VPC 피어링
(Virtual Private Cloud)
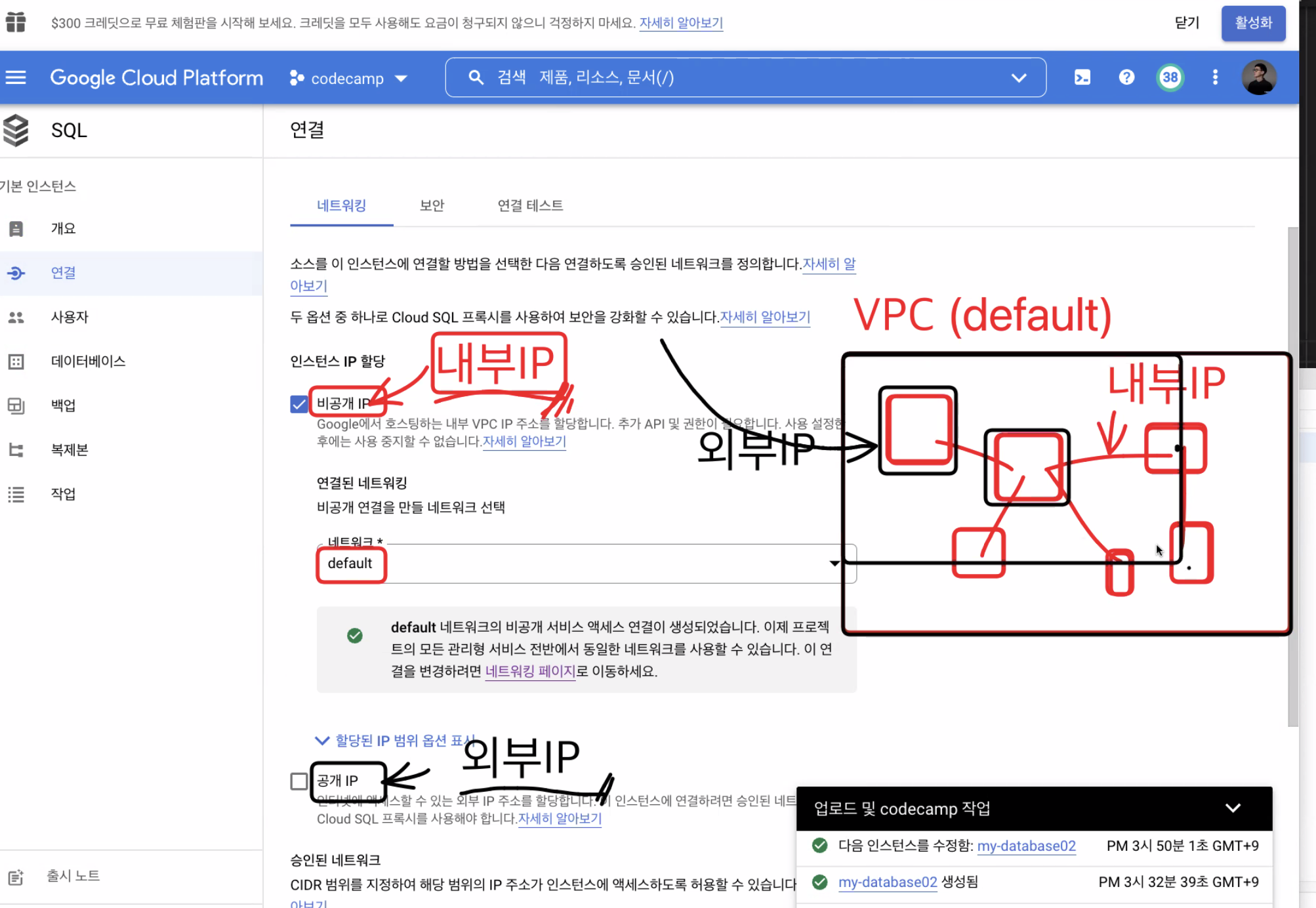
VPC virtual private cloud. Default vac 설정이 되어있는 컴퓨터는 방화벽이 필요없이 서로간에 연결이 가능하다 - 이때 사용되는 IP 가 내부 IP
밖에서 들어오기 위해 필요한 아이피가 외부 IP 이다
mySQL
- 데이터가 도커안에 만들어진 mysql 서버에 저장된다면 불안전하고, 도커가 날라가면서 언제든지 같이 날라가버릴 수 있기 때문에, GCP 에서 데이터 서버를 만들어 준다.
