Numpy와 Array
Numpy란?
Numpy는 Numerical Python의 줄임말로 과학계산, 특히 행렬연산에 특화된 라이브러리이다.
Numpy는 다음과 같은 특징을 가진다.
- 빠르고 효율적인 다차원 배열
- 배열 원소를 다루거나 배열 간의 수학 계산
- 배열 기반의 데이터를 다룰 수 있다. (Pytorch, Tensorflow의 Tensor)
- 선형대수 계산
Numpy용 Array : ndarray
numpy는 ndarray라는 자료를 사용하여 행렬 연산을 진행한다.
list를 사용하여 ndarray 만들기
np.array 함수를 사용하여 list를 numpy용 list인 ndarray를 만들 수 있다. 이는 n차원 배열을 의미한다.
import numpy as np데이터의 형태에 따라 1D Array, 2D Array, 3D Array 등으로 부른다.
# 1차원 Array
x = np.array([1, 2, 3, 4])
x_list = [1, 2, 3, 4]type을 확인 해 보면 numpy.ndarray 로 출력되는 것을 확인할 수 있다.
# 2차원 Array
x = np.array([[1,2,3,4],
[5,6,7,8]
])# 3차원 Array
x = np.array([
[[1,2], [3,4]],
[[5,6], [7,8]],
])numpy용 range : np.arange
range() 와 같이 시작점, 끝점, 스텝을 설정하여 np.ndarray를 만들 수 있다.
np.arange(10)
np.arange(1, 10)
np.arange(1, 10, 2)numpy용 실수 range : np.linspace
x = np.linspace(0, 100, num = 1001)
x = np.arange(100)
y = x ** 2빈 배열을 만드는 4가지 방법
np.zeros(shape): 0으로 채워진 ndarraynp.ones(shape): 0으로 채워진 ndarraynp.full(shape, value):value로 채워진 ndarraynp.empty(shape): 임의의 ndarray (메모리 아무곳에 할당하기에 쓰레기값 존재 가능)
shape은 n차원의 직사각형, 직육면체의 형태를 의미합니다. tuple 형식으로 제공해주어야 합니다.
np.zeros((5)) # zeros 1d
np.zeros((3,4)) # zeros 2d
np.ones(10) # ones 1d
np.ones((7,3)) # ones 2d
np.full((2, 9), 1.5) # full 2d
np.full((3, 4, 5), 10) # full 3d
np.empty((4, 4)) # empty 2dfull()을 사용 할 경우 value에 문자열을 입력 할 경우에는 dtype이 출력된다.
Numpy의 자료형
dtype
Numpy는 기존의 자료형인 int와 float를 기준으로 사용하지만 조금은 다른 자료형을 사용한다.
x = np.array([[1, 2, 3],
[4., 5., 6.]])
print(x[0][0]) # 1.0
print(type(x[0][0])) # <class 'numpy.float64'>
x_list = [[1,2,3],
[4., 5., 6.]]
print(x_list[0][0]) # 1
print(type(x_list[0][0])) # <class 'int'>실행 결과를 보면 float뒤에 숫자 64가 붙어 있는 것을 확인할 수 있다.
Data types - NumPy v1.20.dev0 Manual
위의 페이지에서 자세히 확인이 가능하다.
결론은 int 뒤의 숫자는 표현 가능 한 숫자의 범위의 차이를 나타내며 float 뒤의 숫자는 표현 가능 한 숫자의 범위의 차이와 정밀도의 차이를 나타낸다.
하나의 ndarray 안의 datatype은 모두 동일하며, 이는 .dtype 으로 확인 할 수 있다.
astype
datatype을 변형 시키기 위해 사용하는 메소드
x = x.astype(np.int8)위와 같이 작성 할 경우 float64의 데이터 타입을 int64 로 변경 할 수 있다.
이 경우 한 칸당 64bit를 사용했던 것을 한 칸당 8bit만 사용하게 되기 때문에 메모리를 8배 아낄 수 있다.
