
IPC
IPC(Inter process communication)란
- 하나의 컴퓨터 안에 다른 프로세스들이 정보를 공유하는 방법
- 프로세스들은 각자 독자적인 메모리 공간을 가지기 때문에 다른 프로세스의 메모리에 접근할 수 없음
- 그러므로 정보를 공유하기 위해서는 다른 방법이 필요한 것
IPC 사용 이유
- 정보 공유: 여러 응용 프로그램이 동일한 정보에 관심을 가질 수 있으므로, 정보를 병행적으로 접근할 수 있는 환경을 제공해야함
- 계산 가속화: 특정 태스크를 빠르게 실행하고 싶으면 하나의 태스크를 여러 서브태스크로 나누어 병렬적으로 실행하게 해야 함. 물론 이러한 가속화는 프로세서가 여러개인 상황에서만 가능
- 모듈성: 시스템의 기능별로 프로세스 또는 스레드를 나누어 모듈식으로 시스템을 구성할 수 있음
IPC 종류
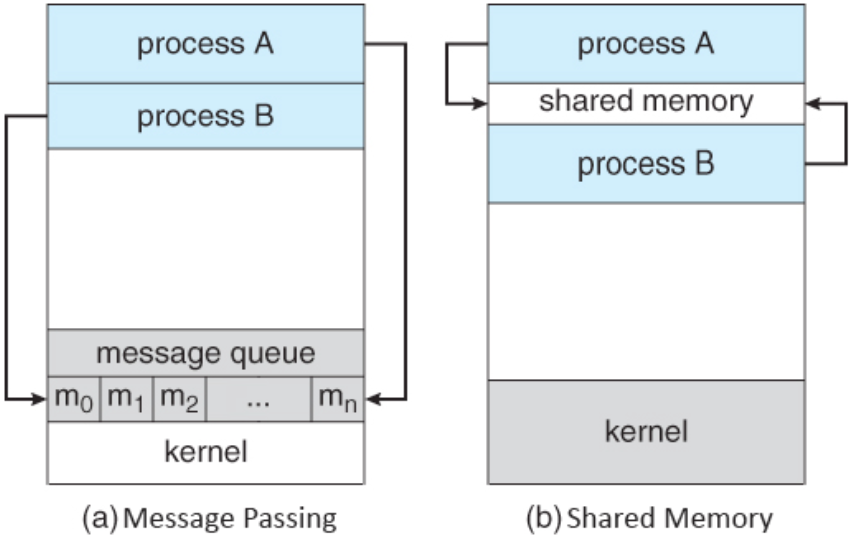
Shared memory
- 협력 프로세스들에 의해 공유되는 메모리의 영역이 구축됨
- 프로세스들은 그 영역에 데이터를 읽고 씀으로써 정보를 교환
- shared memory를 구축할 때만 시스템 콜이 필요
- 구축만 되면 모든 접근은 일반적인 메모리 접근으로 취급
- kernel의 도움이 필요 없음
- message passing에 비해 빠름
- 구축만 되면 모든 접근은 일반적인 메모리 접근으로 취급
Message passing
- 협력 프로세스들 사이에 교환되는 메시지를 통하여 통신이 이루어짐
- race condition이 발생하지 않음
- 적은 양의 데이터를 교환하는 데 유용함
- 통상 시스템 콜을 사용하여 구현되므로 커널을 간섭 등의 부가적인 시간 소비 작업이 필요
- shared memory에 비해 느림
Shared memory
- 공유 메모리 세그먼트는 공유 메모리 세그먼트를 생성하는 프로세스에 위치함
- 그런데 찾아보니, 이 공유 메모리 부분의 실제 부분은 커널에 있는 것 같고, 그걸 매핑해둔 것 같다
- 데이터의 형식과 위치는 데이터를 공유하기로 한 프로세스들에 의해 결정되고 운영체제의 소관이 아님
- 프로세스들은 동시에 동일한 위치에 쓰지 않도록 책임을 져야함
- producer consumer의 해결책으로 작용함
Message passing
- 프로세스들이 네트워크에 의해 연결된 다른 컴퓨터들에 존재할 수 있는 분산 환경에서 특히 유용
Paging
Binding
- 변수의 주소(data)를 프로그램 코드에 mapping 시키는 행위
- 메모리 상의 데이터의 물리적 주소를 실제 코드에 연결시키는 행위
compile time binding
- compile 하면서 미리 메모리에 올라갈 물리적 주소를 코드에 mapping 하는 방법
- single process 환경일 때 사용했던 방법
- compile 하는 순간 프로그램에 메모리 위치가 하드 코딩 되기 때문에, OS만 달라져도 kernel 크기가 달라져서 오류가 발생 → 이식성이 낮음
load time binding
- data를 memory에 코드가 load될 때 물리적 주소를 상대적 주소를 기준으로 코드에 mapping 하는 방법
- 이러면 다른 OS, 다른 기기에서 프로세스를 실행시켜도 기계에 의존성이 떨어졌기 때문에 가능
- 하지만, 한 번 올라가면 process의 data 위치가 고정되기 때문에 메모리를 효율적으로 사용하기 위해 메모리가 이를 관리하기 불편함
execution time binding
- code가 메모리에 올라가도 물리적 주소가 코드에 mapping되지 않고 상대적인 주소가 mapping이 되어있음
- cpu가 실제로 데이터에 접근하려 할 때 상대적 주소가 물리적 주소로 반환됨
- 이를 위해 address mapping table이 필요함
- 이 작업은 굉장히 빨라야 하기 때문에 하드웨어의 지원을 받음. MMU
Logical vs Physical address
- logical address: cpu가 process의 memory영역이라 생각하고 접근하는 주소
- process의 주소 시작은 0번, 끝은 max라고 생각하여 접근하는 주소
- physical address: 실제로 메모리에 올라와 있는 process의 memory영역 주소
- logical 주소에 process의 physical 주소의 첫번째 주소를 더한 값
분리하는 이유
- cpu가 memory상에 실제 위치를 알지 못해도 작업하는데 지장이 없도록 하기 위해
- process의 memory상 위치와 의존성을 제거하는 것
- 이렇게 되면, memory를 더 효율적으로 사용할 수 있도록 운영체제가 관리할 수 있는 가능성이 생긴다.