- GCP 에서는 백업 기능이 존재 하기 때문에 더욱 안전하게 데이터를 저장할 수 있다.
- 또한 하나의 데이터 서버가 연결이 끊어졌을 경우를 대비해서 여러 데이터 서버를 만들어 놓을 수 있다.
- GCP를 활용해서 더욱더 안전하게 서버를 유지할 수 있는 것이다.
DNS 도메인 연결
- 웹사이트를 접속할때 인터넷 사용자들은 보통 ip 주소를 입력해서 접속하지 않는다. 이것을 해결하기 위해 도메인을 구입한 후, 우리 서버의 ip 주소와 도메인을 연결 해주는 과정을 거쳐야 한다.
- GCP로 도메인 끌어오기 -> DNS 영역 만들기 -> 가비아에서 만들어놓은 네임서버 안에 호스트명을 변경 한 후 GCP에서 활용가능하게 바꿔야한다 -> 콘솔에서 dig 도메인이름 NS 를 연결되어 있는 호스트명을 확인할 수 있다.
기본적으로 존재하는 DNS
NS - 내가 누군지 증명
SOA - 시작점이 어디인지 알려주는 디폴트 레코드
인스턴스 그룹
- GCP에서 로드밸런서를 만들기 위해서 필요한 인스턴스~
- 인스턴스 그룹을 사용해서 백엔드 서버의 부하 분산을 설정 할 수 있다.
GCP 에서 로드밸런서를 만들기 위해 필요한 과정중 하나라고 보면 편하다. 로드 밸런서에서 백엔드로 부하 분산되는 방식을 결정 해준다고 요약 할 수 있다.