정의 시 dtype 정하기
별도의 정의 없이 사용 할 경우 default 값은 int와 float 모두 64를 사용한다. 하지만 따로 변형시켜주지 않고 처음에 정의 할 때 부터 dypte을 정의 내릴 수 있다.
x = np.array([1, 3, 3], dtype = np.float32)이 경우 x의 dtype은 float32가 된다.
Numpy에서 Random 사용하기
Numpy의 random 모듈 사용
다양한 random 선택
np.random.rand: 0~1 사이의 랜덤값np.random.randint: 원하는 범위의 정수에서 랜덤하게 선택np.random.uniform,np.random.normal: 다양한 분포에서 생성 가능 (균등분포, 정규분포 등)
Random Seed
컴퓨터의 Random은 사실 random이 아닌 가짜로 생성 된 규칙적인 수열이다.
seed 값이 있는데, 이 값을 고정하면 언제나 같은 값의 랜덤 값을 얻을 수 있다.
예를 들어 seed = 1로 고정 한 경우 몇번을 돌려봐도 같은 랜덤값을 얻게 될 것이다.
np.random.seed(23) # 주석처리를 하며 실험해보기!
np.random.randn(3, 4)Array의 형태
Array의 차원? 크기? 형태?
Numpy의 ndarray의 형태는 다음과 같이 표기할 수 있다.
shape: (2, 3, 4) 등 전체적인 형태ndim: 3 (차원)size: 2 3 4 = 24 (실제로 컴퓨터가 몇차원으로 mapping되는가)
각 dimension을 axis0, axis1, axis2라 하여 하나의 축이 된다.
일반적으로 각 차원마다 사용되는 분야가 다른데 그 예는 다음과 같다.
- 1d : audio / time-series
- 2d : gray-scale image
- 3d : color image
- 4d : video
import numpy as np
x = np.array([[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0, 1, 2, 3],
[4, 5, 6, 7]],
[[0 ,1 ,2, 3],
[4, 5, 6, 7]]])
# ndim
print(x.ndim) # 3
# shape
print(x.shape) # (3, 2, 4)
# size
print(x.size) # 24Reshape
필요에 따라서는 데이터를 다양한 형태로 봐야하는 경우가 필수적으로 발생한다. 그렇기에 .reshape를 활용하여 데이터의 형태를 바꿀 수 있다.
다만 주의해야 할 점은 reshape의 결과도 같은 size여야 한다는 것이다. size = 24인 데이터를 size = 20으로 reshape 요청 시 다음과 같은 에러가 발생한다.
ValueError: cannot reshape array of size 24 into shape (4,5)
혹시, 행과 열 중 하나의 값은 알지만 나머지 하나의 값이 몇인 데이터인지 모를 경우에는 -1로 해 주면 고정된 값 외의 데이터를 알아서 처리해서 보여준다.
x.reshape(4, -1)
##############
# array([[0, 1, 2, 3, 4, 5],
# [6, 7, 0, 1, 2, 3],
# [4, 5, 6, 7, 0, 1],
# [2, 3, 4, 5, 6, 7]])- reshape 수행 시 주의해야 할 점은
x = np.zeros((3, 4, 5))
x.reshape(-1)
x.reshape(1, -1)
x.reshape(1, 1, -1)위 세 가지의 경우가 모두 다르다는 것에 주의하자. 출력의 결과는 다음과 같다.
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
[[[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]]
[[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]]]언뜻 보면 그저 모든 데이터가 0으로 채워진 듯 하나, []의 수가 다르고 차원이 다르다.
이 뜻은 데이터 내용이 모두 0이지만 차원이 다르기 때문에 실제로 이 데이터가 사용 되는 분야가 다르다는 뜻이다. 그렇기 때문에 용도에 맞게 전처리 하기 위해서는 위와 같은 내용을 숙지하고 있으면 좋다.
