유튜브 강의
슬라이드
9강 슬라이드 1~35p 분량 정리분(~28:26)입니다.

- 9강 CNN 아키텍쳐
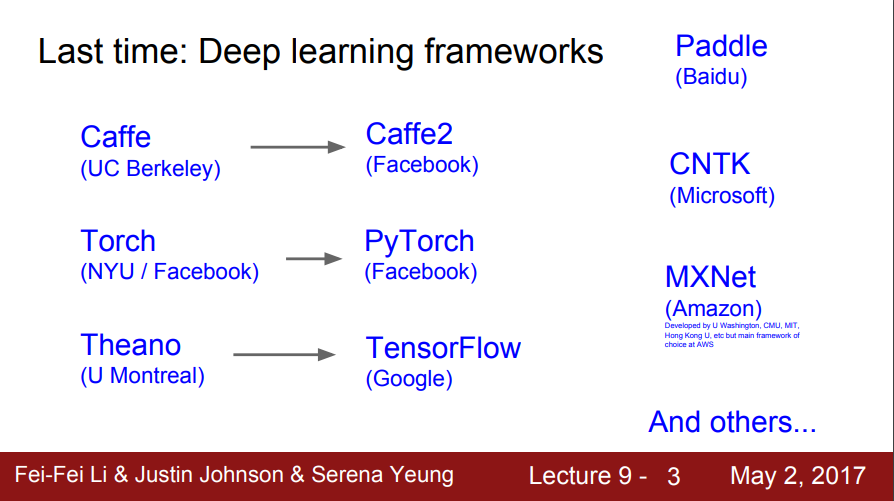
- 지난 시간(8강 딥러닝 소프트웨어): 딥러닝 프레임 워크를 배움

- 딥러닝 프레임워크들을 이용하게 되면,
(1) 큰 계산 그래프(Computational Graphs)를 쉽게 구성
(2) 계산그래프에서 기울기를 쉽게 계산
(3) GPU에서 모두 효율적으로 실행(cuDNN, cuBLAS 등 랩핑)

