✔️ 배깅과 부스팅 중 어떤 것을 선택해야 할까?
-> 개별 결정 트리의 낮은 성능이 문제라면 부스팅이 적합하고, 오버 피팅이 문제라면 배깅이 적합하다.
✔️ 왜 learning_rate가 낮을때 n_estimator 값을 높여야 과적합이 방지될까?
-> learning_rate를 줄인다면 가중치 갱신의 변동폭이 감소해서, 여러 학습기들의 결정 경계(decision boundary) 차이가 줄어들게 된다.
n_estimators 를 늘린다면 생성하는 약한 모델(weak learner)가 늘어나게 되고, 약한 모델이 많아진만큼 결정 경계(decision boundary)가 많아지면서 모델이 복잡해지게 된다.
즉, 부스팅알고리즘에서 n_estimators와 learning_rate는 trade-off 관계입니다.
n_estimators(또는 learning_rate)를 늘리고, learning_rate(또는 n_estimators)을 줄인다면 서로 효과가 상쇄된다.
-> n_estimator : (랜덤포레스트와 다르게) 순차적으로 생성되기 때문에 학습횟수를 의미
✔️ 부스팅 모델은 왜 오버피팅에 민감할까?
-> 이전 트리(이전 학습)가 다음 트리(다음 학습)에 영향을 주기 때문에
0803
✔️ category type으로 변경하는 이유?
-> lightGBM, CatBoost 에서는 범주형 피처를 인코딩 없이 사용할 수 있다.
XGBoost
import xgboost (as xgb)- GBT에서 병렬 학습을 지원하여 학습 속도가 빠름
- 기본 GBT에 비해 더 효율적이고, 다양한 종류의 데이터에 대응할 수 있으며 이식성이 높음
LightGBM
import lightgbm (as lgbm)- XGBoost에 비해 성능은 비슷하지만 학습 시간을 단축
- XGBoost에 비해 더 적은시간, 더 적은 메모리를 사용
CatBoost
import catboost