- reshape를 수행하면 연산의 결과가 모두 가로로 정렬이 된다. 하지만 이 정렬 순서를 세로로 정렬되도록 바꾸고 싶다면
order = F옵션을 추가해주자.
y = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
y.reshape(3, 4, order='F')그러면 아래와 같이 세로로 정렬 된 데이터를 확인할 수 있다.
[[ 0 3 6 9]
[ 1 4 7 10]
[ 2 5 8 11]]transpose
transpose는 행과 열의 숫자를 바꿔 데이터의 형식을 바꾸는 단순한 reshape 방법이라고 생각하면 된다.
사용 방법은 두가지다.
x.Tnp.transpose(x)
x.T.T와 같이 연속해서 사용할 수 있다.
Ravel과 Flatten
numpy의 배열을 1차원 배열로 바꾸는 방법은 총 세가지가 있다.
.reshape(-1).ravel().flatten()
세 가지 방법 모두 1차원 배열로 바꾸는 역할을 수행하지만 reshape, ravel과 flatten의 차이는 명백히 존재한다.
- reshape, ravel : 이 두 가지 방법을 사용하여 shape를 변경 할 경우 변경 된 shape도 변경 전 기존의 shape와 같은 메모리 주소를 참조하기 때문에 기존의 shape도 변경된다.
- flatten : 새로운 객체를 만들기 때문에 기존의 객체가 변하지 않고, 새로운 객체의 shape만 변경된다.
Advanced_indexing
Slicing
numpy는 기존의 list와 유사하지만 더 편리한 slicing을 제공한다.
import numpy as np
a = np.arange(1, 26).reshape(5, 5)
print(a)
#######
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]
[21 22 23 24 25]]1st[행 시작 : 행 끝, 열 시작 : 열 끝] 으로 접근 할 수 있다.
- 값에 접근
a[2][2]- 행에 접근
a[0]- 행들에 접근
a[1:4]- 열에 접근
a[ : , 0] - 열들에 접근
a[ : , 1:4] - 임의의 부분에 접근
a[1:4, 3:5]Slicing + 값 수정
a = np.zeros((5,5))
print(a)
###
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
------------------------------
a[0][0] = 1
print(a)
###
[[1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]- 행 수정
a[1] = 2- 열 수정
a[:, 1] = 3- 행들 수정
a[1:3] = 4- 열들 수정
a[:, 2:5] = 5- 원하는 부분 수정
a[1:-1, 1:-1] = 6- numpy의 slicing도 기존의 python slicing처럼 step 기능을 제공한다.
a = np.zeros((5,5))
a[::2, ::2] = 1 # 0부터 시작하여 모든 행, 열을 2 간격으로
print(a)
###
[[1. 0. 1. 0. 1.]
[0. 0. 0. 0. 0.]
[1. 0. 1. 0. 1.]
[0. 0. 0. 0. 0.]
[1. 0. 1. 0. 1.]]Boolean Indexing
비교 연산을 위해 참 거짓 배열을 만들어보자.
one_zero = np.array([0, 1, 0, 0, 1])
true_false = (one_zero == 1)
print(true_false)
###
[False True False False True]현재 인덱스 1, 4의 내용만 True인 것을 알 수 있다.
a = np.arange(1, 26).reshape(5, 5)
print(a)
###
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]
[21 22 23 24 25]]a[true_false]
###
array([[ 6, 7, 8, 9, 10],
[21, 22, 23, 24, 25]])이제 index를 true_false 배열로 전달 할 수 있다.