로드밸런서
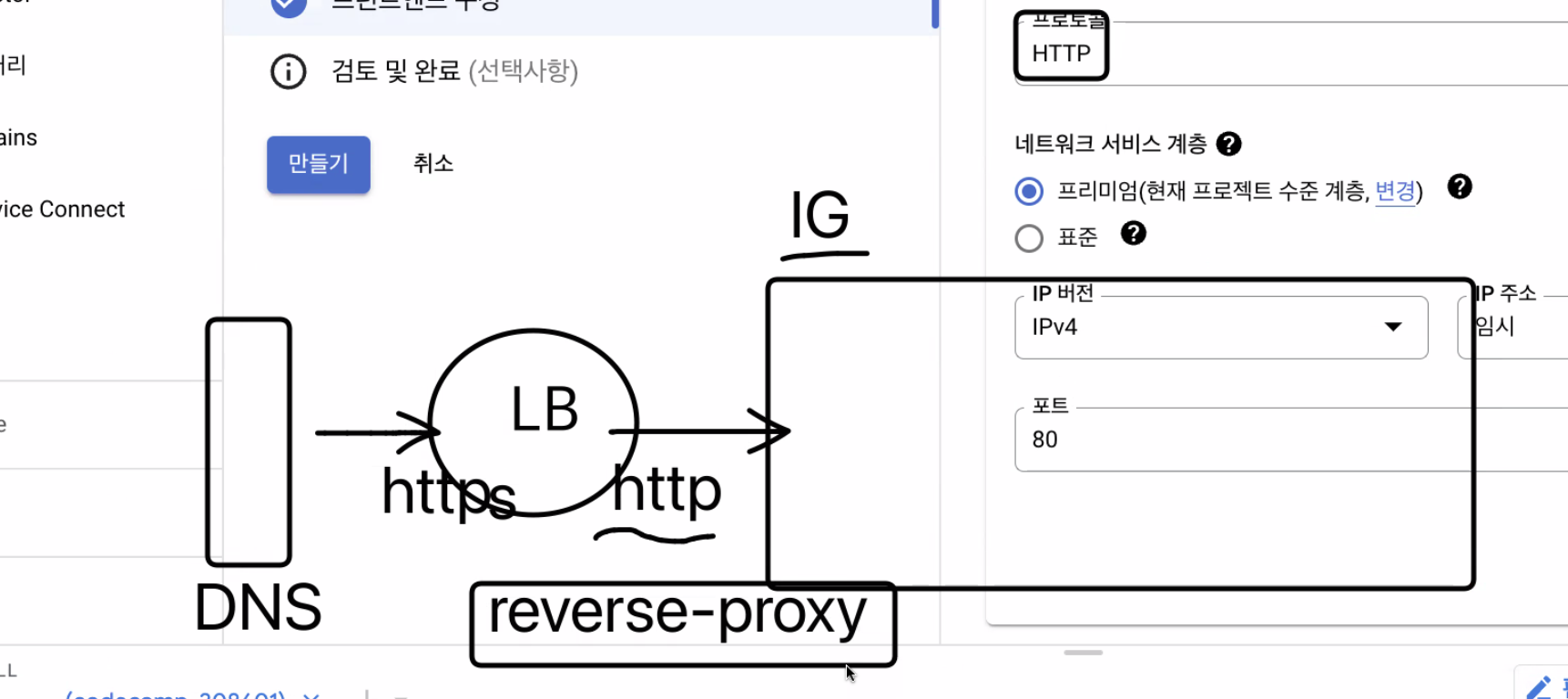
- 로드밸런서의 기본적인 역할은 백엔드 서버의 부하를 막기 위해 존재한다. 로드밸런서가 작동하는 방식도 여러가지가 있다. 간단하게 몇가지 방법을 소개하자면..
round-robin: 접속하는 사람 순서대로 돌아가면서 병렬로 나누어진 서버로 연결을 시켜준다.
smart-load-balancing: 백엔드 서버가 로드벨런서에게 지금 들어온 요청량이 얼마나 되는지 알려준고 적절한 트레픽이 만들어지게 로드밸런서가 분산 시켜준다. (단점: 돈이 많이 듬)
등 여러가지 로드 밸런서의 운영 방법이 존재한다.
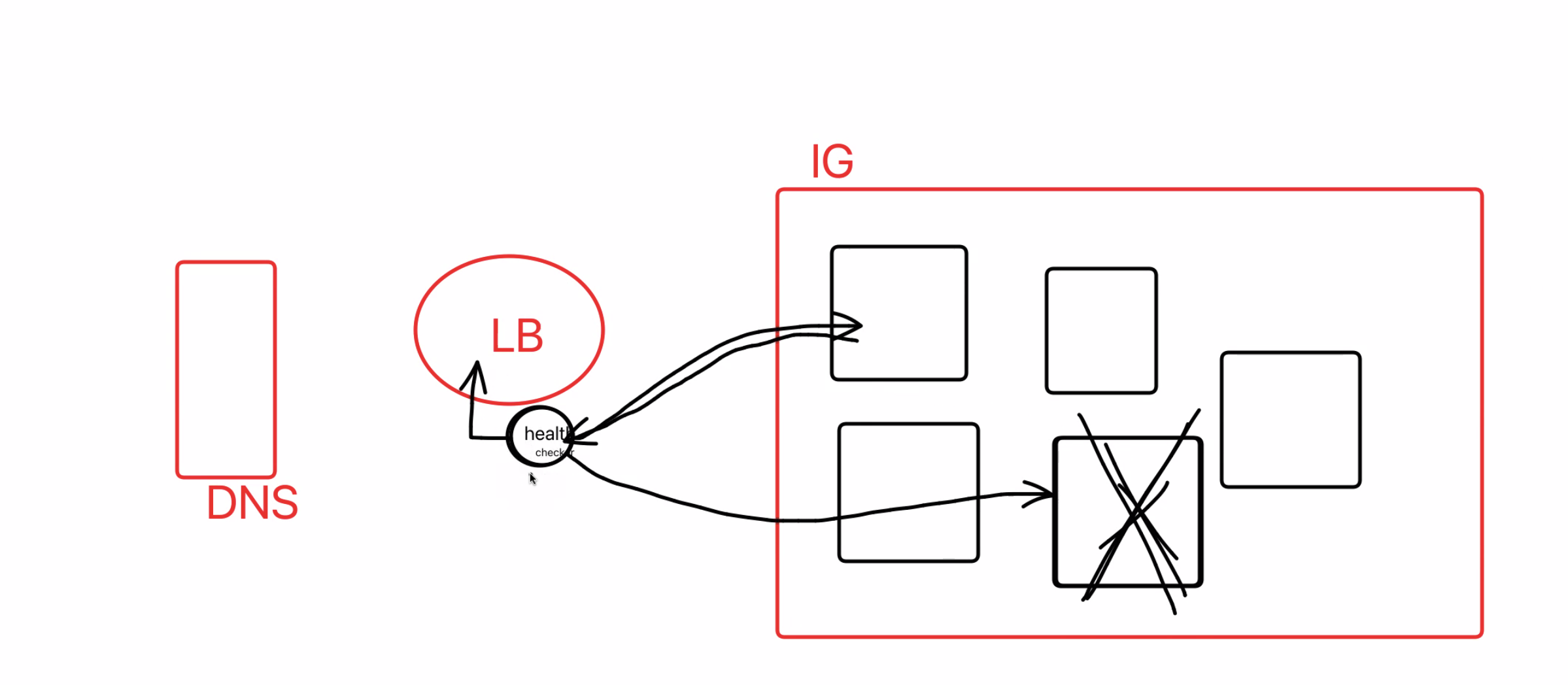
- health checker: GCP 로드밸런서 안에 있는 기능중 하나인데 여러개의 백엔드 서버중 하나의 백엔드 서버가 작동하지 않을때의 상황을 대처하기 위해 만들어짐.
하지만 GCP 에서의 로드 밸런서 역할은 여기서 끝이 아니다. GCP 에서는 로드밸런서를 활용하여 https 즉 인증서 역할을 해준다. 클라이언트로 접속하는 유저들의 보안을 안전하게 책임져 주는 역할을 같이 해준다.
쿠버네티스
https/http
- http(s) s가 인증서 역할을 해준다.
