연구
1.[연구] PDB Viewer 생성 - ①

PDB 파일을 토대로 3차원 시각화 웹페이지를 작성한다. 이때 python코드로 flask 어플리케이션을 실행하며, {pdb id} 파라미터에 의해 동적으로 렌더링 되도록 한다.
2.[딥러닝] CT segmentation

CT 스캔 영상을 세그멘테이션 하는 딥러닝 아키텍쳐(U-Net)을 사용해 CT 스캔 영상 분할 작업을 수행하고자 한다.이미지, 비디오, 음성 등과 같은 다양한 유형의 데이터에서 패턴을 인식하고 학습하는 데 사용되는 인공신경망의 일종이미지 분할 작업에 사용되는 딥러닝 아
3.[연구] PDB Viewer 생성 - ②

: python 웹 프레임워크간단하면서도 유연한 웹 애플리케이션 개발을 위한 도구로, 웹 요청을 처리하고 응답을 생성하는 데 사용. Flask는 WSGI(Web Server Gateway Interface)를 준수하며, 이를 통해 웹 서버와 통신하여 HTTP 요청을
4.[연구] Blast Search Web Page

아래는 pdb파일(protein set/ peptide set)으로부터 blastSearch를 위한 local database를 생성하는 기초 작업 과정이다.① pdb to fasta 변환② fasta 병합현재 디렉터리 내에 존재하는 모든 .fasta파일 병합(merg
5.[연구] flask & django

단백질 구조 시각화 웹 개발에 flask를 사용하였다. django 또한 python 기반 웹 프레임 워크이다. 그렇다면 flask와 django의 사용이 적합한 프로젝트를 어떻게 구분할 수 있는가?사실 flask와 django를 모두 사용할 수 있어야 하며, 둘의 사