# verbose : 로그 출력 제외
catboost.CatBoostRegressor(eval_metric='R2', verbose=False)- 기존 GBT의 느린 학습 속도와 과대적합 문제를 개선
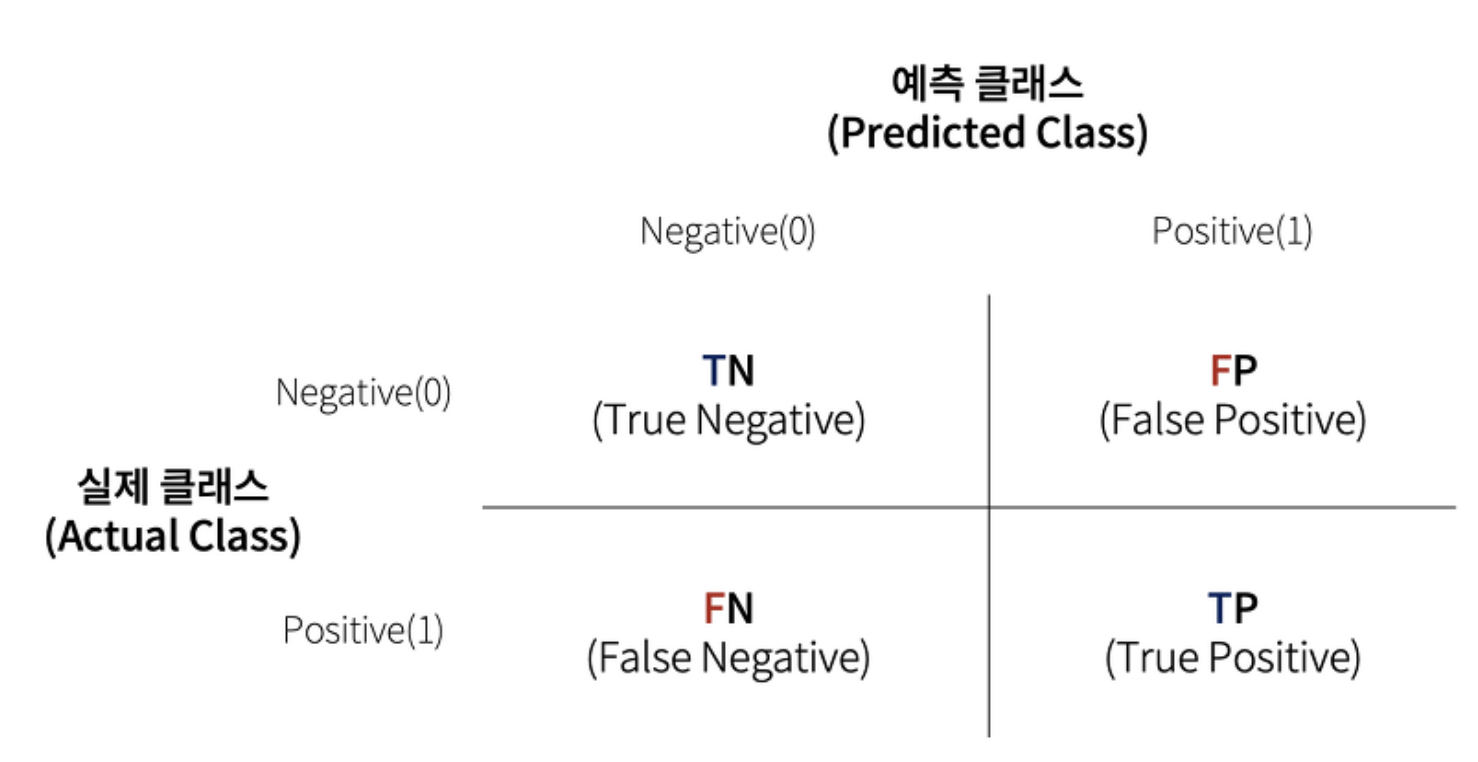
예측값이 1인 것을 기준으로 하는 계산 -> Precision
실제값이 1인것을 기준으로 하는 계산 -> Recall
✔️ 불균형데이터에서 혼동행렬이 필요한 이유는?
만약에 내가 만든 모델이 특정 질병을 탐지하는 모델이라고 할때 실제로 만들어진 모델이 전부 병에 걸렸다고 판단하는 멍청한 모델이 만들어졌다해도, 실제 샘플 데이터가 100만개가 질병이 걸린 사람의 샘플이고 10개만 질병이 걸리지 않은 사람의 샘플이라면 99.99프로로 내가 만든 모델이 정확하게 작동하는 것 처럼 보일 수도 있다. 따라서 이런 Accuracy의 맹점을 보완하기위해 Precision과 Recall 같은 지표가 필요하게 된다.
💡 XGBoost 설명
- XGBoost의 목표는 손실 함수가 최대한 감소하도록 하는 split point(분할점)를 찾는 것이다.
- GBM 대비 빠른 수행 시간을 장점으로 꼽는다.
- Early Stopping(조기 종료) 기능이 있다.
💡 XGBoost에는 없는 LightGBM만의 특징?
- Leaf-wise tree growth
- GOSS
- EFB
💡 부스팅 모델은 왜 시각화가 가능할까?
-> 순차적으로 트리를 생성하기 때문
💡 혼동행렬
- 민감도(재현율): TP / (TP + FN)
- 특이도: TN / (TN + FN)
- 정확도: TP + TN / (TP +FN + FP + TN)
💡 분류성능평가지표
- 특이도(Specificity): 음성 가운데 맞춘 음성의 수
- 정밀도(Precision): 양성 가운데 맞춘 양성의 수
- 성능점수(F1 Score): 정밀도와 민감도의 조화평균
- 정확도(Accuracy): 전체 데이터에서 모델이 옳게 판단한 비율
