
📌Q1. 여러분은 파이썬을 통해 설문조사 문항의 응답내역을 분석하게 되었습니다. 문항별 응답내용에는 하나의 응답만 할 수 있는 single choice 문제와 여러 응답을 선택할 수 있는 multiple choice 문제가 있습니다. 2개를 구분하기 위해 single choice 문항 번호에 "_"를 표기하지 않기로 했습니다.
문항별 응답내역이 'question'에 담겨 있을 때, 조건문과 반복문을 사용하여 아래와 같은 결과가 출력되도록 코드를 작성해보세요.
🔽 출력 예시
['Q2', 'Q3', 'Q4', 'Q5', 'Q8', 'Q9']
# 응답 설문 문항
question = ['Q2', 'Q3', 'Q4', 'Q5', 'Q6_1', 'Q6_2', 'Q6_3', 'Q6_4', 'Q6_5', 'Q6_6',
'Q6_7', 'Q6_8', 'Q6_9', 'Q6_10', 'Q6_11', 'Q6_12', 'Q7_1', 'Q7_2',
'Q7_3', 'Q7_4', 'Q7_5', 'Q7_6', 'Q7_7', 'Q8', 'Q9', 'Q10_1', 'Q10_2',
'Q10_3']Q1. 답
question = ['Q2', 'Q3', 'Q4', 'Q5', 'Q6_1', 'Q6_2', 'Q6_3', 'Q6_4', 'Q6_5', 'Q6_6',
'Q6_7', 'Q6_8', 'Q6_9', 'Q6_10', 'Q6_11', 'Q6_12', 'Q7_1', 'Q7_2',
'Q7_3', 'Q7_4', 'Q7_5', 'Q7_6', 'Q7_7', 'Q8', 'Q9', 'Q10_1', 'Q10_2',
'Q10_3']
result = []
for i in range(len(question)):
if (question[i].find("_") == -1):
result.append(question[i])
print(result)📌Q2. 한스 로슬링(Hans Rosling, 1948년 7월 27일 ~ 2017년 2월 7일)은 스웨덴의 의사이자 통계학자로 비영리 벤처 갭마인더 재단의 공동설립자이기도 합니다. 빅데이터를 가장 잘 활용하는 보건 통계학자로 알려져 있습니다. 베스트셀러 책인 "팩트풀니스" 저자이기도 합니다. 갭마인더 사이트에서는 연도별, 국가별 GDP와 기대수명 데이터를 제공하고 있는데, 대표적으로 파이썬 라이브러리 중 'seaborn'에서 제공되는 예제 데이터가 있습니다. 오늘은 이 데이터를 활용해 문제를 풀어보겠습니다.
다음의 데이터는 연도, 국가별 기대수명을 나타내고 있는 데이터 입니다. 2011년 부터의 연도별, 국가별 평균 기대수명을 구해주세요. (2011년도 포함되게 구합니다.)
[필수 조건] groupby 나 pivot_table을 활용합니다. groupby 로 구할 때 unstack()이라는 기능을 사용하여 아래와 같이 컬럼에 인덱스 값을 올려서 표기할 수 있습니다.
만약 행에는 '연도'가, 열에 '국가'가 들어있고 수치 데이터의 결과값이 아래와 같다면, 출력형태는 조금 달라도 괜찮습니다.
데이터는 다음의 방법으로 읽어옵니다.
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/healthexp.csv")
잘 모르겠다면, 다음의 판다스 문서를 참고해서 풀어보세요! => https://pandas.pydata.org/docs/getting_started/intro_tutorials/07_reshape_table_layout.html
🔽 출력 예시
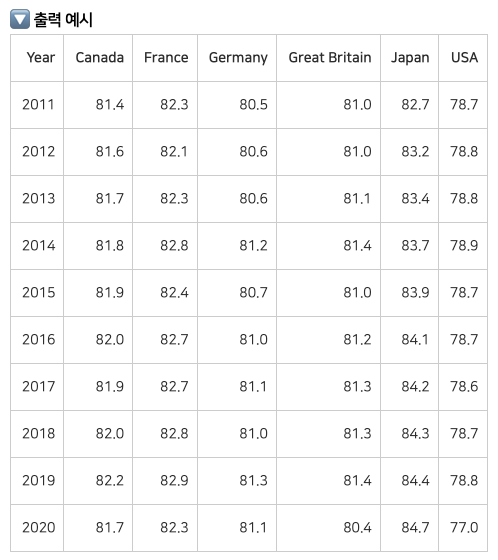
Q2 답
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/healthexp.csv")
# df_2011 = df[df['Year'] >= 2011]
# print(df_2011)
# 첫번째 방법
df_2011.groupby(['Year', 'Country']).mean(['Life_Expectancy']).drop('Spending_USD', axis=1).unstack()
# 2번째 방법
pd.pivot_table(df[df['Year'] >= 2011], index = 'Year', columns = 'Country', values = 'Life_Expectancy', aggfunc = 'mean')
📌Q3. Jupyter notebook 은 문서와 코드를 함께 작성할 수 있다는 점이 장점입니다. Jupyter notebook 에서 지원하는 Markdown 문법을 사용하여, 이번 주에 배운 내용을 정리해 보세요!
이번주 학습 내용은 다음 링크를 참고해주세요!