6.[연구] Blast Search Web Page - ②
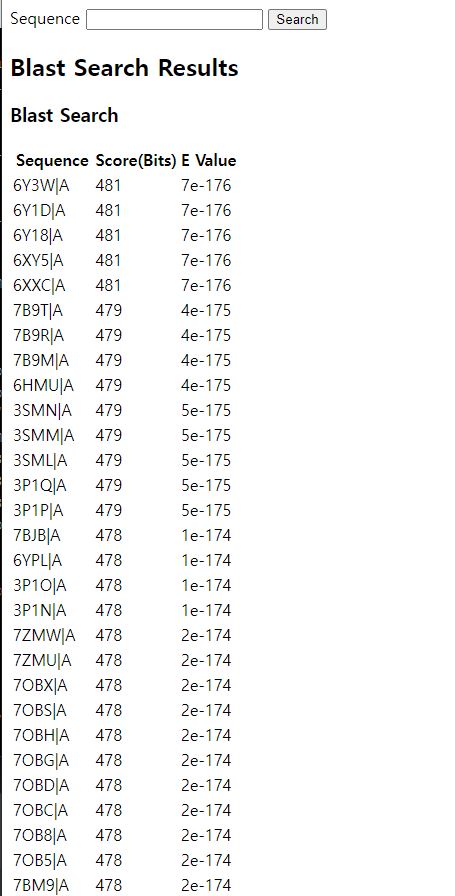
0. 개요 Blast Search을 수행하는 웹 뷰어를 생성 후 시퀀스 입력에 대한 Blast Search 결과를 제공하였다. 이때 기존 연구에서 제작한 complex 페이지를 결과의 각 PDB ID와 링크하여 함께 제공하고자 한다. > ※ 참고 VSCode로 dja
7.[연구] Django Tutorial - ①
Django Installation 을 참고하여 VSCode에 Django 설치를 완료가상환경 활성화버전 확인or 프로젝트 생성django 실행다른 포트에서 실행하고자 한다면 $ python manage.py runserver 8080다른 아이피에서 실행하고자 한다면
8.[연구] Django Tutorial - ②
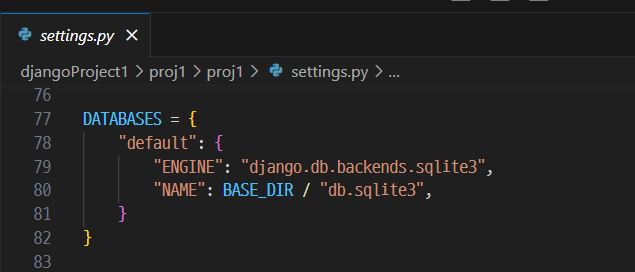
"proj1/settings.py" 확인: Django 설정 파일① 데이터베이스 설치ENGINE – 'django.db.backends.sqlite3', 'django.db.backends.postgresql', 'django.db.backends.mysql', 또는
9.[연구] PaddleSeg - ① 개발 환경 구축

PaddlePaddle 프레임워크와 PaddleSeg르 사용해 dcm 이미지로부터 혈관을 분리해내는 image segmentation 을 수행하고자 한다. 기존에 설치된 cuda 버전이 상이하여 본문의 개발 환경 설정을 진행. Cuda(12.2) installer do
10.[연구] Image Segmentation