3-way-handshake (HTTPS)

syn => syn + ack => ack
1. 클라이언트는 closed 상태, 서버는 listen 상태입니다.
2. 클라이언에서 서버로 연결을 요청하기 위해 syn 을 보낸다.
3. 서버에서 잘 받았으면, 잘 받았다는 ACK 데이터와 함께 SYN 데이터를 보낸다.
4. 여기서 서버는 SYN_RCV 상태로 변경된다.
5. 서버로 부터 ACK + SYN 을 받는다.
6. 클라이언트는 ESTABLISHED 상태로 바뀐다.
7. ACK 데이터를 서버로 보낸다
8. 서버도 ESTABLISHED 상태로 바뀐다.
DOCKER
- 도커, 도커컴포즈, 도커스웜
도커 - 컨테이너
도커컴포즈 - 컨테이너 여러개 묶음
도커스웜 - 컨테이너 관리자 (죽은애 살려주기)
도커스웜, 메소스, 쿠네티스 등등 도커를 관리해주는 역할을 한다, 일반적으로 가장 많이 사용되는 도커 관리자는 쿠버네티스이고 GCP도 쿠버네티스를 이용한다.
그럼 왜 도커 관리자가 필요한 것일까?
- 도커를 컴퓨터 한대에 설치하는 것이 아니기 때문...?
- 여러대의 컴퓨터에 도커가 분산되어 있을때, 내컴퓨터 한대로 하기는 어려워서 클라우드에서 쿠버네티스로 해준다.
- 도커 여러개가 필요할 경우는?

