
Virtual Memory
개념
- physical memory와 logical memory를 분리하는 기술
- 프로세스가 실행되기 위해서는 프로세스의 주소 공간이 모두 메모리에 올라와 있어야함
- 하지만 프로세스마다 주소공간의 크기가 매우 큼
- 이를 해결하기 위해 cpu에게는 process가 올라와 있다고 믿게하고, os가 실제 physical memory를 효율적으로 관리하는 기술 → virtual memory
- cpu가 page에 접근할 때 해당 page를 disk에서 memory로 올려주자
효과
- 어떤 프로세스의 주소 공간을 여러 프로세스에게 공유되도록 할 수 있다.
- fork를 할 때, 마치 새로운 프로세스가 만들어진 것 처럼 virtual memory로는 다른 영역을 주고, physical memory에서는 같은 영역을 가리키게 만드는 것
- copy를 만들지 않으므로 memory를 효율적으로 사용할 수 있고, process creation을 보다 빠르게 할 수 있음
- process의 logical address space가 physical address space보다 크더라도 실행시킬 수 있다.
- 실제로 접근하는 부분만 메모리에 올라오면 되기 때문
- cpu는 마치 모든 프로세스의 주소 공간이 메모리에 모두 올라와 있는 것처럼 느낌
Demand paging
페이지가 필요할 때만 메모리에 올리고 아닐 때에는 디스크에 내려버리는 기술
효과
- Less I/O, Less Memory
- memory에 모든 프로세스 주소 공간이 올라와야 프로세스를 실행할 수 있었는데, 이제 접근할 페이지만 메모리에 올라옴
- 그러므로 전체 총 I/O가 줄어들고, memory 사용량도 감소
- Faster response
- 메모리에 프로세스가 모두 올라오는 것을 기다릴 필요가 없으므로 반응성이 좋아짐
valid-invalid bit
- protection
- page table안에 주소 공간은 아니지만 요소로 있는 garbage 값이 있음
- 주소 공간의 크기를 모르니 여유롭게 page table을 만들기 때문
- 해당 칸들은 invalid
- not-in-memory
- page가 메모리에 올라와 있지 않음
- invalid page