Contiguous Allocation
메모리 상에 프로세스를 연속적으로 저장하는 방식
- physical address를 계산하는 방식의 중요한 가정
- memory는 process에 연속적으로 올라간다.
Hole
- contiguous allocation에서 프로세스가 종료되면, 메모리에서 프로세스가 빠져나감
- 그럼 해당 메모리 공간이 구멍으로 빔. 크기도 제각각. 이를 Hole 이라함
- OS는 메모리를 효율적으로 사용하기 위해서 해당 hole을 관리해야함
- hole이 어디에 존재하는지, 크기는 얼마인지 등 정보를 저장하다가 새로운 process가 메모리에 올라오면 hole을 이용하여 메모리를 제공해야함
Dynamic storage allocation problem
앞으로 어떤 process들이 시작될 지 모르지만, 효율적으로 메모리를 관리하기 위해서 지금 시작된 process를 어느 hole에 넣을지 결정하는 문제
- First-Fit: process가 들어갈 수 있는 가장 처음 hole에 넣기
- Best-Fit: process size와 가장 비슷한 hole에 넣기
- Worst-Fit: 가장 큰 hole에 넣기
- 항상 worst라 할 순 없음. best fit으로 넣으면 external fragmentation이 많이 발생하지만, worst fit으로 넣으면 해당 hole에 다른 process가 들어올 수도 있으므로 external fragmentation이 줄어듦
Fragmentation
메모리 상에 제대로 사용되지 못하는 짜투리 공간
- External Fragmentaion: process에 할당되지 못하고 남아있는 공간
