
다음 내용은 한빛미디어 <퀀트 전략을 위한 인공지능 트레이딩>을 공부하며 요약한 내용입니다.
Shift()
: 인덱스에 연결된 데이터를 일정 간격으로 이동시키는 함수.
- 인덱스에서는 변화없이 데이터 전, 후로 이동. 손쉽게 N일 전의 데이터를 가져올 수 있음
| 매개변수 | 기본 값 | 내용 |
|---|---|---|
| period | 1 | 전달된 정수 만큼 데이터가 이동. 음수가 전달되면 위로, 양수가 전달되면 아래로. |
| axis | 0 | 데이터의 이동 방향. 1 전달되면 오른쪽으로. |
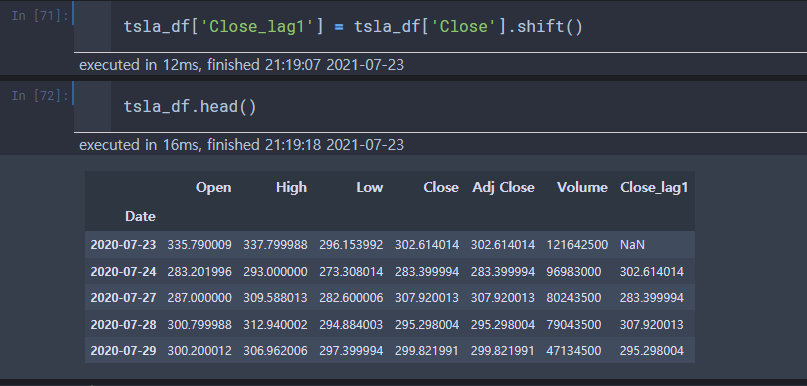
Close_lag1라는 변수로 한 칸 씩 데이터가 아래로 내려온 것을 확인할 수 있다.
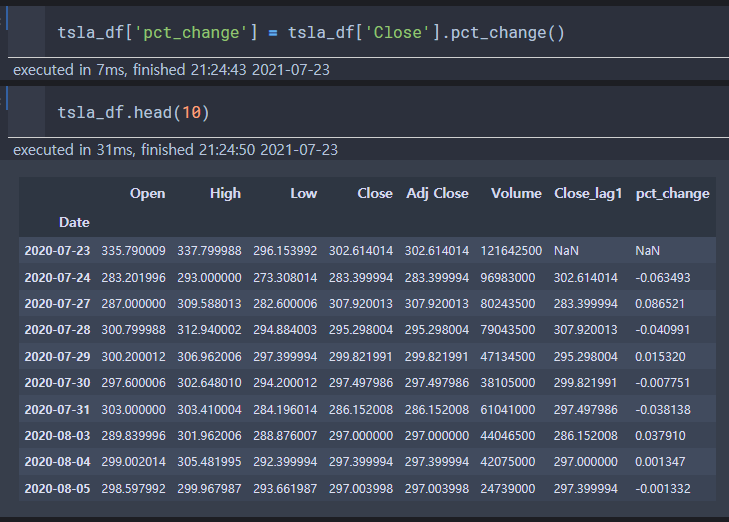
pct_change()
: 함수의 현재값과 이전 요소 값의 백분율 변화량을 연산하는 함수.
- 수익률을 계산할 때 자주 사용.
| 매개변수 | 기본 값 | 내용 |
|---|---|---|
| period | 1 | 정수형 데이터가 전달되면 숫자 간격만큼 데이터와 백분율을 계산함. 음수가 전달되면 위 방향으로 변화율이 계산되고, 양수가 전달되면 아래 방향으로 변화율이 계산됨 |
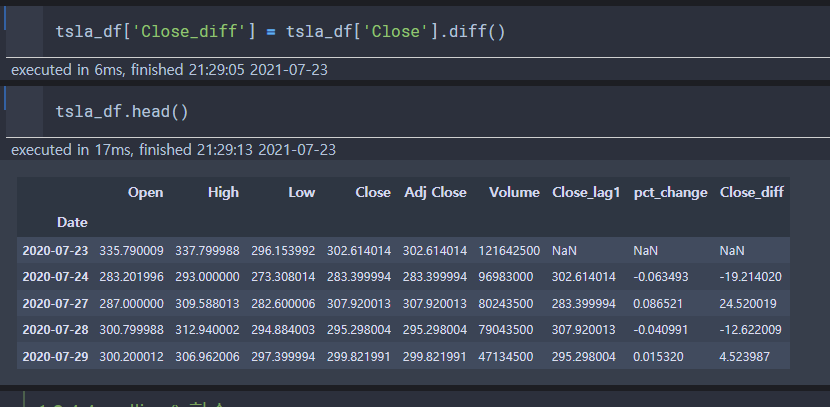
diff()
: 현재 값에서 이전 값을 차감하는 형식으로 변화량을 손쉽게 구하는 함수.
