
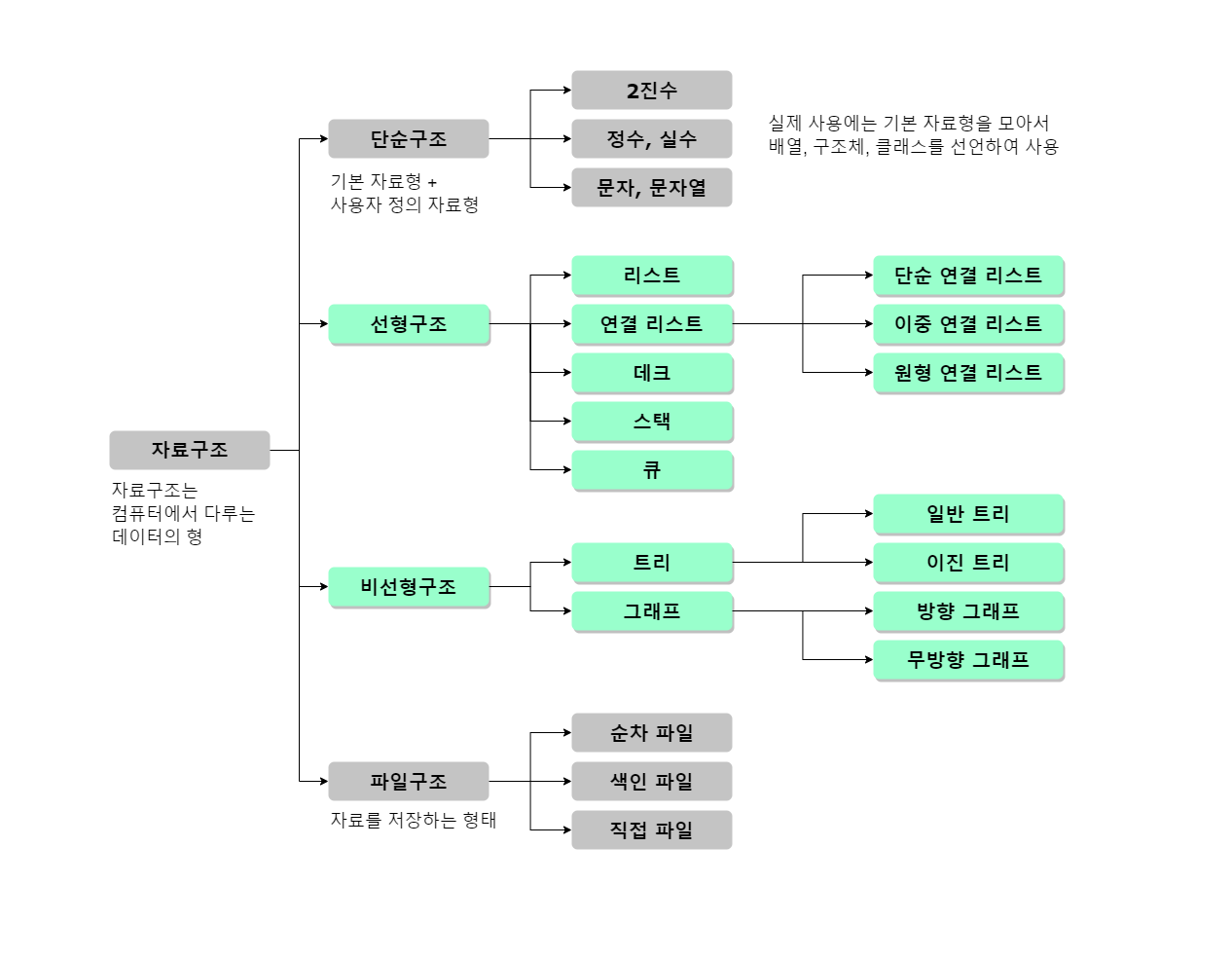
자료구조
자료구조란?
: 여러 데이터의 묶음을 저장하고, 사용하는 방법을 정의한 것
- 필요에 따라 데이터를 효율적으로 다룰 수 있는 방법들을 통틀어 이르는 말
- 특정한 상황에 놓인 문제를 해결하는 데 특화되어있으며, 많은 자료구조를 알아두면 다양한 상황에서 적합한 자료구조를 적용하여 문제를 해결할 수 있다.
프로그램은 데이터를
표현하고, 표현된 데이터를처리하는 것.
데이터의 표현은 데이터를저장을 포함한 개념
이때저장을 책임지는 것이 바로 자료구조이다.
