VectorDB와 RAG 성능
RAG의 검색 흐름을 되짚어보자.
사용자 질의에 대해 Vector DB 검색 후 여기서 관련 문서를 추출한 뒤 LLM에 전달한다.
LLM은 이 RAG 데이터를 토대로 답변을 생성하게 된다.
당연히, Vector DB에서 추출된 RAG 데이터가 검색 정확도와 직결되어 있다.
Naive RAG에서 Advanced RAG로 나아가기 위해서는 코사인 유사도에 의존하는 유사도 검색으로는 한계가 있다.
이번에는 VectorDB를 어떻게 구성하고, 임베딩 품질과 Chunk 정략을 어떻게 수립하고, 어떤 VectorDB 엔진을 사용하는 것이 가장 우수한 성능 캐파로 이어지는지 알아보고자 한다.
1. Naive RAG의 한계
가장 기본적인 LLM 기반 RAG 파이프라인
사용자 질의 → 벡터 검색 결과 → LLM 프롬프트 주입
투박하게 말하자면, 그냥 내부 데이터를 모두 벡터DB에 넣고, "A랑 비슷한거 찾아줘" 와 같은 방식이다.
문서의 양이 적고, 질이 보장된 경우는 Naive RAG로 충분할 수 있지만, 지식의 양이 방대해질 수록 분명히 한계가 존재한다.
ⓐ Indexing 의 한계
- 문서를 Chunking하는 단순 분할로 데이터의 구조적 의미가 누락, 변형 가능
- 긴 문서의 맥락을 파악하는 대신 단어의 코사인 유사도에만 의존
ⓑ Retrieval의 한계
- 사용자 질문을 정확히 임베딩하지 못한 경우 불필요한 노이즈를 포함
ⓒ Generation의 한계
- 답변을 생성할 때 LLM은 문맥을 파악하지 못하고, 환각 위험성
ⓓ Optimization의 한계
- 문서양이 많아질 수록 topK와 같은 파라미터 최적화가 더 어려워짐
RAG(Retrieval-Augmented Generation) 시스템을 구축하다 보면 이런 경험을 한 번쯤 하게 된다.
"분명히 문서에 있는 내용인데, 왜 검색이 안 되지?"
필자가 WCS 자동화창고 RAG 챗봇을 만들면서 딱 이 상황을 겪었다.
매뉴얼에 분명히 "Cell 저장 설정 유형" 내용이 있는데, 검색 결과에는 로그인 화면 설명만 나오는 것이다.
원인을 추적해보니 문제는 세 곳에 있었다.
- 임베딩 모델 — 도메인 용어를 제대로 이해하지 못함
- Chunking 전략 — 문서를 잘못 잘라서 내용이 유실됨
- VectorDB 엔진 설정 — 검색 파라미터가 최적화되지 않음
이 글에서는 각각의 문제와 해결 방법을 실제 경험을 바탕으로 정리한다.
2. 임베딩 모델 선택
2-1. 임베딩이란?
임베딩은 텍스트를 숫자 벡터로 변환하는 과정이다.
"입고 작업 현황" 이라는 문장이 [0.23, -0.51, 0.87, ...] 같은 숫자 배열이 된다.
검색할 때는 질문과 문서의 벡터 간 거리(코사인 유사도)를 계산해서 가장 가까운 문서를 가져온다.
질문: "Cell 저장 설정 유형은?"
↓ 임베딩 변환
[0.12, 0.45, -0.33, ...]
↓ 코사인 유사도 계산
문서 청크들과 비교 → 가장 유사한 청크 반환2-2. 벡터 임베딩 모델(Vector Embedding Model)이란?
텍스트, 이미지, 오디오 등의 비정형 데이터를 컴퓨터가 이해할 수 있는 숫자의 나열인 벡터(Vector)로 변환하는 AI 머신러닝 모델
2-3. 임베딩 모델 선택이 중요한 이유
임베딩 모델에 따라 같은 문서도 벡터 공간에서 전혀 다른 위치에 놓인다.
특히 한국어 도메인 전문 용어가 많은 경우 일반 임베딩 모델은 한계가 있다.
아래 모델을 비교해보았다.