- contiguous allocation을 하면 어떤 경우에도 hole에 process를 넣는 과정에서 fragmentation이 발생한다
- Internal Fragmentation: process에 할당은 되었지만 사용되지 못하고 남아있는 공간
Compaction
프로세스 사이사이 external fragmentation을 없애기 위해 프로세스를 한쪽으로 밀어 붙이는 방법
- overhead가 엄청남. 절대 쓸 수 없음
Paging
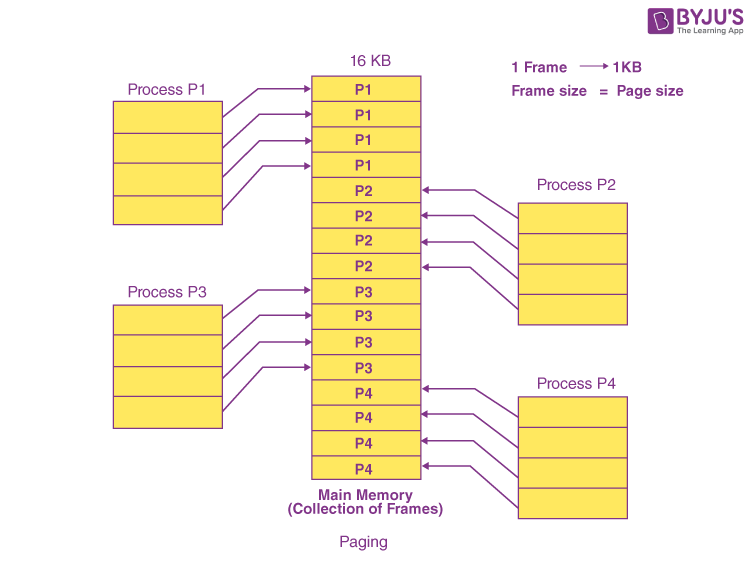
메모리 공간과 process address space 를 동일한 크기의 page로 자르고 하나씩 끼워넣는 방식
- 비어있는 공간에 끼워넣다 보니 하나의 프로세스가 메모리에 연속적으로 올라간다는 보장X
- external fragmentation X
- Internal fragmentation O
- 모든 프로세스가 page 크기로 나누어 떨어지지 않기 때문에
- 하지만 마지막 page에서만 발생하므로 그렇게 큰 문제는 아님
- page를 process간에 공유할 수 있음
- shared page
- contiguous allocation은 데이터에 접근하려면 해당 프로세스의 첫 주소를 알아야 하므로 시작지점이 같지 않으면 불가능
문제점
- 전과 다르게 상대적 주소인 logical address와 process 시작 위치를 기반으로 더하여 physical address를 찾아갈 수 없음
해결책
-
page table 도입
-
모든 page가 어떤 frame에 저장되어있는지 mapping 되어있는 table
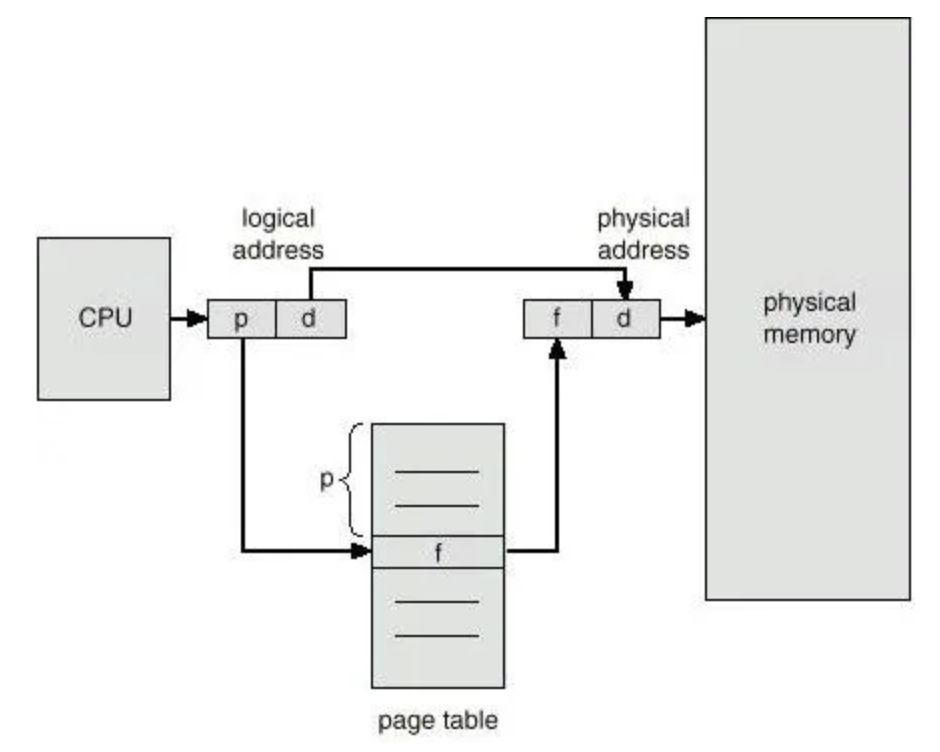
-