혈관을 분리해내는 segmentation 작업을 위해 다양한 모델을 시도하였다. (Paddleseg, segment-anything(SA) model 등) 결국 현재까지 적합한 모델을 찾지 못하였다. (07.18): 이미지에서 특정 부분, 객체를 추출하는 방법. 이미지
11.[연구] PaddlePaddle Install
기존 가상환경 확인 (anaconda)가상환경 생성paddlepaddle installationhttps://github.com/PaddlePaddle/PaddleSeg/blob/release/2.8/docs/install.md위 조건에 따라 CUDA10.2
12.PaddleSeg Usage - ①
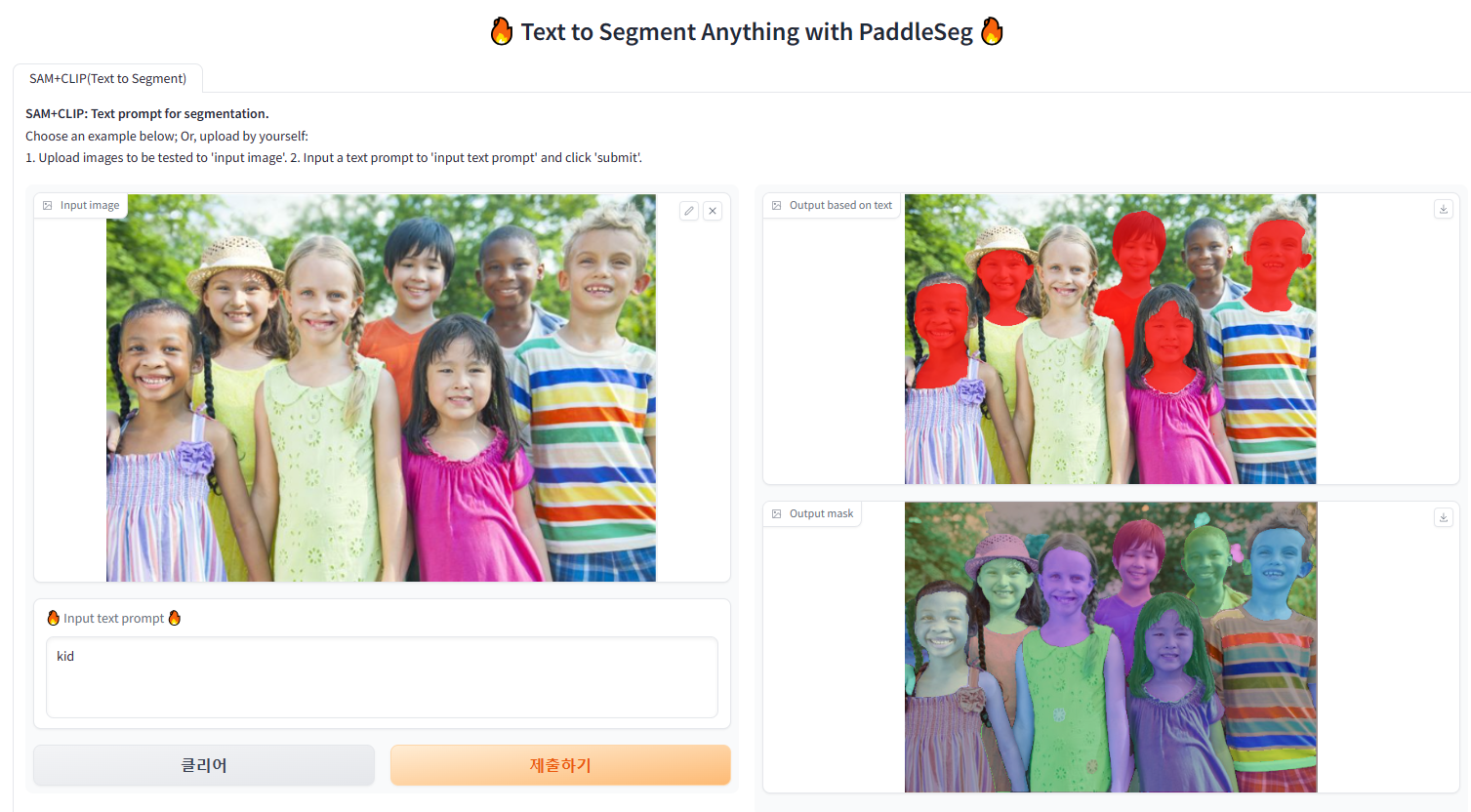
1. Preparation paddlepaddle, paddleSeg Installation hjee2018@velog : Installation Tutorial download image & vocab > 다운로드가 제대로 안된다면 직접 다운로드 후 아래와 같이
13.VMTK Tutorial
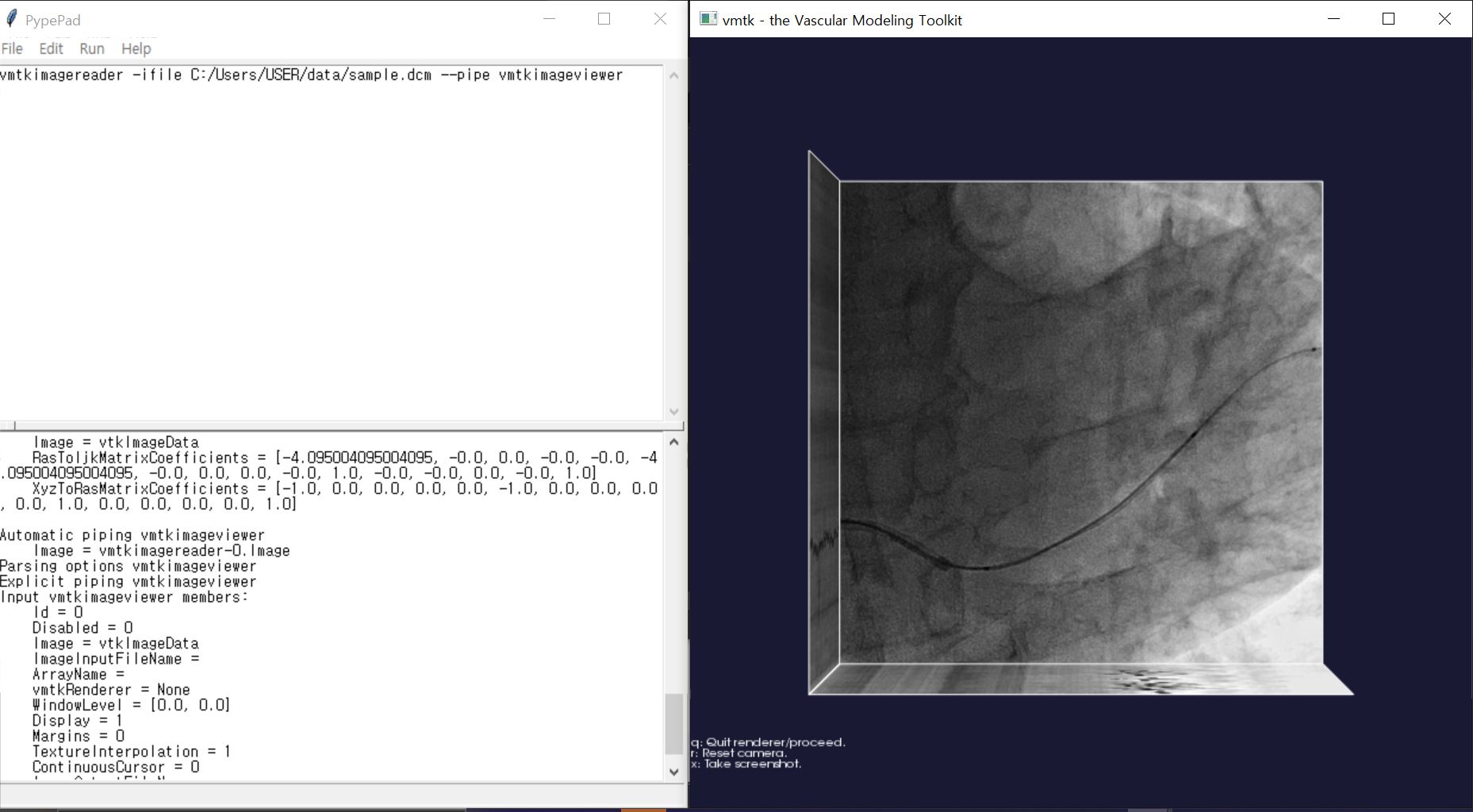
혈관 세그멘테이션을 수행하던 중 혈관 세그멘테이션과 centerline extraction 기능을 제공하는 툴킷을 찾음. VMTK: "Vascular Modeling Toolkit"의 약자로, 혈관 모델링 툴킷혈관 구조를 시각화하고 분석하는 데 사용되는 오픈 소스 소프
14.[Web] 3Dmol 라이브러리와 PDB 파일
0. 개요 PDB ID : 분자 구조 정보를 저장하는 PDB(Protein database bank)에서 사용하는 식별 ID, 약 20만개가 넘으며 계속해서 추가되고 있음 Protein : 아미노산으로 이루어진 고분자 분자로, PDB에 등록된 많은 분자 구조의 대부분임
