다음 내용은 위키북스의 <텐서플로와 머신러닝으로 시작하는 자연어처리> 책을 공부하며 정리한 내용입니다.
사이킷런을 이용한 특징 추출
자연어 처리에서 특징 추출이란 텍스트 데이터에서 단어나 문장들을 어떤 특징 값으로 바꿔주는 것을 의미한다. 기존에 문자로 구성돼 있던 데이터 모델에 적용할 수 있도록 특징을 뽑아 어떤 값으로 바꿔서 수치화한다.
텍스트 데이터를 수치화하는 방법
- CountVectorizer : 각 텍스트에서 횟수를 기준으로 특징을 추출하는 방법
- TfidfVectorizer : TF-IDF라는 값을 사용해 텍스트에서 특징을 추출
- HashingVectorizer : CounterVectorizer와 사용방법은 동일하지만 텍스트를 처리할 때 해시 함수를 사용하기 때문에 실행 시간을 크게 줄일 수 있음. 텍스트의 크기가 클수록 HashingVectorizer를 사용하는 것이 좋음.
CountVectorizer
텍스트 데이터에서 횟수를 기준으로 특징을 추출하는 방법. 어떤 단위(단어,문장)의 횟수를 셀 것인지 선택할 수 있다.
- CountVectorizer 객체 생성
- 객체에 특정 텍스트를 적합 - 횟수를 셀 단어의 목록을 만드는 과정
- 횟수를 기준으로 해당 텍스트를 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
text_data = ['나는 배가 고프다','내일 점심 뭐먹지', ' 내일 공부 해야겠다', '점심 먹고 공부해야지']
count_vectorizer = CountVectorizer()
count_vectorizer.fit(text_data)
print(count_vectorizer.vocabulary_)결과
{'나는': 3, '배가': 7, '고프다': 0, '내일': 4, '점심': 8, '뭐먹지': 6, '공부': 1, '해야겠다': 9, '먹고': 5, '공부해야지': 2}
sentence = [text_data[0]] # ['나는 배가 고프다']
print(count_vectorizer.transform(sentence).toarray())결과
[[1 0 0 1 0 0 0 1 0 0]]
생성한 객체에 fit 함수를 적용하면 자동으로 단어 사전을 생성한다. 이를 활용해 단어를 벡터형태로 만들 수 있다.
| 고프다 | 공부 | 나는 | 내일 | 먹고 | 뭐먹지 | 배가 | 점심 | 해야겠다 | |
|---|---|---|---|---|---|---|---|---|---|
| 나는 배가 고프다 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
이처럼 간단하게 텍스트 데이터에서 특징을 추출할 수있다.
- 장점 : 횟수를 사용해서 벡터를 만들기 때문에 직관적이고 간단해서 여러 상황에서 사용할 수 있음.
- 단점 : 단순히 횟수만을 특징으로 잡기 떄문에 큰 의미는 없지만 자주 사용되는 단어 ( ex, 조사, 지시대명사)가 높은 특징 값을 가지기 때문에 유의미하게 사용하기 어려울 수 있음.
TfidfVectorizer
TF-IDF라는 특정한 값을 사용해서 텍스트 데이터의 특징을 추출하는 방법.
-
TF(Term Frequency) : 특정 단어가 하나의 데이터 안에서 등장하는 횟수.
-
DF (Document Frequency) : 문서 빈도 값으로, 특정 단어가 여러 데이터에 자주 등장하는지 알려주는 지표.
-
IDF (Inverse Document Frequency) : DF 값에 역수를 취한 것. 특정 단어가 다른 데이터에 등장하지 않을 수록 값이 커진 다는 것을 의미함.
-
TF-IDF : TF 값과 IDF 값을 곱해서 사용. 어떤 단어가 해당 문서에 자주 등장하지만 다른 문서에는 많이 없는 단어일수록 높은 값을 가짐.
