
cs231n 강의 정리한 자료들을 보면 ppt 중심으로 설명된 블로그 글은 많이 보았으나, 학생 질문에 대한 질의 응답에 대해 따로 정리된 부분이 없는 것 같아 필요성을 느껴 정리해봤습니다.
질문과 답변 위에는 강의 <시간>을 표시했으며, 클릭시 해당 질문시점의 유튜브 영상을 링크해놨습니다.
학생 질문에 대해 언급되지 않은 부분은 답변에서 질문을 유추해 작성해놓은 것으로 실제 질문과 다를 수 있습니다.
Q.질문1
하이퍼파라미터를 보통 몇개씩 선택해야하나요?
A.답변1
예제는 2개 선택하나, 보통 2개 이상보단 많다.
모델에 따라 다르나 선택한 하이퍼파라미터가 많을수록 기하급수적으로 수가 늘어난다.
사람과 실험마다 다르다.
저스틴은 2~3개를 고르며, 많아도 4개 고르고 그 이상은
통제 불능(out of control)이 된다.
일반적으론 학습률이 제일 중요하다. 제일 먼저 선택해야하며, 다른 요소(regularization,learning rate decay,모델 사이즈)는 학습률보단 덜 중요함
가끔 BCD(block coordinate descent)같은 방법을 쓸 수 있다.
가령 우선, 학습률을 정해놓은 다음에 다양한 모델 사이즈를 시도해보는 것이다.
이 방법을 쓰면 기하급수적으로 늘어나는 서치 스페이스를 조금 줄일 수 있다.
다만 정확히 어떤 순서로 어떻게 찾아야 할지 정하는 것이 가장 큰 문제이다.
Q.질문2
우리가 어떤 하이퍼파라미터 값을 변경할 시에 다른 하이퍼파라미터의 최적 값이 변하는 경우가 빈번할까요?
A.답변2
그런 일이 가끔 발생하긴 합니다.
학습률이 이런 문제에 덜 민감함에도 질문과 같은 경우가 발생하곤 합니다.
학습률이 좋은 범위 내에 속했으면 하지만 보통 optimal 보다는 작은 값이고 학습속도가 길어지곤 합니다.
이런 경우 7강에서 배우게 될 더 좋은(fancier) 최적화 방법을 사용하면 모델이 학습률에 덜 민감하도록 할 수 있습니다.
Q.질문3
학습률을 작게 하고 Epoch을 늘리면 어떤 일이 발생하나요?
A.답변3
그렇게 되면 엄청 오래 걸리겠죠.😄
Q.질문4
(미언급)학습률을 낮추고 오래 학습시키면 되지 않나요?
A.답변4
학습률을 낮추고 오랫동안 학습시키게 되면 이론적으로 항상 동작하는 것이 맞습니다.
하지만 실제로는 학습률이 0.01이냐 0.001이냐는 상당한 중요한 문제입니다.
적절한 학습률을 찾으면 6시간,12시간 또는 하루면 학습을 다 시킬 수 있는데, 조심스럽게 학습률을 10배, 100배 줄여버리면 하루면 끝나는게 100일이 걸릴 수 있습니다.
좋지 않습니다.
보통 컴퓨터과학 분야를 배울때 이런 constants(10배,100배)를 중요하게 다루지 않는 경향이 있는데, 실제 훈련에 대해 생각하면, 그 constants는 많은 문제가 됩니다.
Q.질문5
낮은 학습률을 주면 local optima에 빠질 수 있지 않을까요?
A.답변5
직관적으로는 그럴 수 있겠지만 실제로 그런 일은 많이 발생하지 않습니다.
이와 관련된 내용은 7강에서 배울 것 입니다.
(이후 본 강의 시작)
Q.질문6
바로 SGD를 쓰지 않고 그냥 GD를 쓰면 문제가 해결되지 않을까요?
(질문 전 내용: SGD는 경사에 대한 진짜 정보를 사실 얻고 있지 않으며 경사 추정에 노이즈가 있으면 최소를 향해가는데 시간이 걸릴 수 있다.)
A.답변6
이전 taco shell에서의 문제를 다시 한번 살펴보면 full batch gradient descent에서도 같은 문제가 발생합니다.