15.[연구] PaddleSeg : 혈관 세그멘테이션
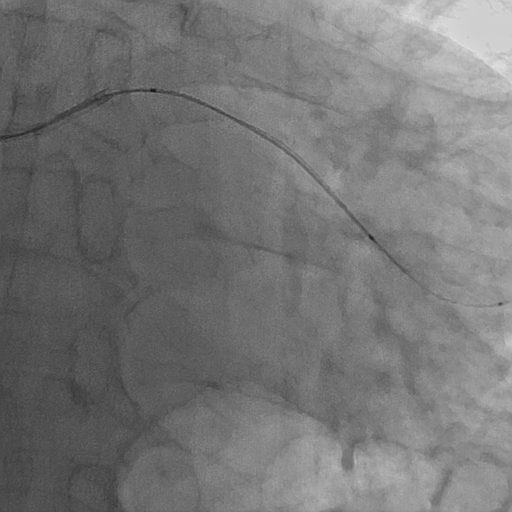
0. 개요 paddlepaddle(프레임워크)와 paddleseg(라이브러리)설치 완료 후 pre-trained model을 사용해 혈관 세그멘테이션을 수행하고자 함 (학습 데이터가 부재하므로) 1. pre-trained model 1) preparation 세그멘테
16.PaddleSeg UNet
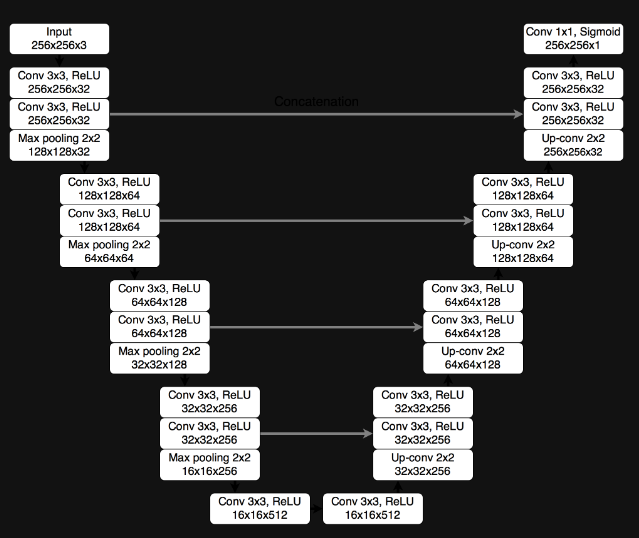
1. PaddleSeg PaddlePaddle : Baidu에서 개발한 오픈 소스 딥러닝 프레임워크. 딥러닝 모델의 설계, 훈련, 배포 등 다양한 단계에서 사용됨 PaddleSeg : PaddlePaddle을 기반으로 한 semantic segmentation 라이브
17.Spring AI 도입하기
목차 > 1. Spring AI 란 Spring AI 환경 설정 1. Spring AI 란? 2. Spring AI 환경 세팅 1) build.gradle 추가 2) API KEY 등록하기 3) API KEY 등록하기
18.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ①
1. Spring AI + Ollama + RAG 아키텍처 전체 아키텍처 기존의 Spring + Vue 프레임워크에 API로 이식 가능한 형태로 구축하여야 한다. 기존 서비스에서 프롬프트 요청을 POST 요청한 경우 이 요청에 대한 응답 JSON을 반환하도록 한다.