- obsolete
- memory에 올라온 page가 disk에서 수정되어서 더 이상 쓸모 없을 때
- invalid page
- not-in-memory와 osbolete 상황에서 page를 디스크에서 메모리로 올려줘야 함
Page fault
virtual memory를 사용하기 위해서는 demand paging 기술을 이용해야 함
그러기 위해선 mmu가 logical address를 기준으로 page가 어느 frame이 저장되어 있는 지 알아내기 위해 page table을 look up 했을 때, valid bit이 invalid인 경우 우선 disk에서 page를 memory로 올려주고 이후에 physical memory로 바꾸는 작업을 진행해야 함
이를 page fault라고 함
invalid bit을 확인하면 trap이 발생하고 page fault handler가 page fault를 처리함
page fault 방식
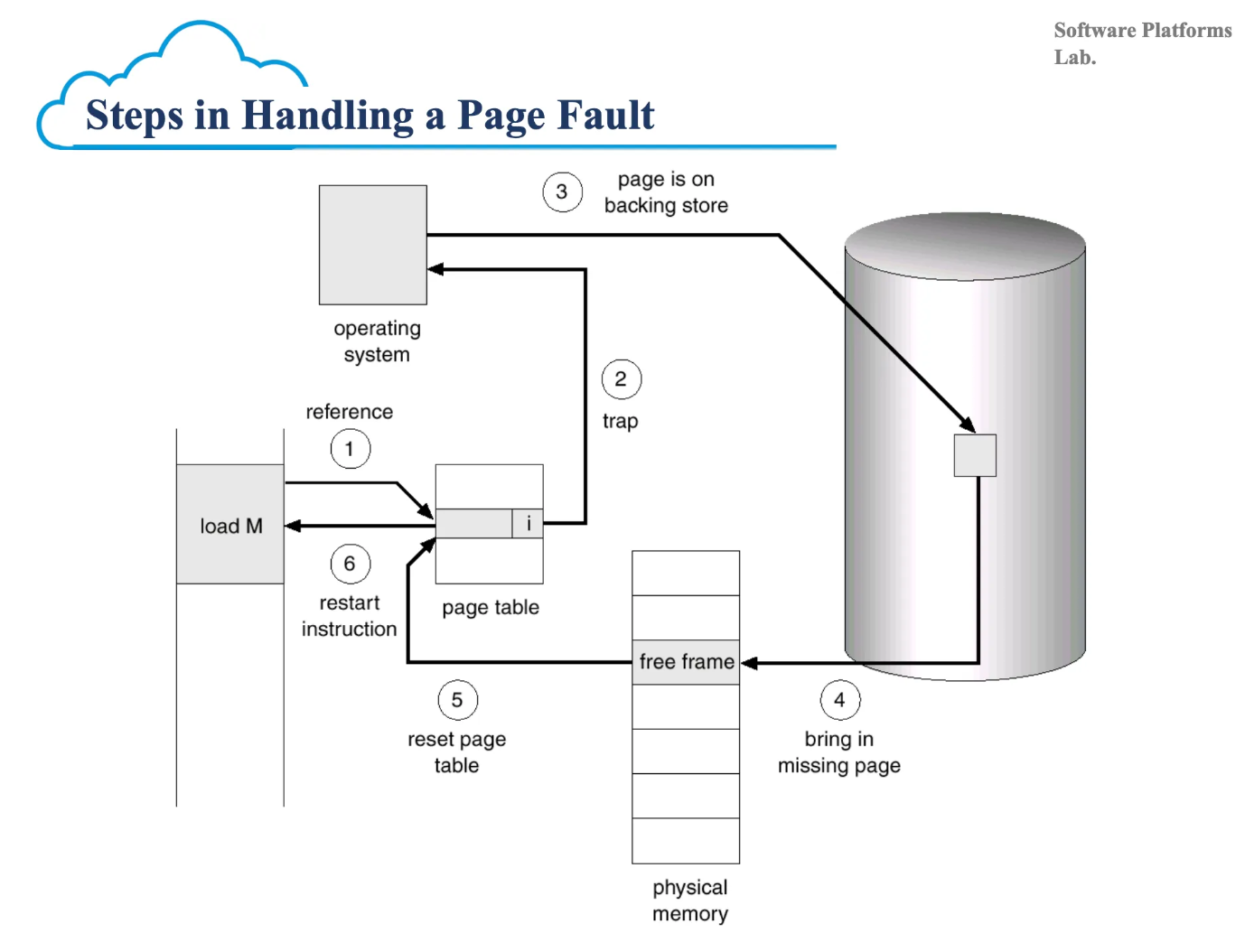
- illegal 참조인지 확인
- illegal이면 page 안올리고 abort
- disk에서 page를 올리기 위해 빈 frame을 찾음
- 만약 빈 frame이 없다면 page중 victim을 선정해 replace
- disk → memory page I/O
- process는 자신이 만든 I/O는 아니지만 wait 상태에 빠짐
- 코드 수행
원자성 문제
- instruction fetch 단계에서 발생하는 page fault는 상관 없으나, 수행 단게에서 발생하는 page fault는 문제를 야기할 수 있음
- instruction을 하던 중간에 page fault가 나면 data가 오염된 상태로 잠시 저장되어 있어야 할 수 있음
- 원자성이 깨져 해당 오염된 정보를 다른 곳에서 접근하면 오류가 발생할 수 있음
성능 문제
- disk → memory
- 빈 frame에 page를 채워 넣을 때 발생하는 I/O
- memory → disk
- replace의 경우 memory에 있는 page가 수정이 되었을 때, disk에 적을 때 발생하는 I/O
디스크는 매우 느리기 때문에 이는 엄청난 overhead
Demand Paging 성능에 영향을 주는 것