page를 2의 지수 크기로 설정하고 mmu에서 비트를 나누어 접근하는 방식으로 logical address를 physical address로 변환함
-
TLB
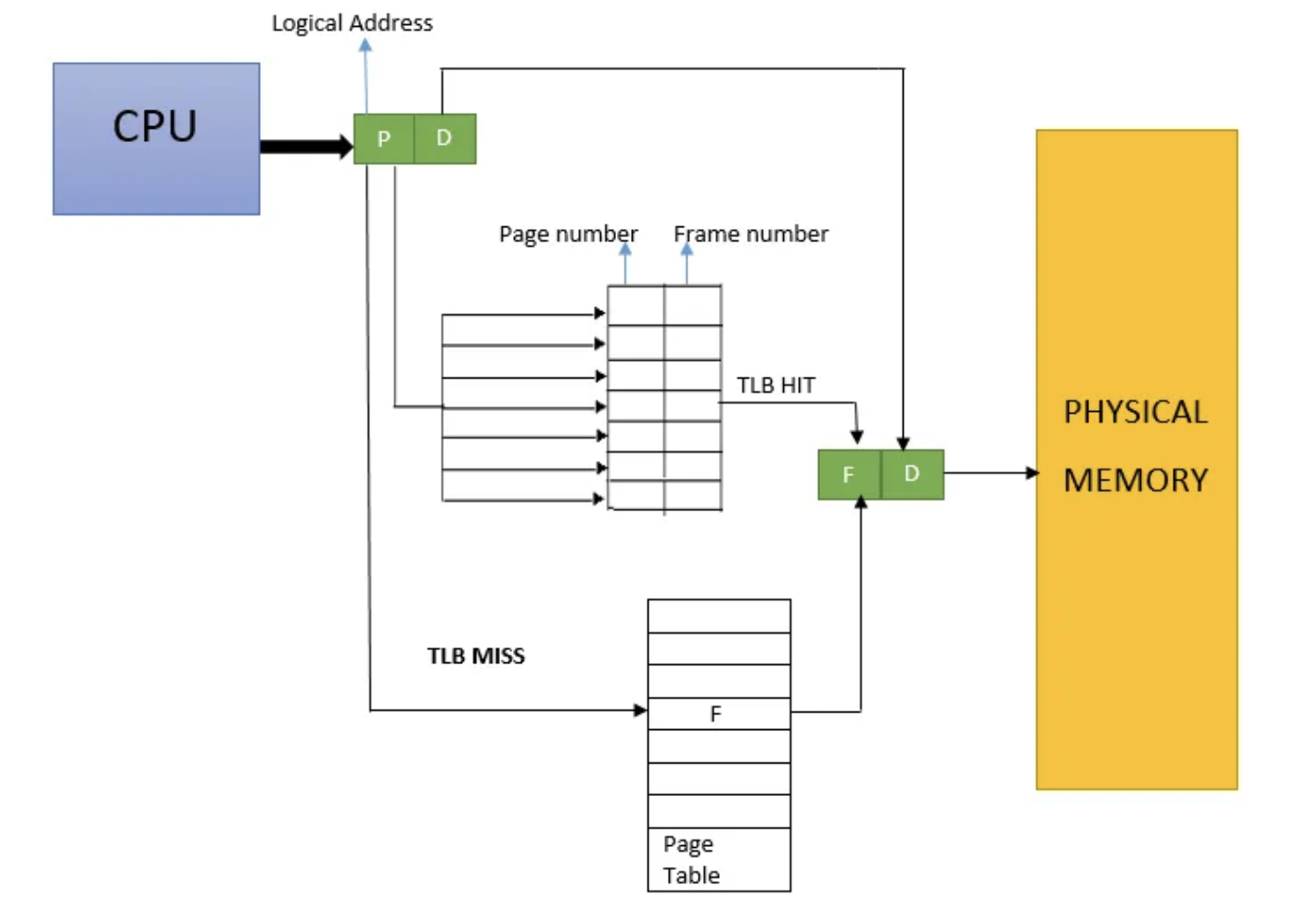
- page table은 mmu를 통해 계속 참조되므로 memory에 올라와 있어야 함
- paging이 없을 때는 logical address를 mmu가 physical address로 변환하고 memory에 한 번만 접근하면 되었으나, paging을 이용하면 memory에 올라와 있는 page table을 참조해야하므로 memory를 두 번 접근해야 함
- cpu 입장에선 memory는 엄청 느린 장치이므로 매번 이를 기다리는 것은 overhead임
- 그래서 빠르게 접근할 수 있는 일종의 cache를 만듦
- TLB(Translation look-aside buffer)
- Associative memory임
- page가 순서대로 연속적으로 저장되어 있는게 아님
- 그래서 모든 index를 뒤져야하는 문제가 있음
- 이를 위해 병렬적으로 데이터를 탐색할 수 있는 장치를 이용함
- process마다 자신의 page table이 따로 있음
- 그래서 context switching이 발생하면 tlb는 flush됨
Page Table
Hierachical Paging
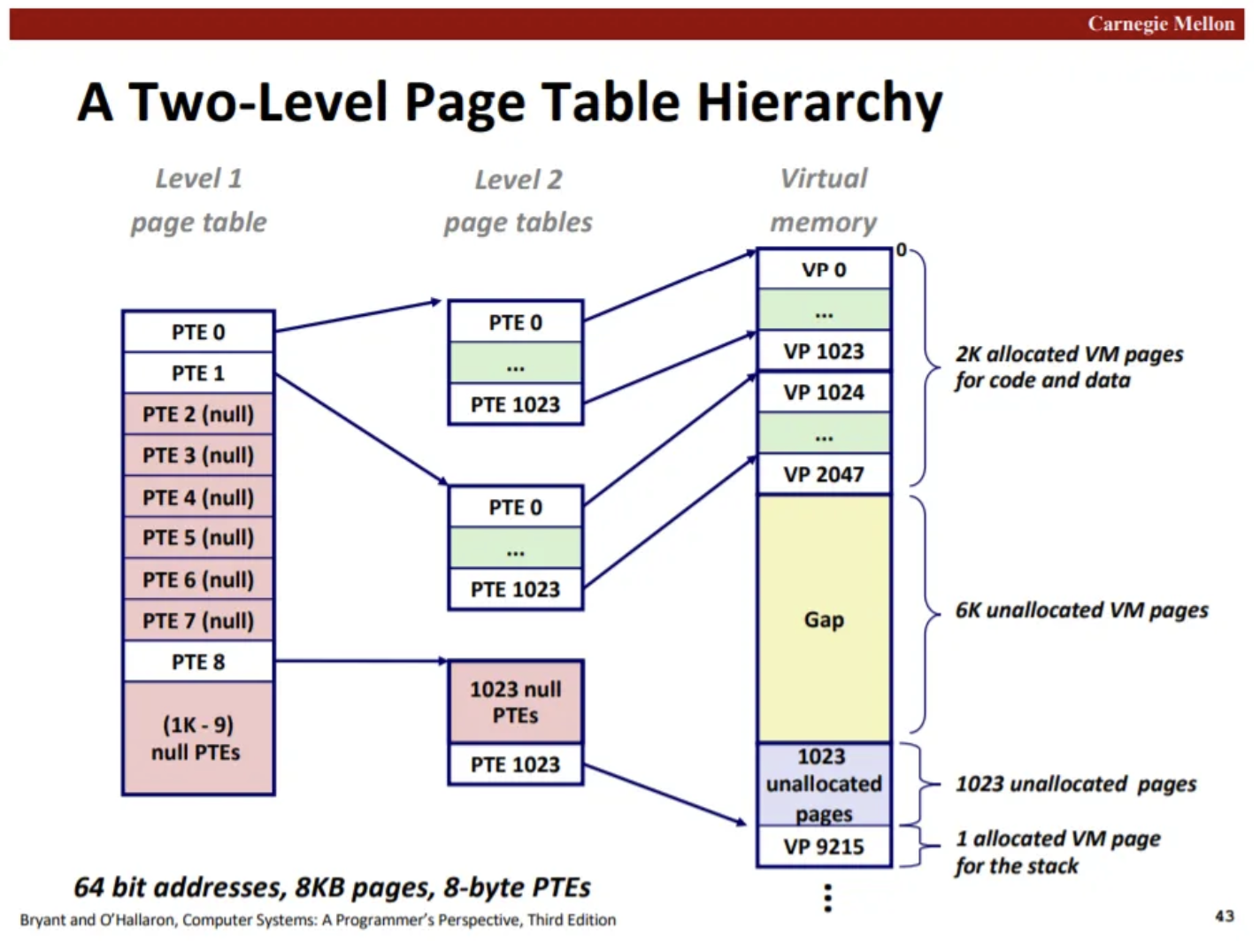
- 등장배경
- 32bit 운영체제에서는 주소 체계가 32bit로 표현됨(바이트당 주소가 표현됨). 한 페이지가 4kb라고 가정했을 때, 32비트 중 12비트는 페이지 내에서 상대적으로 움직이는 비트로 사용되고, 나머지는 20개는 프레임 개수를 나타내는 비트로 활용가능