Kubernetes
- 쿠버네티스는 클라우드에서 기본적으로 다 제공 해준다.
- 클러스터 => 노드 => 파드 => 컨테이너 => 도커 구성되어 있다.
- 기본적으로 배포를 할때, 기존에 만들어져 있는 서비스를 업데이트 하기 위해서 필요한 배포 방법이 존재한다. 기존에 존재하는 노드를 하나 더 만들어서 업데이트를 한다. 그리고 사용자들을 새로 만들어진 노드로 이동 시킨다. 사용자들을 이동 시키는 방법에는 여러가지가 있는데 몇가지 소개하자면 롤링 배포와 카나리 배포등이 존재한다.
롤링 배포: 처음부터 조금씩 조금씩 업데이트 전 노드에서 업데이트 된 노드로 넘긴다.
카나리 배포: 처음에 조금 넘겨보고 이상없으면 다 넘긴다.
위 작업들을 쿠버네티스가 기본적으로 롤링베포를 통해서 실행시켜주고, 롤백까지도 해준다. 또한 자동 확장도 기본적으로 들어가 있다, 쿠버네티스가 자동 확장 하는 단위는 파드이다.
Kubernetes 안에 존재하는 PODS 안에 존재하는 데이터 서버
GCP 안에 따로 존재하는 데이터 서버
PODS 존재하는데, 파드안에 mysql 데이터 서버를 만들어 줄 수 있다. GCP 에서 데이터 베이스 서버를 만들어 줄때 내부 IP로 만들어 줘야 하는것 같다. 데이터 서버는 외부 IP 를 만들어 주면 노출이 될 가능성이 있기 때문에 내부 IP를 만들어주고 백엔드 서버와 연결해 준다. 이렇게 연결된 백엔드 서버가 외부 IP를 통해서 클라이언트와 연결이 가능한 것이다. 하지만 보통의 경우, 데이터 서버를 더욱 안적하게 유지 하기 위해서 GCP 안에 만들어져 있는 SQL을 사용한다. Redis, ElasticSearch 도 마찬가지로 GCP 안에서 따로 만들어줄수 있기 때문에, 이를 이용하는것이 더욱 안전하다고 볼 수 있다.
DNS 와의 연결 (health-checker 오류)

헬스체커가 확인을 하는 과정에서 오류가 났다. http에서 받아오는 경로중 rest-api 를 통해서 요청되는 경로 부분에서 http 방식으로 요청을 보내면 응답이 와야 하는데, 우리가 만들어놓은 백엔드에서는 ('/') 경로가 존재하지 않으니 응답이 없을수 밖에 없음. 그래서 우리 백엔드 서버에 임의로 하나 만들어줘야 했다. 멘토님 말로는 경로 수정을 해도 버그인지 아니면 의도적인지는 모르지만 경로 수정을 하고 난 후에도 계속 ('/') 로 인식한다고 해서 백엔드 서버를 건드려 주는게 더 확실해보인다고 한다.
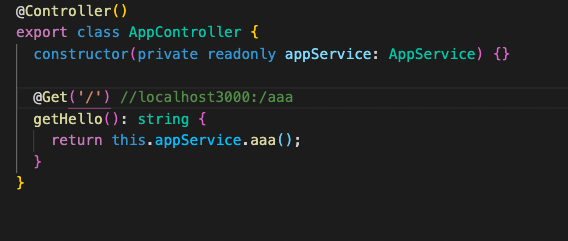
수정후 오류가 없어지고 연결에 성공.
무중단배포
Apache JMeter 를 사용해서 무중단 배포가 이루어지는 확인해보자~!
Apache JMeter 의 몇가지 주요 기능들...
쓰레드 그룹 - https에서 post 요청을 보내서 서버를 부하시켜보자, 쓰레드들의 수 (사용자의 수), Ramp-up (단위: 초), 초단위로 보내는 요청의 수를 만든다.
HTTP 요청 - 요청을 보내는 쿼리문을 작성하는 곳
결과들의 트리 보기 - 요청이 잘 들어갔는지, 무중단 배포가 잘 이루어 졌는지 확인한다.