열만 선택하고 싶다면 다음과 같이도 할 수 있다.
a[:, true_false]
###
array([[ 2, 5],
[ 7, 10],
[12, 15],
[17, 20],
[22, 25]])a = np.arange(1, 26).reshape(5, 5)
---
print(a)
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]
[21 22 23 24 25]]
---
print(a > 10)
[[False False False False False]
[False False False False False]
[ True True True True True]
[ True True True True True]
[ True True True True True]]
---
print(a[a > 10])
[11 12 13 14 15 16 17 18 19 20 21 22 23 24 25Fancy Indexing
선택적으로 Index를 사용할 수도 있다.
a = np.arange(1, 26).reshape(5, 5)
print(a)
print('---')
print(a[[1, 3, 4]])
###
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]
[21 22 23 24 25]]
---
[[ 6 7 8 9 10]
[16 17 18 19 20]
[21 22 23 24 25]]다음과 같이 다차원으로 인덱싱 할 수도 있다.
x = np.array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
rows = np.array([[0, 0],
[3, 3]], dtype=np.intp)
columns = np.array([[0, 2],
[0, 2]], dtype=np.intp)
x[rows, columns]
###
array([[ 0, 2],
[ 9, 11]])기본 연산
벡터와 스칼라의 연산에 대해서 알아보자.
단일 행렬에서 연산
import numpy as np
x = np.array([[1,2,3],
[4,5,6]])
---------------------------------
array([[1, 2, 3],
[4, 5, 6]])슬라이싱도 할 수 있지만 우선 기본 연산만 해보도록 하자.
덧셈
x + 1
--------------------
array([[2, 3, 4],
[5, 6, 7]])뺄셈
x - 1
--------------------
array([[0, 1, 2],
[3, 4, 5]])곱셈
x * 3
-------------------
array([[ 3, 6, 9],
[12, 15, 18]])나눗셈
1 / x
--------------------
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])제곱근
x ** 2
--------------------
array([[ 1, 4, 9],
[16, 25, 36]])행렬 간 연산
x = np.array([[1,2,3],[4,5,6]])
y = np.array([[5,6,7],[8,9,10]])
print(x)
print('---')
print(y)
############
[[1 2 3]
[4 5 6]]
---
[[ 5 6 7]
[ 8 9 10]]덧셈
x + y
##############
array([[ 6, 8, 10],
[12, 14, 16]])뺄셈
x - y
##############
array([[-4, -4, -4],
[-4, -4, -4]])곱, 행렬곱
x * y # 곱
x @ y.T # 행렬곱나눗셈
x / y
##############
array([[0.2 , 0.33333333, 0.42857143],
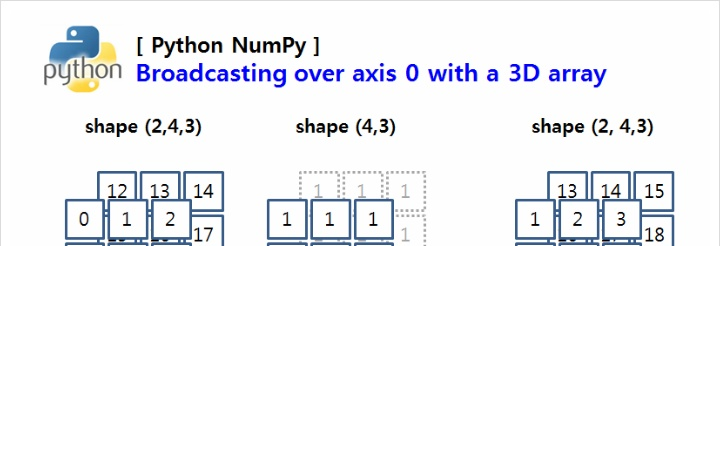
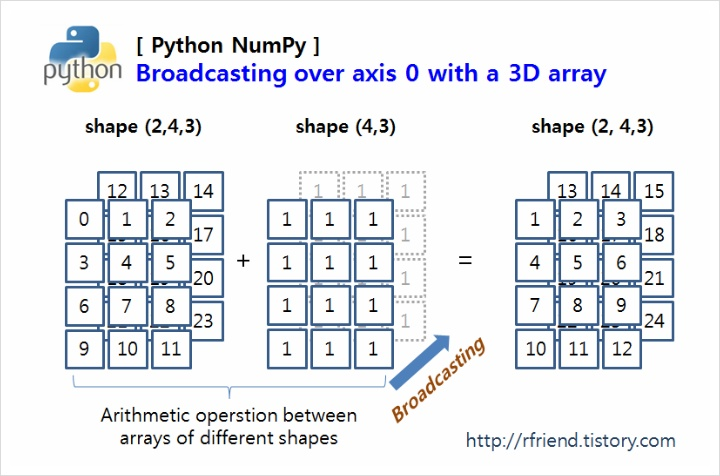
[0.5 , 0.55555556, 0.6 ]])브로드캐스팅
broadcast에는 전파라는 의미가 있다. 방송과 관련 된 용어에 익숙하여 의미가 직관적이지 않다고 생각 할 수 있지만, 여기서 브로드캐스팅을 전파라는 뜻으로 생각하면 조금 더 이해하기 쉽다.