- forward와 backward로 정의하여 모듈화된 레이어를 통해 동작함

- 모델 아키텍처를 레이어 시퀀스로 정의
CNN Architectures

- CNN 아키텍처
- 사례연구(AlexNet, VGG, GoogLeNet, ResNet)
- 엄청 잘 사용하지 않지만 역사적 관점에서 흥미로운 모델, 아주 최신모델도 다룰 것(Also)
LeNet-5
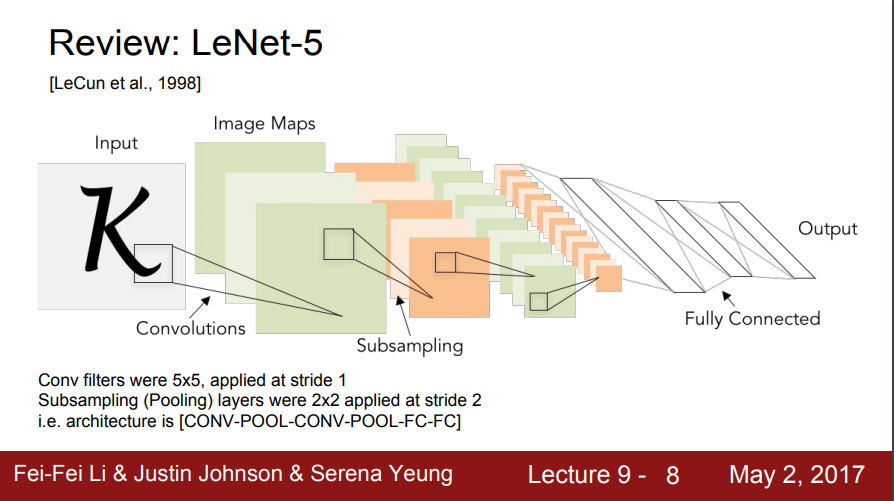
- LeNet은 산업에 성공적으로 적용된 최초의 ConvNet
- 이미지를 입력으로 받아서 stride = 1, 5x5 Conv필터를 사용했고, 몇 개의 Conv 레이어와 몇 개의 풀링 (pooling) 레이어를 거치고 마지막에 FC 레이어가 붙음
- 간단한 모델이지만 숫자인식에서 엄청난 성공을 거둠
AlexNet
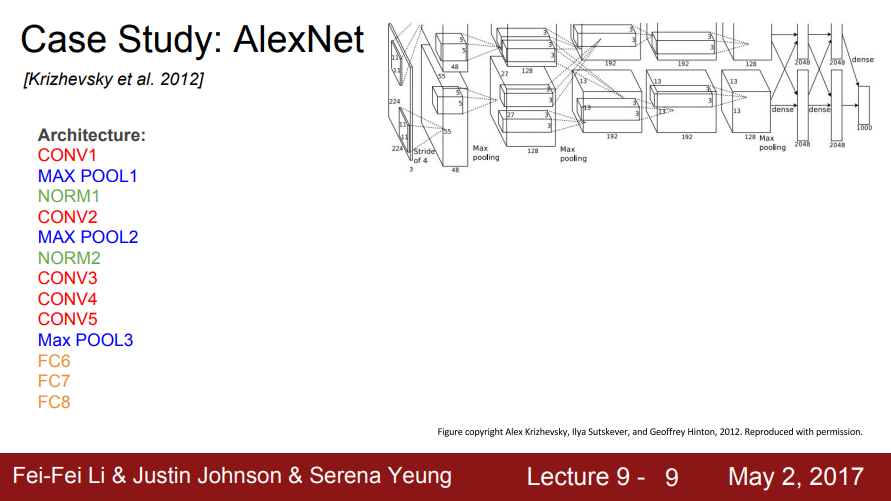
- 2012년에 AlexNet이 나옴
- 최초의 Large scale CNN으로 이미지 분류를 잘 수행함
- 기존 non-딥러닝 모델을 능가하는 성능을 보임
- 기본적으로 conv - pool - normalization구조가 2번 반복되며, conv 레이어가 조금 더 붙고(conv3,4,5) pooling 레이어(Max POOL3) 마지막으로 FC가 붙음(FC 6,7,8)
- 기존 LeNet과 유사하고 전체 레이어가 더 많아짐
- 5개의 Conv 레이어와 2개의 FC 레이어로 구성

- Input: 227x227x3 이미지
- 첫 번째 레이어(CONV1): 11x11 필터가 stride 4로 96개가 존재
- Q: 출력 볼륨 크기는 무엇입니까?
- 힌트: (227-11)/4+1 = 55

- Output 볼륨 [55x55x96]
- Q: 이 레이어의 총 파라미터 수는 몇 개입니까?
- 힌트: 11x11 필터가 총 96개

- 파라미터: (11*11*3)*96 = 35K
- 필터 11*11 입력 Depth 3 필터 96

- 두번째 레이어(pooling): stride 2인 3x3 필터
- Q: 출력 볼륨 크기는 무엇입니까?
- 힌트: (55-3)/2+1 = 27

- Output 볼륨 [27x27x96]
- Q: 이 레이어의 파라미터 수는 얼마입니까?

- 0! 풀링계층은 파라미터가 없음

- Input: 227x227x3 images
이후 CONV1: 55x55x96
이후 POOL1: 27x27x96
...
- Q: 왜 pooling 레이어에는 파라미터가 없을까? 학생 질문 7:47
- A: 학습시킬 파라미터가 없음
파라미터는 학습시키는 가중치로 conv 레이어에는 학습할 수 있는 가중치가 있으나, pooling은 가중치가 없고 특정 지역의 큰 값만 뽑아내는 역할을 함
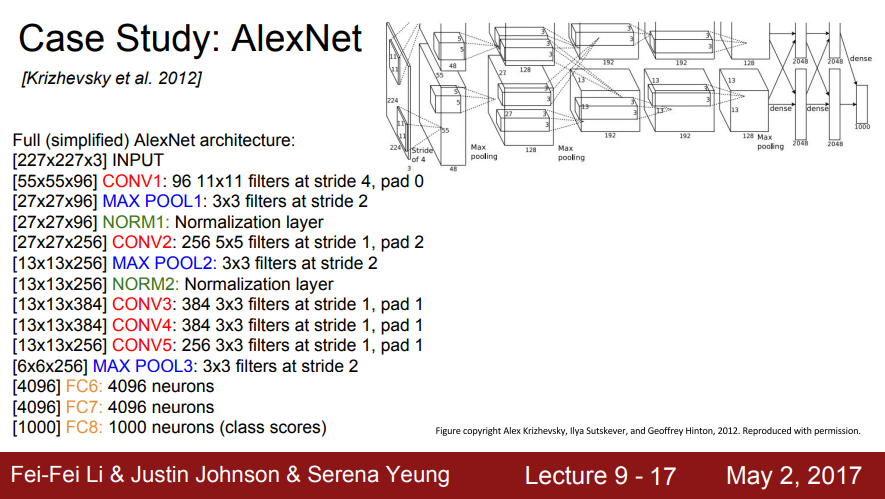
- 전체 (단순화한) AlexNet 아키텍쳐
- conv 레이어의 파라미터 크기는 앞서 계산한 값과 유사
- 끝의 몇개의 FC 레이어는 4096개의 노드를 가진 레이어
- FC8은 Softmax를 통과하여 1000 ImageNet 클래스로 이동