- 그러면 페이지 테이블에 저장해야할 데이터 양은 (페이지 수) (주소 자체 크기) = 2^20 2^2(32bit == 4byte) = 2^22 byte 2^22 byte == 4 2^10 2^10 byte == 4MB 그런데 이 사이즈는 한 페이지의 크기를 넘고, 페이지 테이블은 메모리에 저장되기 때문에, 여러 프레임에 저장되어야 함 그러면 mmu가 연산할 때 tlb miss가 나면 page table에서 index 접근으로 가져오는 것이 불가능해짐. 연속적으로 데이터가 올라와 있는게 아니기 때문임
- outer-page table을 만들어서 page table의 page가 어느 frame에 저장되어 있는지 저장 그리고 전체 page table은 크기가 크기 때문에 disk로 내려버림 지금 참조되는 page table block만 메모리에 올려서 일을 처리 → 참조 지역성으로 해결 page number도 아래와 같이 관리
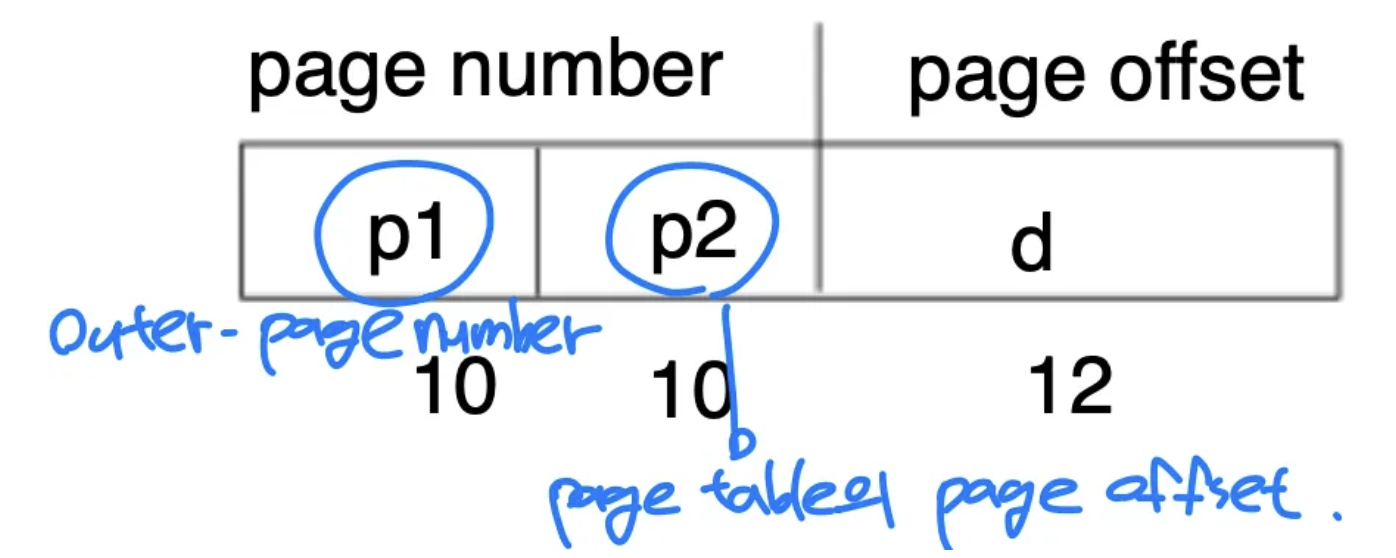
- 문제점
- outer page table도 한 프레임안에 들어가지 않을 수 있음
- 실제로 64-bit 주소 체계를 사용하면 한 프레임에 들어가지 않음
- 해결방법
- outer page table을 더 다단계로 만들자
- 하지만 이는 overhead임
- 단계가 길어지면 길어질 수록 memory에 접근해야하는 회수가 증가한다
- tlb가 이를 많이 해결해줌
- 그런데 64bit 운영체제에서는 6단계나 만들어야함
- 그래서 64bit 운영체제에서 64bit 주소체계를 사용하지 않고 48bit 주소체계를 사용하여 4단계로 처리 → 4단계는 처리할만함