요약 보고서 - 평균적인 요청 속도가 기록되어 있다, 최소값, 최대값, 표준편차 등등
HTTP 헤더 관리자 - 요청이 json 타입으로 보내질수 있도록 설정해주는 부분.
아래 리스트는 서버 부하 테스트 도구들이다.

CI/CD
이 전체 부분을 자동화 하는 것이 CI/CD 가 되겠다. 잣
git add .
git commit -m '무중단배포'
git push origin master
docker-compose -f docker-compose.prod.yaml build
docker-compose -f docker-compose.prod.yaml push
gcp Kubernetes 접속
set image
이부분을 자동화 하는 것이 CI/CD 부분이다.
git push 를 하면 자동으로 배포까지 완료되게 만들어준다.
이부분을 살짝 수동적으로 바꾸면, 마지막 부분을 한번 더 최종적으로 검증후 배포가 진행되게 만들 수 있다.
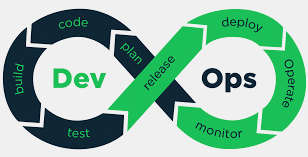
기능 명세서
만들어진 html 을 토대로, 각각의 부분을 세분화 해서 api 를 구현할 것인지에 대한 상세 설명서.
깃에서
리포지토리 안에
- 브랜치는 세부 폴더라고 생각하면 된다.
- git branch 브랜치 확인
- git checkout (브랜치 이동) 이동할 브랜치
- git checkout -b (브랜치 이동) 이동할 브랜치가 존재하지 않는다면 만들어서 -b 이동
- git checkout master
- git checkout -b aaa 브랜치를 따왔다고 얘기한다. 여기서 중요한거는 어떤 브랜치에서 따왔느냐가 중요하다
- git checkout -b qqq
- git checkout master 이미 있는 브랜치로 이동할때는 -b 를 안한다
브랜치가 다르면 각각 폴더가 다르다. 커밋을 한 것들 기준이다.
지금까지는 마스터에서 해주었지만 이제부터는 develop 브랜치를 따로 만들어서 사용한다.
디벨롭에서 피처 브랜치를 딴다- 즉 기능을 담당하는 브랜치를 만든다.
디벨롭 브랜치 아래에 피처 브랜치
피처들
철수: 게시글 등록 - 철수는 브랜치를 따는데 feature-boardwrite
영희: 상품등록 - 영희도 브랜치를 따는데 feature-productwrite
훈이: 결제하기 - 훈이도 브랜치는 딴다 feature-payment
피처를 만들어 놓은것을 디밸롭에 다 합친다.
이제 디밸롭이 준비되었다면, 배포를 준비한다. 여기서 바로 마스터 브랜치로 합치는것이 아니라 릴리스 브랜치를 따로 만들어서 이동시켜 준다.
realease branch - 여기서는 api 를 더 만드는게 아닌 버그를 찾아서 수정하고 업데이트만 해주는 과정을 해주는것이 암묵적인 룰이다.
마지막으로 master branch 로 합쳐서 -> 마스터 브랜치를 배포한다.
배포를 하면서 문제가 생기면 hotfix branch 가 필요로 한다. 버그가 critical 하다면 마스터 브랜치에서 핫픽스 브랜치를 따서, 파일을 그대로 가지고 이동을 하고, hotfixes 에서 고치고 다시 바로
어디서 브랜치를 땃느냐가 중요하다. 어디서 따오냐에 따라 복사가 다르게 된다고 생각하면 된다.