- pure demand paging
- cold start 문제
- 접근되는 page만 memory에 올라오기 때문에, 처음에 process가 시작 될 때 process의 모든 페이지가 메모리에 올라와 있지 않아서 발생
- 이를 해결하기 위해 몇가지 기술을 활용
- free paging: 미리 프로세스가 시작될 때 접근할 페이지를 memory에 올리는 기술
- read ahead: 접근되는 page 근처 page를 함께 가져오기
- 참조지역성
- 만약 page fault를 통해 메모리에 가지고 올라온 데이터가 계속 빈번하게 접근되어서 디스크에 접근할 일이 없다면 overhead를 크게 줄일 수 있음
- 실제로 locality가 상당히 강하기 때문에 page fault overhead는 거의 문제가 되지 않음
- 메모리에 올라와 있는 page가 앞으로 접근될 것이라 예측되는 page를 올려줘야 하고, replace 되지 않도록 유지시켜 참조 지역성을 극대화 해야함
- 페이지 교체 알고리즘이 중요함
Page 교체 알고리즘
개념
- 가상 메모리에서 page fault가 발생했는데 free frame이 없을 때, 기존에 올라와 있는 page 중 하나를 재물로 삼아 swap out하고 지금 접근한 page를 올려주는 것
- 어느 페이지를 쫓아 낼 것인지 결정하는 알고리즘
- program의 locality를 최대한 보존해주는 방향으로 페이지 교체를 해 page fault를 최소화
과정
- 디스크에서 불러온 page를 찾는다.
- 비어있는 frame을 찾는다. 찾으면 그냥 사용하고 찾을 수 없다면 victim frame을 선정해서 쫓아낸다. dirty frame 이었다면 disk에 write 해주고 clean page면 그냥 위에 덮어쓴다.
- 아까 찾은 page를 해당 프레임에 탑재시킨다.
- process를 다시 시작시킨다.
성능평가
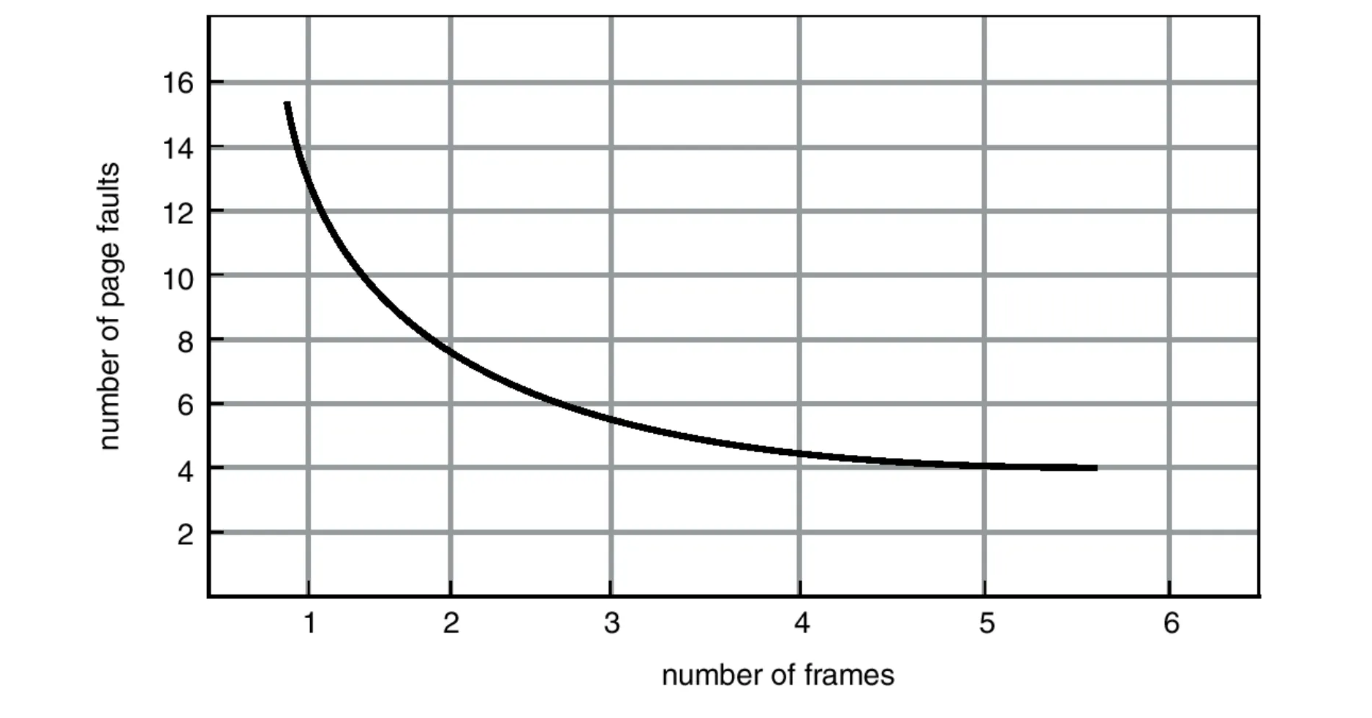
- 상식적으로 주어진 프레임의 수가 늘어나면 page fault는 덜 발생할 것이다
- 메모리에 올라올 수 있는 page가 많아지기 때문
- 한번 올라오면 memory가 disk로 쫓겨날 확률이 낮아지기 때문