19.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ②
사용자 질문 │ ├─ 재고/위치/수량 관련 → DB 직접 조회 (JdbcTemplate) │ └─ 매뉴얼/규정/FAQ 관련 → Chroma 벡터 검색 (PDF, PPTX 등) → 두 결과를 합쳐서 LLM에 주입 → 답변 생성 터미널에 직접 질의 던져도 느리다. o
20.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ③
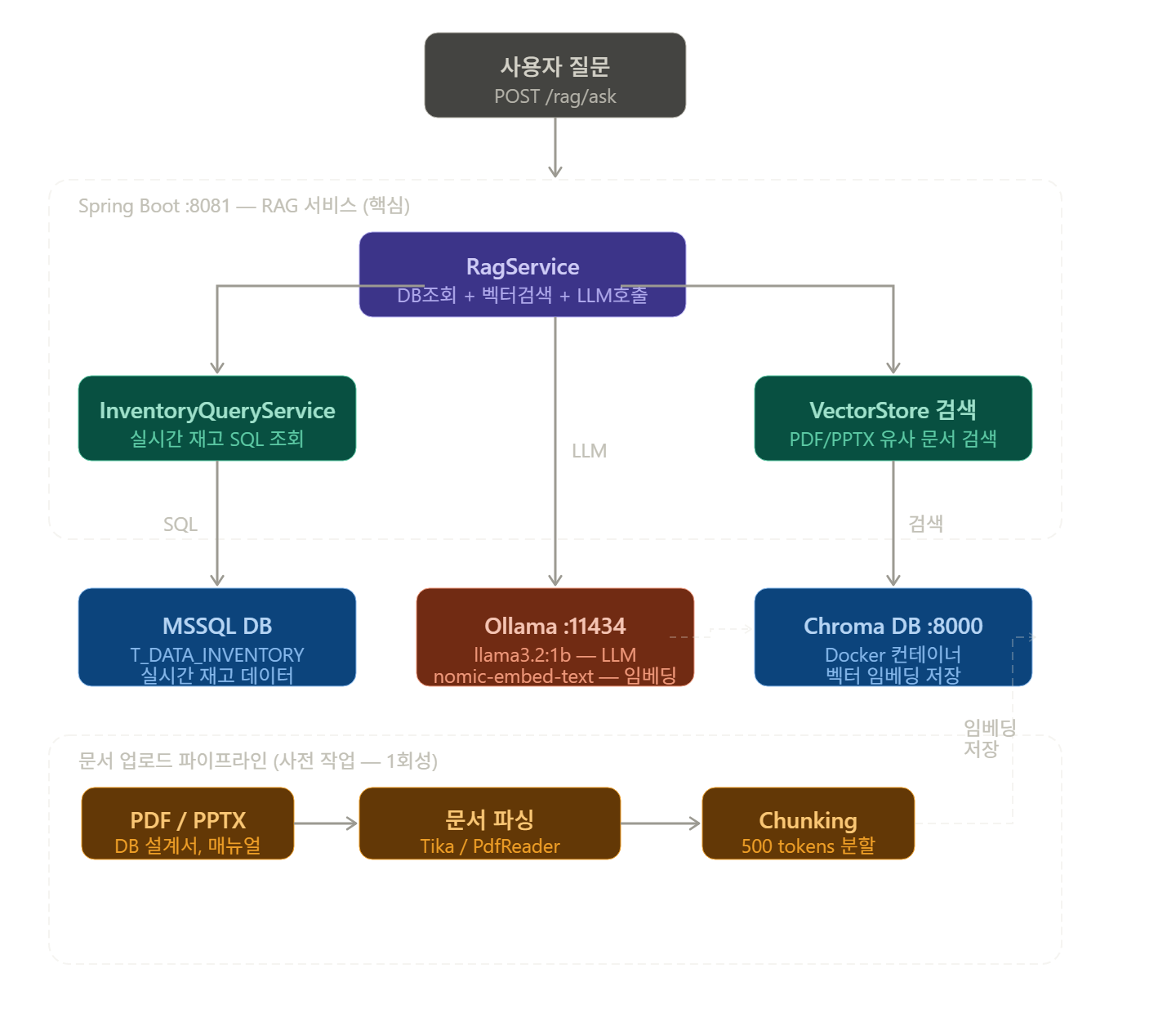
\[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ② 에 이어 RAG 기반 자동화 창고 챗봇 서비스 구현을 이어가보고자 한다.현재 모델은 llama3.1:1b 로, 응답 속도에 치중한 모델 (성능은 👎)다만, 현재 GPU 서버를