| 모델 | 크기 | 한국어 지원 | 폐쇄망 | 특징 |
|------|------|------------|--------|------|
| nomic-embed-text | 137M | 보통 | ✅ | Ollama 지원, 설치 간편 |
| mxbai-embed-large | 335M | 보통 | ✅ | 영어 강점 |
| bge-m3 | 570M | 우수 | ✅ | 한국어/다국어 최강 |
| text-embedding-3-small | - | 우수 | ❌ | OpenAI API 필요 |
| kakaobank/kf-deberta | 111M | 특화 | ✅ | 금융 도메인 특화 |
① BGE-M3
- '설비 ID','에러코드' 등 고유 명사 짚어내는 데 최적
② OpenAI text-embedding-3-large/small
- 비용-성능 밸런스가 우수. 다국어 처리에도 우수, 특별한 인프라 구축 없이 OpenAI API Docs를 통해 즉시 테스트 데이터셋을 만들어 성능을 평가하기에 유리
③ multilingual-e5-large-instruct
④ Solar-Embedding-1-Mini
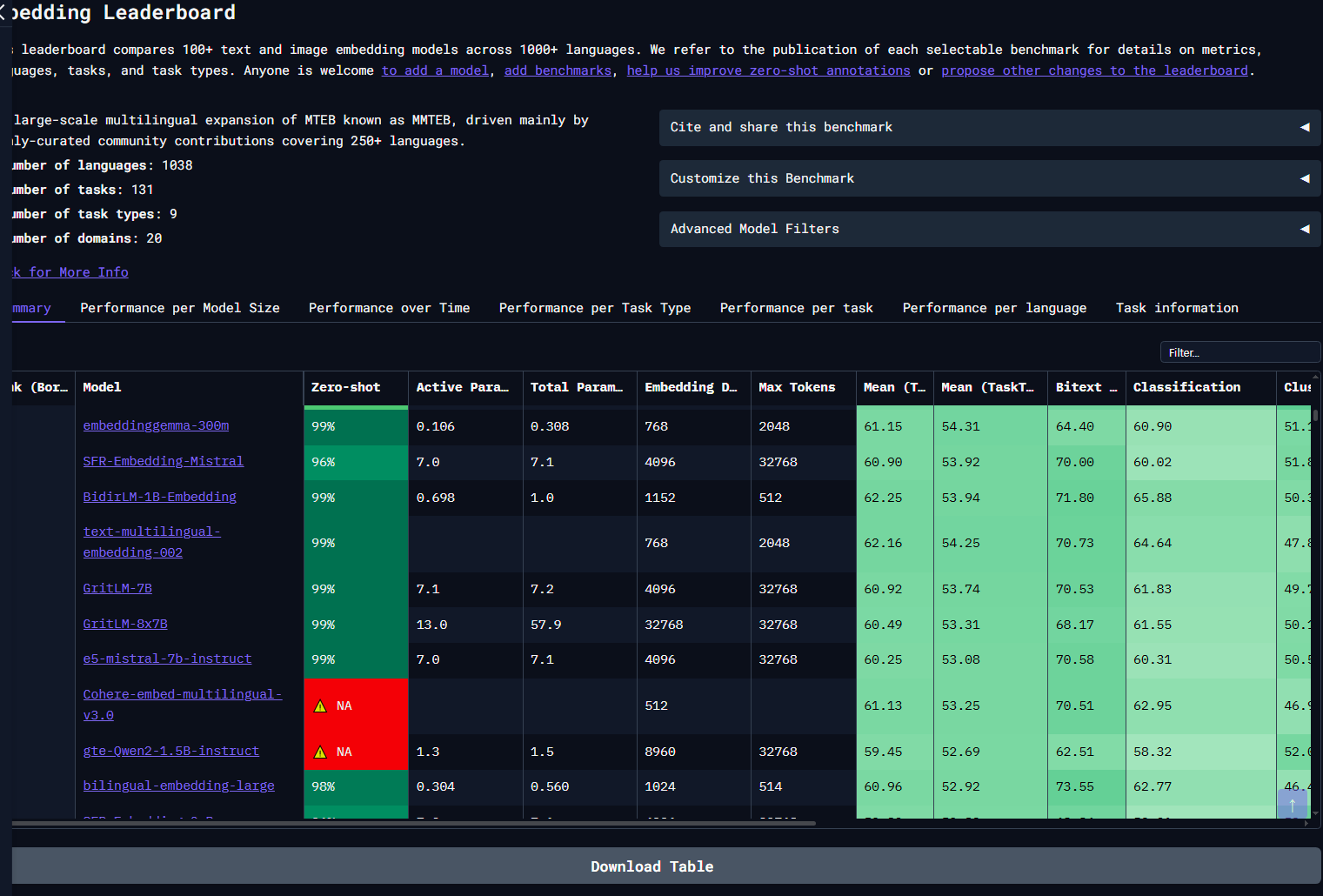
모델 선정 시 몇 가지 참고 지표는 다음과 같다.
(모든 모델을 분석 도입해볼 수 없음)
- ⓐ Zero-Shot : 학습되지 않은 데이터의 임베딩(벡터화) 수행 능력
- ⓑ Active / Total Param : 활성 파라미터/총 파라미터
모델이 작동시키는 파라미터 수 는 추론 속도와 직결된다.
전체 모델의 파라미터 수는 VRAM 성능과 직결된다. - ⓒ Retreival(nDCG@10) : RAG 핵심 성능으로 검색 정확도
*HuggingFace: 임베딩모델 Hub. 링크 내 여러 모델을 비교 도입하여 내 시스템에 적합한 모델을 찾아보도록 한다.
2-4. 도메인 특화 임베딩의 중요성 ★
WCS 도메인에서 이런 용어들이 문제가 된다.
"호기" ↔ "스태커크레인" ↔ "STC" → 같은 의미이지만 다른 벡터
"BCR" ↔ "바코드 리더기" → 같은 의미이지만 다른 벡터
"T_WORK" ↔ "작업 테이블" → 연관성 낮게 측정
"작업" ↔ "지시" ↔ "잡" ... → 연관성을 파악하지 못함일반 임베딩 모델은 이런 도메인 약어/전문용어 간 의미적 연결을 잘 못 한다.
그렇다고 모든 도메인 정보를 스키마로 제공할 수 없는 노릇이다.
⚠️ 참고
Groq = 초고속 LLM 추론 전문으로, Chat 모델만 제공 (llama, gemma 등)
→ 임베딩 모델 없음 & 공식적으로 지원 계획 없음
2. VectorDB 임베딩 모델 비교
전부 동일한 Rag 데이터를 사용해 답변을 비교해보도록 하자.
2-1. harrier-oss-v1-27b
현 시점(2026.06) 최우수에 가까운 Retreival을 갖는 벡터 임베딩 모델이다.
Microsoft 사에서 공개한
1-3. Chunking 전략
1-4. VectorDB 엔진 비교
1-5. Hybrid Search
1-6. Re-Ranking
1-7. Threshold & Top K 튜닝
* 2026. VectorDB 비교
* VectorDB란?
※ chromadb 동일 파일 중복 적재?