-> 조사나 지시대명사처럼 자주 등장하는 단어는 TF 값은 크지만 IDF값은 작아지므로 CountVectorizer가 가진 단점을 해결 할 수 있음.
from sklearn.feature_extraction.text import TfidfVectorizer
text_data = ['나는 배가 고프다','내일 점심 뭐먹지', ' 내일 공부 해야겠다', '점심 먹고 공부해야지']
tfidf_vectorizer = TfidfVectorizer()
tfidf_vectorizer.fit(text_data)
print(tfidf_vectorizer.vocabulary_)결과
{'나는': 3, '배가': 7, '고프다': 0, '내일': 4, '점심': 8, '뭐먹지': 6, '공부': 1, '해야겠다': 9, '먹고': 5, '공부해야지': 2}
sentence = [text_data[3]] # ['점심 먹고 공부 해야지']
print(tfidf_vectorizer.transform(text_data).toarray())결과
[[0.57735027 0. 0. 0.57735027 0. 0.
0. 0.57735027 0. 0. ][0. 0. 0. 0. 0.52640543 0.
0.66767854 0. 0.52640543 0. ]
[0. 0.61761437 0. 0. 0.48693426 0.
0. 0. 0. 0.61761437][0. 0. 0.61761437 0. 0. 0.61761437
0. 0. 0.48693426 0. ]]
해석
1,4,7,9번째 단어를 제외한 단어는 해당 문장에 사용되지 않아서 모두 0 값이 나왔다.
1,7번-공부와 점심은 0.4정도의 값을 갖고
4,9번- 먹고, 해야지는 0.5 정도의 값을 가진다.
해당 문장안에서 단어의 출현 빈도를 측정하고 해당 단어가 다른 데이터에서는 잘 나오지 않는 값일 수록 높은 값을 가진다.
자연어 토크나이징 도구
토크나이징 : 예측해야 할 입력 정보(문장 또는 발화)를 하나의 특정 기본 단위로 자르는 것. 텍스트에 대해 특정 기준 단위로 문장을 나누는 것을 의미함.
ex. 문장 -> 단어
글 -> 문장
영어 토크나이징 라이브러리
NLTK
영어 텍스트 전처리 작업에 많이 쓰이는 오픈 소스 라이브러리. 50여 개가 넘는 말뭉치 리소스를 활용해 영어 텍스트를 분석할 수 있게 제공.
설치
conda install nltk- 말뭉치(corpus) 내려받기
import nltk
nltk.download()결과
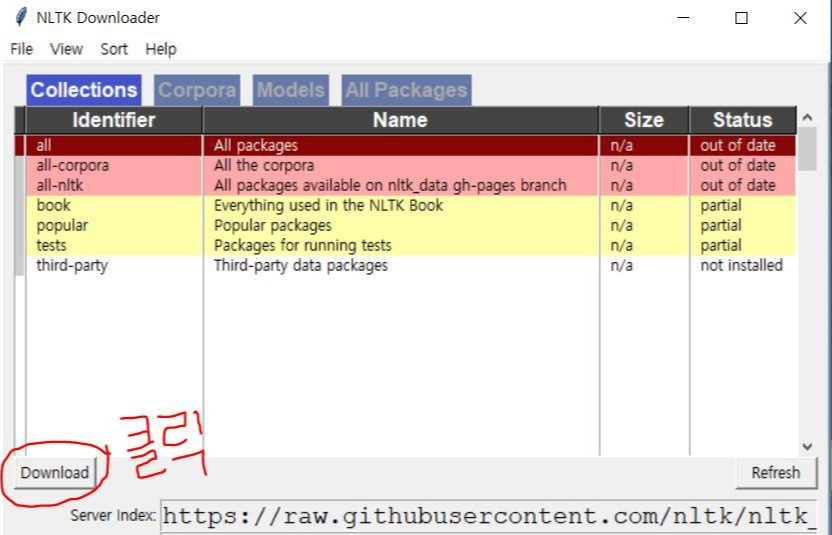
다음과 같은 화면이 뜬다.
원하는 corpus를 다운받으면 된다.
단어 단위 토크나이징
from nltk.tokenize import word_tokenize
sentence = "I like Samsung. I love galaxy Tab 7"
print(word_tokenize(sentence))결과
['I', 'like', 'Samsung', '.', 'I', 'love', 'galaxy', 'Tab', '7']
반환값 : 리스트. 특수 문자의 경우 따로 구분됨.