- 데이터 분석 환경 구성:https://www.boostcourse.org/ds112/joinLectures/28140
- 데이터 분석 준비하기:https://www.boostcourse.org/ds112/joinLectures/28138
Q3 답
# 1.1 무엇을 분석할 것인가? 데이터 분석을 위한 환경 만들기
# 1.2 아나콘다 소개 및 주피터 노트북 사용법
- 아나콘다 공식 사이트(https://www.anaconda.com/download/success)에 들어가서 본인의 OS에 맞는 아나콘다 다운로드.
- 아나콘다는 여러가지 툴을 브라우저로 돌릴 수 있게 도와주는 프로그램.
- 해당 강의에서 사용할 툴은 주피터랩과 주피터노트북이 있다.
- 주피터랩: 한 화면을 분할해서 여러 개를 각각 돌릴 수 있음.
- 주피터노트북: 탭 하나에 한 개를 돌릴 수 있음.
- 마크다운
- 텍스트 기반의 마크업언어로 쉽게 쓰고 읽을 수 있으며 HTML로 변환이 가능하다. 특수기호와 문자를 이용한 매우 간단한 구조의 문법을 사용하여 웹에서도 보다 빠르게 컨텐츠를 작성하고 보다 직관적으로 인식할 수 있다.
- 마크다운 문법은 [GitHub 마크다운 문법 정리](https://gist.github.com/ihoneymon/652be052a0727ad59601) 참조
- 셀 추가/편집/삭제
- a: 위에 셀 한 개 추가
- b: 아래 셀 한 개 추가
- dd: 셀 삭제
- m: 셀을 마크다운 셀로 변환
- h: 다양한 주피터 노트북의 단축키 확인
# 2.1 데이터 분석을 위한 파이썬 속성 코스
- import this: 파이썬의 철학이 담겨있는 Zen of Python이 출력됨
- import: 파이썬의 라이브러리나 패키지를 가져와서 사용할 수 있게 해 줌.
- boolean: True / False
- list: 배열
- for: 반복문
- if: 조건문
- len: 문자열 또는 배열의 길이
- split: 문자열 또는 배열 나누기
- join: 문자열 또는 배열 합치기
# 2.2 판다스 차트시트를 활용한 기초 익히기
- Pandas: Python Data Analysis Library
- [판다스 cheat sheet](https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf)
- 해당 파일에 있는 것들만 알아도 판다스 활용 충분히 가능
- [10 minutes to Pandas](https://pandas.pydata.org/pandas-docs/version/1.0.0/getting_started/10min.html)
- 데이터 타입에서는 DataFrame과 Series가 있다.
DataFrame은 2차원 Series는 1차원으로 생각하면 됨.
- Summarize Data: .value_counts, .sort_values, .drop
- Group Data: .groupby, .pivot_table, .plot, .plot.bar, .plot.density,
# 2.3 파일 경로 설정 방법
- [공공데이터 포털](https://www.data.go.kr/index.do)에서
- pwd: 현재 디렉토리 출력
- ls: 현재 디렉토리 내의 모든 파일리스트 출력
- pd.read_csv('파일이름', encoding="cp949")
- encoding의 경우 기본적으로는 utf-8의 형식.
- 한글의 경우 오류가 날 경우 encoding="cp949"를 추가
📌Q4. 앞으로 우리는 공공데이터포털에서 데이터를 다운로드 받아 과정을 진행할 예정입니다. 본격적인 학습 이전에! 데이터를 다루는 방법이 익숙해지도록 한번 더 연습해보고, 어떤 문제를 풀 수 있을지도 함께 고민해보아요!
공공데이터포털에서 원하는 데이터를 다운로드 받아 경로를 설정하고, 주피터 노트북과 판다스를 통해 불러와 보세요!
어떤 데이터를 사용해야할지 고민된다면 다음 링크의 데이터를 다운로드 받아도 좋습니다.
[참고 예시] 공공데이터포털 - 서울특별시 강남구_생활폐기물배출량
이 때, 인코딩 오류가 발생한다면 encoding="cp949" 옵션을 사용해 주세요!
cp949는 한글 윈도우에서 사용하는 인코딩 방식이랍니다. 인코딩과 관련된 자세한 내용은 다음을 참고해 주세요.
문자 인코딩 - 위키백과, 우리 모두의 백과사전
파일을 열거나 저장할 때 텍스트 인코딩 선택
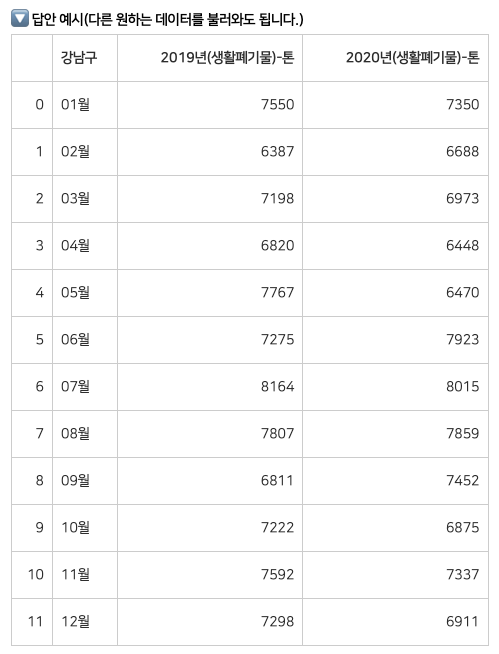
Q4 답
import pandas as pd
pd.read_csv('서울특별시 강남구_생활폐기물배출량_20221019.csv', encoding='cp949')