- 세부정보/회고:
- ReLU 최초 사용
- Norm 레이어 사용(더 이상 일반적이지 않음_큰 효과 없음)
- data augumentation을 많이 적용(flipping, jittering, color norm 등 적용)
- dropout 0.5
- 배치사이즈 128
- SGD 모멘텀 0.9
- 초기 학습률 1e-2, val 정확도가 안정되면 학습률을 1e-10까지 줄임
- L2 가중치 감소(weight decay) 5e-4
- 7 CNN (모델)앙상블: 18.2% -> 15.4%

- 모델이 2개로 나눠져서 서로 교차함
- 역사적 노트: AlexNet 학습 당시 3GB의 메모리만 있는 GTX 580 GPU에서 교육
전체 레이어를 GPU에 넣을 수 없기에 네트워크를 GPU에 분산시켜 넣음
모델의 뉴런과 feature map을 절반인 2개의 GPU에 네트워크가 분산됨
- 첫번째 레이어 출력 55x55x96이고, 다이어그램을 보면 각 GPU에서의 Depth가 48임
- feature map을 절반씩 가지고 있음
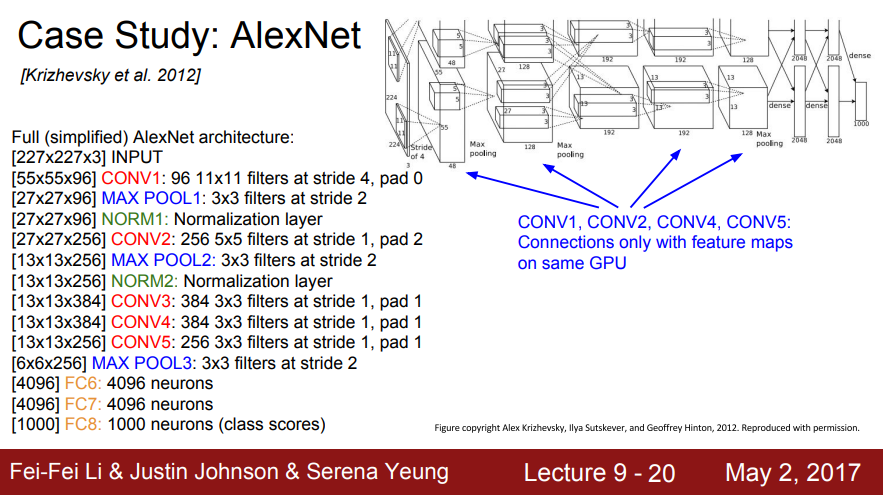
- CONV1, CONV2, CONV4, CONV5: 동일한 GPU의 기능 맵과만 연결
- 같은 GPU 내에 있는 feature map만 사용
- 전체 96 feature map이 아닌 48개의 feature map만 사용
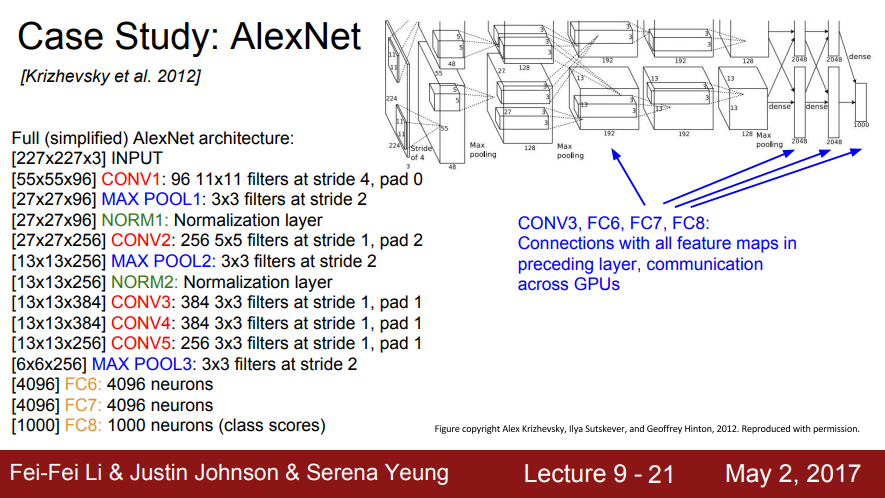
- CONV3, FC6, FC7, FC8: 이전 레이어의 모든 feature map과의 연결, GPU 간의 통신
- 이 레이어들에서는 GPU간의 통신을 하기 때문에 전체 Depth를 전부 가져올 수 있음
- Q: 왜 예시가 Full (simplified) AlexNet architecture일까? 학생 질문 12:05
- A: (simplified)라고 하는 이유는 PPT에 AlexNet의 세부적인 것을 전부 표시하지 않았기 때문