스택(Stack)

- 데이터를 순서대로 쌓는 자료구조
ex. 프링글스
스택의 특징
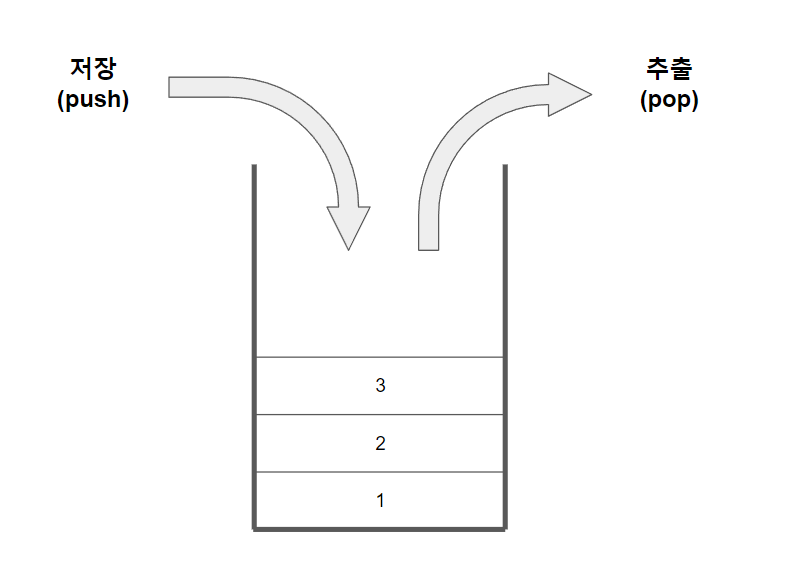
- LIFO(Last In First Out) - 후입선출
- 가장 먼저 들어간 것이 가장 늦게 나오고, 가장 늦게 들어간 것이 가장 먼저 나온다.
- 입출력의 방향이 하나로만 이루어져 있어 제한적 접근이 특징이다.
- 데이터를 하나씩 넣고 뺄 수 있다.
후입선출이라는 특징을 가지고 있기 때문에 배열의 인덱스를 이동시킬 필요가 없음
💡데이터가 배열로 이루어져 있다면 스택의 자료구조를 택하는 것이 유리하다.
- 스택의 예시 : 인터넷 뒤로가기, 앞으로 가기
스택의 메서드
| 메서드 | 반환 타입 | 설명 |
|---|---|---|
| empty() | boolean | Stack이 비어있는지 알려준다. |
| peek() | Object | Stack의 맨 위에 저장되어 있는 객체를 반환.(확인만 가능 꺼내지는 못함) |
| pop() | Object | Stack의 맨 위에 저장되어 있는 객체를 꺼낸다. |
| push(Object item) | Object | Stack에 객체(item)을 저장한다. |
| size() | Integer | Stack에 추가된 데이터의 크기를 반환. |
| show() | String | Stack에 포함되어 있는 모든 데이터를 String타입으로 변환하여 반환 |
| clear() | 현재 Stack에 포함되어 있는 모든 데이터를 삭제 |
큐(Queue)

큐의 특징
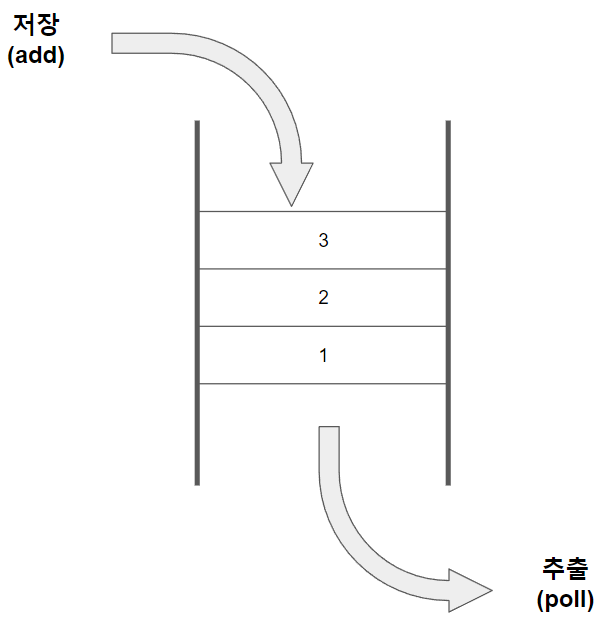
- FIFO(First In First Out) - 선입선출
- 스택과 반대로 입출력의 방향이 서로 다르게 되어 있어 두 곳으로 접근이 가능
- 데이터를 넣는 것을 'enqueue', 데이터를 꺼내는 것을 'dequeue'라고 한다.
- 데이터는 하나씩 넣고 뺄 수 있다.
선입선출이기때문에 배열에서 사용할 경우, 인덱스를 변경하기 위해 처리 속도가 상대적으로 느려짐
💡 인덱스가 존재하지 않는 LinkedList에서는 큐의 자료구조를 택하는 것이 유리하다.