- outer page table을 더 다단계로 만들자
Hashed page table
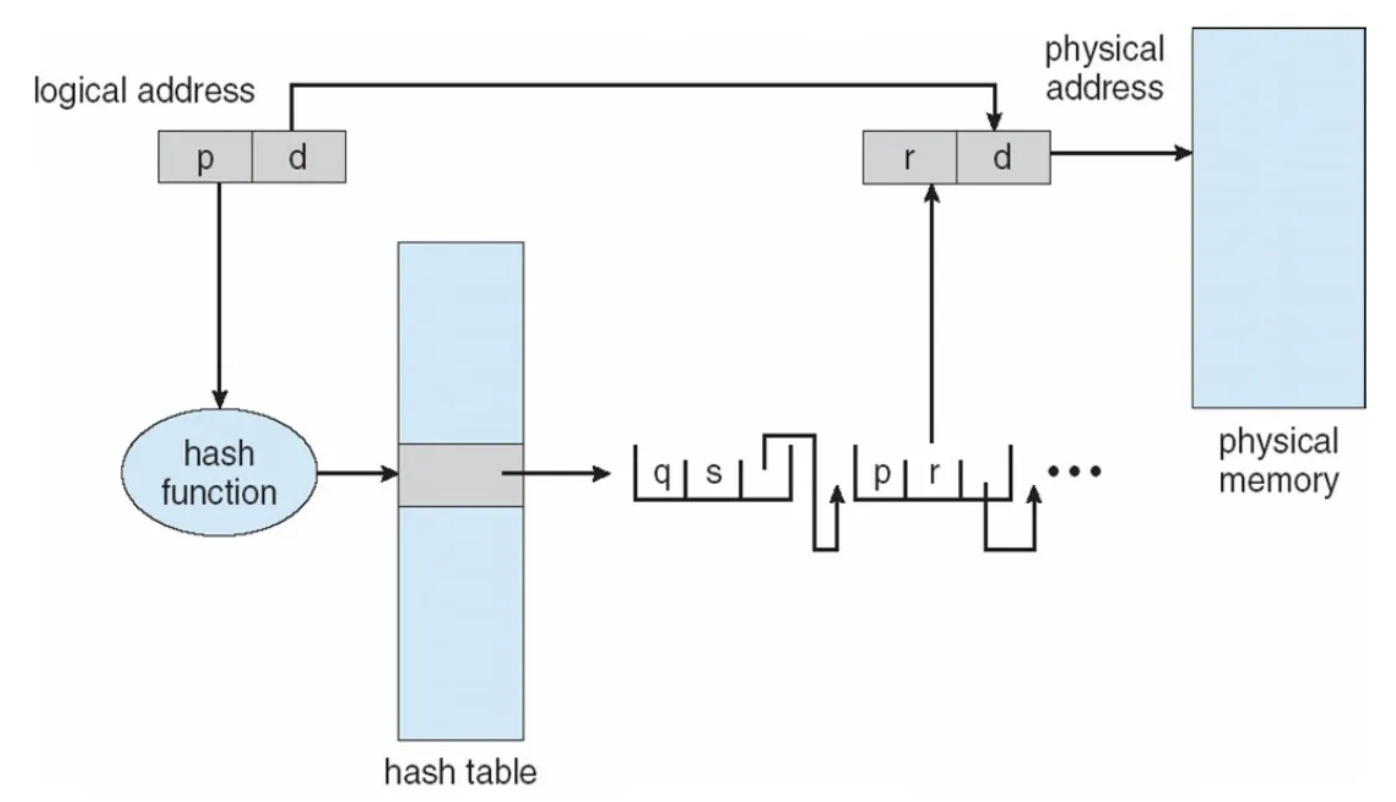
- hash function을 활용해서 page가 저장되어 있는 frame number를 가져오는 것
- collision이 발생해서 최대 O(n)의 시간복잡도가 발생할 수 있음
- 32 bit 운영체제에서는 two-level page table로 hashed page table의 최악의 경우보다 훨씬 빠른 설계를 제공하므로 고려한 가치가 없음
- 그 이상의 주소체계를 가진 운영체제에서는 고려해볼만 하다
Inverted page table
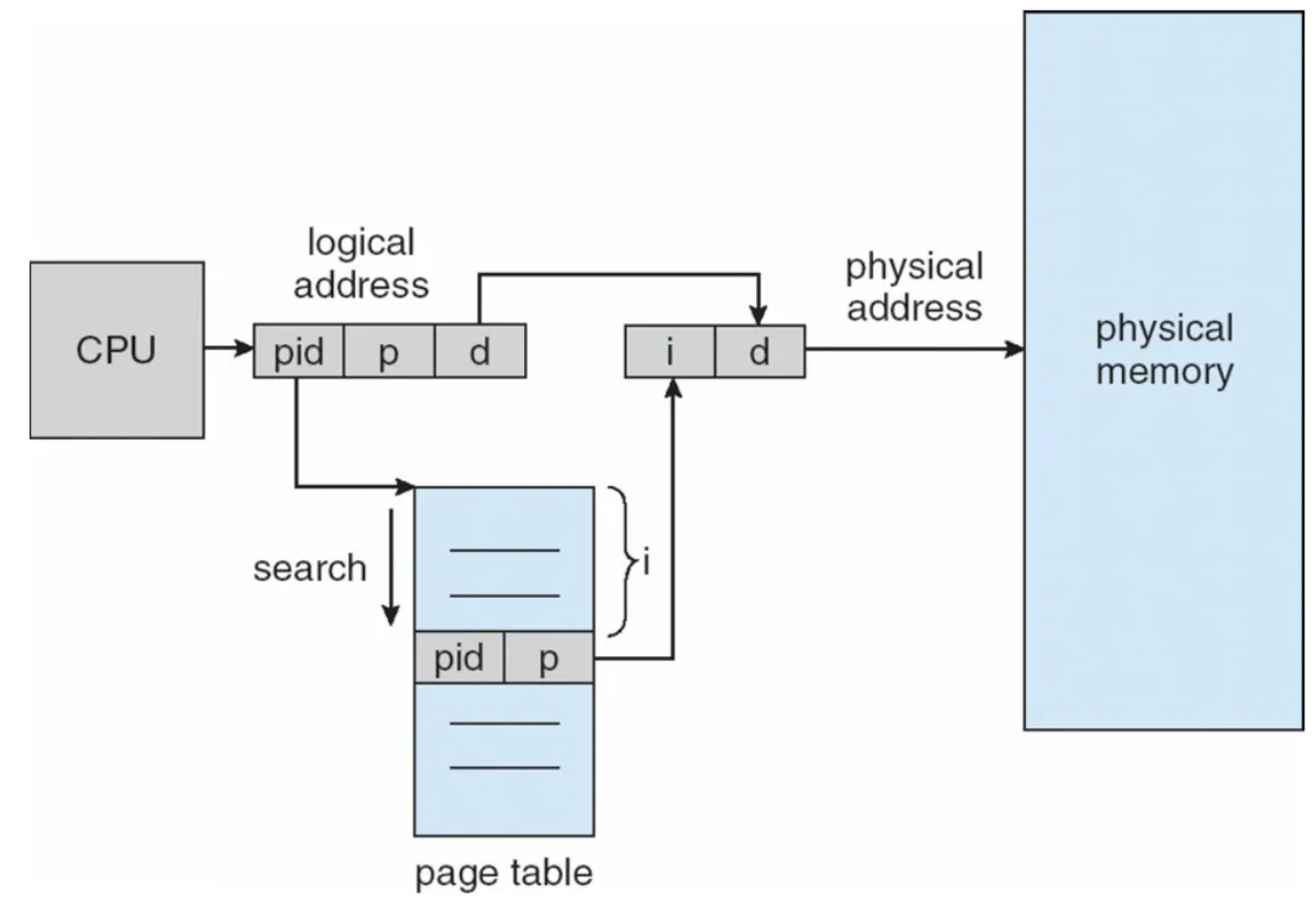
- 등장배경
- 이 모든 것이 page table의 크기가 너무 크기 때문에 발생하는 문제
- 한 프로세스가 가지는 주소 공간이 2^32 byte 즉 4GB이기 때문에 이러한 문제가 발생
- 프로세스가 10개면 40GB임
- 이러지말고, physical address를 logical address에 매핑해주자 “거꾸로”
- 시스템 자체에 하나의 페이지 테이블만 가지고, 프로세스 별로 페이지 테이블을 주지 말자
- 메모리 frame을 기준으로 page table을 만들고 어느 프레임에 어떤 프로세스의 어떤 페이지가 들어가는지 저장하자
- 문제점
- page가 어느 프레임에 저장되어있는 지 찾기 위해 모든 frame을 다 뒤져보아야함
- paging의 가장 큰 장점 중 하나인 shared page 기술을 활용할 수 없음
- 하나의 page에 최대 몇개의 process가 공유 될 지 한계를 정해야하는 구조이기 때문