Noise의 문제도 Noise는 미니배치뿐만아니라 네트워크의 explicit stochasticity로도 발생합니다.
이는 나중에 더 살펴 볼 것이지만 이는 여전히 문제가 됩니다.
Saddle points(안장점) 또한 full batch GD에서 문제가 됩니다,
전체 데이터를 사용한다고 해도 여전히 나타날 수 있습니다.
기본적으로 full batch gradient descent를 사용한다고 하더라도 이런 문제들이 해결되지는 않습니다.
이러한 위험요소들을 다루기 위해서는 더 좋은 최적화 알고리즘이 필요합니다.
(이후 이번 문제들의 대다수를 해결할 수 있는 아주 간단한 방법으로 SGD에 momentum term을 추가하는 방법을 설명)
Q.질문7
어떻게 SGD momentum이 poorly conditioned coordinate(컨디션이 좋지 않은 좌표)문제를 해결할 수 있을까요?
A.답변7
우선 velocity estimation term에서 velocity 가 어떻게 계산되는지 보면 gradient를 계속 더해갑니다.
이는 하이퍼파러미터인 rho(마찰: 보통0.9 또는 0.99)에 영향을 받습니다.
그리고 현재 gradient가 상대적으로 작은 값이고, 이 상황에서 rho가 적절한 값으로 잘 동작한다고 하면, velocity가 실제 gradient보다 더 커지는 지점까지 조금씩 증가할 것입니다.
이는 poorly conditioned dimension에서 더 빨리 학습될 수 있도록 도와줍니다.
Q.질문8
velocity의 초기값을 구하는 좋은 방법이 있을까요?
A.답변8
velocity의 초기값은 항상 0입니다.
이는 하이퍼파라미터가 아니며 그저 0으로 둡니다.
Q.질문9
(미언급)velocity는 무엇인가요?
A.답변9
직관적으로 보면 velocity는 이전 gradients의 weighted sum입니다.
Q.질문10
(미언급)질문9와 상동
A.답변10

그리고 더 최근의 gradients에 가중치가 더 크게 부여됩니다.(그림참조)
매 스텝마다 이전 velocity에 rho(0.9 또는 0.99)를 곱하고 현재 gradient를 더해줍니다.
이를 moving average라고 볼 수 있습니다.
그리고 시간이 지날수록 이전 gradiente들은 exponentially(기하급수적으로)하게 감소합니다.
Q.질문11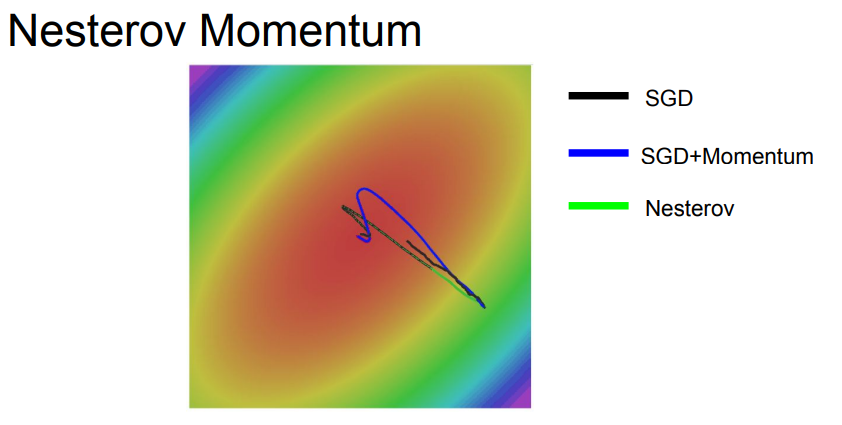
예시만 보면 momentum이 엄청 좋아보이는데 만일 minima가 엄청 좁고 깊은 곳이라면 어떻게 되나요?
momentum의 velocity가 오히려 minima를 건너 뛰는 현상도 발생할 수 있지 않을까요?
A.답변11
그 부분은 관련된 최근 연구들이 주목하는 주제이기도 합니다.
하지만 사실은 그렇게 좁고 깊은(sharp) minima는 좋은 minima가 아닙니다.
우리는 그런 곳에 도달하는 것도 원하지 않습니다.
좁고 깊은(sharp) minima는 훨씬 더 심한 overfits을 불러오게 됩니다.
