Feature Creation
- 원본 데이터의 조합/변환 등을 기반하여 새로운 특징들을 구축 및 생성하는 방법
원본 데이터로 특징을 새롭게 생성하여 분석 과정 내 성능과 효율성 확보하고자 함
목적 및 필요성
| 품질 확보 | 최적화된 형태 변환 |
|---|---|
| 가공을 거치지 않은 Raw 데이터 활용 기반의 모델링은 품질 확보 어려움 | 효과적인 Feature를 확보하는 것이 데이터 분석 내 가장 중요한 과정임 |
특징 생성 방안
| 범주 인코딩 | 결합 및 분해 | 차원 축소 |
|---|---|---|
| 크게 Nominal(순서없는)과 Ordina(순서있는)형식으로 나뉘는 범주형 변수 | 데이터 셋의 변수들의 조합을 기반으로 새로운 특징을 구축하는 방법 | 원본 데이터로부터 새로운 특징의 집합을 생성하는 것 |
| 숫자가 아닌 범주 변수 값을 숫자로 표현하고 모델링에 적용하기 위한 과정 | 변수 간의 연산 혹은 분해를 통해 새로운 특징을 구축하고 입력 변수로 모델링에 적용 | 고차원 원시 데이터 셋을 저차원으로 차원 축소하도록 새로운 특징을 생성하는 방식 |
범주 인코딩
- 범주형 데이터의 알고리즘 적용을 위한 수치형 변환
One-hot-Encoding: 순서의 의미를 지니지 않은 범주형 변수를 처리하는 대표적 방법, k개의 범주를 지닌 범주형 변수를 k개의 변수로 변환
결합 기반 특징 생성
- 변수 간의 결합을 통해 새로운 의미를 지닌 특징을 생성
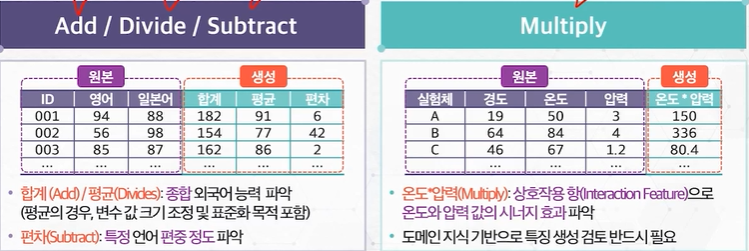
분해 기반 특징 생성
- 변수의 분해를 통해 새로운 의미를 지닌 특징을 생성
Separate: 특정 변수 활용 기반의 새로운 의미를 파악할 수 있는 특징을 생성하는 방법, 도메인 지식 및 일반적 개념 기반으로 생성 가능
차원 축소 목적 특징 생성
- 변수들이 지닌 정보를 최대한 확보하는 저차원 데이터로 생성
PCA(Principal Component Analysis)- 서로 연관된 변수들이 관측되었을 떄, 원본 데이터 분산 기반의 특징을 생성
- 주성분 간의 서로 독립을 이루도록 구성 (상관관계가 없도록 구성)
- 군집 분석 기반의 고차원 데이터를 하나의 특징으로 차원 축소
Featurization via Clustering- 고차원 데이터를 군집 분석을 기반으로 특징의 개수를 하나의 특징(군집 결과)으로 축소
- 이렇게 획득한 군집 결과 특징을 분류/회귀 등 문제 해결을 위한 입력 변수로 활용(Stacking 방법)
- 즉, 원본 데이터 내 여러 개의 특징을 하나의 특징으로 축소하여 모델 연산 비용 감소 추구
one_hot Encoding
data['city'].value_counts()
#city라는 범주형 변수 one_hot Encoding
#Pandas의 get_dummies 함수 활용하여 쉽게 구현 가능
encoding_data = data.copy()
encoding_data = pd.get_dummies(encoding_data, columns = ['city'])
encoding_data.head()
#기존 city 변수 내 5개의 범주 존재
#get_dummies 함수로 원본데이터의 city 변수 대신 각 범주별 변수가 생성( 1개 -> 5개 )
- one-hot Encoding은 각 범주의 요소마다 별도 컬럼으로 생성하여 True/False를 표현
- 기계학습의 많은 알고리즘은 수치형 데이터를 입력값으로 받아야함
- 따라서, 범주형 변수의 one-hot Encoding기법을 활용하여 기계학습 적용의 제약점을 해소 가능
결합 및 분해 기반 특징 생성
#기존 범주형 변수 date 컬럼을 datetime형식으로 변환
creation_data['date'] = pd.to_datetime(creation_data['date'])
#date컬럼을 연/월/일/요일 등 의미를 지닌 변수로 분해
creation_data['year'] = creation_data['date'].dt.year #연도 month, day, hour
.
.
.
#오전 오후 의미를 지닌 변수 생성을 위한 결합 방안
creation_data['ampm'] = 'AM'
creation_data.loc[creation_data['hour'] > 12, 'ampm' = 'PM'PCA
#주성분 분석 수행
from sklearn.decomposition import PCA
#두 개 주성분만 유지시키도록 수행
#30개를 2개 주성분으로 남도록 변환
pca = PCA(n_components=2)
pca.fit(input_scaled)
X_pca = pca.transform(input_scaled)
X_pca
#PCA 수행된 input 데이터 확인
#2개의 주성분 확인
X_pca_df = pd.DataFrame(X_pca, columns = ['pc1','pc2'])
X_pca_df#시각화
import matplotlib.pyplot as plt
import seaborn as sns
#산정도로 2개 주성분 시각화
ax = sns.scatterplot(x='pc1', y='pc2', data = X_pca_df)clustering(군집 분석)
from sklearn.cluster import KMeans
#일부 변수만 선택
subset_df = input_df.iloc[:,0:15]
#데이터 스케일링
std_scaler.fit(subset_df)
subset_input_scaled = std_scaler.transform(subset_df)
#k-mean 클러스터링 활용 군집 label수 설정
k = 5
model = KMeans(n_clusters = k, random_state = 10)
#클러스터링 결과를 타겟 변수와 비교하기 위해 원 데이터에 컬럼으로 생성
target_df['cluster'] = model.fit_predict(subset_input_scaled)
#최종 데이터
target_df
#위와 기존거랑 Target 비교
pd.crosstab(target_df.diagnosis, target_df.cluster)
--> 임의의 15개 변수만을 활용한 하나의 특징이 Target구분에 효과적임을 예측 가능
이처럼 많은 변수를 하나의 특징으로 구성하고, 입력 데이터의 차원을 줄인다면 모델 연산 비용 절감에 효과적
난 성미다.