| 매개변수 | 기본 값 | 내용 |
|---|---|---|
| Period | 1 | 양수를 넣으면 한칸 아래로 미루고, 음수를 넣으면 한 칸 위로 올림. |
| axis | 0 | 1(columns)을 전달하면 오른쪽 칼럼 방향으로 계산을 수행. |
rolling()
: 윈도우 window의 평균값, 최솟값, 최댓값 등을 계산하는 함수. 윈도우 크기만큼의 데이터를 이용해 연산을 수행하기에 윈도우 함수라고도 불림.
- 윈도우 window : 일정 구간의 데이터
- 이동평균선, 지수 이동 평균, 볼리저 밴드를 계산할 때 사용
- 출력 타입 : Rolling 클래스
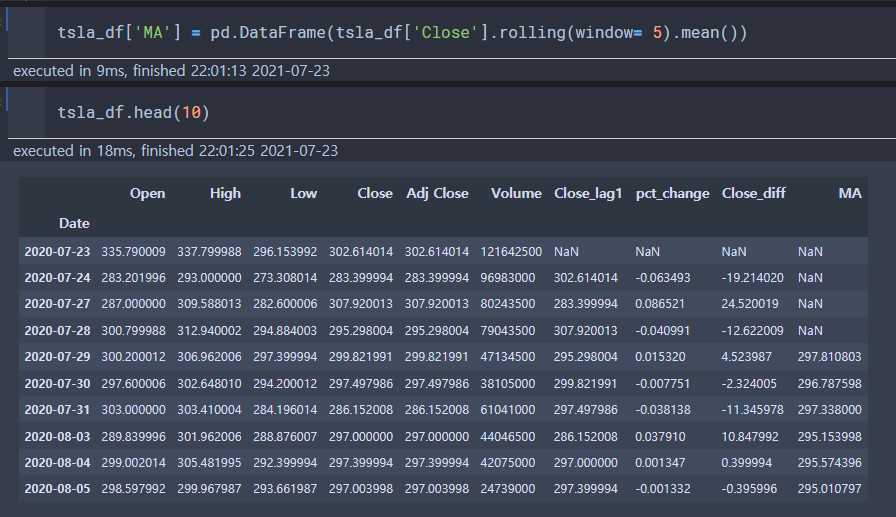
크기가 5인 윈도우를 한 칸씩 오른쪽으로 롤링. 5개 구간 평균을 구하거나 최댓값 혹은 최솟값 등의 집계함수를 체인해 계산할 수 있음.
윈도우 사이즈 5를 전달했으므로 5개의 데이터가 확보되지 않으면 NaN 값을 출력함.
( 이동 평균선을 계산할 때는 결측치가 생기는 것이 자연스럽기 때문에 NaN값을 그대로 둠 )
resample()
: 시간 간격을 재 조정하는 기능. 이미 확보한 데이터가 일별 데이터일 때 시간 간격을 재조정해 월별 데이터로 가공한다거나 일별 데이터를 시간별 데이터로 재조정할 때 사용.