예로 normalization 레이어는 자세히 기입하지 않음
- AlexNet 논문에 아키텍처와 관련된 이슈로 그림에서는 첫 레이어가 224x224지만 실제 입력은 227x227임
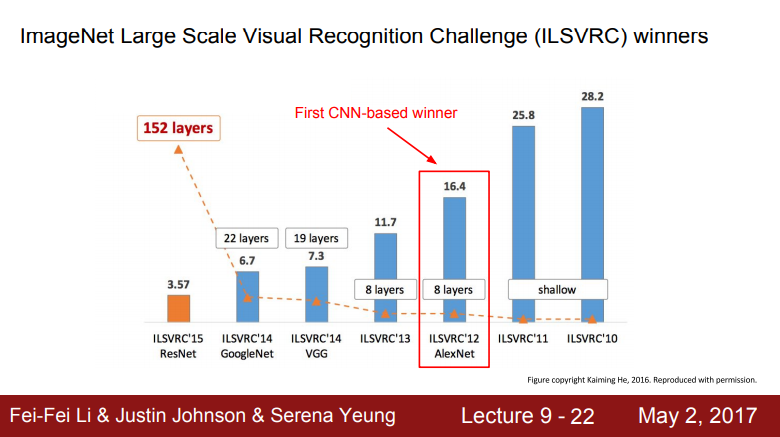
- ImageNet 대규모 시각적 인식 챌린지(ILSVRC) 우승자
- Image Classification Benchmark의 2012년도에 우승한 모델
- 최초의 CNN 기반 우승 모델이고 수년전까지 대부분 CNN 아키텍처의 베이스모델로 사용됨
- 다양한 task의 전이학습(transfer learning)에 많이 사용됨
ZFNet
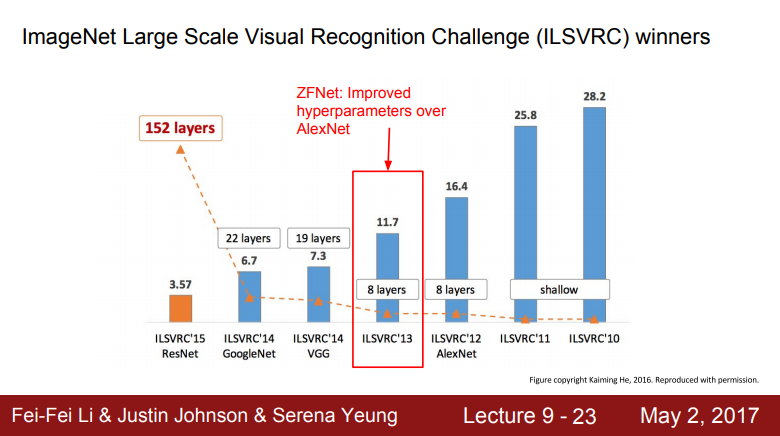
- 2013년 ImageNet 승자는 ZFNet이란 모델이며 ZF는 저자명을 딴 명칭
- ZFNet는 AlexNet의 하이퍼파라미터를 개선한 모델
- Q: AlexNet이 기존 모델들 보다 뛰어날 수 있는 이유? 학생 질문 13:50
- A: 기존 방법과 다른 접근방식인 딥러닝과 Conv Net 때문
AlexNet이 위 두가지를 최초로 적용함
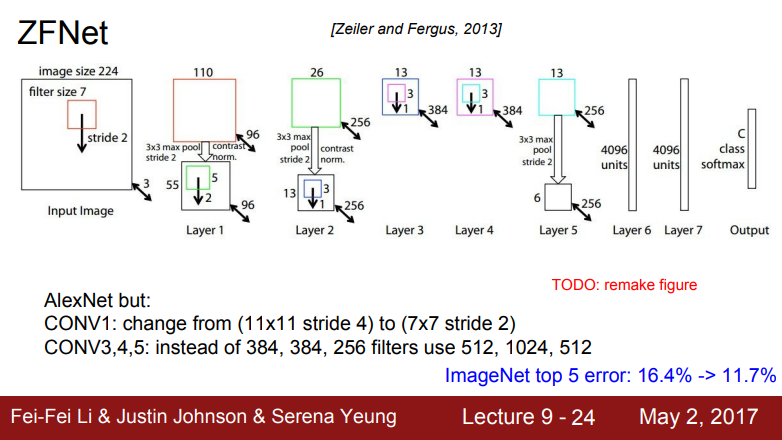
- AlexNet과 같은 레이어 수와 기본 구조도 같으나 stride, 필터 수 등 하이퍼파라미터 조절하여 Error rate를 개선
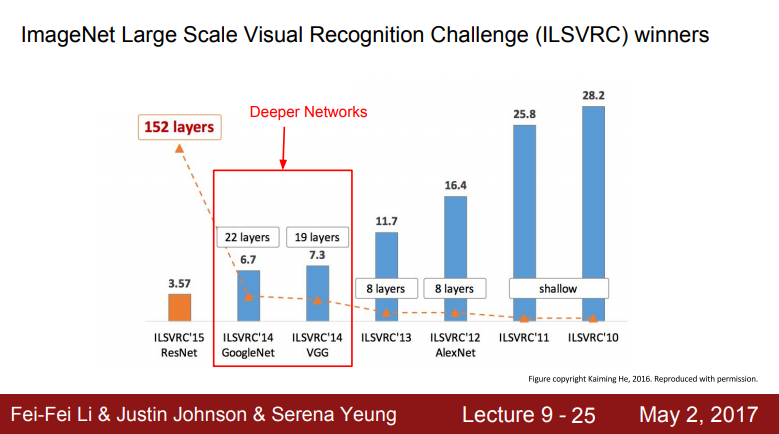
- 2014년에는 아키텍처도 많이 변하고 성능도 항상함
- 가장 큰 차이점은 네트워크가 훨씬 더 깊어짐
- 2012, 2013년에는 8개의 레이어였으나 2014년에는 19,22 레이어로 늘어남
- 2017년도의 우승자는 Google의 GoogLenet이고 Oxford의 VGGNet이 2등을 차지함
- VGGNet은 Localization challenge 등 다른 트랙에서 1위를 차지함
VGGNet