문장 단위 토크나이징
from nltk.tokenize import sent_tokenize
paragraph = "I like Samsung. I love galaxy Tab 7"
print(sent_tokenize(paragraph))결과
['I like Samsung.', 'I love galaxy Tab 7']
텍스트가 2개의 문장으로 나눠진 리스트로 나오는 것을 알 수 있다.
한국어 토크나이징 라이브러리
KoNLPy
한국어에 대해 형태소 분석으로 형태소 단위 토크나이징을 가능하게 할뿐만 아니라 구문 분석을 가능하게 하는 오픈소스 라이브러리.
형태소 단위 토크나이징
KoNLPy에서는 여러 형태소 분석기를 제공하며, 각 형태소 분석기 별로 분석 결과가 다를 수 있다.
형태소 분석기는 클래스 형태로 구현되어있고, 객체 생성 후 메서드를 호출해 토크나이징 할 수 있다.
형태소 분석 및 품사 태깅
-
형태소 : 의미를 가지는 가장 작은 단위로서 더 쪼개지면 의미를 상실하는 것들.
-
형태소 분석 : 의미를 가지는 단위를 기준으로 문장을 살펴보는 것
-
형태소 분석기 목록
- Hannaum- Kkma
- Komoran
- Mecab (윈도우에서 사용 불가)
- Okt (Twitter)
import konlpyOkt 형태소 분석기로 형태소 분석을 해보겠다.
from konlpy.tag import Okt형태소 분석기 객체 생성한다.
okt = Okt()Okt 객체에서 제공하는 함수는 다음 4가지다.
-
morphs()
: 텍스트를 형태소 단위로 나눈다. 옵션으로는 norm(문장을 정규화), stem( 각 단어에서 어간을 추출 )이 있는데 각각 True 혹은 False값을 받는다. -
nouns()
: 텍스트에서 명사만 추출 -
pharases()
: 텍스트에서 어절을 추출 -
pos()
: 각 품사를 태깅. 주어진 텍스트를 형태소 단위로 나누고, 각 형태소에 해당하는 품사와 함께 리스트화 한다. 옵션으로는 norm, stem, join(나눠진 형태소와 품사를 형태소/품사 형태로 리스트화)가 있다.
- 형태소 단위로 나누기
text = "제 취미는 영화 보기예요. 저는 시간 있을 때 영화관에 가요."
print(okt.morphs(text))
print(okt.morphs(text,stem=True)) # 형태소 단위로 나눈 후 어간을 추출결과
['제', '취미', '는', '영화', '보기', '예요', '.', '저', '는', '시간', '있을', '때', '영화관', '에', '가요', '.']['제', '취미', '는', '영화', '보기', '예요', '.', '저', '는', '시간', '있다', '때', '영화관', '에', '가요', '.']
- 명사 , 어절 추출
print(okt.nouns(text))
print(okt.phrases(text))결과
['제', '취미', '영화', '보기', '저', '시간', '때', '영화관', '가요']['제 취미', '영화', '영화 보기', '시간', '시간 있을 때', '시간 있을 때 영화관', '가요', '취미', '보기', '영화관']
- 품사 태깅
print(okt.pos(text))
print(okt.pos(text,join=True)) # 형태소와 품사를 붙여서 리스트화결과
[('제', 'Noun'), ('취미', 'Noun'), ('는', 'Josa'), ('영화', 'Noun'), ('보기', 'Noun'), ('예요', 'Josa'), ('.', 'Punctuation'), ('저', 'Noun'), ('는', 'Josa'), ('시간', 'Noun'), ('있을', 'Adjective'), ('때', 'Noun'), ('영화관', 'Noun'), ('에', 'Josa'), ('가요', 'Noun'), ('.', 'Punctuation')]['제/Noun', '취미/Noun', '는/Josa', '영화/Noun', '보기/Noun', '예요/Josa', './Punctuation', '저/Noun', '는/Josa', '시간/Noun', '있을/Adjective', '때/Noun', '영화관/Noun', '에/Josa', '가요/Noun', './Punctuation']