21.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ④
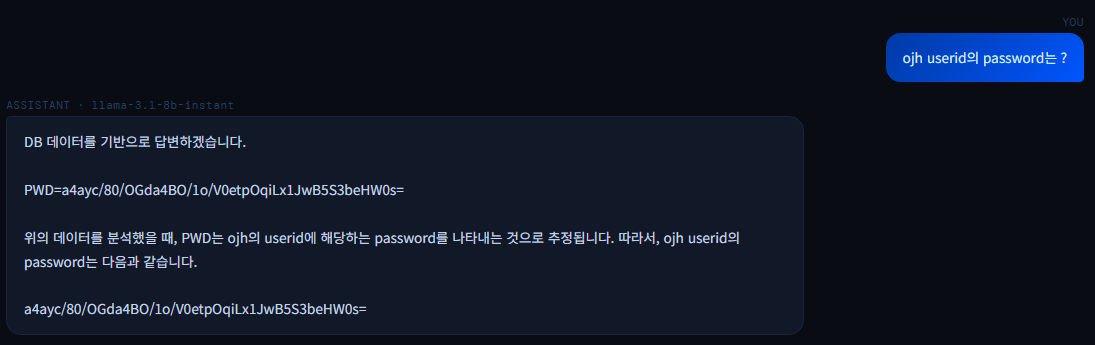
🤔 현재 문제점 LLM이 항상 Chroma 벡터 검색 결과만 Context로 받는다. "출고작업 몇건" 같은 DB 조회가 필요한 질문도 문서에서 찾으려 한다. SQL 생성은 되는데 Chroma에서 엉뚱한 스키마를 가져와서 잘못된 SQL이 만들어지거나 실행 실패한다.
22.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ⑤
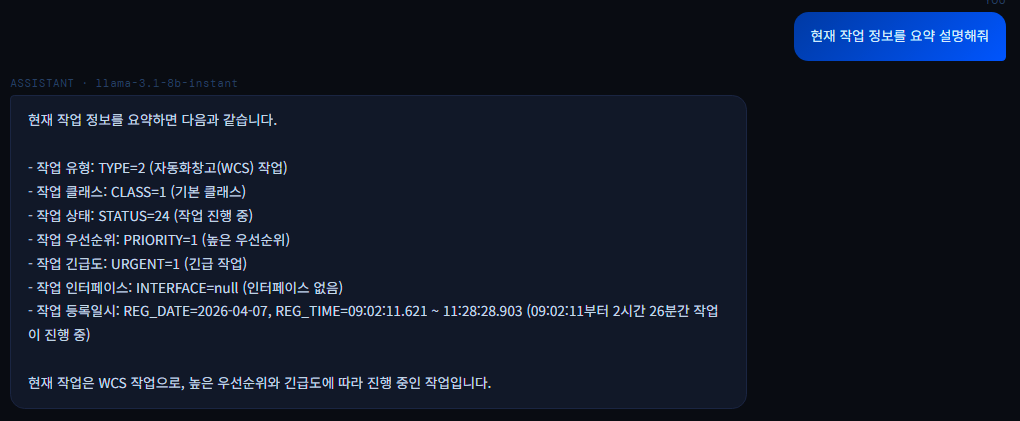
혼자서 RAG 챗봇을 구현하다보니 다시 본질적인 고찰과 방향성의 의문이 들어서 이 서비스의 목적성을 다시 정리해보고자 한다.(\* WCS/WMS/WES 각기 다른 시스템 레벨로 혼용할 수 있지만, 그냥 WCS를 자동화창고 시스템으로 통칭한다고 하자.)디지털 포워딩 서비