- 더 깊고 작은 필터를 사용함
- AlexNet에서 8개 였던 레이어를 16~19개 레이어로 사용
- 항상 3x3 필터를 사용하고 작은 필터를 유지하며 주기적으로 pooling을 수행하며 전체 네트워크를 구성함
- ImageNet에서 7.3%의 Top 5 Error를 기록
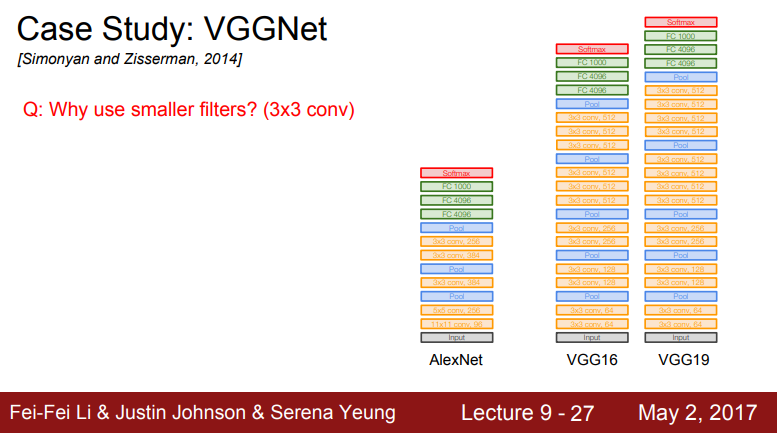