가령 Training set을 두배 늘었다고 생각해보면, 최적화 시키는 산의 지형(landscape)자체가 바뀌게 될 것입니다.
Training set이 더 많이 모이면 그런 민감한 minima는 점점 사라집니다.
여기서 얻을 수 있는 직관은 우리가 원하는 minima는 아주 평평한 minima라는 것입니다.
"아주 평평한 minima"는 Training data의 변화에 좀더 강인할 지도 모르기 때문입니다.
결국 평평한 minima가 일반화를 잘 할 수도 있으며, Training data에도 더 좋은 결과를 얻을 수 있을 것입니다.
아주 최근 연구되고 있는 분야로 아주 좋은 질문입니다.(2017년 기준)
그러므로 momentum이 좁고 깊은 minima를 무시하는 것은 버그가 아닌 momentum의 특징입니다.
확실하진 않지만 이는 momentum의 좋은 점입니다.
Q.질문12
convex인데 왜 AdaGrad에게 불리할까요?
(질문 전 내용:실제로 AdaGrad는 잘 쓰이지 않으며 이런 식의 비교는 사실 AdaGrad에게 불공정합니다. 아마 학습률을 늘리면 RMSProp과 비슷한 동작을 할 것입니다.)
A.답변12
이 예시의 문제는 convex case이지만 학습률이 서로 상이하기 때문입니다.
때문에 여러 알고리즘 간에 "같은 학습률"을 가지고 AdaGrad를 visualization(시각화)하는 것은 공정하지 못합니다.
visualization을 하고자 한다면 알고리즘 별로 학습률을 조정하는 것이 좋습니다.
Q.질문13
first moment도 second moment처럼 초기에 엄청 작은 값일 것입니다.
학습률에 '엄청 작은 값'을 곱하고(first moment) '엄청 작은 값의 제곱근(second moment)'을 나누면 어떻게 될까요?
A.답변13
어쩌면 서로 상쇄시킬 수 있고 상쇄된다면 문제는 해결되는 것이죠.
경우에 따라서 서로 상쇄될 수도 있습니다.
하지만 간혹 엄청 큰 step이 발생하는 경우도 생길 수 있습니다.
하지만 한번 발행하면 정말 나쁜 상황일 것입니다.
제대로 초기화를 해주지 않아서 아주 큰 step이 발생했다면, 초기화가 엉망이 되고 아주 엉뚱한 곳으로 이동해 결국 수렴할 수 없게 될 수도 있습니다.
Q.질문14
수식의 10^-7이 무엇인가요?
A.답변14
저 값은 AdaGrad, PMSProp, Adam에서 등장합니다.
현재 어떤 값을 나눗셈을 하고 있습니다.
그 값이 항상 0이 아니라는 보장은 없죠.
따라서 분모에 작은 양수 값을 더해줘서 0이 되는 것을 사전에 방지할 수 있습니다.
이 또한 하이퍼파라미터이긴 하지만 큰 영향력은 없습니다.
보통 10^-7이나 10^-8정도를 사용하면 잘 동작합니다.
Q.질문15
Adam이 해결하지 못한 것은 무엇인가요?
A.답변15
Neural networks는 여전히 크고 학습은 오래 걸립니다.
Adam을 쓰더라도 여전히 문제점들은 있습니다.
손실함수가 타원형일 경우 Adam을 이용하면 각 차원마다 적절하게 속도를 조절하면서 '독립적으로' step을 조절할 것입니다.
하지만 이 타원이 축 방향으로 정렬되어 있지 않고 기울기가 기울어져 있다면, 이 경우 Adam은 차원에 해당하는 축만 조절할 수 있습니다.
이는 차원을 회전시킨 다음 수평/수직 축으로만 늘렸다 줄였다 하는 것입니다.
회전을 시킬 수 없습니다.
이런 회전된 타원(poor conditioning)문제는 Adam을 비롯한 여러 알고리즘들도 다룰 수 없는 문제입니다.
Q.질문16
모델간의 Loss 차이가 크면 한쪽이 overfiting 일 수 있으니 별로 안좋고, 또 차이가 작아도 좋지 않을까요?
좋은 앙상블 결과를 위해서라면 모델 간의 최적의 갭을 찾는 것이 중요하지 않을까요?