일반적으로 Numpy는 모양이 다른 배열끼리는 연산이 불가능하다. 이러한 불편함을 해결하기 위해 서로 다른 모양이더라도 연산을 가능하도록 해 주는 기능이 브로드캐스팅이다.
서로 다른 모양의 배열을 모두 연산 가능토록 해 주는 것은 아니다. 어떠한 조건을 만족 할 경우 브로드캐스팅을 통한 연산이 가능하다. 그렇다면 어떤 조건을 만족해야할까?
- 차원의 크기가 1일 때 가능하다.
두 배열 간의 연산에서 최소한 하나의 배열의 차원이 1이라면 가능하다.
- 차원의 짝이 맞을 때 가능하다.
차원에 대해 축의 길이가 동일하면 브로드캐스팅이 가능하다.
예제를 통하여 위의 내용을 이해해보자.
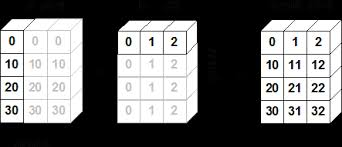
a = np.array([0. , 10. , 20. , 30. ]).reshape(4, -1)
############
print(a)
[[ 0.]
[10.]
[20.]
[30.]]
############
print(a.shape)
(4, 1)b = np.array([0. , 1. , 2. ])
print(b.shape)
#############
(3,)위의 그림을 numpy를 활용하여 배열로 나타내면 위와 같이 표현 될 것이다.
이 a와 b는 차원의 크기가 1이라는 조건을 만족하기 때문에 브로드캐스팅을 활용하여 연산을 할 수 있다. 따라서 이를 연산하면 다음과 같다.
print(a + b)
############
array([[ 0., 1., 2.],
[10., 11., 12.],
[20., 21., 22.],
[30., 31., 32.]])이렇게 브로드캐스팅 기능을 활용할 수 있다.
Numpy 함수
numpy에서 주로 사용할 수 있는 기초적인 유용한 함수에 대해 알아보자.
단일 연산 함수 (유니버셜 함수)
내부의 원소를 일체적으로 변경시킨다고 하여 ufunc(universal function) 라고 불린다.
random
랜덤한 수의 배열을 만들 수 있다.
np.random.seed(42)
arr = np.random.randint(-10, 10, (3, 4)) # random의 int 숫자 범위, (3, 4) 크기의 배열abs
절댓값을 표현할 수 있다.
np.abs(arr)sqrt
제곱근을 표현할 수 있다.
np.sqrt(arr)해당 메소드를 사용했을 때, <ipython-input-4-b58949107b3d>:1: RuntimeWarning: invalid value encountered in sqrt np.sqrt(arr) 위와 같은 에러가 발생할 수 있다. 이런 에러가 발생하는 이유는 음수에 제곱근을 사용하려 했기 때문에 발생한다.
numpy에서는 수가 될 수 없는 값을 nan, 범위를 넘은 수를 inf 로 표기된다.