- 이러한 반비례 성질을 따라가면 잘 만든 page 교체 알고리즘
FIFO algorithm
- 먼저 들어온 page를 먼저 victim으로 선정하는 알고리즘
- belady’s anomaly
- frame수가 증가해도 page fault가 감소하지 않고 오히려 증가하는 현상
- 예측을 벗어남
- belady’s anomaly
Optimal algorithm
- belady’s anomaly를 없애기 위해 최적의 상황을 가정
- FIFO algorithm에서 생각해보니, victim으로 선정된 page가 근래에 접근이 되는 경우에 page fault가 비효율적으로 발생
- 제일 나중에 접근될 페이지를 victim으로 선정하자
- 굉장히 좋은 방법이나, 미래를 예측할 수 없기 때문에 구현 불가
- 그래서 최적의 상황의 기준을 삼고 타 algorithm의 성능과 비교하는 지표로 사용
LRU algorithm
- optimal algorithm을 비슷하게 따라가기 위해서 미래를 예측해보기로 함
- locality에 기반하면, 최근에 접근된 page는 또 접근될 확률이 크다
- 그러니 가장 오래전에 접근한 page를 victim으로 삼자
- 이는 cache에서도 동일하게 적용한다
LRU Implementation algorithm
Counter implementation
- cpu의 실제 논리적 시간 혹은 memory에 접근한 회수를 page table에 작성하고, 가장 오래된 page를 victim으로 선정하는 방식
- 구현을 하기위해 각 page가 언제 접근되었는지 매번 접근 시에 page table에 작성을 해야하고, page fault가 발생해 victim을 선정할 때마다 O(n) 알고리즘으로 min값을 찾아줘야 하는 overhead가 발생
Stack implementation
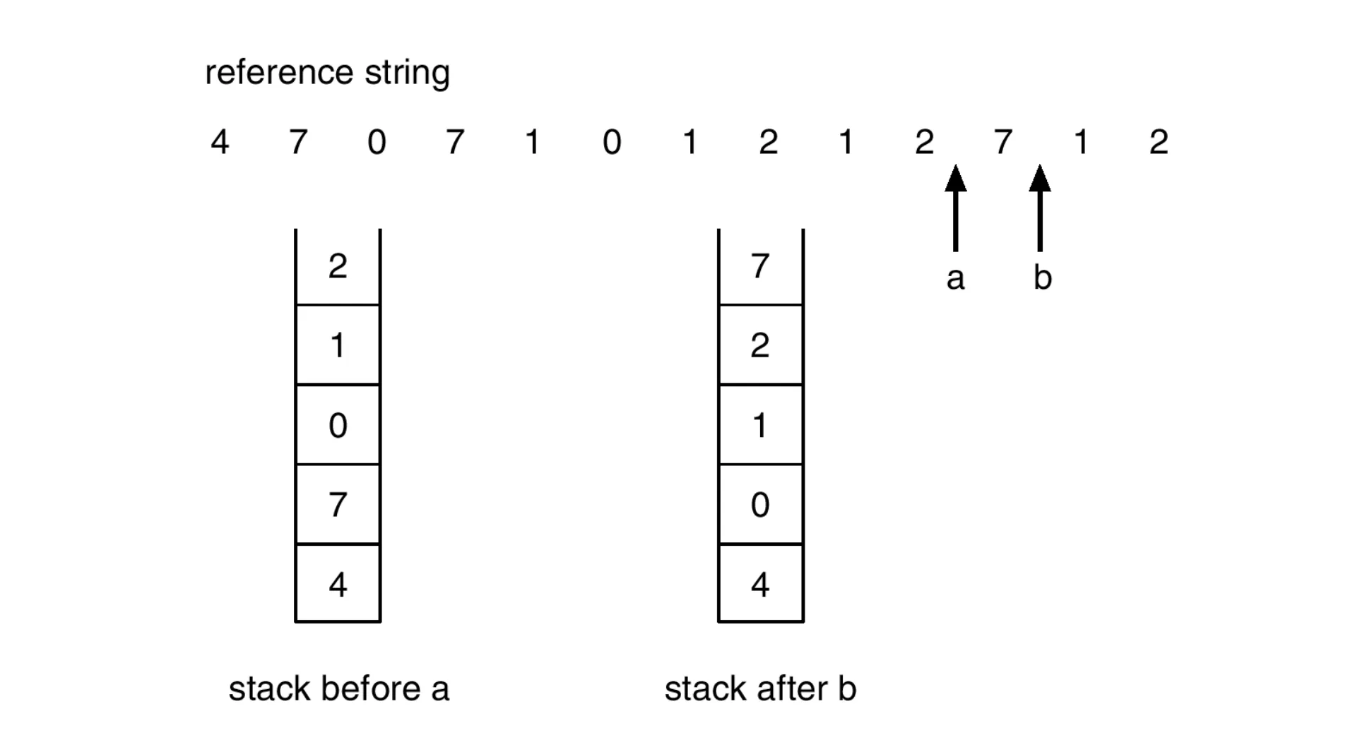
- page를 접근할 때마다 stack의 가장 위에 넣어서 자연스럽게 stack 가장 아래에 제일 오래된 page가 남게하는 방식
- 오래된 page를 O(1)만에 접근 가능
- 이 구조를 위해 doubly linked list로 스택을 구현
- page 옮길 때마다 pointer를 6번 변경해야함