- Q: 더 작은 필터를 사용하는 이유는 무엇입니까? (3x3 conv)
- A: 필터 크기가 작으면 파라미터의 수가 더 적고 큰 필터에 비해 레이어를 더 많이 쌓을 수 있음(Depth를 키울 수 있음)
3x3 필터를 여러개 쌓은 것은 7x7 필터를 사용한 것과 동일한 실질적인 수용장 (effective receptive field)를 가지는 것

- Q: 세 개의 3x3 conv(stride 1) 레이어의 effective receptive field는 무엇입니까?
- A: 입력의 전체 영역, 픽셀들이 서로 겹치는 것
여기서는 7x7로 하나의 7x7 필터를 사용하는 것과 동일

- 더 깊게 쌓으면 비선형(Non-linearity)을 추가할 수 잇고 파라미터수도 더 적어짐
- 전체 파라미터의 갯수를 3x3 필터에는 9개 파라미터가 있음
- 3x3xC(C는 Depth)에 출력 Feature map의 갯수를 곱해야하는데 입력 Depth와 같음
- 각 레이어 당 3x3xCxC가 되고 레이어가 세개이므로 3을 더 곱함
- 7x7 필터의 경우 7x7xCxC

- 전체 네트워크를 살펴보면 비슷한 conv-pooling 패턴이 반복적으로 진행
- VGG16인 모든 레이어 수를 세면 16개
- VGG19의 경우 유사한 아키텍쳐지만 conv 레이어가 조금 추가됨

- 네트워크 전체 메모리 사용량
- Forward pass 시 필요한 전체 메모리를 계산한 것
- 각 노드가 4bytes 메모리를 차지하므로 전체 약 100MB의 메모리가 필요하나 이 값은 Forward pass만 계산한 값
- Backward pass를 고려한다면 더 많은 메모리가 필요
- VGG16은 메모리 사용량이 많은 편
- 전체 메모리가 5GB면 이미지 하나당 100mb이므로 50장 밖에 처리할 수 없음
- 그리고 전체 피라미터 갯수는 138M개(AlexNet의 경우 60m개)
- Q: 네트워크가 더 깊다는 게 필터의 갯수가 많은 건가요? 레이어의 갯수가 더 많은 건가요? 학생 질문 20:57
- A: 이 경우에는 레이어의 갯수를 의미함
Depth는 두가지로 사용할 수 있음
채널의 Depth(width,height,depth)와
일반적인 "네트워크의 깊이"라고 할때는 네트워크의 전체 레이어 갯수를 의미
"학습가능한 가중치를 가진 레이어의 갯수"(conv,FC 레이어 )
- Q: 하나의 conv 레이어 내에 여러개의 필터가 존재하는 이유는? 학생 질문 22:01
- A: 지난 convNet 강의에서 다룬 적 있으므로 참고해 볼 것
예시로 3x3 conv 필터가 있을 때, 3x3xDepth를 보고 하나의 Feature map을 만들어 내고 입력 전체를 돌면서 하나의 Feature map을 완성
각 필터가 존재하는 이유는 서로 다른 패턴을 인식하기 위해서 임
각 필터는 각각의 Feature map을 만들게 되는 것
- Q: 네트워크가 깊어질수록 레이어의 필터 갯수(채널 Depth)를 늘려야 하는 지? 학생 질문 23:07
- A: 디자인하기 나름이고 반드시 그럴 필요 없음
실제로 Depth를 많이 늘림
Depth를 많이 늘리는 이유 중 하나는 계산량을 일정하게 유지시키기 위해서 임(constant level of compute)
보통 네트워크가 깊어질수록 각 레이어의 입력을 Down sampling하게 됨
Spatial area가 작아질수록 필터의 Depth를 조금씩 늘려주게 됨
Width Height가 작아지기 때문에 Depth를 늘려도 부담없음
- Q: 네트워크에 SoftMax Loss 대신 SVM Loss를 사용해도 되는지? 학생 질문 23:59
- A: 지난 강의에서 다룬 내용이며 둘 다 사용할 수 있음
보통 SoftMax Loss를 일반적으로 사용
- Q: 앞서 계산한 메모리 중에 굳이 가지지 않고 버려도 되는 부분이 있는지? 학생 질문 24:37
- A: YES 일부는 굳이 가지고 있지 않아도 됨
하지만 Backword pass 시 chain rule을 계산할 때 대부분은 이용됨
따라서 대부분은 반드시 가지고 있어야 함