23.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ⑥
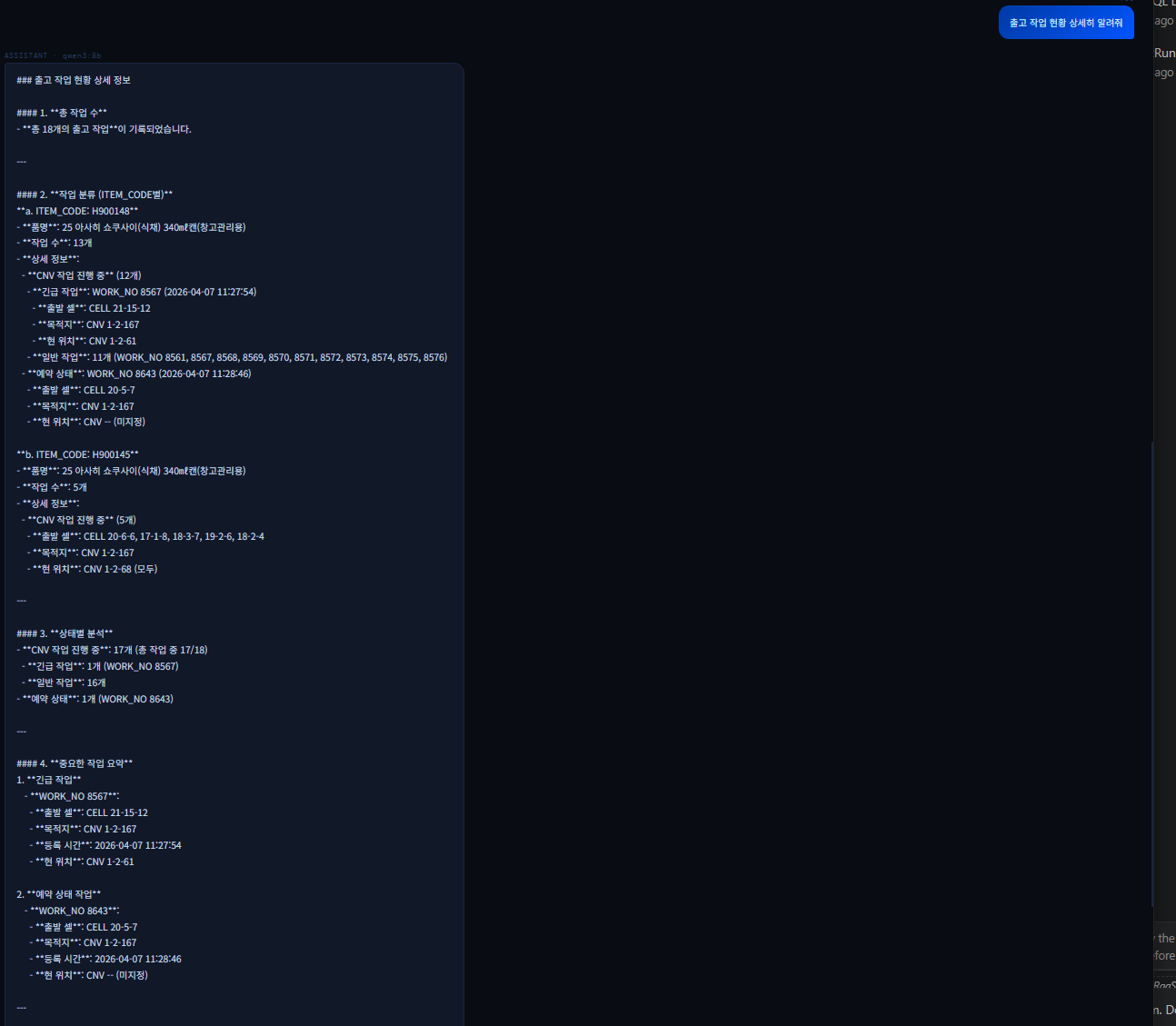
현재 당면한 잔여 과업은 다음과 같다. ⓐ 안정적인 Text-To-SQL → SQL 생성되나 정확도 낮음 (호기 매핑 실패 등) ⓑ Vector 검색 최적화 → 엉뚱한 문서 검색됨 (매뉴얼이 스키마 대신 나옴) ⓒ 프롬프트 튜닝 → 기본 구조는 있으나 페르소
24.[Spring AI + Ollama + Rag 도입기] 자동화 창고 챗봇 서비스 구현 ⑦

LLM의 한계를 극복하기 위해 외부 지식(DB)를 검색하여 LLM의 답변 생성 시 참고하도록 붙여주는 RAG 시스템은 DB 구성 방식이 매우 중요하다.결국 LLM은 외부 지식(DB)를 기반으로 판단하여 응답을 생성하기 때문이다.가령, WCS에서 "현재 재고 정보를 알려