- memory access가 6번임
- overhead가 큼
LRU Approximation algorithm
reference bit algorithm
- page마다 reference bit을 생성
- page에 접근할 때마다 bit 0→1로 변경
- 그리고 주기적으로 모든 reference bit을 0으로 reset
- 자주 접근이 되는 page는 reset 이후에도 금방 1로 변경됨
- reference bit이 0인 page를 victim으로 선정
- 문제점: bit가 0인 page 중 누가 가장 오래된 지 알 수 없음. 성능이 낮음
additional-reference-bits algorithm
- reference bit을 여러개 두는 방법
- 8비트로 가정했을 때, 처음에 0000 0000 으로 시작
- 접근되면 1로 표시
- 0000 0000 → 0000 0001
- 한 주기마다 비트가 밀림
- 0000 0000 → 0000 0010
- 문제점: 공간을 많이 사용해야하고, reference bit중 가장 작은 것을 찾는 대소 관계를 비교해야는 문제
second chance (clock) algorithm
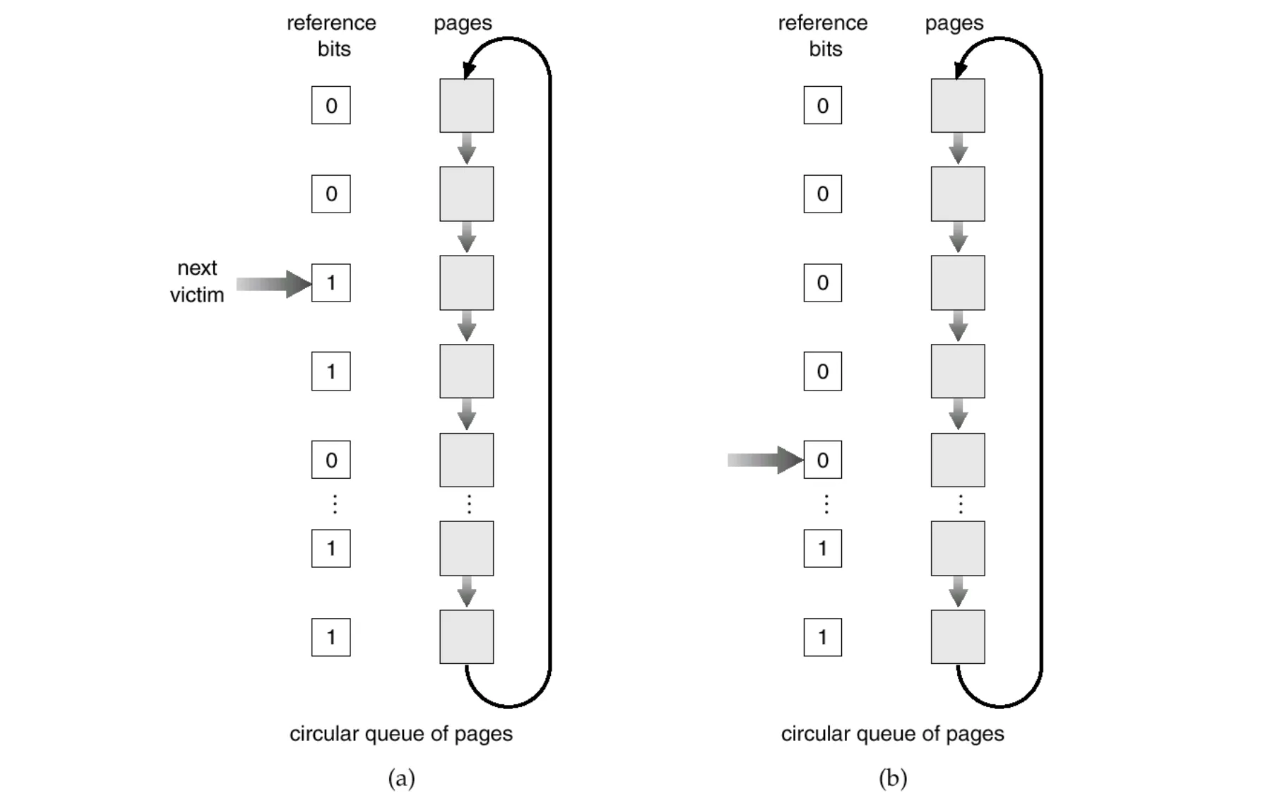
- reference bit를 하나만 사용하고, page를 circular queue로 관리, pointer 하나 사용
- pointer가 cicular queue를 돌면서 주기적으로 하나씩 reference bit을 0으로 초기화
- 한 바퀴 돌고 왔는데 아직도 0이면 오랫동안 접근이 되지 않았다고 판단하고 victim으로 선정
- reference bit algorithm과 차이점
- 방금 0으로 만든 page와 30 주기 전 0으로 만들었는데 아직도 0인 페이지는 시간차이가 발생하므로, 누가 더 오래 된 page인지 구별할 수 있음
- 요즘 사용하는 방식
Counting algorithm
LFU algorithm
- 제일 덜 접근된 페이지를 victim으로 선정하는 알고리즘
MFU algorithm
- 접근이 덜 된 페이지는 방금 올라와서 접근이 덜 되었다고 생각하고 접근이 가장 많이 일어난 page를 victim으로 선정하는 알고리즘