- 해결방법
- 속도증가를 위해 hashing 적용
- shared page는 극복 불가
Segmentation
프로그램을 의미 단위로 구분하는 것
-
특징
- segmentation 별로 크기가 다를 수 있음
-
등장배경
- paging 기법을 사용하다 보니 프로그램의 의미가 기준이 아닌 크기를 기준으로 나눔
- 결과적으로, 동일한 함수가 다른 페이지에 나누어져 있는 현상이 발생
- “의미적인 덩어리” 개념이 사라짐
- 이는 문제를 야기
- paging의 가장 큰 장점 중 하나인 shared page 기능에서 발생
- 한 page 안에 공유 가능한 정보와 공유 불가능한 정보가 섞임
- 여러 page에 공유 가능한 정보가 나뉜다면 모든 페이지에 공유 가능한 page라는 정보가 기입
- paging의 가장 큰 장점 중 하나인 shared page 기능에서 발생
- paging 기법을 사용하다 보니 프로그램의 의미가 기준이 아닌 크기를 기준으로 나눔
-
구조
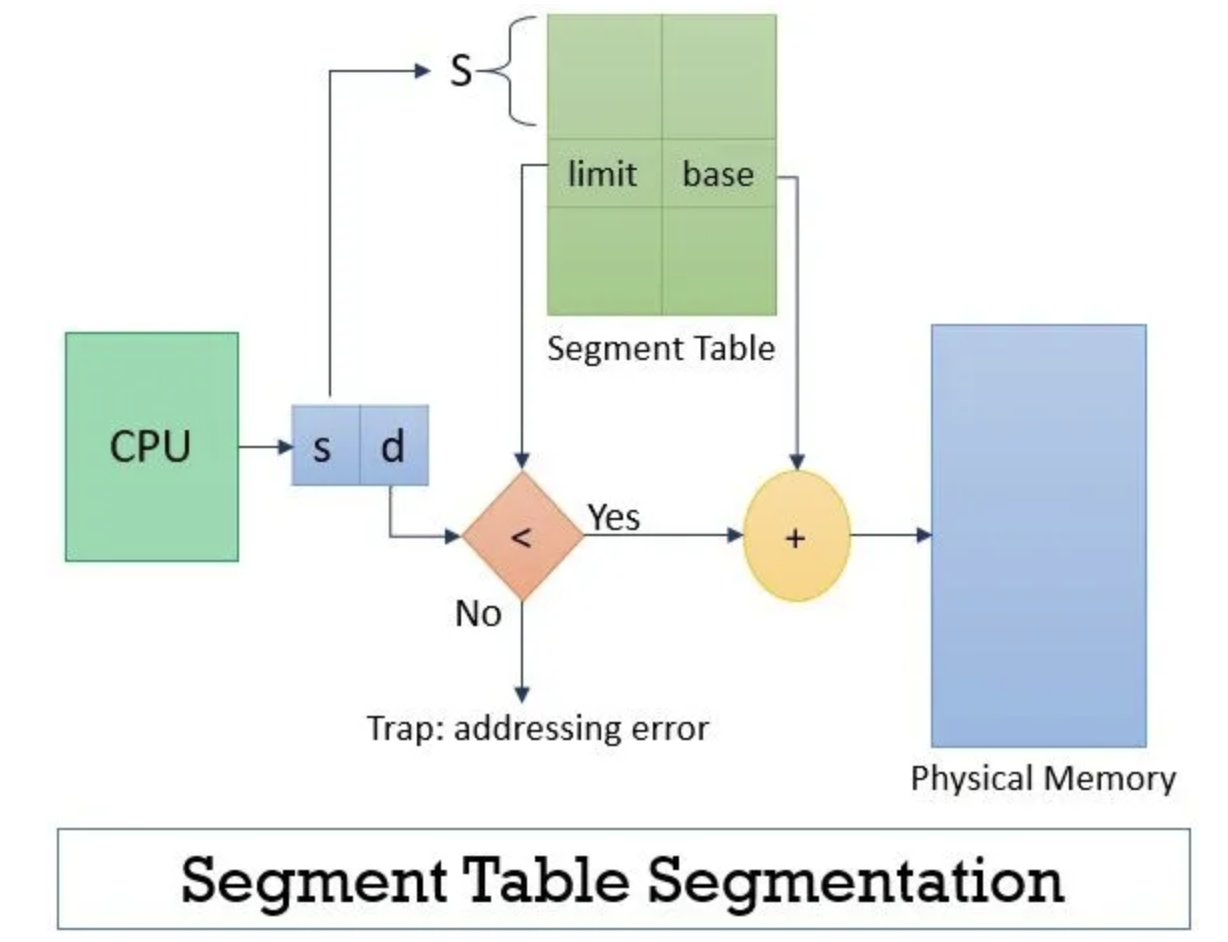
- paging의 주소 체계와 비슷함
- segmentation table을 만들고 logical address로 base address와 offset을 이용하여 접근
- segmentation table에는 base, limit 두 가지 정보가 저장
- base는 seg가 시작되는 주소
- limit은 seg의 길이
- paging과 비교되는 몇 가지 특징을 가짐
- protection
- paging에서는 접근이 가능한 page인지 아닌지, 다시 말해 address space에 실제로 포함이 되는 page 인지 아닌지를 나타내는 valid bit만으로 접근 가능 여부를 설정