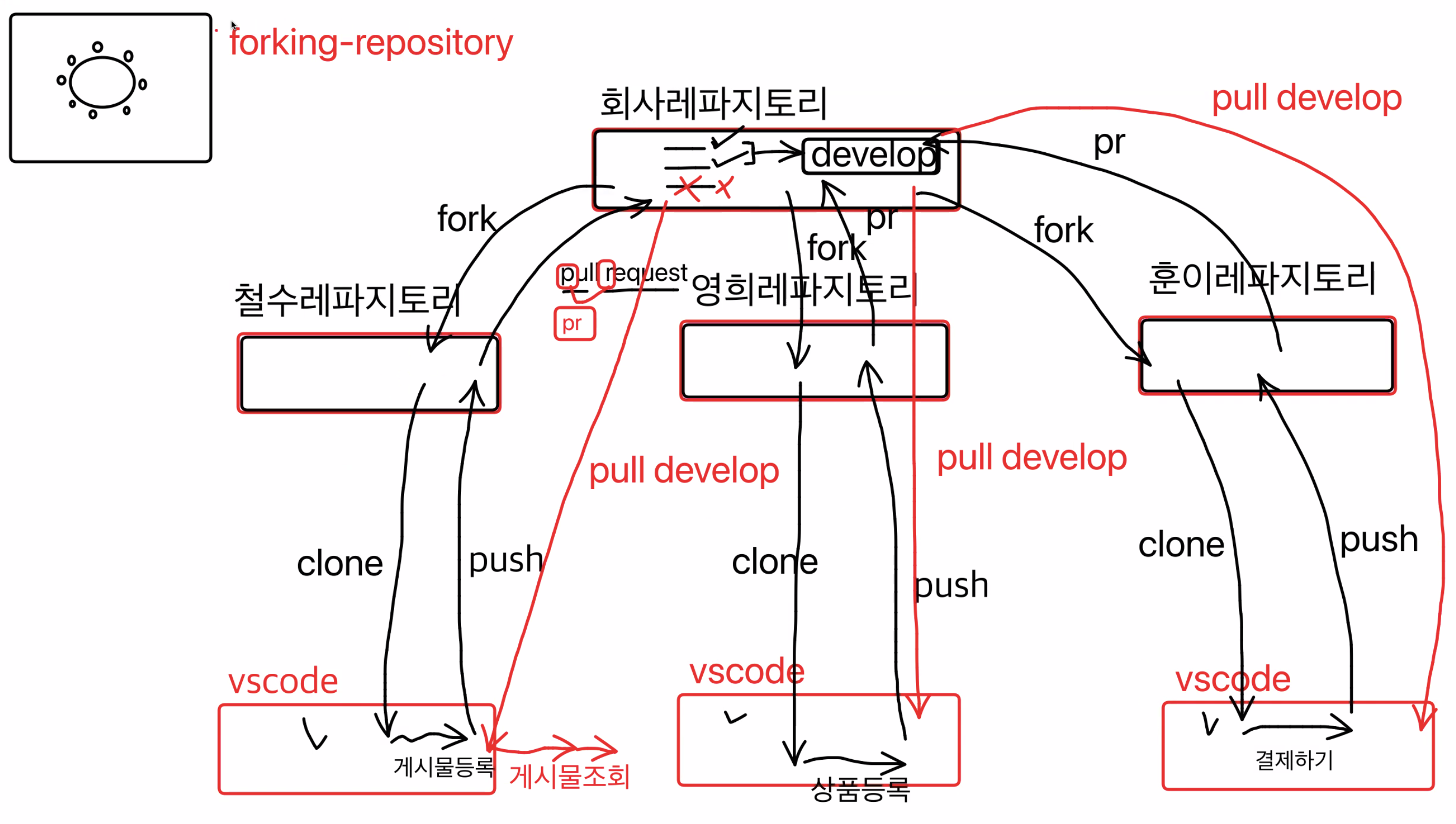
forking-repository
- fork <= git push origin feature-boardwrite 자신의 레파지토리로 보낼때
- fork => git pull upstream develop (upstream 에서 업데이트 된 코드를 덮어 씌울때)
- 서로 독립적인 기능 만들기
- 공통 기능들은? 리더, 시니어 분들이 맡아서 한다. 예를 들어서 로그인 (피해 여부 체크)
- 미리 다음꺼를 개발 하고 싶을때? 가급적이면 독립적인 기능을 만드는게 좋다, 머지가 안된 기능과 독립적인 기능 만들기
git logs
git remote -v