- 파라미터가 존재하는 곳들의 메모리 사용분포를 보면 초기 레이어에 많은 메모리를 사용
- Sparial dimention이 큰 곳들이 메모리를 더 많이 사용
- 마지막 레이어는 많은 파라미터를 사용함
- FC 레이어가 dense connection 때문에 엄청난 양의 파라미터를 사용함
- 최근 일부 네트워크들은 너무 많은 파라미터를 줄이기 위해 아예 FC 레이어를 없애기도 함

- 여기에 각 레이어를 부르는 명칭이 있을 수 있음
- conv3-64는 64개의 필터를 가진 3x3 conv 필터임
- 다이어그램의 오른쪽을 보면 각 필터를 묶어 놓았음
- 오렌지색 블록은 첫번째(part 1의 conv는 conv1+1, conv1-2와 같이 표현

- VGGNet은 ImageNet 2014 calssification challenge에서 2등, localization은 1등함
- 학습 과정은 AlexNet과 유사
- Local response normalization은 사용하지 않음(큰 도움되지 않음)
- VGG16와 VGG19은 유사하며 VGG19가 조금 더 깊음(VGG19가 약간 더 우수하고 메모리도 더 사용함)
- 보통 VGG16을 많이 사용함
- 모델 성능을 위해 앙상블 기법을 사용함
- VGG의 마지막 FC레이어인 FC7은 ImageNet 1000 class 바로 직전에 위치한 레이어임
- 이 FC7은 4096 사이즈 레이어 인데 아주 좋은 feature represetation을 가진 것으로 알려져 있음
- 다른 데이터에서도 특징 추출이 잘 되며 다른 Task에서도 일반화 능력이 뛰어남
- Q: localization이 무엇인지? 학생 질문 27:45
- A: localization은 task임
기본적으로 "이미지에 고양이가 있는지?" 분류하는 것 뿐만 아니라 정확히 고양이가 어디에 있는지 네모 박스를 그리는 것
Detection과는 조금 다름(Detection은 이미지 내에 다수의 객체가 존재할 수 있음)
localization은 이미지에 객체가 하나만 있다고 가정하고 이미지를 분류하고 추가적으로 네모박스도 쳐야함
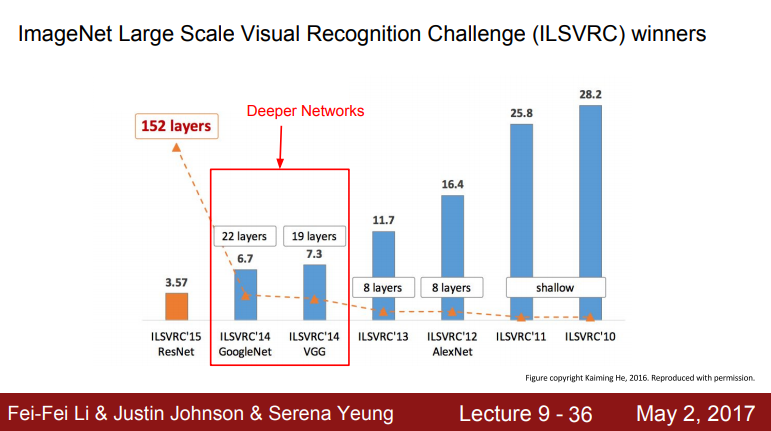
- VGG를 보았음
- 이제 구글넷 (GoogLeNet)에 대해서 얘기할 것임
- 2014년 Classification Challenge에서 우승한 모델임

굴러가는 토마토