- segmentation에서는 R/W/X 기법을 활용하여 더 세부적으로 조절함
- 의미별로 하나의 덩어리로 묶어든 개념이기 때문
- Sharing
- paging에서는 page 하나 하나 share를 따로 해줘야 했지만, segmentation에서는 더 효율적으로 share할 수 있음. 하나의 큰 의미 단위를 한꺼번에 share할 수 있기 때문
- protection처럼 더 세부적으로 어떤 기능이 가능하게 share할 지도 정할 수 있음
- allocation
- 하지만 segmentation은 하나의 의미 단위 안에서 contiguous allocation이고, segmentation 별로 크기가 다르기 때문에 external fragmentation을 피해갈 수 없음
- protection
Segmentation with paging
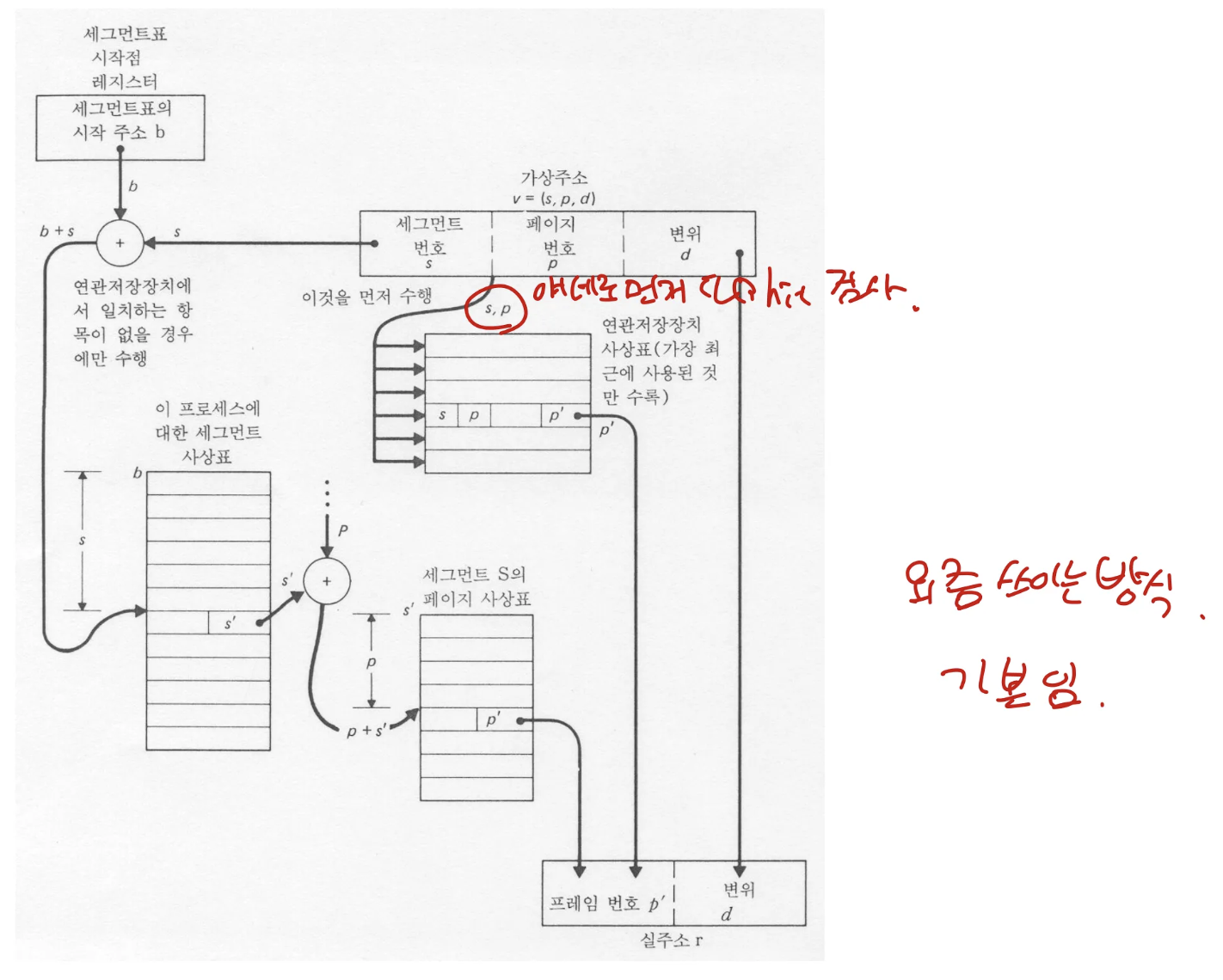
segmentation의 external fragmentation을 해결하기 위해 paging을 도입
- memory를 page단위로 잘라 frame으로 만든다
- process address space를 segmentation 단위로 자른다
- segmentation을 page 단위로 자른다
- A segmentation의 B page에 C 번째 줄에 있는 데이터라고 접근 가능
- 이제 의미 단위로도 묶이고, paging도 적용이 됨
- 이를 접근하기 위해 segment 마다 page table이 이제 필요
- segmentation 기법의 장점을 활용하기 위해서 segmentation table에서 sharing, protection을 하면 됨