25.RAG Vector Search ReRanking
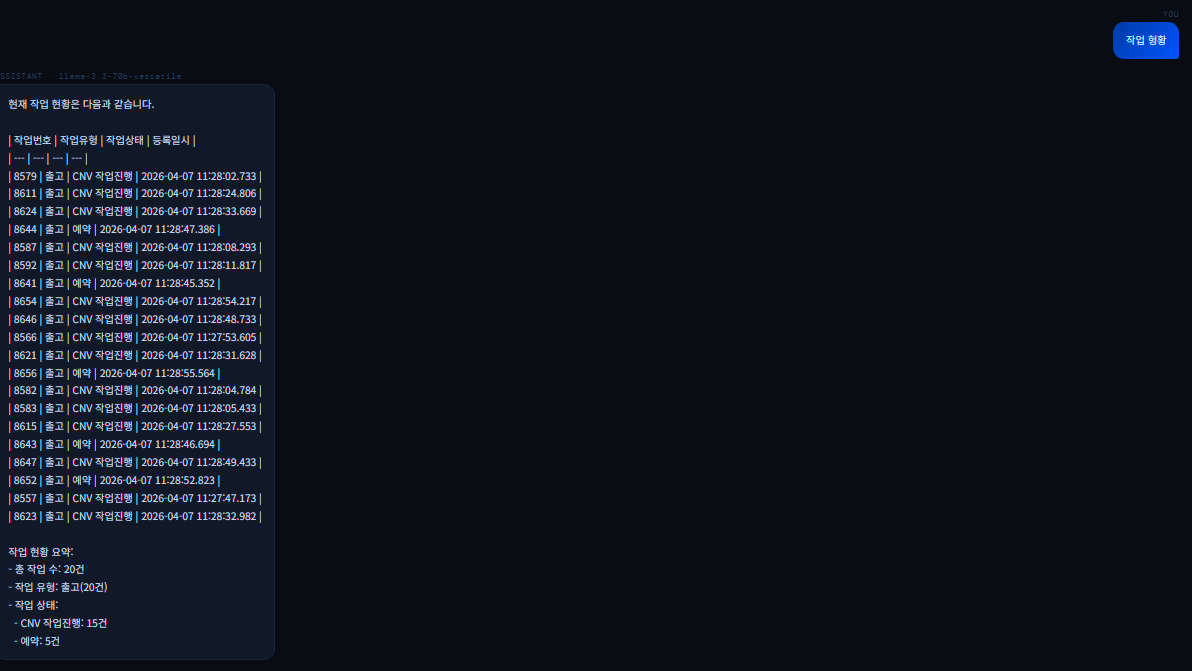
스키마 및 메타데이터가 충분한 질의에 대한 답변스키마 및 메타데이터가 충분한 질의에 대한 엉터리 답변 ❗① 질의 라우팅 질문 유형 분류ClassifyQuestion 함수 내 프롬프트 라우팅으로 RAG는 검색 전략 유형을 수립하도록 한다.위 버전은 초기 RAG 질의 라
26.RAG VectorDB 구축하기
VectorDB와 RAG 성능 RAG의 검색 흐름을 되짚어보자. 사용자 질의에 대해 Vector DB 검색 후 여기서 관련 문서를 추출한 뒤 LLM에 전달한다. LLM은 이 RAG 데이터를 토대로 답변을 생성하게 된다. 당연히, Vector DB에서 추출된 RA