- 하지만 결과적으로 LRU가 더 좋기 때문에 counting algorithm은 사용하지 않음
Race condition
개념
여러개의 process/thread 들이 공유된 정보에 동시에 접근하여 올바르지 못한 값이 결정되는 현상
- 이를 해결하기 위해 process간 동기화가 필요
critical-section problem
개념
- critical-section: 다른 프로세스와 정보를 공유하는 부분. 허나, 한 번에 하나의 프로세스만 접근할 수 있음
- 이를 위해 한 process가 critical section에서 작업 중이면, 다른 process가 접근하지 못하도록 막아줘야함
해결책의 조건
-
mutual exclusion(상호 배제)
하나의 프로세스가 임계구역에서 실행되고 있다면, 다른 프로세스는 임계구역에 접근할 수 없음
-
progress(진행)
critical section에서 다른 process가 실행되고 있지 않다면, 진입하고 싶어하는 process를 막으면 안됨
-
bounded waiting(한정된 대기
process가 critical section에 진입하기 위해 무한정 대기를 하게 하면 안된다
peterson’s alogrithm
(process 두 개라는 가정)
- turn 변수와 flag 배열을 이용하여 critical section problem을 해결하는 알고리즘
- turn 변수만 있으면 progress X
- flag 배열만 있으면 progress X (모두 true가 될 수 있음)

- flag가 모두 true가 되더라도 turn은 하나의 값만 가질 수 있으므로 critical section에 접근하는 process는 언제나 하나임 → mutual exclusion O
- critical section이 비어있으면 모든 flag 배열은 false일텐데, 그 경우에 while은 반드시 false이기에 통과 가능 → progress O
- 그리고 앞의 process가 종료되면 어떠한 경우에도 다른 process가 한번은 critical section에 접근 가능 → bounded waiting O
- 단점: while에서 cpu를 사용하며 busy waiting 해야함
Mutex
개념