A.답변16
사실 갭이 중요한 것이 아닙니다.
중요한 것은 validation set의 성능을 최대화 시키는 것입니다.
하지만 우선 갭을 신경쓰지 않고 모델을 조금더 Overfitting 시킬 수 있다면 아마 더 좋은 성능을 낼 수 있을 것입니다.
validation set 성능과 이 갭 사이에는 묘한 관계가 있지만 오로지 validation set 성능만 신경쓰면 됩니다.
Q.질문17
앙상블 모델마다 하이퍼파라미터를 동일하게 줘야할까요?
A.답변17
그렇지 않을 수도 있습니다.
다양한 "모델사이즈", "학습률", "다양한 regularization기법" 등을 앙상블 할 수 있습니다.
실제로 그렇게 사용하기도 합니다.
Q.질문18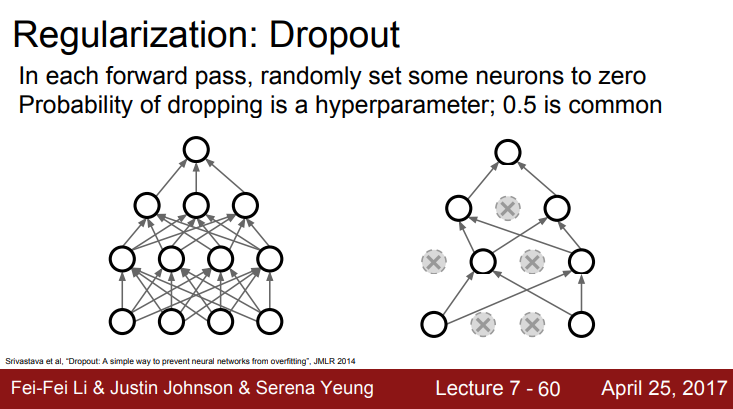
지금 무엇을 0으로 놓나요?
A.답변18
activations을 0으로 설정하는 것입니다.
각 레이어에서 next activ = prev activ * weight입니다.
현재 activations의 일부를 0으로 만들면 다음 레이어의 일부는 0과 곱해질 것입니다.
(그림 상에서 순방향 전달마다 몇몇 뉴런들을 0으로 설정한다고 적혀있습니다.)
Q.질문19
어떤 종류의 레이어에서 Dropout을 사용할까요?
A.답변19
Dropout은 fc layer에서 흔히 사용합니다.
하지만 conv layers에서도 종종 볼 수 있습니다.
conv net의 경우에서는 전체 feature map에서 Dropout을 시행합니다.
conv layer의 경우 여러 channerls이 있기 때문에 일부 channel 자체를 Dropout 시킬 수도 있습니다.
Q.질문19
Dropout을 사용하게 되면, Train time에서 gradient에는 어떤 일이 일어나나요?
A.답변19
Dropout이 0으로 만들지 않은 노드에서만 Backprop이 발생하게 됩니다.
때문에 Dropout을 사용하게 되면 전체 학습시간이 늘어납니다.
각 스텝마다 업데이트 되는 파라미터의 수가 줄어들기 때문이죠.
Dropout을 사용하면 전체 학습시간은 늘어나지만, 모델이 수렴한 후에는 더 좋은 일반화 능력을 얻을 수 있습니다.
Q.질문20
보통 하나 이상의 regularization 방법을 사용하나요?
A.답변20
일반적으로는 Batch normalization을 많이 사용합니다.
대부분의 네트워크에서 보통 잘 동작하기 때문이죠.
아주 깊은 네트워크에서도 수렴을 잘 하도록 도와줍니다.
대게는 Batch normalization만으로 충분합니다.
overfitting이 발생한다 싶으면 Dropout과 같은 다양한 방법을 추가해 볼 수 있습니다.
보통은 이를 가지고 blind cross-validation를 수행하지는 않습니다.
대신 네트워크에 overfit의 조짐이 보일 때, 하나씩 추가시켜 보는 것입니다.

7강에서는 20가지의 질문이 나왔습니다.
어떤 부분에 대한 질문이였는지 참고하기 위해 Summary를 넣습니다.
이 강의를 보시는 분들께 많은 도움이 되었으면 합니다.
