[python]_크롤링(3)_requests
requests
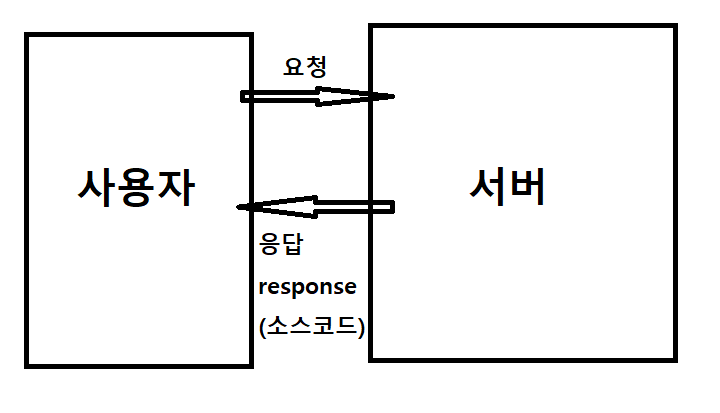
requests는 브라우저 없이 파이썬에서 다이렉트로 서버에 http요청을 넣습니다.
요청을 받은 페이지는 해당 페이지의 소스코드를 파이썬 내부로 전송해줍니다.
단, 버튼 클릭이나 광고 닫기 등의 작업은 애초에 브라우저가 없기때문에 불가능하고 오로지 특정 주소로 접속했을 때 최초에 전송되는 페이지 코드만 가져올 수 있습니다.
대신 물리 브라우저를 직접 켜지 않고, 명목상으로 요청만 하기 때문에
속도나 리소스면에서는 훨씬 우월합니다.
F12 > 네트워크탭에 서버와 주고받은 주소기록이 남음
2022-10-14 10:20:30 크롬브라우저 185.31.29.33 서울
2022-10-14 10:20:30 파이썬 185.31.29.33 서울
(브라우저) (주소)
- 내가 브라우저로 특정 서버 주소를 쳐서 접속시도를 합니다.
- 서버에 내가 접속한다는 요청이 들어갑니다.
- 서버가 요청에 응답하면서 response데이터를 함께 전송합니다.
- 브라우저가 받은 데이터를 해석해서 내 PC에 반영합니다
4-1. 웹사이트 접속이었으면 소스코드를 받아와서
사람이 볼 수 있도록 자동으로 그려줍니다.(렌더링해줍니다)
4-4. 게임이면 해당 명령어가 들어가서 게임상황에 반영됩니다.
requests를 이용한 크롤링은 브라우저가 없기 때문에 그려주지 못합니다.
# requests, beautifulsoup, time 임포트
import requests
from bs4 import BeautifulSoup
import time
# 특정 주소에 대한 요청은 requests.get("주소")로 합니다.
# 요청에 대한 서버의 응답(response)는 req 변수에 저장했습니다.
# 크롬이 아닌 파이썬을 이용해서 홈페이지 요청했기 때문에 브라우저로 보이는게 아니라 소스를 긁어옴
req = requests.get("http://www.naver.com")
# html소스코드 읽어오기(selenium의 .text와 문법은 같으나 기능이 다름에 주의)
# req.text를 이용하면 셀레니움의 driver.page_source와 동일한 코드를 받아옵니다.
type(req.text) # str
source = req.text
# http 헤더 가져오기
# 요청에 따른 상세 정보를 보여줍니다 지금은 이런게 있다는 것만 체크래주세요.
req.headers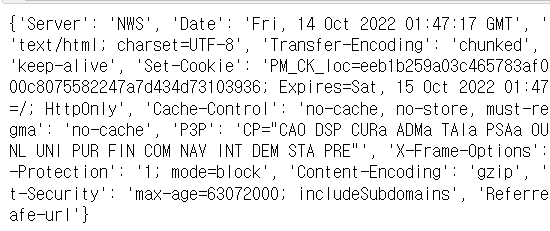
(참고)
404 # 주소없음
200 # 접속완료# http 상태코드 가져오기
req.status_code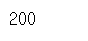
알라딘 베스트셀러 7페이지 크롤링
- requests를 이용해서 해주세요.
- beaurtifulsoup 구간부터는 selenium을 활용한 크롤링과 차이가 없습니다.
- 제목 저자 가격을 나열해주세요
req = requests.get('https://www.aladin.co.kr/shop/common/wbest.aspx?BestType=Bestseller&BranchType=1&CID=0&page=7&cnt=1000&SortOrder=1')
source = req.text
parsed_source = BeautifulSoup(source, "html.parser")
div_book_list = parsed_source.find_all("div", class_="ss_book_box")
book_li_list = []
for book in div_book_list:
book_li_list = book.find_all("li")
if (book_li_list[1].text[0] =='['):
print(book_li_list[1].text)
print(book_li_list[2].text)
print(book_li_list[3].text)
else:
print(book_li_list[0].text)
print(book_li_list[1].text)
print(book_li_list[2].text)
print("--------------------------") 

파이썬초짜의 기록