✔️ 정확도로 제대로 된 모델의 성늘을 측정하기 어려운 사례는?
-> 금융 => 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부
-> 제조업 => 양불(양품, 불량품) 여부
-> 헬스케어 => 희귀질병(암 진단여부)
-> IT관련 => 게임 어뷰저, 광고 어뷰저, 그외 어뷰저
대회에서 어뷰저 관련 내용을 찾을 때는 Fraud 등으로 검색하면 여러 사례를 찾을 수 있음
기존에는 예측을 할 때 주로 predict 를 사용했지만 predict_proba 를 하게 되면 0,1 등의 클래스 값이 아닌 확률값으로 반환합니다.
임계값(Threshold)을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 합니다.
0804
# stratify : 지정한 data의 비율을 유지
# 예를들면 label set인 y가 20%의 0과 80%의 1로 이루어진 binary set일 때,
# stratify=y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 20%, 80%를 유지한 채 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
> ((213605, 30), (71202, 30), (213605,), (71202,))# predict_proba : 확률값을 예측
model.predict_proba(X_test)[:5]
> array([[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.]])# np.argmax : 값이 가장 큰 인덱스를 반환
import numpy as np
y_pred_proba_class = np.argmax(y_pred_proba, axis=1)
y_pred_proba_class
> array([0, 0, 0, ..., 0, 0, 0])# 데이터 재구조화
pd.crosstab(y_test, y_pred)
> col_0 0 1
Class
0 71052 27
1 38 85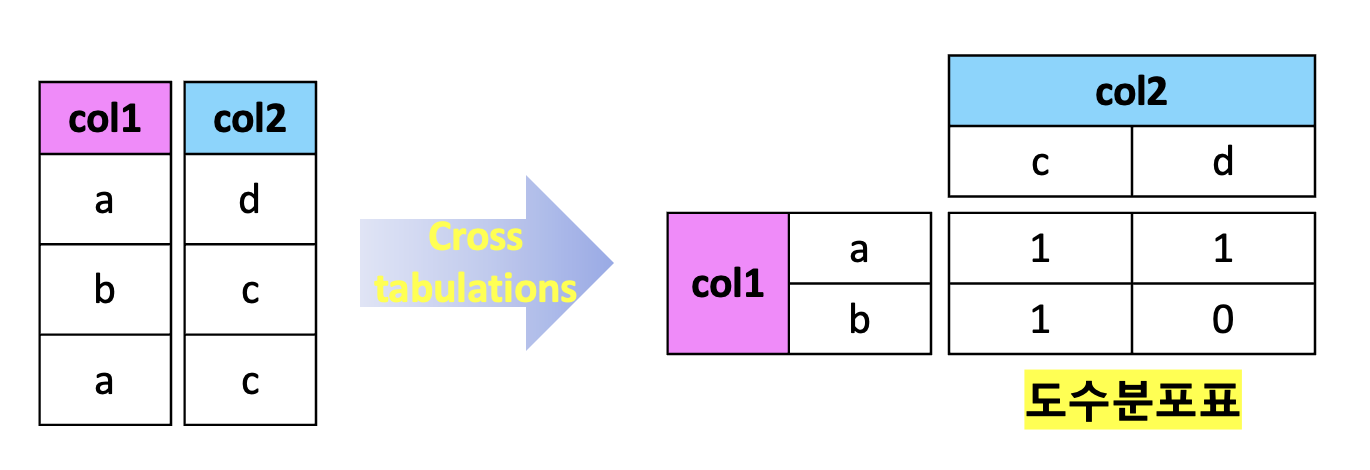
✅ CrossTab은 Pivot Table의 일종, Pivot Table의 특수한 형태
✅ 두 Column의 교차 빈도, 비율, 덧셈 등을 구할 때 주로 사용
# 27, 38이 오류값
from sklearn.metrics import confusion_matrix
cf = confusion_matrix(y_test, y_pred)
cf
> array([[71052, 27],
[ 38, 85]])# seaborn과 같은 sklearn 자체적인 기능
sns.heatmap(cf, annot=True, cmap='Blues')
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay(cf).plot()from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
> precision recall f1-score support
0 1.00 1.00 1.00 71079
1 0.76 0.69 0.72 123
accuracy 1.00 71202
macro avg 0.88 0.85 0.86 71202
weighted avg 1.00 1.00 1.00 71202언더샘플링
# # 1인 데이터가 492개이기 때문에 0인 데이터를 랜덤하게 492개 추출하면 언더샘플링
y.value_counts()
> 0 284315
1 492
df_0 = df[df['Class'] == 0].sample(492)
df_1 = df[df['Class'] == 1]
df_0.shape, df_1.shape
> ((492, 31), (492, 31))
df_under = pd.concat([df_0, df_1])
df_under['Class'].value_counts()
> 0 492
1 492오버샘플링
# SMOTE(Synthetic Minority Over-sampling Technique)합성 소수자 오버샘플링 기법
# X, y를 학습하고 다시 샘플링(fit_resample)
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_resample, y_resample = sm.fit_resample(X, y)
X.shape, X_resample.shape
> ((284807, 30), (568630, 30))
y.shape, y_resample.shape
> ((284807,), (568630,))
y.value_counts()
> 0 284315
1 492
y_resample.value_counts()
> 0 284315
1 284315SMOTE를 사용한 오버샘플링 데이터로 모델을 만들어 예측한 결과를 비교했습니다.
샘플링을 사용하지 않고 데이터를 나눠 학습했을 때와 비교해서 f1_score, precision, recall 값이 모두 높아졌음을 알 수 있습니다.
정답 클래스가 불균형하면 학습을 제대로 하기 어렵기 때문에 오버샘플링이나 언더샘플링으로 정답 클래스를 비슷하게 만들어 주면 좀 더 나은 성능을 냅니다.
✔️ classification_report를 했을 때 값이 1이다?
-> 반올림 한 결과이기 때문에 confusion_matrix를 통해 정확하게 확인 가능
💡 precision은 예측값 기준 => 1종 오류
💡 recall 실제값 기준 => 2종 오류
가중치와 편향을 도출하는 역전파 과정에서 미분 기법을 이용하게 됩니다. 하지만 활성화함수를 sigmoid와 tanh 함수로 설정하게 되면 이 미분과정에서 기울기가 0으로 수렴하게 됩니다. 따라서 점점 기울기가 사라지고 이에 따른 가중치와 편향 도출이 어려워지는 문제가 발생합니다.