- peterson’s algorithm과 같은 알고리즘은 개발자가 원리를 이해하고 직접 critical section마다 적어줘야 효력이 발생
- 이렇게 하지말고, 열쇠 시스템을 만들어서 열쇠를 가지고 있는 process만 접근 가능하도록 하자
do {
acquire lock;
/* critical section */
release lock
/* remainder section */
} while (True);- lock system이 제대로 동작하기 위해서는 lock을 한순간에 하나의 process에게만 줄 수 있다 보장되어야함
- single process 환경에서는 lock을 획득할 때 interrupt를 꺼버리는 방법으로 해결
- multi process 환경에서는 hardware에서 이를 지원 → atomic hardware
Atomic hardware
- Test and Set

- Swap

Semaphore
개념
- 세마포어 변수 S, wait(), signal()로 구성
- atomic function인 wait, signal로 S에 접근
//busy waiting
wait(s) {
while(s <= 0);
s--;
}
signal(s) {
s++;
}
// block-wakeUp
typedef struct {
int value;
struct process *list;
} semaphore;
wait(semaphore *s) {
s->value--;
if (s->value < 0) {
add this process to s->list;
sleep();
}
}
wait(semaphore *s) {
s->value++;
if (s->value <= 0) {
choose process P in s->list;
wakeup(P);
}
}- mutex와 달리, 여러 자원을 관리할 수 있음
- binary semaphore는 공유자원 1개, counting semaphore는 여러개를 상호 배제 가능
Busy waiting vs Block-WakeUp
- critical section의 크기가 그렇게 크지 않으면 busy waiting이 나을수도 있다
- 왜냐하면, block시키고 wake up 시키는 것도 overhead의 일종이기 때문