- up-sampling : 분 단위, 초 단위로 샘플의 빈도수를 증가시킴
- interpolation 보간법을 사용해 누락된 데이터를 채움. - down-sampling : 몇 일, 몇 달 단위로 샘플의 빈도수를 감소시킴
- 기존 데이터를 aggregation하는 방법으로 데이터를 사용.
| 매개변수 | 기본 값 | 내용 |
|---|---|---|
| rule | 월말 일자를 기준으로 데이터를 정렬 |
-> rule에 전달하는 단위는 날짜 주기 단위와 같은 단위
참고 : https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html
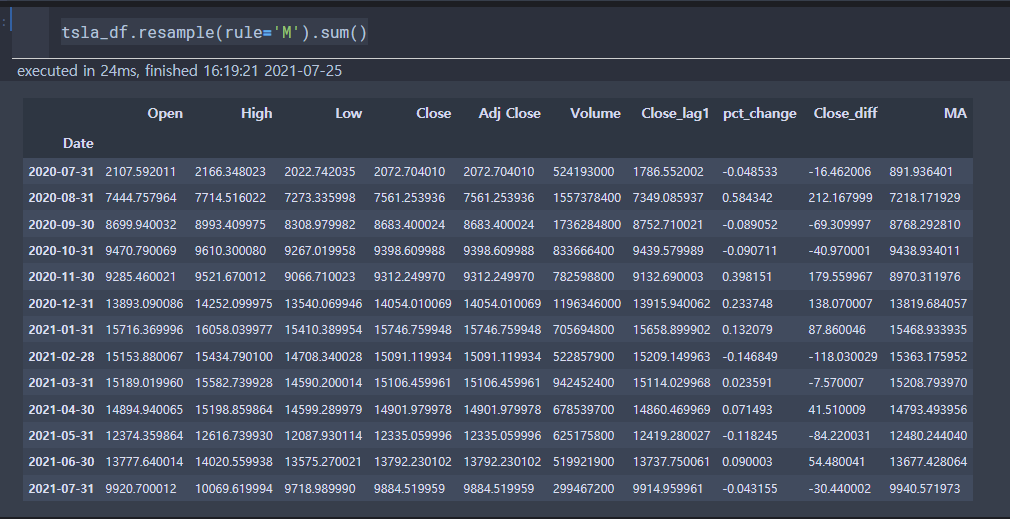
sum()으로 월별 합계를 계산
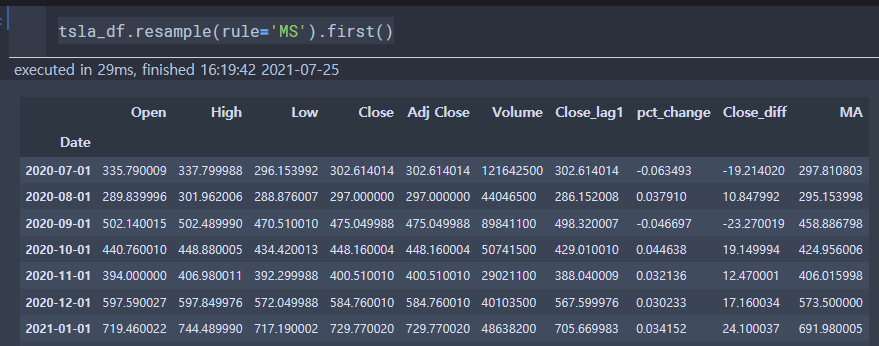
rule에 start를 의미하는 S를 붙여 'MS'를 전달하고, first()를 사용하면 월 초의 데이터가 나온다.
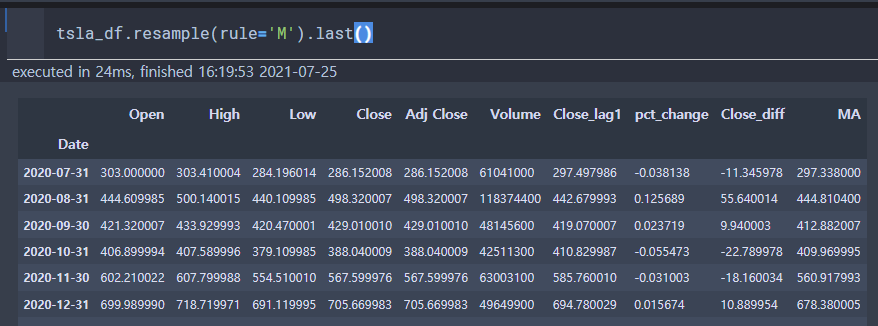
last()를 사용하면 월말 일자만 확인할 수 있다.

아무것도 모릅니다