이런 에러가 발생한 경우는 다음과 같이 절댓값을 활용하여 음수를 양수로 바꿔준 후 제곱근을 해 줄 수 있도록 하자.
np.sqrt(np.abs(arr))square
제곱 표현
np.square(arr)exp
numpy의 exp함수는 exponential 값. 즉, 지수함수의 값을 구하는 함수이다.
np.exp(arr)log
지수함수를 표현했으니 log 함수도 표현할 수 있다.
arr2 = np.abs(arr)
np.log(arr2)sign
sign() 는 부호 판별 함수이다. 수가 1 또는 0 또는 -1 인지로 표현된다.
- 1로 표현 될 경우 경우 : 양수(Positive)
- 0으로 표현 될 경우 : 0(Zero)
- -1로 표현 될 경우 : 음수(Negative)
np.sign(arr)ceil
numpy에서 사용되는 올림함수이다.
np.ceil(arr)floor
numpy에서 사용되는 내림함수이다.
np.floor(arr)isnan
배열의 값에 None 값이 있는지를 참, 거짓의 Boolean값으로 판별 해 주는 함수이다. None이 있다면 True, 없다면 False를 리턴한다.
np.isnan(arr)isinf
위에서 numpy는 표현할 수 있는 범위의 수를 벗어나면 inf로 표현한다고 하였다. 따라서 isinf는 표현 범위를 벗어 난 수가 있는지 없는지를 Boolean 값으로 리턴 해 주는 함수이다.
np.isinf(arr)삼각함수
sin, cos, tan와 같은 삼각함수도 표현할 수 있다.
np.cos(arr)
np.sin(arr)
np.tan(arr)2개의 array를 위한 함수
2개의 array를 사용하는 함수도 기본 numpy의 연산과 비슷하다.
산술 연산
- add
np.add(x, y)- subtract
np.subtract(x, y)- multiply
np.multiply(x, y)- divide
np.divide(x, y)비교 연산
2개의 array를 비교 할 수 있는 연산이다.
- minimum : 2개의 array의 각 행과 각 열을 각각 모두 비교하여 더 작은 값을 찾는다.
np.minimum(x, y)- maximum : 더 큰 값을 찾는다.
np.maximum(x, y)연결 연산
2개의 array를 연결 시킬 수 있는 함수이다. 해당 메소드를 사용 할 때는 인자를 tuple형태로 넘겨주도록 하자.
x = np.full((3, 4), 1)
y = np.full((3, 4), 2)- hstack : 두 배열을 수평으로 연결시킨다.
np.hstack((x, y))- vstack : 두 배열을 수직으로 연결시킨다.
np.vstack((x, y))- dstack, stack : 새로운 축으로 배열 1과 배열 2를 이어 붙일 수 있다.
np.dstack((x, y))
np.stack((x, y))
np.stack((x, y), axis = 1)
np.stack((x, y), axis = 2)통계 메서드
numpy에서는 각 array에 대한 통계에 활용할 수 있는 값들을 쉽게 얻을 수 있게 지원한다.
arr_1d = np.random.randint(-20, 20, (6))
arr_2d = np.random.randint(-20, 20, (3, 4))
arr_3d = np.random.randint(-20, 20, (2, 3, 4))- sum : 모든 행, 렬의 합
print(arr_1d.sum())
print(arr_2d.sum())
print(arr_3d.sum())이 통계와 관련 된 모든 함수는 다양하게 axis를 설정하며 원하는 축의 값을 얻을 수 있다.
print(arr_2d.sum(axis=0))
print(arr_2d.sum(axis=1))- mean : 평균 값
print(arr_1d.mean())
print(arr_1d.mean())
print(arr_1d.mean())- std : 표준편차
- min : 최솟값
- argmin : 최솟값 색인. 최솟값이 어디있는지 알려준다.
- max : 최댓값
- argmax : 최댓값 색인. 최댓값이 어딨는지 알려준다.
- cumsum : 배열에서 주어진 축에 따라 누적되는 원소들의 누적 합을 계산하는 함수. 각 row와 column의 구분이 없어지고 순서대로 sum을 한다.
- cumprod : 배열에서 주어진 축에 따라 누적되는 원소들의 누적 곱을 계산하는 함수
