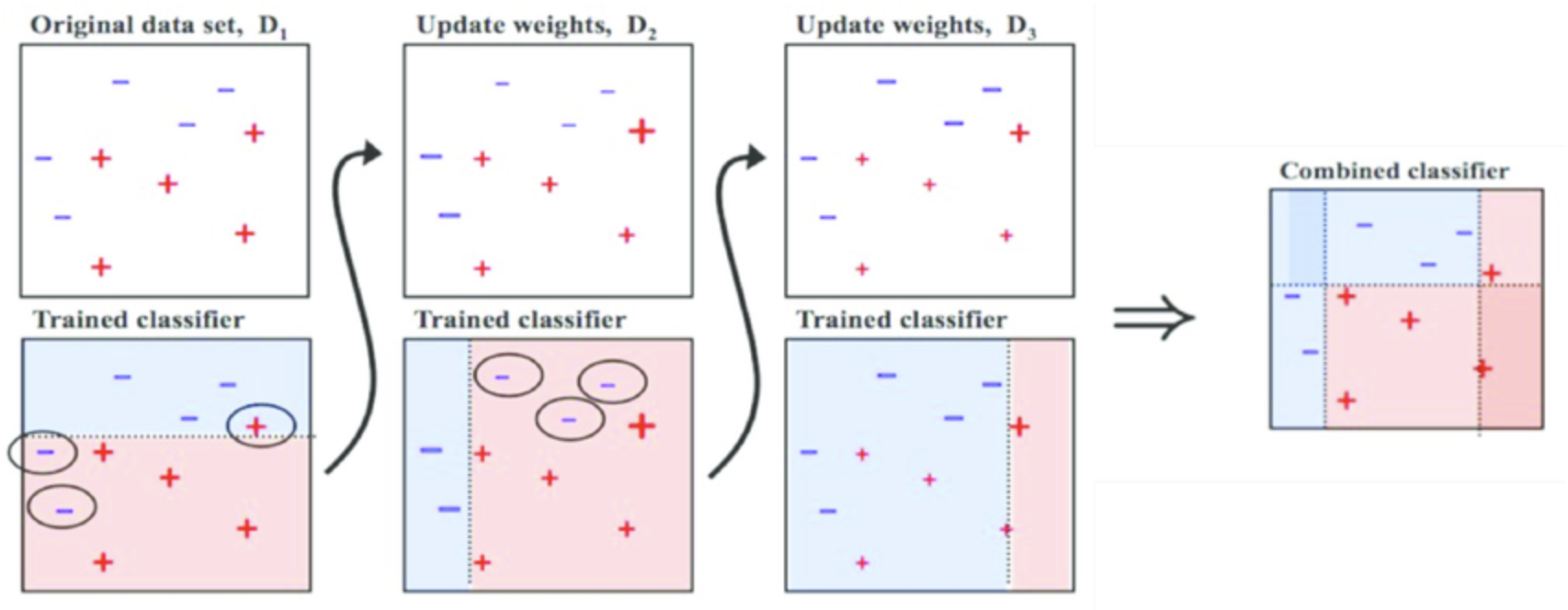
✓ 에이다부스트 (Ada Boost)
✓ 그래디언트부스트 (Gradient Boosting)
-

8 -1
PCA (Principal Component Analysis)
: 고차원의 데이터를 저차원의 데이터로 축소시키는 차원 축소 방법 중 하나
차원 축소는 많은 피쳐로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것이다.
피쳐가 많아질수록 예측 신뢰도가 떨어지고, 과적합(overfitting)이 발생하고, 개별 피쳐간의 상관관계가 높을 가능성이 있다.
✔️ 차원축소를 하는 이유?
-> 시각화
-> 노이즈 제거
-> 메모리 절약
-> 퍼포먼스 향상