- 큐의 예시 : 프린터
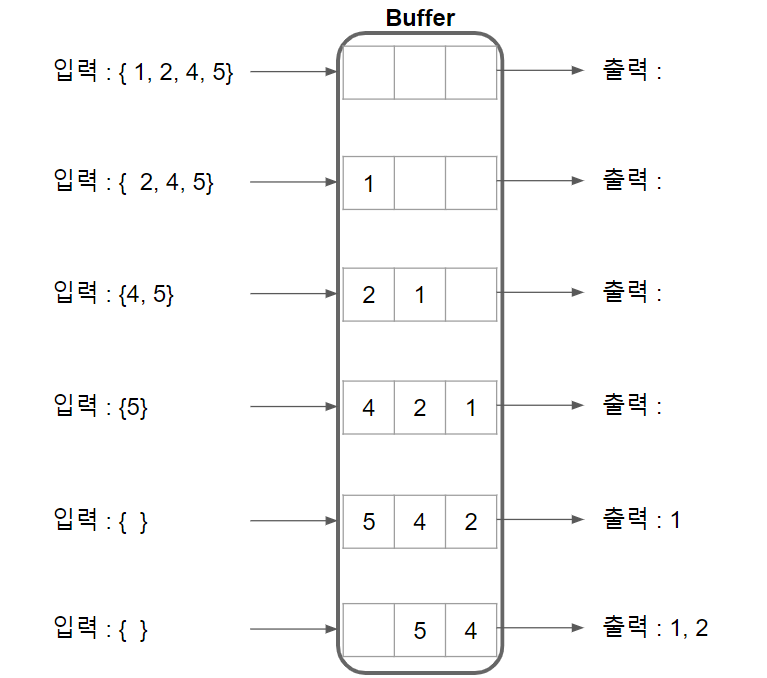
버퍼(Buffer)
- 데이터를 처리하는 프로그램, 장치들 사이에 존재하는 속도, 시간의 차이를 극복하기 위한 임시 기억 장치의 자료구조
- 큐와 함께 사용된다.
- 데이터 처리를 규직적으로 할 수 있도록 도와주는 역할
큐의 메서드
| 메서드 | 반환 타입 | 설명 |
|---|---|---|
| add() | Object | 큐에 데이터를 저장한다. |
| poll() | Object | 가장 먼저 저장된 데이터를 큐에서 삭제하고 삭제한 데이터를 반환 |
| peek() | Object | 큐에 가장 먼저 저장된 데이터를 반환 |
| size() | Integer | 큐에 추가된 데이터의 크기를 반환. |
| show() | String | 큐에 포함되어 있는 모든 데이터를 String타입으로 변환하여 반환 |
| clear() | 현재 Stack에 포함되어 있는 모든 데이터를 삭제 |
원형큐
- 큐는 일반적으로 선형의 형태를 띄고 있다.
선형큐의 단점
- 공간 효율성이 좋지 않다.
- 배열의
front가 계속 뒤로 밀려나면서front앞에 공간이 남게 된다. 따라서 하나의 데이터가 삭제되면 그 뒤에 따라오는 데이터들의 인덱스를 앞으로 당겨와야 하니 데이터 처리 속도가 상대적으로 느려진다.
- 배열의
- 데이터가 꽉 차면 데이터를 추가하기 어렵다.
- 새로운 배열에 복사하면 되는 문제이기는 하나, 속도와 시간이 많이 소요된다는 단점을 가진다.
원형큐
- 선형큐의 단점을 보완하고자 사용하는 자료구조
- 가장 앞에 있는 데이터를 Front 가장 뒤에 있는 데이터를 Rear이라고 한다.
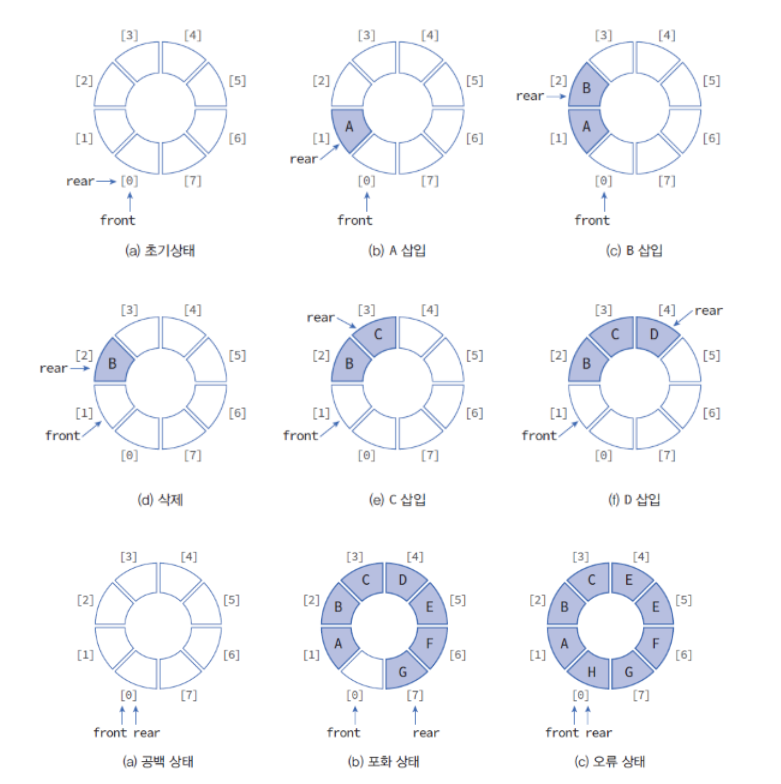
- 큐가 공백인 상태 : front == rear
- 큐가 포화인 상태 : front == (rear+1)%(큐의 사이즈)
큐의 공백과 포화인 상태를 구분하기 위해 하나의 공간을 항상 비워둔다.

🧑💻백엔드 개발자, 조금씩 꾸준하게